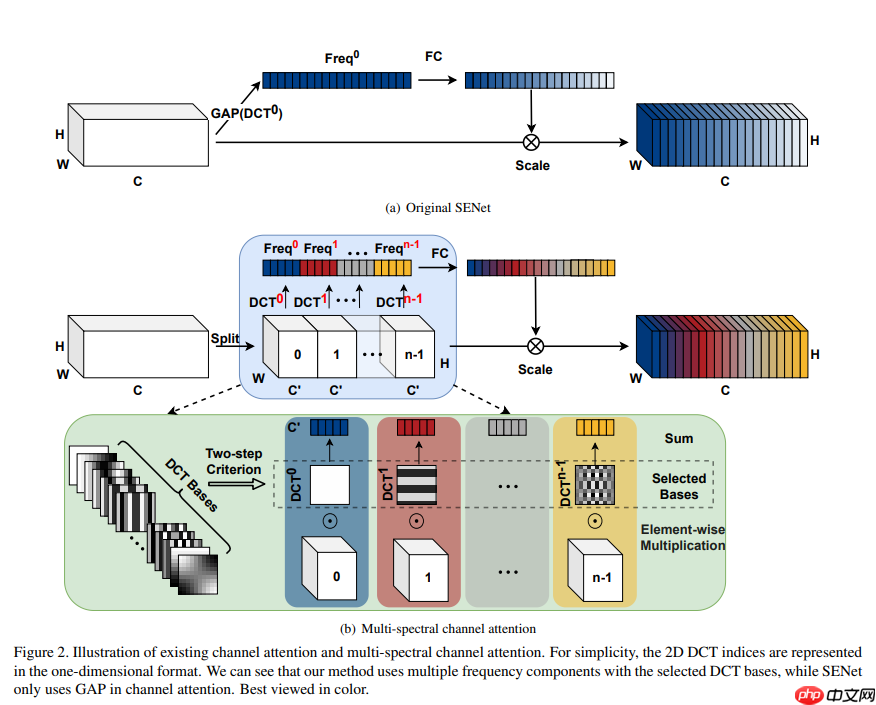
FcaNet通过频率域分析重新审视通道注意力,证明GAP是二维DCT的特例。据此将通道注意力推广到频域,提出多谱通道注意力框架,通过选择更多频率分量引入更多信息。实验显示,其在ImageNet和COCO数据集表现优异,基于ResNet时精度高于SENet,且实现简单。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

att=sigmoid(fc(gap(X)))
X~:,i,:,:=attiX:,i,:,:, s.t. i∈{0,1,⋯,C−1}
fk=i=0∑L−1xicos(Lπk(i+21)), s.t. k∈{0,1,⋯,L−1}
fh,w2d=i=0∑H−1j=0∑W−1xi,j2dDCT weightscos(Hπh(i+21))cos(Wπw(i+21)), s.t. h∈{0,1,⋯,H−1},w∈{0,1,⋯,W−1}
xi,j2d=h=0∑H−1w=0∑W−1fh,w2dDCT weightscos(Hπh(i+21))cos(Wπw(i+21)), s.t. i∈{0,1,⋯,H−1},j∈{0,1,⋯,W−1}
f0,02d=i=0∑H−1j=0∑W−1xi,j2dcos(H0(i+21))cos(W0(j+21))=1=i=0∑H−1j=0∑W−1xi,j2d=gap(x2d)HW
Bh,wi,j=cos(Hπh(i+21))cos(Wπw(j+21))
xi,j2d=h=0∑H−1w=0∑W−1fh,w2dcos(Hπh(i+21))cos(Wπw(j+21))=f0,02dB0,0i,j+f0,12dB0,1i,j+⋯+fH−1.W−12dBH−1,W−1i,j=gap(x2d)HWB0,0i,j+f0,12dB0,1i,j+⋯+fH−1.W−12dBH−1,W−1i,js.t. i∈{0,1,⋯,H−1},j∈{0,1,⋯,W−1}
X=utilized gap(X)HWB0,0i,j+discarded f0,12dB0,1i,j+⋯+fH−1,W−12dBH−1,W−1i,j
基于此,作者设计了多谱注意力模块(Multi-Spectral Attention Module),该模块通过推广 GAP 采用更多频率分量从而引入更多的信息。
首先,输入 X 被沿着通道划分为多块,记为 [X0,X1,⋯,Xn−1],其中每个 Xi∈RC′×H×W,i∈{0,1,⋯,n−1},C′=nC,每个块分配一个二维 DCT 分量,那么每一块的输出结果如下式。
Freqi=2DDCTu,v(Xi)=h=0∑H−1w=0∑W−1X:,h,wiBh,wu,vs.t. i∈{0,1,⋯,n−1}
Freq =cat([ Fre q0, Fre q1,⋯, Freq n−1])
ms−att=sigmoid(fc( Freq ))
import mathimport paddleimport paddle.nn as nnfrom paddle.vision.models import ResNet
def get_freq_indices(method):
assert method in [ 'top1', 'top2', 'top4', 'top8', 'top16', 'top32', 'bot1', 'bot2', 'bot4', 'bot8', 'bot16', 'bot32', 'low1', 'low2', 'low4', 'low8', 'low16', 'low32'
]
num_freq = int(method[3:]) if 'top' in method:
all_top_indices_x = [ 0, 0, 6, 0, 0, 1, 1, 4, 5, 1, 3, 0, 0, 0, 3, 2, 4, 6, 3, 5, 5, 2, 6, 5, 5, 3, 3, 4, 2, 2, 6, 1
]
all_top_indices_y = [ 0, 1, 0, 5, 2, 0, 2, 0, 0, 6, 0, 4, 6, 3, 5, 2, 6, 3, 3, 3, 5, 1, 1, 2, 4, 2, 1, 1, 3, 0, 5, 3
]
