
在前几天的文章中,我们详细介绍了在windows系统下如何创建网络爬虫的虚拟环境以及如何安装scrapy,包括scrapy安装过程中可能会遇到的常见问题及其解决方案。如果你对这些内容感兴趣,可以通过链接查看详细信息。今天,小编将带领大家深入了解scrapy爬虫框架,并指导如何创建第一个scrapy项目,具体步骤如下。
 首先,进入虚拟环境。如果你不清楚如何进入虚拟环境,可以参考之前的文章:如何在Windows下创建指定的虚拟环境和如何创建默认的虚拟环境。进入环境后,使用“pip list”命令检查Scrapy是否已成功安装,如下图所示。
首先,进入虚拟环境。如果你不清楚如何进入虚拟环境,可以参考之前的文章:如何在Windows下创建指定的虚拟环境和如何创建默认的虚拟环境。进入环境后,使用“pip list”命令检查Scrapy是否已成功安装,如下图所示。
 可以看到,Scrapy已经成功安装。
可以看到,Scrapy已经成功安装。
接下来,小编计划将Scrapy项目放置在demo文件夹中,因此需要先返回到上级目录,如下图所示。
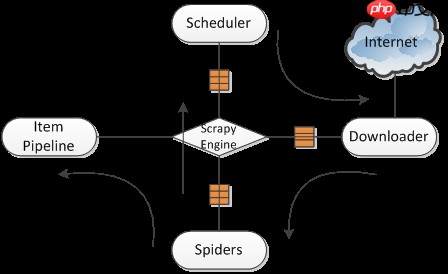
 然后,开始创建新的Scrapy项目。输入命令“scrapy startproject article”,其中“article”是项目名称,可以根据需要更改。输入命令后,系统会根据模板创建项目,模板位于“D:\pythonDemo\2018\September\demo\scrapy_demo\Lib\site-packages\scrapy\templates\project”目录,与你的爬虫环境相关,如下图所示,等待项目创建完成。当然,我们也可以自定义爬虫模板,但目前Scrapy提供的模板已经足够使用,我们只要能理解Scrapy的运作原理即可。
