本项目基于PaddlePaddle2.2,在波士顿房价预测案例基础上优化,增加epoch与loss对应图及最低loss时epoch-id函数以找最佳参数,用相关系数评价回归结果。通过数据探索分析、预处理、建模训练、预测等步骤,对比数据打乱与否的效果,揭示机器学习与传统拟合的区别,还包含模型应用及结果可视化。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

PaddlePaddle拥有强大的大数据处理能力。
paddle.nn 目录下包含飞桨框架支持的神经网络层和相关函数的相关API。
https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/nn/Overview_cn.html#juanjiceng

应用paddle.nn 可以构建数据回归模型,进行大数据分析。
本项目基于PaddlePaddle2.2在预测波士顿房价的案例基础上,增加了epoch与loss的对应图以及求最低loss时epoch-id的函数,从而找到最佳的模型参数,为建模调参提供帮助。
预测波士顿房价的案例连接如下:https://www.paddlepaddle.org.cn/documentation/docs/zh/practices/quick_start/linear_regression.html
此外,本项目使用相关系数对回归结果进行评价。
import paddleimport numpy as npimport osimport matplotlibimport matplotlib.pyplot as pltimport pandas as pdimport seaborn as snsimport warnings
warnings.filterwarnings("ignore")print(paddle.__version__)#下载数据!wget https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data -O housing.data
# 从文件导入数据datafile = './housing.data'housing_data = np.fromfile(datafile, sep=' ') feature_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE','DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV'] feature_num = len(feature_names)# 将原始数据进行Reshape,变成[N, 14]这样的形状housing_data = housing_data.reshape([housing_data.shape[0] // feature_num, feature_num])
数据建模前,需要对数据进行探索性分析。
探索性分析主要是通过数据可视化(绘图)以及相关性分析来了解数据规律(自变量和因变量的函数关系)
# 画图看特征间的关系,主要是变量两两之间的关系(线性或非线性,有无明显较为相关关系)features_np = np.array([x[:13] for x in housing_data], np.float32)
labels_np = np.array([x[-1] for x in housing_data], np.float32)
df = pd.DataFrame(housing_data, columns=feature_names)
matplotlib.use('TkAgg')
%matplotlib inline
sns.pairplot(df.dropna(), y_vars=feature_names[-1], x_vars=feature_names[::1], diag_kind='kde')
plt.show()# 相关性分析fig, ax = plt.subplots(figsize=(15, 1)) corr_data = df.corr().iloc[-1] corr_data = np.asarray(corr_data).reshape(1, 14) ax = sns.heatmap(corr_data, cbar=True, annot=True) plt.show()
在数据回归时,若数据数值差异太大,会导致模型参数不收敛。因此需要对数据进行归一化处理。
本项目只对属性值(自变量)进行归一化处理,房价(因变量)没有归一化。
注意:若对房价(因变量)进行了数据预处理,计算结果务必进行数据逆处理,否则会导致预测值和原值差异极大,严重时模型参数无法收敛
#归一化前,数据数值差异极大sns.boxplot(data=df.iloc[:, 0:13])
#定义归一化方法features_max = housing_data.max(axis=0)
features_min = housing_data.min(axis=0)
features_avg = housing_data.sum(axis=0) / housing_data.shape[0]def feature_norm(input):
f_size = input.shape
output_features = np.zeros(f_size, np.float32) for batch_id in range(f_size[0]): for index in range(13):
output_features[batch_id][index] = (input[batch_id][index] - features_avg[index]) / (features_max[index] - features_min[index]) return output_features# 只对属性进行归一化housing_features = feature_norm(housing_data[:, :13])# print(feature_trian.shape)housing_data = np.c_[housing_features, housing_data[:, -1]].astype(np.float32)# print(training_data[0])
# 归一化后的train_data, 看下各属性的情况features_np = np.array([x[:13] for x in housing_data],np.float32) labels_np = np.array([x[-1] for x in housing_data],np.float32) data_np = np.c_[features_np, labels_np] df = pd.DataFrame(data_np, columns=feature_names) sns.boxplot(data=df.iloc[:, 0:13])
# 将训练数据集和测试数据集按照8:2的比例分开ratio = 0.8offset = int(housing_data.shape[0] * ratio) train_data = housing_data[:offset] test_data = housing_data[offset:]
每批次投入的数据量越多,模型回归的计算量变大,计算速度变小,无法收敛的可能性也增大。
