







初识scrapy:什么是scrapy?
Scrapy 是一个用 Python 编写的开源爬虫框架,基于高性能的事件驱动网络引擎 Twisted,Scrapy 爬虫具有极高的性能。
Scrapy 内置数据提取器(Selector),支持 XPath 和 Scrapy 自有的 CSS Selector 语法,并且支持正则表达式,便于从网页中提取信息。交互式的命令行工具便于测试 Selector 和调试爬虫,支持将数据导出为 JSON、CSV、XML 格式。Scrapy 的可扩展性强,运行自己编写的特定功能插件,内置了许多扩展和中间件,用于处理 cookies 和 session、HTTP 压缩、认证、缓存、robots.txt 以及爬虫深度限制。Scrapy 内部数据流程图如下:

Scrapy 内部数据流程图其中:
立即学习“Python免费学习笔记(深入)”;
Scrapy Engine(引擎):负责 Spider、ItemPipeline、Downloader、Scheduler 之间的通信、信号、数据传递等。 Scheduler(调度器):接受引擎发送的 Request 请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。 Downloader(下载器):负责下载 Scrapy Engine(引擎)发送的所有 Requests 请求,并将其获取到的 Responses 交还给 Scrapy Engine(引擎),由引擎交给 Spider 处理。 Spider(爬虫):负责处理所有 Responses,从中分析提取数据,获取 Item 字段所需的数据,并将需要跟进的 URL 提交给引擎,再次进入 Scheduler(调度器)。 Item Pipeline(管道):负责处理 Spider 中获取到的 Item,并进行后期处理(详细分析、过滤、存储等)。 Downloader Middlewares(下载中间件):可以自定义扩展下载功能的组件。 Spider Middlewares(Spider 中间件):可以自定义扩展和操作引擎和 Spider 之间通信的功能组件(例如进入 Spider 的 Responses 和从 Spider 出去的 Requests)。
制作 Scrapy 爬虫的步骤:
新建项目(scrapy startproject xxx):新建一个新的爬虫项目。
明确目标(编写 items.py):明确你想要抓取的目标。
制作爬虫(spiders/xxspider.py):制作爬虫开始爬取网页。
存储内容(pipelines.py):设计管道存储爬取内容。
如何安装 Scrapy?
在 Windows 系统下安装 Scrapy:
在 Windows 64 位系统下,安装 Scrapy 需要先安装以下依赖库:
pip install wheel lxml-4.2.1-cp36-cp36m-win_amd64.whl pyOpenSSL-17.5.0-py2.py3-none-any.whl pywin32-221.win-amd64-py3.6.exe Twisted-17.9.0-cp36-cp36m-win_amd64.whl pip install scrapy
在 Linux 下安装 Scrapy:
系统版本为 Ubuntu 16.04:
sudo apt-get install build-essential python3-dev libssl-dev libffi-dev libxml2 libxml2-dev libxslt1-dev zlib1g-dev pip install scrapy
Scrapy 文件结构:

