本教程将分别讲解实现该项目使用到的主要组件,以及如何进行数据处理,如何使用 Paddlerec 实现模型 MIND 的训练和测试,最后还提供了如何通过训练好的模型 MIND 和 Milvus 启动一个召回服务。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

本教程基于 PaddleRec 实现的模型 MIND 和向量数据库 Milvus 来搭建一个商品召回系统。
本教程将分别讲解实现该项目使用到的主要组件,以及如何进行数据处理,如何使用 Paddlerec 实现模型 MIND 的训练和测试,最后还提供了如何通过训练好的模型 MIND 和 Milvus 启动一个召回服务。Milvus 是一款开源向量数据库,用于赋能 AI 应用和向量相似度搜索。
Milvus 提供以下 2 个版本:
Milvus 2.0 是一款云原生向量数据库,采用存储与计算分离的架构设计。
整个系统分为四个层面:
接入层(Access Layer): 系统的门面,包含了一组对等的 proxy 节点。接入层是暴露给用户的统一 endpoint,负责转发请求并收集执行结果。
协调服务(Coordinator Service): 系统的大脑,负责分配任务给执行节点。总共有四类协调者角色,分别为 root 协调者、data 协调者、query 协调者和 index 协调者。
执行节点(Worker Node): 系统的四肢。执行节点只负责被动执行协调服务发起的读写请求。目前有三类执行节点,即 data 节点、query 节点和 index 节点。
存储服务(Storage): 系统的骨骼,是所有其他功能实现的基础。Milvus 依赖三类存储:元数据存储、消息存储(Log Broker)和对象存储。
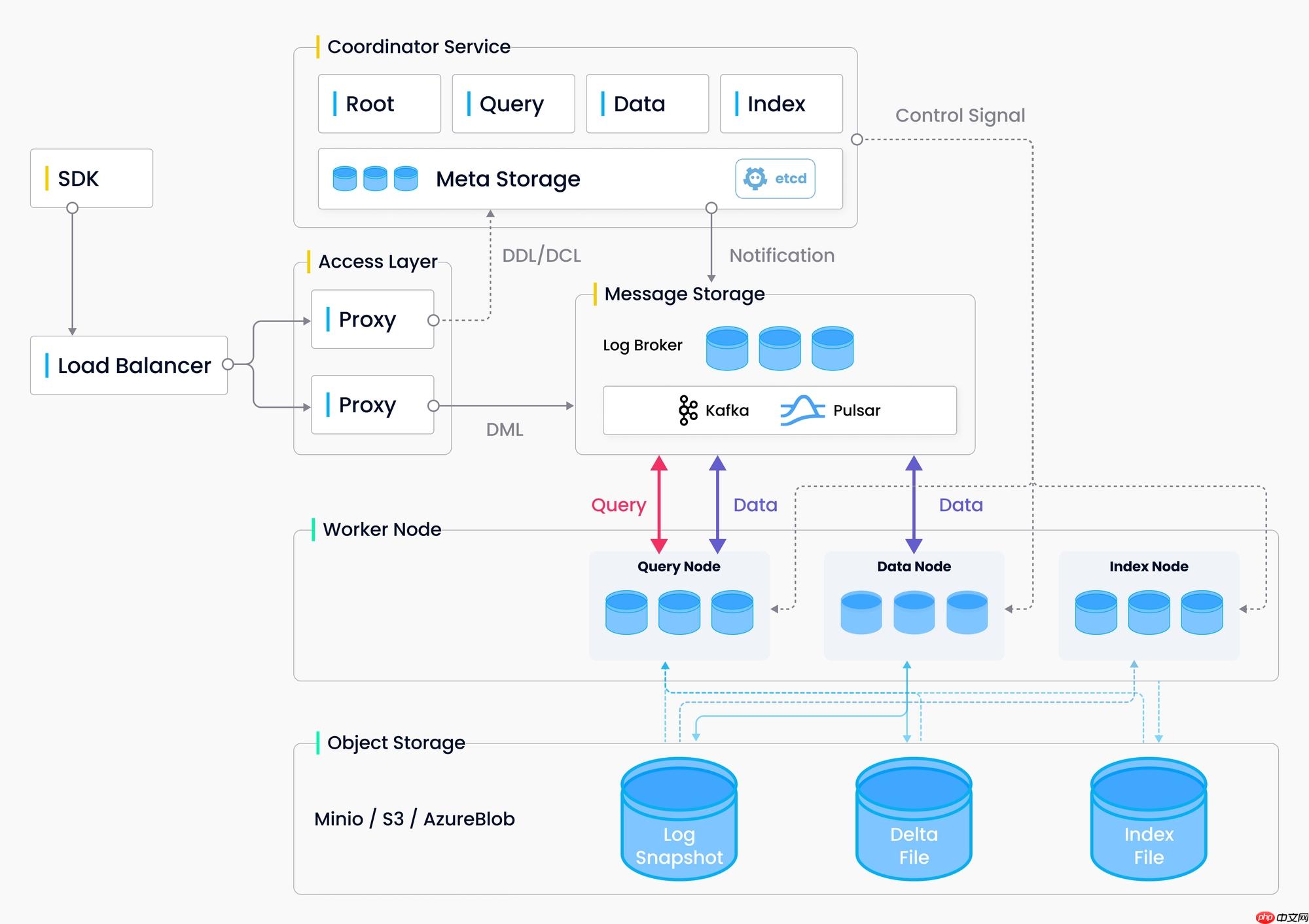
本教程讲解的推荐召回系统中将使用 Milvus 来实现向量召回这一过程,在启动本教程的服务之前,需要先启动 Milvus 服务。
本教程中提供了已经编译好的 Milvus 包,在终端运行以下命令启动 Milvus.
tar xf milvus_1.0.tar.gzexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$PWD/milvus/lib cd milvus/scrip nohup sh start_server.sh &
安装 Milvus 客户端
pip install pymilvus==1.0.1
什么是 PaddleRec?
MIND 算法全称为:Multi-Interest Network with Dynamic Routing for Recommendation at Tmall,由阿里的算法团队开发。
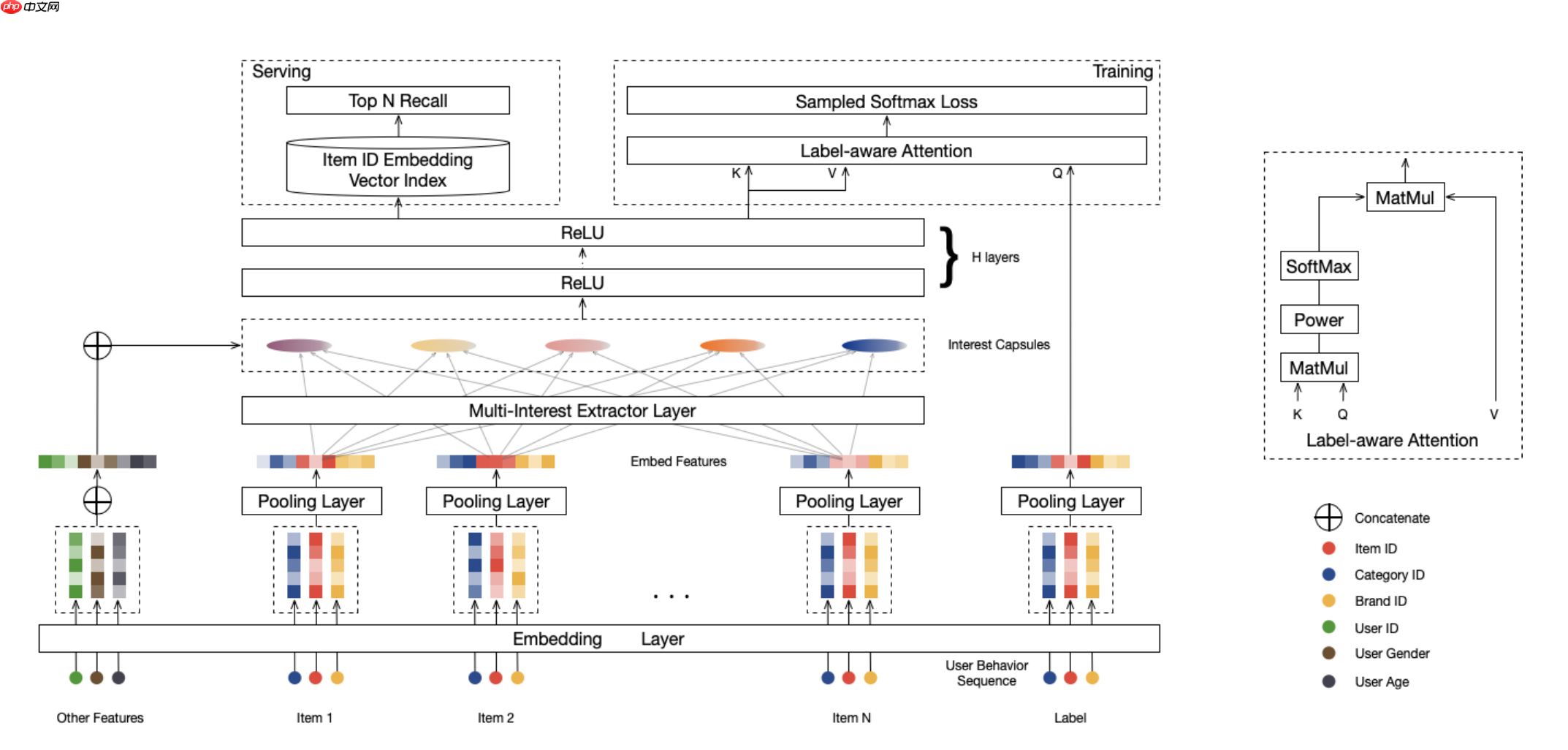
工业界的推荐系统通常包括召回阶段和排序阶段。召回阶段我们根据用户的兴趣从海量的商品中去检索出用户(User)感兴趣的候选商品( Item),满足推荐相关性和多样性需求。目前的深度学习召回模型的大多是为每个用户生成一个兴趣向量,但在实际的购物场景中,用户的兴趣是多样的,不同兴趣之间甚至可能是不相关的。比如用户可能同时期望购买服装、化妆品、零食,而一个长度有限的向量很难表示用户这样的多个兴趣。MIND 模型通过 Dynamic Routing 的方法从用户行为和用户属性信息中动态学习出多个表示用户兴趣的向量,更好的捕捉用户的多样兴趣,来提升召回的丰富度和准确度。