但若每批次投入的数据量过少,那么模型的准确度会变差。
# 确定每轮训练过程中,每批次投入的数据量bratio=0.2 #数据投喂比例BATCH_SIZE = int(len(train_data)*bratio)
paddle.nn 目录下包含飞桨框架支持的神经网络层和相关函数的相关API。
https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/nn/Overview_cn.html#juanjiceng
替换、增加、减少paddle.nn 的函数,调节函数中的参数,都会改变数据模型,而数据模型决定了预测的准确度。
import paddleimport paddle.nn.functional as Fclass LeNet(paddle.nn.Layer):
def __init__(self):
super(LeNet, self).__init__() # 形状变换,将数据形状从多维变为1维度
#self.flatten = paddle.nn.Flatten()
# 第一个全连接层
self.linear1 = paddle.nn.Linear(in_features=13, out_features=10)# # 使用ReLU激活函数
self.act1 = paddle.nn.Softplus()# # 第二个全连接层
self.linear2 = paddle.nn.Linear(in_features=10, out_features=1)# # 使用ReLU激活函数
#self.act2 = paddle.nn.ReLU()# # 第三个全连接层
#self.linear3 = paddle.nn.Linear(in_features=20, out_features=1)
def forward(self, x):
#x = self.flatten(x)
x = self.linear1(x)
x = self.act1(x)
x = self.linear2(x) #x = self.act2(x)
#x = self.linear3(x)
return x
model = LeNet()#设置模型的优化方法optimizer = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
利用数据训练集的房价(因变量)和归一化后的属性值(自变量)进行模型训练。
把自变量代入模型函数,计算出预测值,然后计算出预测值和真实值的均方差(mse_loss),并据此使用优化器对模型参数进行优化。
import paddle.nn.functional as F
y_preds = []
labels_list = []
train_nums = []
train_costs = []def train(model):
print('start training ... ') # 开启模型训练模式
model.train()
EPOCH_NUM = 500 #设置训练轮数
train_num = 0
for epoch_id in range(EPOCH_NUM): # 在每轮迭代开始之前,将训练数据的顺序随机的打乱
np.random.shuffle(train_data) # 将训练数据进行拆分,每个batch包含BATCH_SIZE条数据
mini_batches = [train_data[k: k+BATCH_SIZE] for k in range(0, len(train_data), BATCH_SIZE)] for batch_id, data in enumerate(mini_batches):
features_np = np.array(data[:, :13], np.float32)
labels_np = np.array(data[:, -1:], np.float32)
features = paddle.to_tensor(features_np)
labels = paddle.to_tensor(labels_np)
# 前向计算
y_pred = model(features)
cost = F.mse_loss(y_pred, label=labels)#默认reduction='mean'
train_cost = cost.numpy()[0] # 反向传播
cost.backward() # 最小化loss,更新参数
optimizer.step() # 清除梯度
optimizer.clear_grad()
if epoch_id%5 == 0: #训练轮数为500,每5轮保存一次参数
print("Pass:%d,Cost:%0.5f"%(epoch_id, train_cost)) # save state_dict
paddle.save(model.state_dict(),'./checkpoint/epoch{}.pdparams'.format(epoch_id))
paddle.save(optimizer.state_dict(),'./checkpoint/epoch{}.pdopt'.format(epoch_id))
train_num = train_num + BATCH_SIZE
train_nums.append(train_num)
train_costs.append(train_cost)
train(model)绘制模型训练过程图
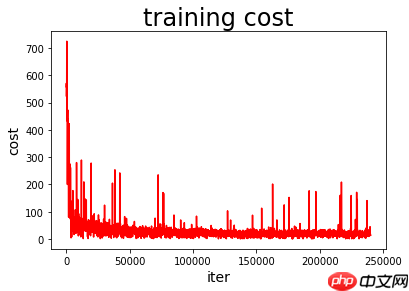
def draw_train_process(iters, train_costs):
plt.title("training cost", fontsize=24)
plt.xlabel("iter", fontsize=14)
plt.ylabel("cost", fontsize=14)
plt.plot(iters, train_costs, color='red', label='training cost')
plt.show()
matplotlib.use('TkAgg')
%matplotlib inline
draw_train_process(train_nums, train_costs)本项目把保存的参数依次加载到模型,然后用模型及相应参数对测试数据集进行回归效果评价。
评价指标包括预测值和真实值的均方差(mean_loss)和预测值和真实值的相关系数(corr)
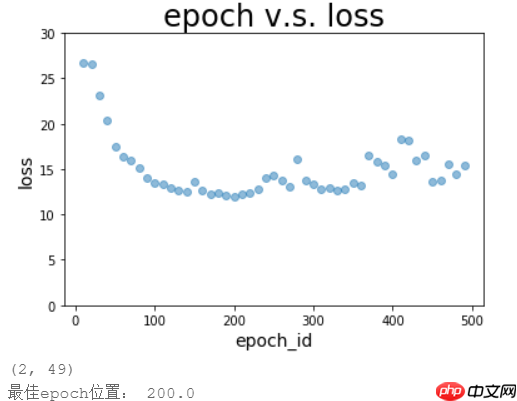
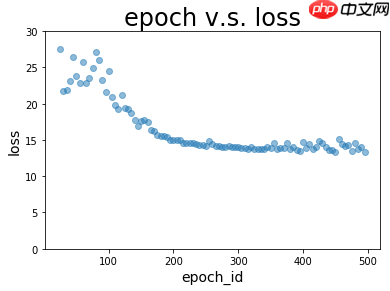
