






本文为PaddleRS实现变化检测提供保姆级教程,涵盖数据组织、模型训练到推理应用全流程。其贡献包括独家的变化检测数据集切片代码、数据列表生成、推理示例,还详解配置文件参数。介绍了PaddleRS及变化检测任务特殊性,浅析相关网络架构与训练文件,补全套件功能,最后展示结果,助力新手掌握全流程。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

PaddleRS 手把手教你PaddleRS实现变化检测
在官方详细教程发布前,可参考本保姆级教程,从数据组织、模型训练到推理应用,让你一键跑通,纵享丝滑
本项目主要贡献:
- 提供了变化检测数据集的切片代码,对文件夹下所有数据切片,并且克隆文件夹结构,训练集、验证集、测试集一键搞定,目前全网独家
- 组织PaddleRS变化检测所需要的数据列表,生成train.txt等,目前全网独家
- 训练好之后的推理示例,实例化网络,加载权重,使用paddlers.transofrms,处理图像,推理得到结果的例子,目前全网独家
- 详细介绍配置文件参数的意义,让新手不再迷茫
- 真正的保姆级全流程教程,不忽略一丝细节

PaddleRS简介
PaddleRS是基于飞桨开发的遥感处理平台,支持遥感图像分类,目标检测,图像分割,以及变化检测等常用遥感任务,帮助开发者更便捷地完成从训练到部署全流程遥感深度学习应用。
项目意义
变化检测任务较为特殊,需要给网络提供前后两个时相的遥感影像与对应label,无基础的用户可能应用困难。
图像分类、目标检测、语义分割三大任务可参考对应的套件,但变化检测没得参考。
本项目应运而生,为国产开源贡献绵薄之力。
网络架构浅析
以cdnet为例,路径:PaddleRS/ paddlers / custom_models / cd / models / cdnet.py
非常简单的三部分:
- 最基础结构是77的卷积层组合:补边,77卷积层,BN层,激活层

- 网络整体结构:9个conv7*7组合,四个下采样,四个上采样,很简单
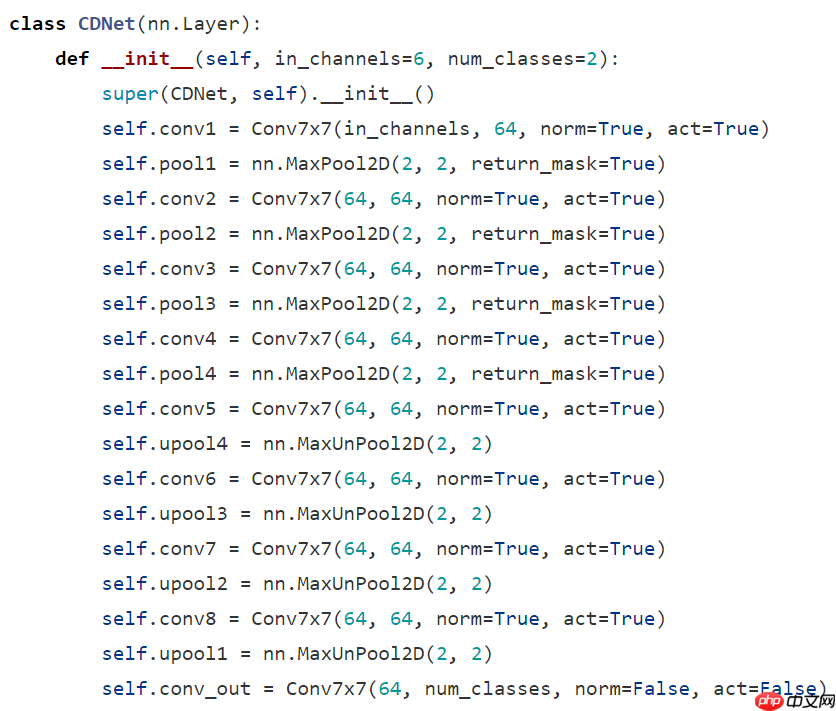
- 传播过程:四次卷积组合+下采样,经过conv5,然后四次上采样,经过conv_out输出,是最基础的FCN结构。唯一需要注意的是第一行,t1与t2进行了cat叠加,拼接成了6通道,之后和普通的3通道输入语义分割网络没有任何区别
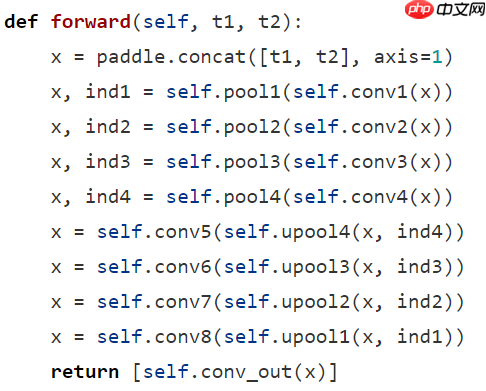
训练文件浅析
以cdnet为例,路径:tutorials/train/change_detection/cdnet_build.py
- 模型实例化:
model = pdrs.tasks.CDNet(num_classes=num_classes, in_channels=6),其中num_classes是读取的label.txt的行数。由num_classes = len(train_dataset.labels)获取。
大部分情况下,变化检测是二分类任务,所以label.txt随便写两行即可,例如:
0
1

- 数据transform,这块没啥好说的,数据读取后,resize到统一尺寸,然后增强,归一化,与其他套件没区别
train_transforms = T.Compose([
T.Resize(target_size=512),
T.RandomHorizontalFlip(),
T.Normalize( mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])- 定义dataset,这个是本文重点,难点问题都出现在这
train_dataset = pdrs.datasets.CDDataset( data_dir='E:/dataFiles/github/PaddleRS/tutorials/train/change_detection/DataSet', file_list='tutorials/train/change_detection/DataSet/train.txt', label_list='tutorials/train/change_detection/DataSet/labels.txt', transforms=train_transforms, num_workers=0, shuffle=True)
- data_dir代表的是存放数据的文件夹,根目录,与file_list和label_list存储位置无关
- train.txt(val.txt)文件中,每一行保存了前时刻影像t1,后时刻影像t2,变化标签lab三个关键内容,分隔符是空格
- 要保证os.path.join(data_dir,t1),os.path.join(data_dir,t2),os.path.join(data_dir,lab)能读取到文件,否则出错
- 如果label是0,255的格式,一定要设置binarize_labels为True(原实例文件中没有),否则报错:ValueError: label should not out of bound, but gotTensor(shape=[1], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
- train.txt还有一种组织形式,前时刻影像t1,后时刻影像t2,变化标签lab,前时刻建筑物标签lab1,后时刻建筑物标签lab2,这种情况下模型不仅做孪生网络,还做语义分割,但是个人不建议用,请相信我的专业=。=