MIND 的创新点在于:
通过Mulit-Interest Extractor Layer 获取User的多个兴趣向量表达。提出了具有动态路由特点的多兴趣网络,利用Dynamic Routing以自适应地聚合User历史行为到User兴趣表达向量中;
通过Label-Aware Attention 标签感知注意力机制,指导学习User的多兴趣表达Embedding;
MIND 架构图如下:
运行上述脚本后,将会得到 train 和 valid 两个数据文件,其中分别存放了训练数据集和测试数据集。
训练数据的格式如下:
0,17978,00,901,10,97224,20,774,30,85757,4
其中每一列分别表示:
测试数据的格式如下:
user_id:487766 hist_item:17784 hist_item:126 hist_item:36 hist_item:124 hist_item:34 hist_item:1 hist_item:134 hist_item:6331 hist_item:141 hist_item:4336 hist_item:1373 eval_item:1062 eval_item:867 eval_item:62user_id:487793 hist_item:153428 hist_item:132997 hist_item:155723 hist_item:66546 hist_item:335397 hist_item:1926 eval_item:1122 eval_item:10105user_id:487820 hist_item:268524 hist_item:44318 hist_item:35153 hist_item:70847 eval_item:238318
其中每一列分别表示:
其中 hist_item 和 eval_item 均是变长序列,读取方式请参考 model/mind/mind_infer_reader.py
我们基于上述提到的推荐模型算法 MIND, 使用 PaddleRec 实现了推荐模型 MIND。本教程实现的 MIND 模型,训练的输入是一系列用户 id, 和用户历史点击的 item id 和点击时间。模型从用户的历史点击行为来学习用户的兴趣向量,本模块实现的模型会对每个用户得到四个兴趣向量,同时也会通过学习得到训练数据集中包含的所有 item 的向量表示。
模型实现相关的代码放在目录 recommend/model 之下。
你可以通过修改配置文件 recommend/model/mind/config.yaml 来设置训练模型时的参数。
| Parameter | Description |
|---|---|
| runner.train_data_dir | 训练数据集路径,该路径为数据集相对 config.yaml 的相对路径,这里使用数据准备时下载得到的数据集 |