通过绘制epoch v.s. loss图以及epoch v.s. corr图,直观查看训练过程中loss和corr的变化
通过寻找最低loss的函数记录最佳的epoch_id,并保存到最佳参数目录
通过寻找最高corr的函数记录最佳的epoch_id,并保存到最佳参数目录
#对测试数据集的预测结果进行评价batch=[]
loss=[]
corr=[]for batch_id in range(0,500,5):#训练轮数为500,每5轮保存一次参数
# 加载模型参数
layer_state_dict = paddle.load('checkpoint/epoch{}.pdparams'.format(batch_id))
opt_state_dict = paddle.load('checkpoint/epoch{}.pdopt'.format(batch_id))
optimizer = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
model.set_state_dict(layer_state_dict)
optimizer.set_state_dict(opt_state_dict)
# 获取预测数据
INFER_BATCH_SIZE = 100 #len(test_data)
infer_features_np = np.array([data[:13] for data in test_data]).astype("float32")
infer_labels_np = np.array([data[-1] for data in test_data]).astype("float32")
infer_features = paddle.to_tensor(infer_features_np)
infer_labels = paddle.to_tensor(infer_labels_np)
fetch_list = model(infer_features)
sum_cost = 0
for i in range(INFER_BATCH_SIZE):
infer_result = fetch_list[i][0]
ground_truth = infer_labels[i] #if i % 10 == 0:
#print("No.%d: infer result is %.2f,ground truth is %.2f" % (i, infer_result, ground_truth))
cost = paddle.pow(infer_result - ground_truth, 2)
sum_cost += cost
mean_loss = sum_cost / INFER_BATCH_SIZE #计算均方差
x = pd.Series(np.array(fetch_list.flatten()).tolist()) #利用Series将列表转换成新的、pandas可处理的数据
y = pd.Series(infer_labels_np.tolist())
xycorr = round(x.corr(y), 4) #计算相关系数,round(a, 4)是保留a的前四位小数
print("epoch_id:%d, Mean loss is:%.4f, corr is:%.4f"%(batch_id, mean_loss.numpy(),xycorr)) if mean_loss.numpy()<30 :
batch=np.append(batch,batch_id)
loss=np.append(loss,mean_loss.numpy())
corr=np.append(corr,xycorr)#绘制epoch v.s. loss图def plot_epoch_loss(batch, loss):
plt.figure()
plt.title("epoch v.s. loss", fontsize=24)
plt.xlabel("epoch_id", fontsize=14)
plt.ylabel("loss", fontsize=14)
plt.ylim(0,30)
plt.scatter(batch, loss, alpha=0.5) # scatter:散点图,alpha:"透明度"
#plt.plot(ground, ground, c='red')
plt.show()#绘制epoch v.s. corr图def plot_epoch_corr(batch, corr):
plt.figure()
plt.title("epoch v.s. corr", fontsize=24)
plt.xlabel("epoch_id", fontsize=14)
plt.ylabel("corr", fontsize=14)
plt.ylim(0,1)
plt.scatter(batch, corr, alpha=0.5) # scatter:散点图,alpha:"透明度"
#plt.plot(ground, ground, c='red')
plt.show()plot_epoch_loss(batch, loss) #绘图zuijia=int(batch[loss.tolist().index(min(loss))]) #记录最佳位置print ('loss最佳epoch位置:',zuijia)
plot_epoch_corr(batch, corr) #绘图zuijia2=int(batch[corr.tolist().index(max(corr))]) #记录最佳位置print ('corr最佳epoch位置:',zuijia2)#创建用于保存最佳epoch_id的文件夹import osimport datetime# 下面列举三种格式# 年-月-日 时:分:秒nowTime=datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')# 年-月-日dayTime = datetime.datetime.now().strftime('%Y-%m-%d')# 时:分:秒hourTime = datetime.datetime.now().strftime('%H:%M:%S')# 指定文件路径file_path = 'best model{}'.format(nowTime) # 此处也可以使用nowTime或hourTime,看你想使用哪种格式了。# 判断文件夹是否已存在isExists = os.path.exists(file_path)if not isExists:
os.makedirs(file_path ) # 若包含多级文件夹就使用makedirs,只有一个文件夹可以使用mkdirfrom shutil import copy #shutil 是用来复制黏贴文件的copy('checkpoint/epoch{}.pdparams'.format(zuijia), file_path)#完成复制黏贴copy('checkpoint/epoch{}.pdopt'.format(zuijia), file_path)#完成复制黏贴copy('checkpoint/epoch{}.pdparams'.format(zuijia2), file_path)#完成复制黏贴copy('checkpoint/epoch{}.pdopt'.format(zuijia2), file_path)#完成复制黏贴导入需要应用模型进行预测的数据
对导入的数据按第5部分的预处理方法进行预处理
加载模型的最佳参数,对数据进行预测,评估预测结果
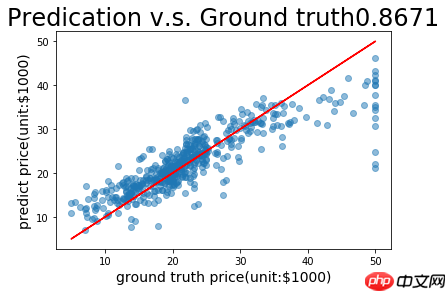
把预测值和实际值进行可视化处理
# 从文件导入应用数据datafile = './yingyong.data'yingyong_data = np.fromfile(datafile, sep=' ') feature_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE','DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV'] feature_num = len(feature_names)# 将原始数据进行Reshape,变成[N, 14]这样的形状yingyong_data = yingyong_data.reshape([yingyong_data.shape[0] // feature_num, feature_num])#!!归一化程序务必与第5部分所使用的完全一致!!只对属性进行归一化yingyong_features = feature_norm(yingyong_data[:, :13]) # print(feature_trian.shape)yingyong_data = np.c_[yingyong_features, yingyong_data[:, -1]].astype(np.float32)# print(training_data[0])
# load 最佳的参数batch_id=zuijia #zuijia1 !!!根据显示的epoch位置调整!!!layer_state_dict = paddle.load('best model2021-11-19 12:17:58/epoch270.pdparams')#layer_state_dict = paddle.load('checkpoint/epoch{}.pdparams'.format(batch_id))opt_state_dict = paddle.load('checkpoint/epoch{}.pdopt'.format(batch_id))
model.set_state_dict(layer_state_dict)
optimizer.set_state_dict(opt_state_dict)
# 获取预测数据INFER_BATCH_SIZE = len(yingyong_data)
infer_features_np = np.array([data[:13] for data in yingyong_data]).astype("float32")
infer_labels_np = np.array([data[-1] for data in yingyong_data]).astype("float32")
infer_features = paddle.to_tensor(infer_features_np)
infer_labels = paddle.to_tensor(infer_labels_np)
fetch_list = model(infer_features)
sum_cost = 0for i in range(INFER_BATCH_SIZE):
infer_result = fetch_list[i][0]
ground_truth = infer_labels[i] if i % 1 == 0: print("No.%d: infer result is %.2f,ground truth is %.2f" % (i, infer_result, ground_truth))
cost = paddle.pow(infer_result - ground_truth, 2)
sum_cost += cost
mean_loss = sum_cost / INFER_BATCH_SIZEprint("Mean loss is:", mean_loss.numpy())x = pd.Series(np.array(fetch_list.flatten()).tolist()) #利用Series将列表转换成新的、pandas可处理的数据y = pd.Series(infer_labels_np.tolist())
xycorr = round(x.corr(y), 4) #计算标准差,round(a, 4)是保留a的前四位小数
print('相关系数 :', xycorr)def plot_pred_ground(pred, ground):
plt.figure()
plt.title("Predication v.s. Ground truth"+ str(xycorr), fontsize=24)
plt.xlabel("ground truth price(unit:$1000)", fontsize=14)
plt.ylabel("predict price(unit:$1000)", fontsize=14)
plt.scatter(ground, pred, alpha=0.5) # scatter:散点图,alpha:"透明度"
plt.plot(ground, ground, c='red')
plt.show()
plot_pred_ground(fetch_list, infer_labels_np)使用此研究助手,本人对比了“在每轮迭代开始之前,将训练数据的顺序随机的打乱 np.random.shuffle(train_data)”与否的效果,进一步明白了机器学习与传统数据拟合的区别。
若对训练数据的顺序不进行随机的打乱,那么程序进行的是传统的数据拟合操作,随着程序的运行,均方差loss不断减小,说明拟合准确度在不断提高,但当加载模型及参数对测试集进行预测时,看到预测集中loss很大,且变化幅度很大。


若对训练数据的顺序进行随机的打乱,那么程序进行的是机器学习过程,随着程序的运行,均方差loss呈现波动下降趋势,这是因为每一次打乱顺序都会对loss造成脉冲,但经优化后loss仍会逐步下降。当加载模型及参数对测试集进行预测时,看到预测集中loss很小,且存在变化不大的区间。
以上就是基于PaddlePaddle2.2的数据建模研究助手的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号







 587
587

























