






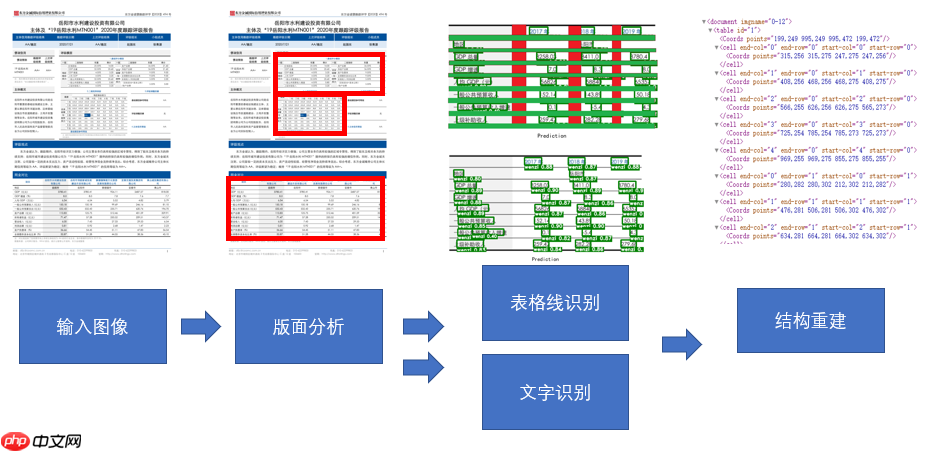
技术方向:表格文字检测,表格结构重建 使用了Paddlex的detection; 引用了Paddle segmentation 的Unet结构,自定义训练 同花顺-文档图片表格结构识别算法方。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

1、比赛介绍
整体背景
表格作为一种高效的数据组织与展现方法被广泛应用,已成为各类文档中最常见的页面对象。目前很大一部分文档以图片的形式存在,无法直接获取表格信息。人工还原表格既费时又容易出错,因此如何自动并准确地从文档图片中识别出表格成为一个亟待解决的问题。但由于表格大小、种类与样式的复杂多样(例如表格中存在不同的背景填充、不同的行列合并方法、不同的分割线类型等),导致表格识别一直是文档识别领域的研究难点。
本赛题专注于表格结构识别,为选手提供了已标注的表格图片数据,需要选手通过深度学习的方法,识别出表格结构并输出。
- 赛题任务
选手需要训练模型并准确还原出表格结构信息。
训练数据主要包括原始图片及对应的ground truth,ground truth内包含表格位置信息和单元格信息。选手可以直接使用ground truth内的表格位置信息,也可以使用自己预测的表格位置信息。在得到表格区域的基础上,选手需要将表格的结构识别出来,输出单元格的行列结构信息及单元格内的文字位置信息。
- 数据说明
数据量
640张训练集、106张测试集A、108张测试集B及其对应的ground truth(xml文件)
数据来源
各大公司财报的扫描件图片、评级报告图片
ground truth字段说明:
table:表格,包含表格位置信息及该表格内的单元格信息。points字段为“x0, y0 x1, y1 x2,y2 x3, y3”格式,表示表格区域的四个角点,角点顺序不固定
cell:单元格,包含行列信息及位置信息
start_col、end_col、start_row、end_row:单元格所处的行列信息
points:单元格内文本的位置信息,格式为“x0, y0 x1, y1 x2,y2 x3, y3”,表示文本区域的四个角点,角点顺序不固定;当单元格内存在多行文本时,取所有文本的最小外包矩形作为文本区域
- ground truth示例如下:

- 评测标准
a. 总体概括评测标准
- 单元格F1
b. 评价指标计算流程
- 计算预测的表格内的单元格的相邻关系,假设所有预测的表格内的单元格相邻关系的总数为S
参考论文:
《A Methodology for Evaluating Algorithms for Table Understanding in PDF Documents》
将预测的表格区域与ground truth中的表格区域进行映射,取IOU大于0.8的表格区域作为预测正确的表格区域,其余作为预测错误的表格区域
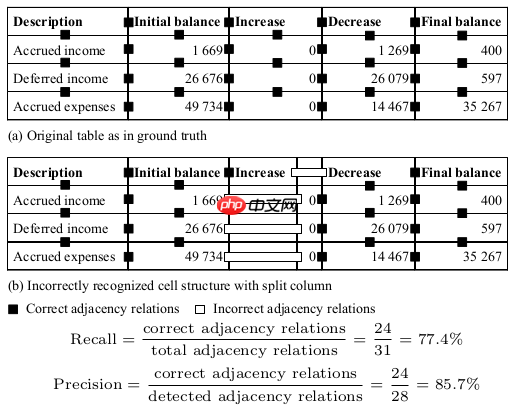
在正确的表格区域内,将预测的单元格内的文本区域与ground truth中的单元格文本区域进行映射,取IOU的阈值为0.5和0.6;当单元格内存在多行文本时,所有文本的最小外包矩形作为文本区域,参考下图:
2、官方baseline介绍
导航链接
- 思路简介:
- 分为两个模型,一个为文字定位模型,另一个是表格结构分析模型。
- 文字定位方案是CRAFT: Character-Region Awareness For Text detection,论文,采用VGG16做文字定位。原方案中直接拿来用,全图检测文字,在此不做过多描述。
- 表格可以通过xml文件获取边界框,不需要检测
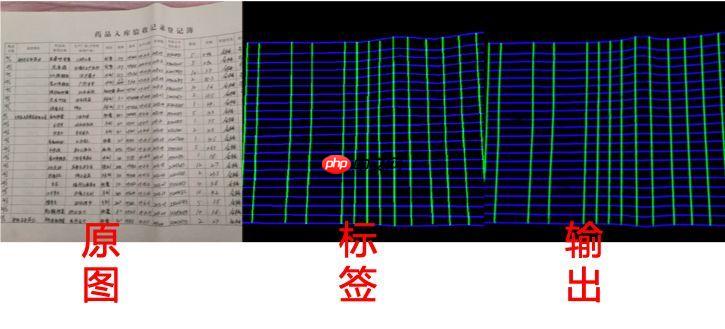
- 表格结构分析基于unet语义分割模型来做,生成两个图层,分别是表格的横向线和纵向线(有线表格和无线表格都按照有线处理)。拼接进行展示,从左到右依次是横向线、纵向线、表格图像,效果如下:

- 分割完成后,表格被横纵线条阶段,用opencv找矩形,还原行列结构,形成cell列表,示意图如下:
- 以cell为单位,遍历每个文字对象的中心点是否落在本cell中,若中心点在cell中,将四个角点坐标都加入列表L,遍历完成后,取L中所有点的最小外接矩形作为文本框的坐标框
3、比赛解题思路的探讨
表格结构化这一任务,在研究领域依然充满了挑战,并未出现一个算法或一套框架一统江湖。结合本比赛,简要进行难点剖析,提出改进思路 当前所有表格结构化方法大体都可分为三步走:
- 提取行列特征
- 提取文字内容
- 重构表格结构
在此框架下,具有不同的技术方案,例如:
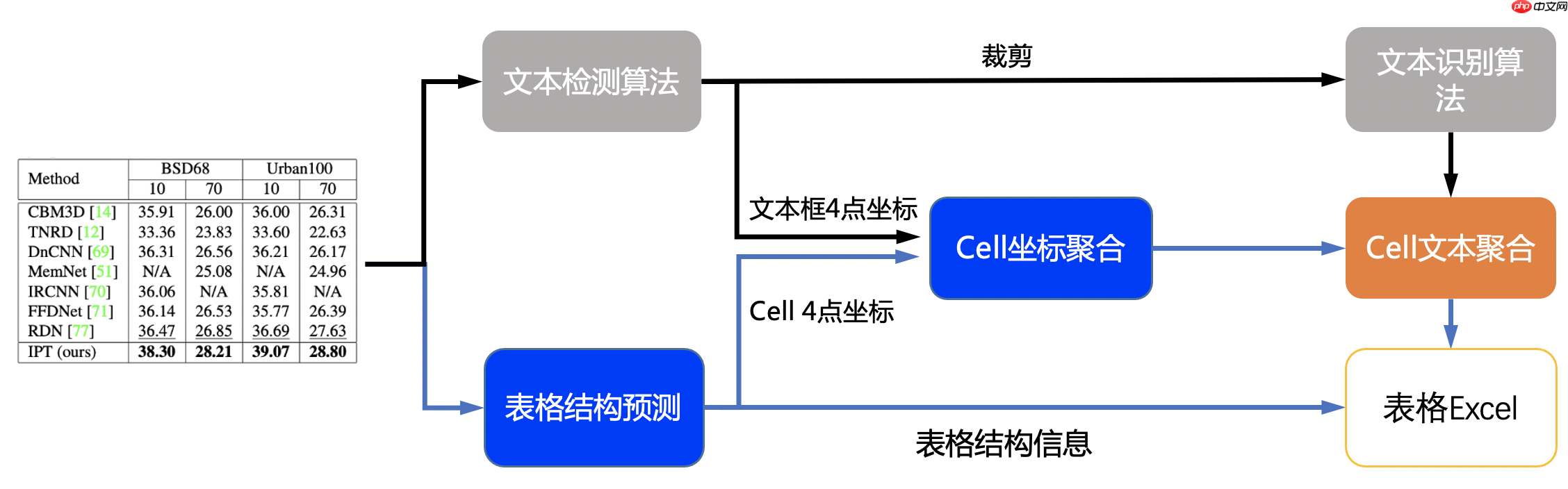
百度OCR表格识别的技术方案:单行文本检测-DB,单行文本识别-CRNN,表格结构和cell坐标预测-RARE