mapper_x = all_top_indices_x[:num_freq]
mapper_y = all_top_indices_y[:num_freq] elif 'low' in method:
all_low_indices_x = [ 0, 0, 1, 1, 0, 2, 2, 1, 2, 0, 3, 4, 0, 1, 3, 0, 1, 2, 3, 4, 5, 0, 1, 2, 3, 4, 5, 6, 1, 2, 3, 4
]
all_low_indices_y = [ 0, 1, 0, 1, 2, 0, 1, 2, 2, 3, 0, 0, 4, 3, 1, 5, 4, 3, 2, 1, 0, 6, 5, 4, 3, 2, 1, 0, 6, 5, 4, 3
]
mapper_x = all_low_indices_x[:num_freq]
mapper_y = all_low_indices_y[:num_freq] elif 'bot' in method:
all_bot_indices_x = [ 6, 1, 3, 3, 2, 4, 1, 2, 4, 4, 5, 1, 4, 6, 2, 5, 6, 1, 6, 2, 2, 4, 3, 3, 5, 5, 6, 2, 5, 5, 3, 6
]
all_bot_indices_y = [ 6, 4, 4, 6, 6, 3, 1, 4, 4, 5, 6, 5, 2, 2, 5, 1, 4, 3, 5, 0, 3, 1, 1, 2, 4, 2, 1, 1, 5, 3, 3, 3
]
mapper_x = all_bot_indices_x[:num_freq]
mapper_y = all_bot_indices_y[:num_freq] else: raise NotImplementedError return mapper_x, mapper_yclass MultiSpectralAttentionLayer(nn.Layer):
def __init__(self,
channel,
dct_h,
dct_w,
reduction=16,
freq_sel_method='top16'):
super(MultiSpectralAttentionLayer, self).__init__()
self.reduction = reduction
self.dct_h = dct_h
self.dct_w = dct_w
mapper_x, mapper_y = get_freq_indices(freq_sel_method)
self.num_split = len(mapper_x)
mapper_x = [temp_x * (dct_h // 7) for temp_x in mapper_x]
mapper_y = [temp_y * (dct_w // 7) for temp_y in mapper_y] # make the frequencies in different sizes are identical to a 7x7 frequency space
# eg, (2,2) in 14x14 is identical to (1,1) in 7x7
self.dct_layer = MultiSpectralDCTLayer(dct_h, dct_w, mapper_x,
mapper_y, channel)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias_attr=False),
nn.ReLU(), nn.Linear(channel // reduction,
channel,
bias_attr=False), nn.Sigmoid()) def forward(self, x):
n, c, h, w = x.shape
x_pooled = x if h != self.dct_h or w != self.dct_w:
x_pooled = nn.functional.adaptive_avg_pool2d(
x, (self.dct_h, self.dct_w)) # If you have concerns about one-line-change, don't worry. :)