| runner.train_reader_path | 读取训练数据集的脚本,在本教程中默认为 "mind_reader" |
| runner.use_gpu | 训练模型时是否使用 GPU |
| runner.use_auc | 训练模型时是否使用 auc |
| runner.train_batch_size | 模型训练的 batch_size |
| runner.epochs | 模型训练的 epochs 数,本处默认值为20 |
| runner.print_interval | 训练过程中,打印训练信息的间隔数 |
| runner.model_save_path | 模型的存储路径 |
按照需要修改配置文件后,运行以下命令开始训练模型 MIND。(此处训练时间较长,如果想快速体验训练过程,可以适当减小 epochs。)
cd recommend/modelpython -u trainer.py -m mind/config.yaml
为了使用户可以快速搭建一个推荐系统中的召回服务,本教程提供了一个使用 config.yaml 中的默认参数和上述数据训练后的模型 recommend/model/output_model_mind.tar.gz 。解压后可供后续直接使用。
本模块将对测试数据进行预测。预测时,从模型中取得所有的 item 向量存入 Milvus 中(共 367983 个 item)。再将测试数据集的用户信息通过模型得到用户兴趣向量,本教程构建的模型中将对每个用户分别输出四个 64 维的用户兴趣向量,以表达用户多样的兴趣分布。然后利用四个兴趣向量在 Milvus 中分别检索出TopK个与其近邻的 item 向量,再对得到的四个结果集排序,最后得到 TopK 个 用户感兴趣的商品。
本模块教程分别评测了 Recall@50, NDCG@50, HitRate@50 这几个指标。
按照需要修改配置文件后,运行以下命令开始测试模型的召回率
| Parameter | Description |
|---|---|
| runner.use_gpu | 是否使用 GPU |
| runner.use_auc | 是否使用 auc |
| runner.infer_batch_size | 每次测试时的数据 batch 大小 |
| runner.infer_reader_path | 读取测试数据集的脚本,在本教程中默认为 mind_infer_reader |
| runner.test_data_dir | 测试数据集路径,可以是相对 config.yaml 的相对路径,也可以是绝对路径 |
| runner.infer_load_path | 模型路径, 可以是模型相对 config.yaml 的相对路径,也可以为绝对路径 |
| runner.infer_start_epoch | 从训练时第 infer_start_epoch 次保存的模型开始测试 |
| runner.infer_end_epoch | 测试到训练时第 infer_end_epoch 次保存的模型结束 |
训练过程中,每一个 epoch 都会保存一次训练得到的模型参数结果。在测试模型召回率时,通过 runner.infer_start_epoch 和 runner.infer_end_epoch 来指定要测试的模型。
