
智谱glm大模型团队推出了 glyph 框架,探索了一条区别于主流方法的全新上下文扩展路径。
该框架创新性地采用视觉-文本压缩技术,将长篇文本转化为图像形式,使模型能够通过“看图”的方式理解语义内容。借助 由大语言模型驱动的搜索算法,Glyph 可自动寻找到最优的视觉渲染策略,在显著减少输入 token 数量的同时,保留关键语义信息,从而有效突破传统模型在上下文长度上的限制。
在多项长文本基准测试中,Glyph 在性能表现与当前顶尖LLM相当的基础上,实现了约 3至4倍的上下文压缩率,并带来了数倍的训练与推理速度提升。
Glyph 开辟了长上下文建模的新思路——通过将文本视觉化实现高效的信息扩展,为构建面向超长文本处理的大模型提供了极具潜力的发展方向。
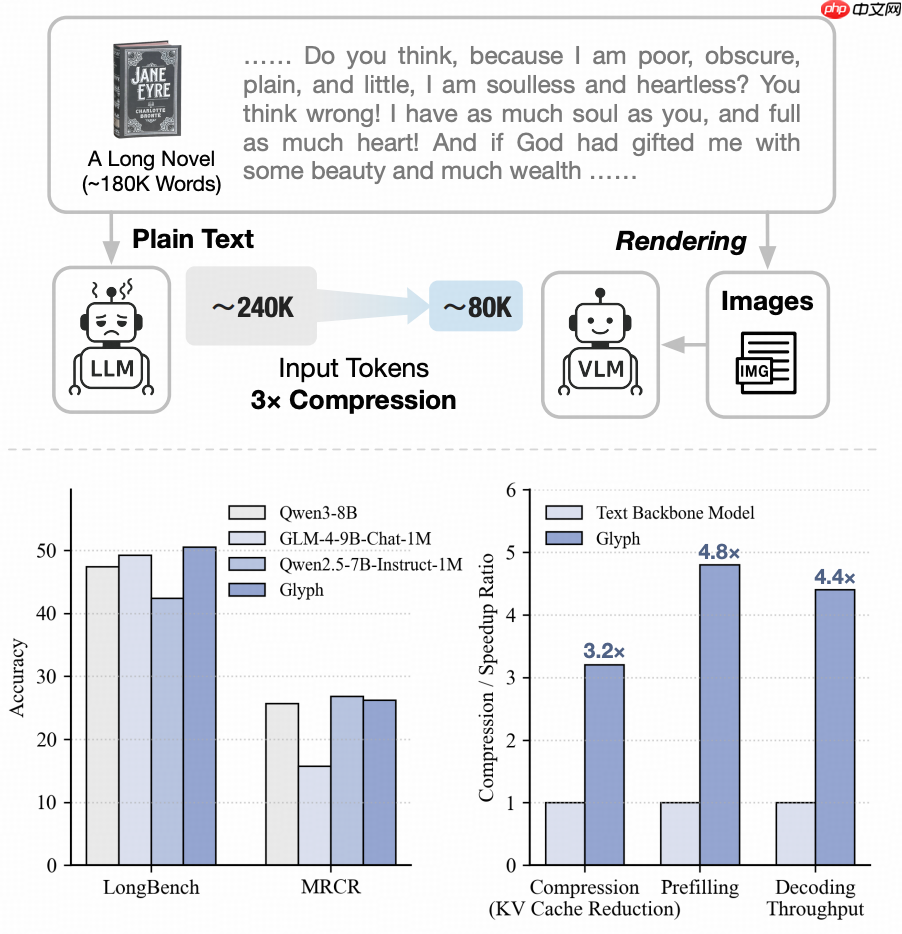
面对文档理解、代码库分析、复杂推理等任务时,大模型常常需要处理数十万乃至上百万 token 的输入数据。
然而,直接扩大模型上下文窗口会带来极高的计算和内存开销,导致“百万级上下文”模型难以实际部署与广泛应用。
为应对这一挑战,研究团队提出 Glyph ——一种基于视觉化输入的新型上下文扩展范式。
不同于依赖修改注意力机制的传统方案,Glyph 从输入表征层面重构问题本质:
将原始文本转换为图像输入,利用视觉-语言模型(VLM)进行读取与理解,实现在不增加模型原生上下文容量的前提下,完成对超长文本的有效建模。
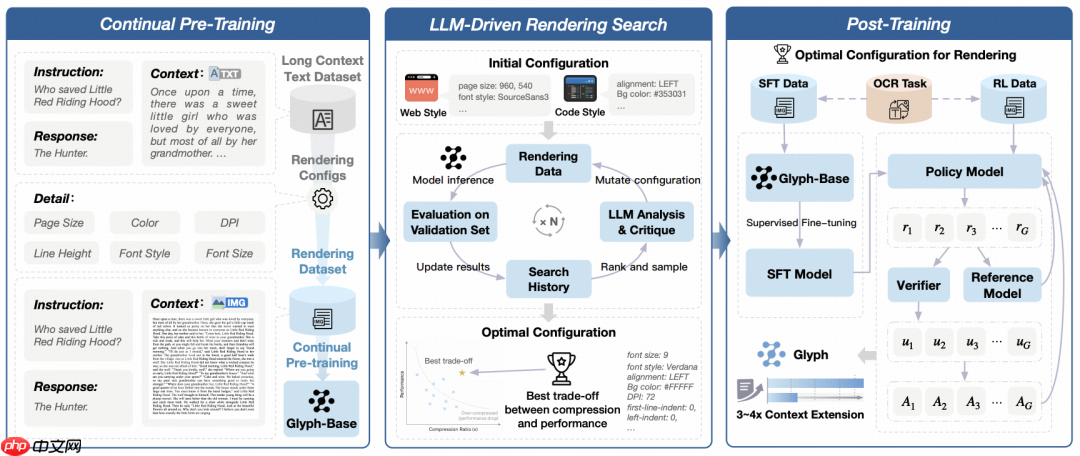
Glyph 的核心理念是让模型学会“用眼睛阅读”超长文本。通过将文字内容渲染成图像,模型可在有限 token 预算下接收更密集的信息流,达成高效的语义压缩。整个系统包含三个关键阶段:
持续预训练阶段