# In the ImageNet models, this line will never be triggered.
# This is for compatibility in instance segmentation and object detection.
y = self.dct_layer(x_pooled)
y = self.fc(y).reshape((n, c, 1, 1)) return x * y.expand_as(x)class MultiSpectralDCTLayer(nn.Layer):
"""
Generate dct filters
"""
def __init__(self, height, width, mapper_x, mapper_y, channel):
super(MultiSpectralDCTLayer, self).__init__() assert len(mapper_x) == len(mapper_y) assert channel % len(mapper_x) == 0
self.num_freq = len(mapper_x) # fixed DCT init
self.register_buffer( 'weight',
self.get_dct_filter(height, width, mapper_x, mapper_y, channel)) # # fixed random init
# self.register_buffer(
# 'weight',
# paddle.rand((channel, height, width)))
# # learnable DCT init
# self.register_parameter(
# 'weight',
# self.get_dct_filter(height, width, mapper_x, mapper_y, channel))
# # learnable random init
# self.register_parameter(
# 'weight',
# paddle.rand((channel, height, width)))
def forward(self, x):
assert len(x.shape) == 4, 'x must been 4 dimensions, but got ' + str( len(x.shape)) # n, c, h, w = x.shape
x = x * self.weight
result = paddle.sum(x, axis=[2, 3]) return result def build_filter(self, pos, freq, POS):
result = math.cos(math.pi * freq * (pos + 0.5) / POS) / math.sqrt(POS) if freq == 0: return result else: return result * math.sqrt(2) def get_dct_filter(self, tile_size_x, tile_size_y, mapper_x, mapper_y,
channel):
dct_filter = paddle.zeros((channel, tile_size_x, tile_size_y))
c_part = channel // len(mapper_x) for i, (u_x, v_y) in enumerate(zip(mapper_x, mapper_y)): for t_x in range(tile_size_x): for t_y in range(tile_size_y):
dct_filter[i * c_part:(i + 1) * c_part,
t_x, t_y] = self.build_filter(
t_x, u_x, tile_size_x) * self.build_filter(
t_y, v_y, tile_size_y) return dct_filterdef conv3x3(in_planes, out_planes, stride=1):
return nn.Conv2D(in_planes,
out_planes,
kernel_size=3,
stride=stride,
padding=1,
bias_attr=False)class FcaBottleneck(nn.Layer):
expansion = 4
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None,
reduction=16):
global _mapper_x, _mapper_y super(FcaBottleneck, self).__init__() # assert fea_h is not None
# assert fea_w is not None
c2wh = dict([(64, 56), (128, 28), (256, 14), (512, 7)])
self.planes = planes
self.conv1 = nn.Conv2D(inplanes,
planes,
kernel_size=1,
bias_attr=False)
self.bn1 = nn.BatchNorm2D(planes)
self.conv2 = nn.Conv2D(planes,
planes,
kernel_size=3,
stride=stride,
padding=1,
bias_attr=False)
self.bn2 = nn.BatchNorm2D(planes)
self.conv3 = nn.Conv2D(planes,
planes * 4,
kernel_size=1,
bias_attr=False)
self.bn3 = nn.BatchNorm2D(planes * 4)
self.relu = nn.ReLU()
self.att = MultiSpectralAttentionLayer(planes * 4,
c2wh[planes],
c2wh[planes],
reduction=reduction,
freq_sel_method='top16')
self.downsample = downsample
self.stride = stride def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.att(out) if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out) return outclass FcaBasicBlock(nn.Layer):
expansion = 1
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None,
reduction=16):
global _mapper_x, _mapper_y super(FcaBasicBlock, self).__init__() # assert fea_h is not None
# assert fea_w is not None
c2wh = dict([(64, 56), (128, 28), (256, 14), (512, 7)])
self.planes = planes
self.conv1 = nn.Conv2D(inplanes,
planes,
kernel_size=3,
stride=stride,
padding=1,
bias_attr=False)
self.bn1 = nn.BatchNorm2D(planes)
self.conv2 = nn.Conv2D(planes,
planes,
kernel_size=3,
padding=1,
bias_attr=False)
self.bn2 = nn.BatchNorm2D(planes)
self.relu = nn.ReLU()
self.att = MultiSpectralAttentionLayer(planes,
c2wh[planes],
c2wh[planes],
reduction=reduction,
freq_sel_method='top16')