本文档主要讲述的是Python之模块学习;python是由一系列的模块组成的,每个模块就是一个py为后缀的文件,同时模块也是一个命名空间,从而避免了变量名称冲突的问题。模块我们就可以理解为lib库,如果需要使用某个模块中的函数或对象,则要导入这个模块才可以使用,除了系统默认的模块(内置函数)不需要导入外。希望本文档会给有需要的朋友带来帮助;感兴趣的朋友可以过来看看
安装好 Scrapy 后,我们在 Windows 命令行模式下输入以下命令创建 Scrapy 项目:
scrapy startproject 项目名称
可以看到创建了以下文件:
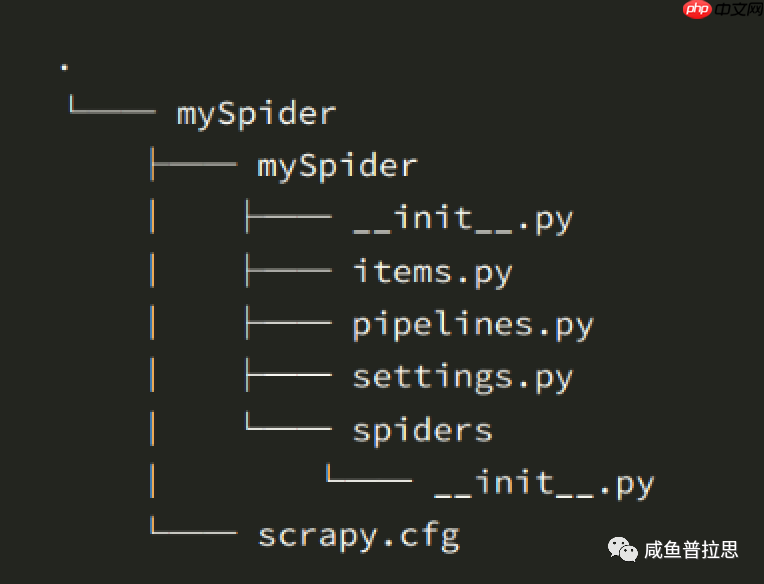
Scrapy 文件结构其中:
scrapy.cfg:项目的配置文件 xxSpider/:项目的 Python 模块,将会从这里引用代码 xxSpider/items.py:项目的目标文件 xxSpider/pipelines.py:项目的管道文件 xxSpider/settings.py:项目的设置文件 xxSpider/spiders/:存储爬虫代码目录
Scrapy 单文件 Demo:
创建完 Scrapy 项目后,还是要上手实验一下才能更好地理解,所以根据之前我在实验楼课程中的学习笔记写了一个 Scrapy 单文件 Demo,使用这个单文件 Demo 能快速爬取实验楼全部课程信息。首先看下单文件的内容结构:
# -*- coding:utf-8 -*- import scrapyclass ShiyanlouCoursesSpider(scrapy.Spider): """ 所有 scrapy 爬虫需要写一个 Spider 类,这个类要继承 scrapy.Spider 类。在这个类中定义要请求的网站和链接、如何从返回的网页提取数据等等。"""
爬虫标识符号,在 scrapy 项目中可能会有多个爬虫,name 用于标识每个爬虫,不能相同
name = 'shiyanlou-courses' def start_requests(self): """ 需要返回一个可迭代的对象,迭代的元素是scrapy.Request对象,可迭代对象可以是一个列表或者迭代器,这样 scrapy 就知道有哪些网页需要爬取了。scrapy.Request接受一个 url 参数和一个 callback 参数,url 指明要爬取的网页,callback 是一个回调函数用于处理返回的网页,通常是一个提取数据的 parse 函数。""" pass def parse(self, response): """ 这个方法作为 `scrapy.Request` 的 callback,在里面编写提取数据的代码。scrapy 中的下载器会下载 `start_reqeusts` 中定义的每个 `Request` 并且结果封装为一个 response 对象传入这个方法。""" pass因为实验楼的网页结构还是很简单的,所以解析部分就不做赘述,直接上单文件完整代码:
# -*- coding:utf-8 -*-import scrapy
class ShiyanlouCoursesSpider(scrapy.Spider): def start_requests(self):
课程列表页面 url 模版
url_tmpl = 'https://www.shiyanlou.com/courses/?category=all&course_type=all&fee=all&tag=all&page={}' # 所有要爬取的页面 urls = (url_tmpl.format(i) for i in range(1, 23)) # 返回一个生成器,生成 Request 对象,生成器是可迭代对象 for url in urls: yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): # 遍历每个课程的 div.course-body for course in response.css('div.course-body'): # 使用 css 语法对每个 course 提取数据 yield { # 课程名称 'name': course.css('div.course-name::text').extract_first(), # 课程描述 'description': course.css('div.course-desc::text').extract_first(), # 课程类型,实验楼的课程有免费,会员,训练营三种,免费课程并没有字样显示,也就是说没有 span.pull-right 这个标签,没有这个标签就代表时免费课程,使用默认值 `免费`就可以了。 'type': course.css('div.course-footer span.pull-right::text').extract_first(default='Free'), # 注意 // 前面的 .,没有点表示整个文档所有的 div.course-body,有 . 才表示当前迭代的这个 div.course-body 'students': course.xpath('.//span[contains(@class, "pull-left")]/text()[2]').re_first('[^\d]*(\d*)[^\d]*') }保存文件,使用
scrapy runspider xx.py -o data.json运行代码,这里使用-o参数将结果输出为 JSON 格式。写在后面:
这是咸鱼的第四篇学习笔记,旨在熟悉 Scrapy 单文件结构,为之后深入学习 Scrapy 打好基础。




