- 开始训练,没啥好说的,一看就明白
model.train( num_epochs=1, train_dataset=train_dataset, train_batch_size=4, eval_dataset=eval_dataset, learning_rate=0.01, pretrain_weights=None, save_dir='output/cdnet')
套件功能补全
- 变化检测数据集切片,spliter-cd.py
保留原数据集结构,work/train,val,text三个文件夹下所有图片一键切片,克隆原数据集目录结构,方便快捷
- split_data_cd(args.image_folder, args.block_size, args.save_folder)是主函数
- args.image_folder数据集根目录,要包含train、val等子文件夹
- args.block_size是切片后的大小
- args.save_folder是切片后存储的文件夹
- 生成文件列表,work/create_list.py
- create_list(args.image_folder, args.A,args.B,args.label, args.save_txt)是主函数
- args.image_folder是根目录
- args.A,args.B,args.label是根目录下T1影像,T2影像,变化label存储的文件夹
- args.save_txt是生成列表的存储路径
- 补全预测代码,work/cdnet_predict.py
- args.weight 训练好的权重
- args.A,args.B,是T1影像路径,T2影像路径
- args.pre 预测图片存储的位置
顺便说个bug !python PaddleRS/setup.py install 会报错 FileNotFoundError: [Errno 2] No such file or directory: 'README.md'
# 准备数据!unzip -oq data/data136610/LEVIR-CD.zip -d data/# 切片!python work/spliter-cd.py --image_folder data/LEVIR-CD --block_size 256 --save_folder dataset# 创建列表!python work/create_list.py --image_folder ./dataset/train --A A --B B --label label --save_txt train.txt !python work/create_list.py --image_folder ./dataset/val --A A --B B --label label --save_txt val.txt !python work/create_list.py --image_folder ./dataset/test --A A --B B --label label --save_txt test.txt
# 准备环境!git clone https://gitee.com/cloudzhangyi/PaddleRS.git !pip install -r PaddleRS/requirements.txt
# 开始训练!cp ./work/cdnet_build_and_train.py PaddleRS/tutorials/train/change_detection !python PaddleRS/tutorials/train/change_detection/cdnet_build_and_train.py
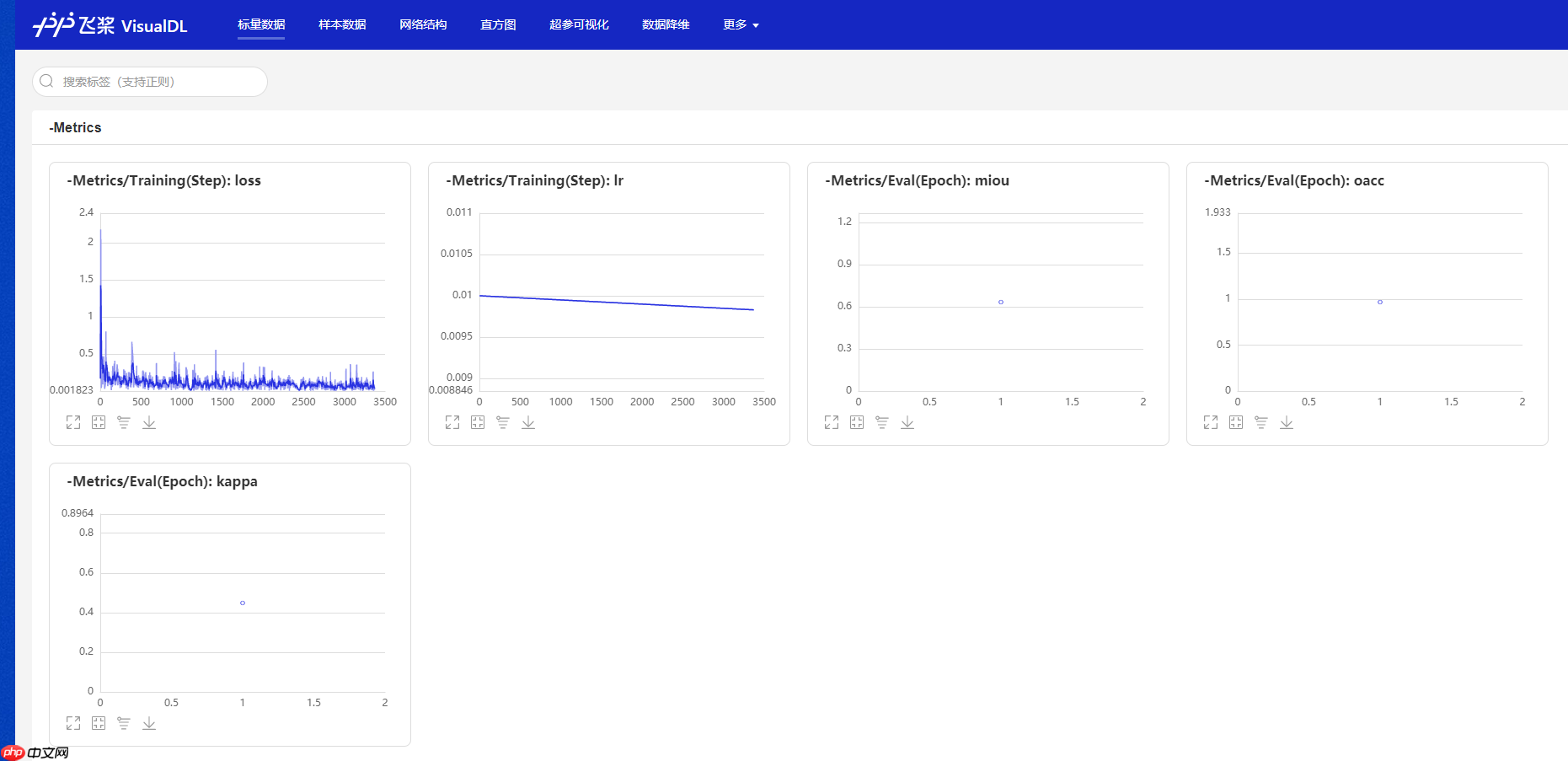
训练曲线可视化
运行上面代码,会产生output/cdnet/vdl_log文件夹,此文件内文件是VisualDL可读取的训练信息
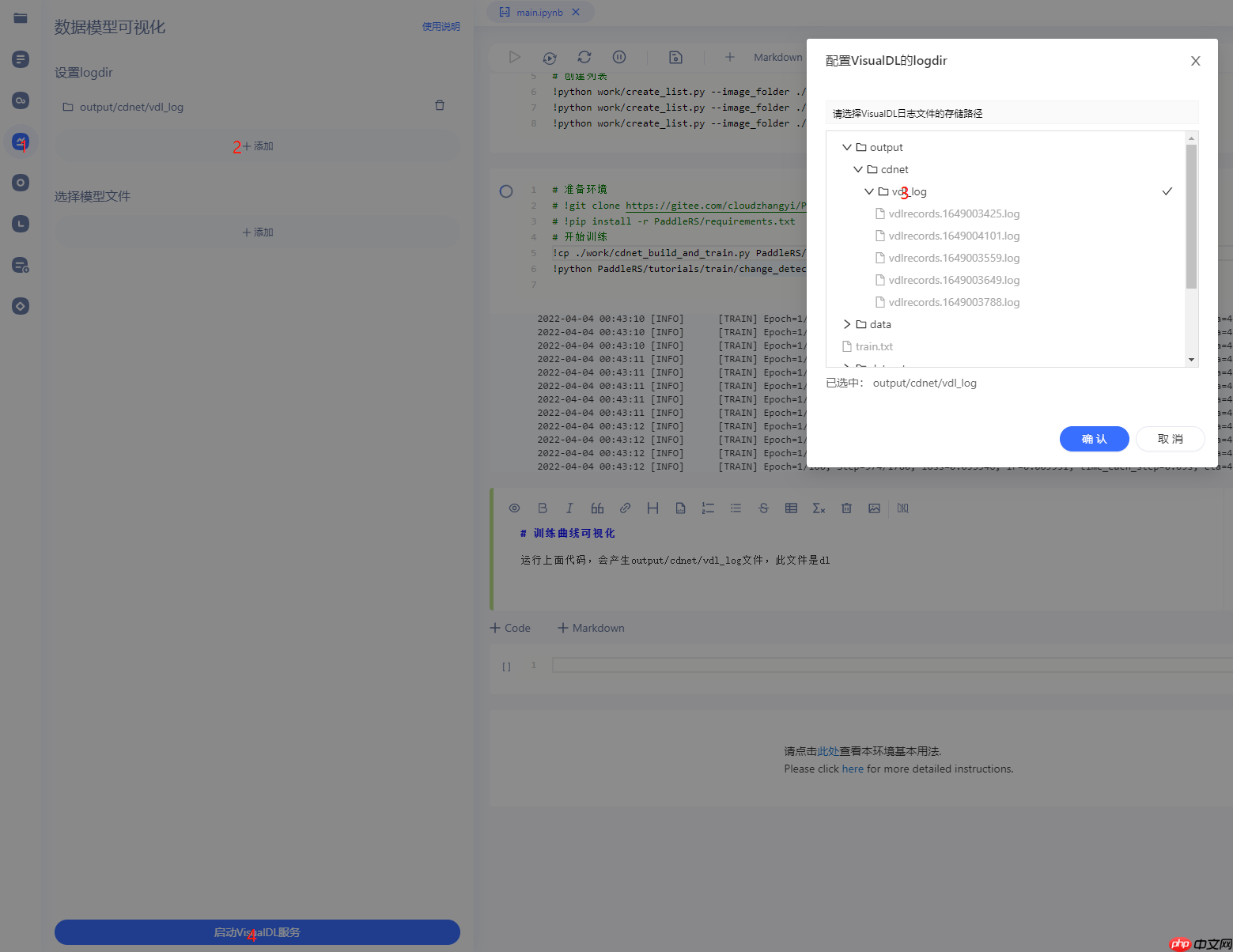
按照上图步骤,启动可视化,查看训练曲线
# 这是你训练的权重,如果你训练充分的话用这个# !python work/cdnet_predict.py --weight output/cdnet/best_model/model.pdparams --A dataset/test/A/test_2_0_0.png --B dataset/test/B/test_2_0_0.png --pre ./work/pre.png# 这是我训练的权重,直接看的话用这个,100个epoch!python work/cdnet_predict.py --weight work/model.pdparams --A dataset/test/A/test_2_0_0.png --B dataset/test/B/test_2_0_0.png --pre ./work/pre.png
结果展示
test数据集中结果展示,从左到右分别是T1,T2,label,prediction,分析图
分析图中:
蓝色:True Positive (真正, TP)被模型预测为正的正样本
绿色:False Positive (假正, FP)被模型预测为正的负样本
红色:False Negative(假负 , FN)被模型预测为负的正样本





毕竟用的最简单的网络,效果并不是很好,训练100个rpoch,验证集最佳F1值在0.85左右
本项目至此结束,希望PaddleRS越做越好。




