然后,开始创建新的Scrapy项目。输入命令“scrapy startproject article”,其中“article”是项目名称,可以根据需要更改。输入命令后,系统会根据模板创建项目,模板位于“D:\pythonDemo\2018\September\demo\scrapy_demo\Lib\site-packages\scrapy\templates\project”目录,与你的爬虫环境相关,如下图所示,等待项目创建完成。当然,我们也可以自定义爬虫模板,但目前Scrapy提供的模板已经足够使用,我们只要能理解Scrapy的运作原理即可。
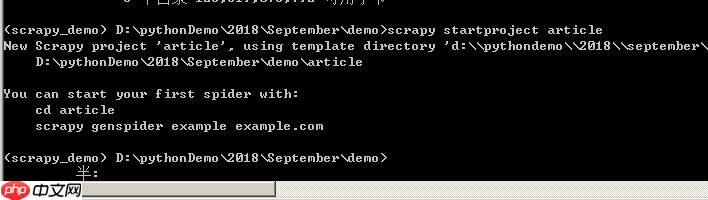 根据上图提示,首先进入article文件夹,输入命令“cd article”,然后通过“dir”查看目录,也可以使用“tree /f”生成文件目录的树形结构,如下图所示,可以清晰地看到Scrapy创建命令生成的文件。
根据上图提示,首先进入article文件夹,输入命令“cd article”,然后通过“dir”查看目录,也可以使用“tree /f”生成文件目录的树形结构,如下图所示,可以清晰地看到Scrapy创建命令生成的文件。
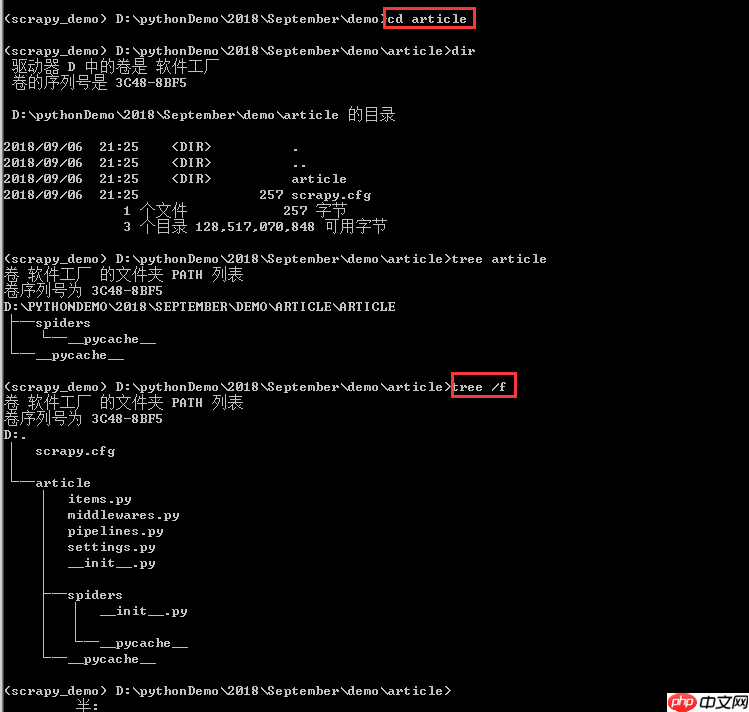 顶层的article文件夹是项目名称。
顶层的article文件夹是项目名称。
第二层包含一个与项目同名的文件夹article和一个scrapy.cfg文件。这个同名的article文件夹是一个模块,所有项目代码都在这个模块内添加,而scrapy.cfg文件是整个Scrapy项目的配置文件。

本套教程,以一个真实的学校教学管理系统为案例,手把手教会您如何在一张白纸上,从零开始,一步一步的用ThinkPHP5框架快速开发出一个商业项目,让您快速入门TP5项目开发。
 12533
12533