通过以下运行以下命令来测试模型的召回率。
cd recommend/modelpython -u infer.py -m mind/config.yaml -top_n 50
在完成模型训练以及使用测试数据集对模型对模型从 Recall, NDCG, HitRate 这几个指标进行评测以后,本教程还提供了一个召回服务。包括 数据导入,召回,查询库中 item 的数量, 删除指定的库。
本项目中,我们提供了一个使用 Amazon Book 数据集训练 (epoch=20) 的模型。可以解压后直接测试使用。
cd recommend/model/tar xf output_model_mind.tar.gz
在启动之前确保已经参照上述步骤启动 Milvus 服务。同时按照环境修改 recommend/config.py 中的参数:
| Parameter | Description |
|---|---|
| MILVUS_HOST | Milvus 服务所在的 IP 地址 |
| MILVUS_PORT | Milvus 服务的端口号 |
| VECTOR_DIMENSION | item embedding 的维度 |
| DEFAULT_COLLECTION | Milvus 集合的名称 |
| MODEL_CONFIG_PATH | MIND 模型的配置文件路径: config.yaml |
| EPOCH_NUM | 选择使用训练时第 EPOCH_NUM 保存的模型 |
安装 python 依赖:
pip install fastapi pip install uvicorn
执行以下命令,启动召回服务:
cd recommend nohup uvicorn main:app &
该服务一共提供了四个接口:
curl -X 'POST' \ 'http://127.0.0.1:8000/rec/insert_data' \ -H 'accept: application/json' \ -d ''
curl -X 'POST' \
'http://127.0.0.1:8000/rec/recall' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"top_k": 50,
"hist_item": [[43,23,65,675,3456,8654,123454,54367,234561],[675,3456,8654,123454,76543,1234,9769,5670,65443,123098,34219,234098]]
}'curl -X 'POST' \ 'http://127.0.0.1:8000/rec/count' \ -H 'accept: application/json' \ -d ''
curl -X 'POST' \ 'http://127.0.0.1:8000/qa/drop' \ -H 'accept: application/json' \ -d ''
以上就是基于 Milvus 和 MIND 算法的商品召回的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 485
485