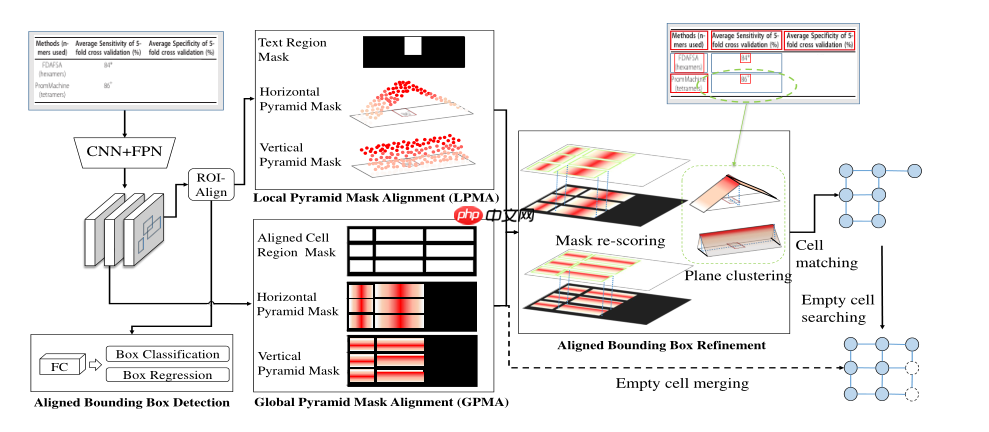
海康威视OCR/表格识别方案: 图像经过CNN提取特征后分成两路,一路类似于Mask RCNN的形式用来检测非空单元格叫LPMA,另一个头全局学习整张图上的非空单元格的水平和垂直对齐的soft mask叫GPMA
腾讯的解决方案:Unet做语义分割,线段合并,矫正等后处理,文字识别,文字定位,对齐
GFTE:Graph-based Financial Table Extraction图神经网络方案:单元格上构建无向图G = 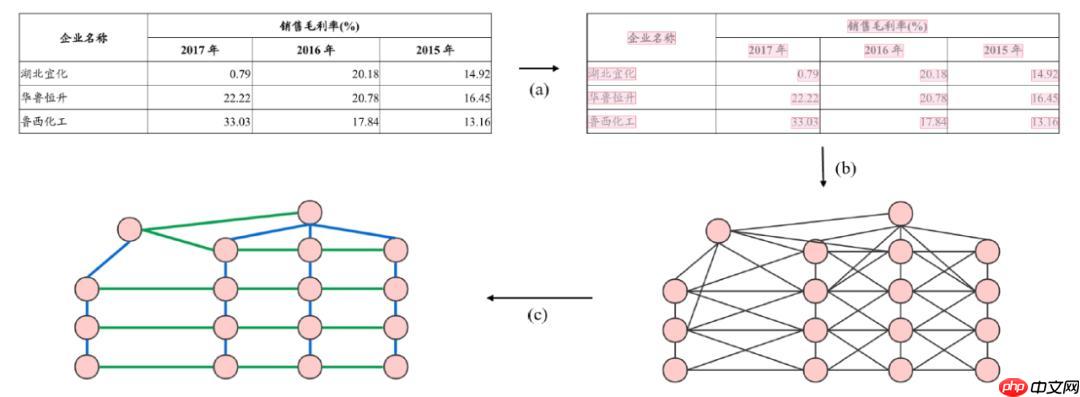
本解决方案属于基于语义分割的模式进行预测
4、赛题难点分析与应对策略
- 数据标签获取
- 通过手绘的方式来获取;
优点:准确;缺点:耗时 1300+表格,标注需30小时+
- 代码方式获取,例如官方文档中mask逻辑:
(1)获取未被合并的单元格,提取其中文字坐标框
(2)将每一列所有坐标框形成一个集合,求其外接矩形
(3)所得矩形之间的区域,划分为表格线
优点:快速;缺点:对错切、错标注、整行整列合并的情况,无法正常生成标注,如下图第一列漏标:
无法得到优质的样本库,漏标多,仅能处理无单元格合并的简单表格
- 语义分割网络与本任务目标存在差距
表格结构化,目标是得到包含行列的结构化数据,而语义分割的结果是基于像素的栅格数据,是非结构化的,语义分割的结果转换为表格结构存在着语义鸿沟,简单的形状提取难以很好的完成此任务。例如下图:


在识别情况尚可的情况下,左侧小块的误识别区域将对整个表格结构产生极大的影像(五列变为六列),而这种情况是无法被处理的
应对策略:
- 人工数据清洗
对数据进行可视化后人工判读,花费三小时,清洗出以下有问题的数据:
- 确保子样本库正确,迁移到大样本库中
先把简单的表格找出来,形成高质量的子样本库,训练模型1
模型1预测复杂结构的表格,生成伪标签,与原代码生成标签叠加,补漏
- 采用二次识别的模式剔除误识别区域;或探索图神经网络在表格误识别中的应用
本人才疏学浅,GCN没做过=。=
5、本项目所做的工作
- 替换CRAFT,使用ppyplov2定位文字
- 自定义数据集,paddlesegAPI实现Une-tattention实现语义分割,代替pytorch版本
- 数据预处理等工作,可完整的实现从数据到提交文件的全流程
6、代码实现
准备环境、数据、训练预测等代码 代码简洁,已配置好,一键运行
# 解压数据集,data/data133551/data.zip为原版数据集,已划分为训练集验证集,后期训练可再调整!unzip -oq data/data133551/data.zip -d work/# data/data133260/data.zip为预处理数据集,只有表格数据,已转化为icdar格式,可直接用paddle——ocr套件训练
# 安装环境!pip install paddleseg !pip install paddlex %cd work/
# 训练分割模型!python seg_train.py
预测生成提交结果
使用预训练的目标检测模型与分割模型完成预测(训练过程未包含在项目)
- 预训练模型目标检测效果

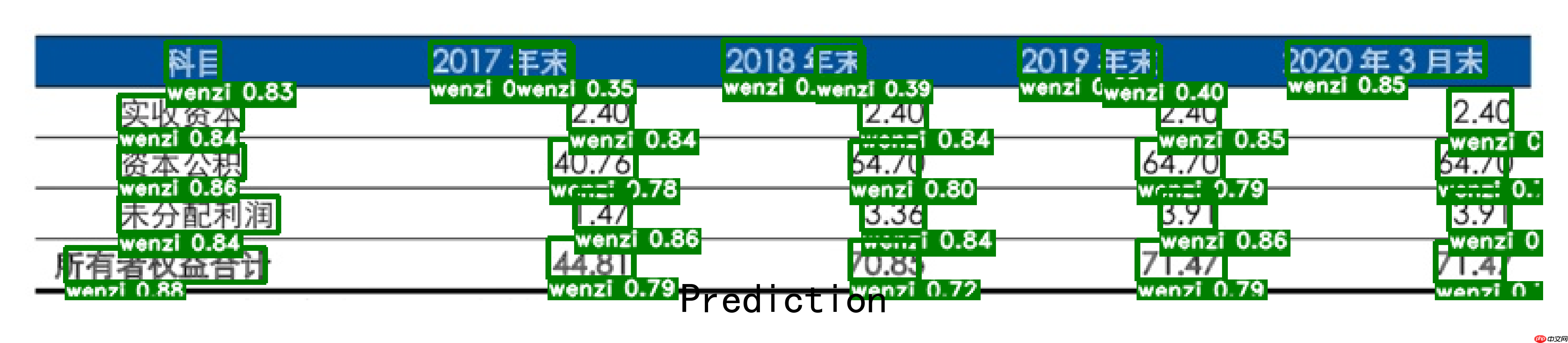
所有步骤都集成在pre.py中
运行pre.py,结果保存在opt中




