第三层中有五个文件和一个文件夹,其中__init__.py是一个空文件,用于将其上级目录变成一个模块;items.py用于定义存储对象,决定爬取哪些项目;middlewares.py是中间件文件,通常不需要修改,主要负责相关组件之间的请求与响应;pipelines.py是管道文件,决定爬取后的数据如何处理和存储;settings.py是项目设置文件,用于设置项目管道数据的处理方法、爬虫频率、表名等;spiders文件夹中放置的是爬虫主体文件(用于实现爬虫逻辑)和一个__init__.py空文件。
在Windows文件夹中,也可以清晰地看到新建的Scrapy文件,如下图所示。
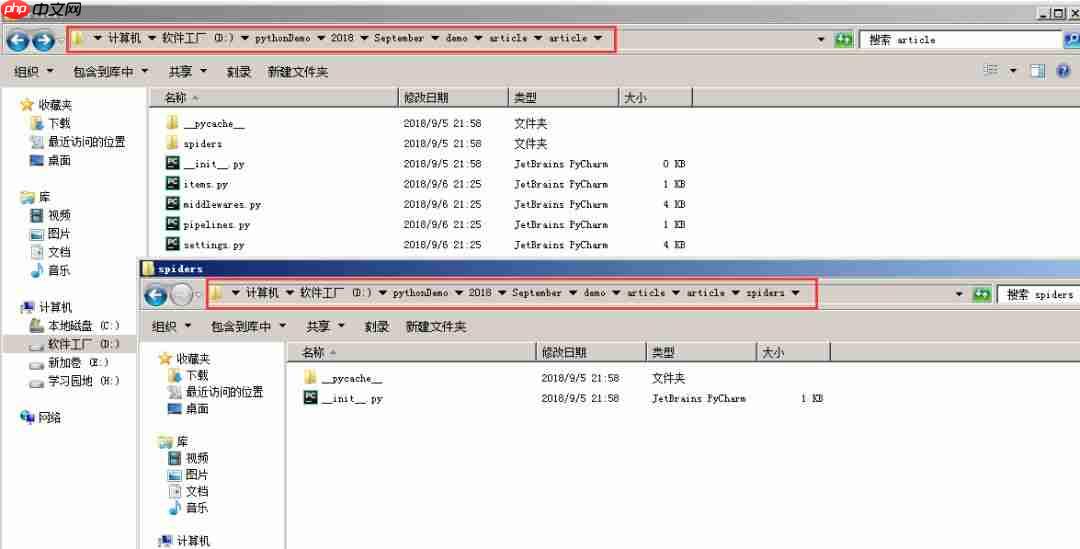 当然,也可以通过Pycharm导入项目来查看项目文件,这样会更加清晰,如下图所示。
当然,也可以通过Pycharm导入项目来查看项目文件,这样会更加清晰,如下图所示。
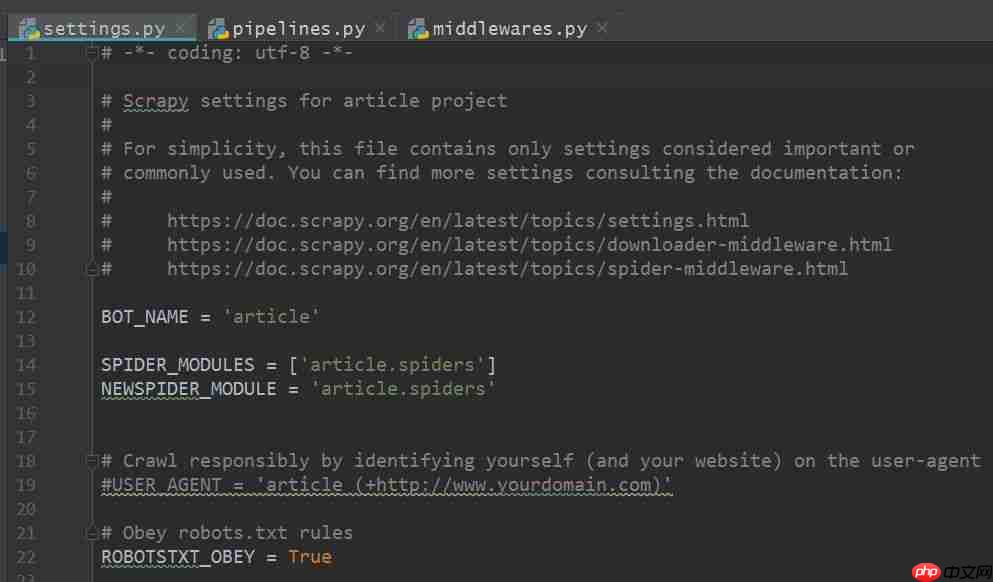
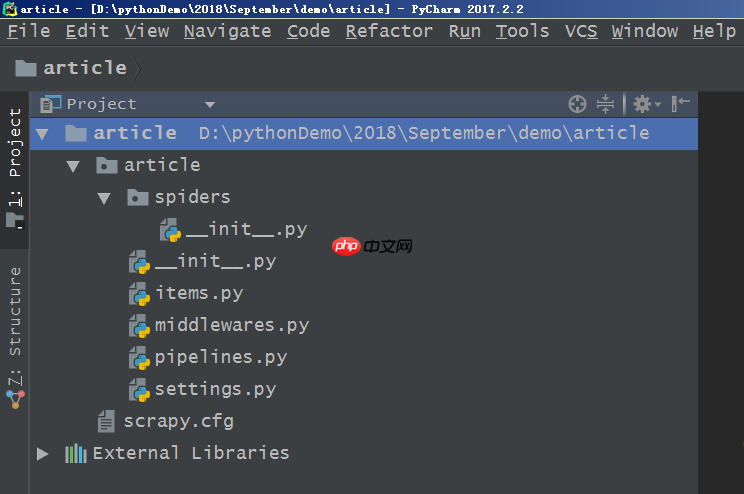 点击各个项目文件,可以查看其中的内容。settings.py文件的内容如下图所示,其他文件的内容在此不再赘述。
点击各个项目文件,可以查看其中的内容。settings.py文件的内容如下图所示,其他文件的内容在此不再赘述。
 至此,第一个Scrapy爬虫项目的创建及其文件解析介绍就到这里了。下一步将继续介绍Scrapy爬虫项目的进阶内容,敬请期待。
至此,第一个Scrapy爬虫项目的创建及其文件解析介绍就到这里了。下一步将继续介绍Scrapy爬虫项目的进阶内容,敬请期待。
--------------------- End ---------------------
以上就是手把手教你如何新建scrapy爬虫框架的第一个项目(上)的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 463
463





