研究人员将大量长文本数据渲染为多种视觉样式,涵盖文档排版、网页布局、代码展示等多种真实场景。基于这些图像化文本,构建包括 OCR 识别、图文联合建模、视觉补全在内的多样化任务,帮助模型同时掌握字符的视觉特征与其深层语义。此阶段强化了跨模态对齐能力,使模型能准确“读懂”图像中的文字内容。
**LLM驱动的渲染策略搜索
不同的渲染参数(如字体大小、行距、分辨率、布局方式)会显著影响模型的理解效果与压缩效率。为此,团队设计了一种基于大语言模型引导的遗传搜索算法****。该方法在验证集上评估不同配置的表现,由 LLM 分析结果并生成改进方案,经过多轮迭代后自动收敛至最优渲染策略,在压缩率与语义保真之间达到最佳平衡。
后训练优化阶段
确定最优渲染方式后,模型进入精细化调优阶段,采用有监督微调(SFT)结合 GRPO 强化学习算法进行优化。同时引入OCR辅助学习任务,进一步增强模型对细粒度文本结构的识别与理解能力。
Glyph 标志着一种融合视觉与语言的上下文扩展新范式的诞生。
通过三阶段协同训练,Glyph 实现了在 3–4倍文本压缩率 下仍保持强劲的任务表现,并大幅提升了训练与推理效率。
在极端压缩条件下,仅使用 128K 上下文的视觉模型,即可成功处理 百万 token 级别的文本任务,展现出强大的扩展潜力,也为未来迈向千万级上下文的智能系统奠定了坚实基础。
源码地址:点击下载
以上就是智谱提出 Glyph:通过视觉-文本压缩扩展上下文窗口的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。




Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 911
911





