self.downsample = downsample
self.stride = stride def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.att(out) if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out) return out/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int):
def fcanet34(num_classes=1000, pretrained=False):
"""Constructs a FcaNet-34 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(FcaBasicBlock, 34, num_classes=num_classes)
model.avgpool = nn.AdaptiveAvgPool2D(1) if pretrained:
params = paddle.load('data/data100873/fca34.pdparams')
model.set_dict(params) return modeldef fcanet50(num_classes=1000, pretrained=False):
"""Constructs a FcaNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(FcaBottleneck, 50, num_classes=num_classes)
model.avgpool = nn.AdaptiveAvgPool2D(1) if pretrained:
params = paddle.load('data/data100873/fca50.pdparams')
model.set_dict(params) return modeldef fcanet101(num_classes=1000, pretrained=False):
"""Constructs a FcaNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(FcaBottleneck, 101, num_classes=num_classes)
model.avgpool = nn.AdaptiveAvgPool2D(1) if pretrained:
params = paddle.load('data/data100873/fca101.pdparams')
model.set_dict(params) return modeldef fcanet152(num_classes=1000, pretrained=False):
"""Constructs a FcaNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(FcaBottleneck, 152, num_classes=num_classes)
model.avgpool = nn.AdaptiveAvgPool2D(1) if pretrained:
params = paddle.load('data/data100873/fca152.pdparams')
model.set_dict(params) return modelmodel = fcanet34(pretrained=True) x = paddle.randn((1, 3, 224, 224)) out = model(x)print(out.shape) model.eval() out = model(x)print(out.shape)
[1, 1000] [1, 1000]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:648: UserWarning: When training, we now always track global mean and variance. "When training, we now always track global mean and variance.")
| Model | Reported | Evaluation Results |
|---|---|---|
| FcaNet34 | 75.07 | 75.02 |
| FcaNet50 | 78.52 | 78.57 |
| FcaNet101 | 79.64 | 79.63 |
| FcaNet152 | 80.08 | 80.02 |
!mkdir ~/data/ILSVRC2012 !tar -xf ~/data/data68594/ILSVRC2012_img_val.tar -C ~/data/ILSVRC2012
import osimport cv2import numpy as npimport paddleimport paddle.vision.transforms as Tfrom PIL import Image# 构建数据集class ILSVRC2012(paddle.io.Dataset):
def __init__(self, root, label_list, transform, backend='pil'):
self.transform = transform
self.root = root
self.label_list = label_list
self.backend = backend
self.load_datas() def load_datas(self):
self.imgs = []
self.labels = [] with open(self.label_list, 'r') as f: for line in f:
img, label = line[:-1].split(' ')
self.imgs.append(os.path.join(self.root, img))
self.labels.append(int(label)) def __getitem__(self, idx):
label = self.labels[idx]
image = self.imgs[idx] if self.backend=='cv2':
image = cv2.imread(image) else:
image = Image.open(image).convert('RGB')
image = self.transform(image) return image.astype('float32'), np.array(label).astype('int64') def __len__(self):
return len(self.imgs)
val_transforms = T.Compose([
T.Resize(256, interpolation='bicubic'),
T.CenterCrop(224),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 配置模型model = fcanet34(pretrained=True)
model = paddle.Model(model)
model.prepare(metrics=paddle.metric.Accuracy(topk=(1, 5)))# 配置数据集val_dataset = ILSVRC2012('data/ILSVRC2012', transform=val_transforms, label_list='data/data68594/val_list.txt', backend='pil')# 模型验证acc = model.evaluate(val_dataset, batch_size=8, num_workers=0, verbose=1)print(acc){'acc_top1': 0.74838, 'acc_top5': 0.92048}以上就是Paddle2.0:浅析并实现 FcaNet 模型的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 490
490























