本文复现去attention化论文,以Feed-Forward替代Transformer的attention层,基于ViT、DeiT模型在ImageNet表现良好。代码构建相关模型,展示结构与参数,在Cifar10简短训练,表明视觉Transformer中除注意力外的部分可能很重要。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

hi guy!我们又再一次见面了,这次来复现一篇非常有趣的论文,去attention化
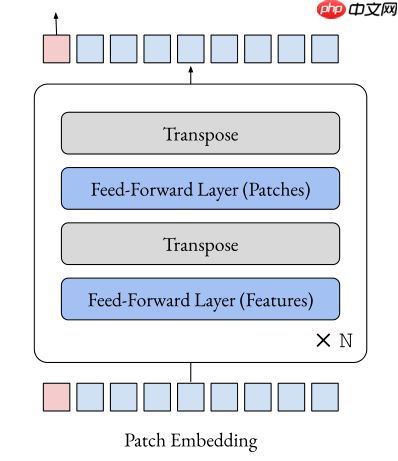
作者实验竟然惊讶发现,仅Feed-Forward就能在ImageNet表现良好的性能,这可以帮助研究人员理解为什么当前模型为什么这么有效
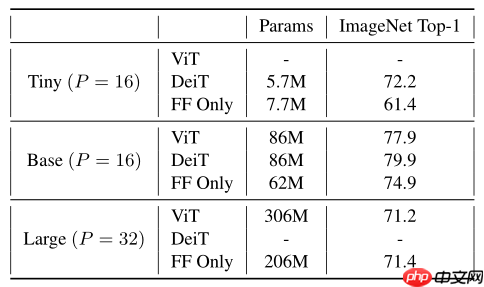
具体来说,该模型用FF(fead-forward)替换Transformer的attention层,基于ViT、DeiT的模型获得了良好的top1准确性,如下所示
import paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom functools import partial trunc_normal_ = nn.initializer.TruncatedNormal(std=.02) zeros_ = nn.initializer.Constant(value=0.) ones_ = nn.initializer.Constant(value=1.) kaiming_normal_ = nn.initializer.KaimingNormal()
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int):
def swapdim(x, dim1, dim2):
a = list(range(len(x.shape)))
a[dim1], a[dim2] = a[dim2], a[dim1] return x.transpose(a)def drop_path(x, drop_prob = 0., training = False):
if drop_prob == 0. or not training: return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = paddle.to_tensor(keep_prob) + paddle.rand(shape)
random_tensor = paddle.floor(random_tensor)
output = x.divide(keep_prob) * random_tensor return outputclass DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class Identity(nn.Layer):
def __init__(self, *args, **kwargs):
super(Identity, self).__init__()
def forward(self, input):
return inputclass Mlp(nn.Layer):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop) def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x) return xclass LinearBlock(nn.Layer):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, num_tokens=197):
super().__init__() # First stage
self.mlp1 = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=drop)
self.norm1 = norm_layer(dim) # Second stage
self.mlp2 = Mlp(in_features=num_tokens, hidden_features=int(
num_tokens * mlp_ratio), act_layer=act_layer, drop=drop)
self.norm2 = norm_layer(num_tokens) # Dropout (or a variant)
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity() def forward(self, x):
x = x + self.drop_path(self.mlp1(self.norm1(x)))
x = swapdim(x, -2, -1)
x = x + self.drop_path(self.mlp2(self.norm2(x)))
x = swapdim(x, -2, -1) return xclass PatchEmbed(nn.Layer):
""" Wraps a convolution """
def __init__(self, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) def forward(self, x):
x = self.proj(x) return xclass LearnedPositionalEncoding(nn.Layer):
""" Learned positional encoding with dynamic interpolation at runtime """
def __init__(self, height, width, embed_dim):
super().__init__()
self.height = height
self.width = width
self.pos_embed = self.create_parameter(shape=[1, embed_dim, height, width], default_initializer=trunc_normal_)
self.add_parameter("pos_embed", self.pos_embed)
self.cls_pos_embed = self.create_parameter(shape=[1, 1, embed_dim], default_initializer=trunc_normal_)
self.add_parameter("cls_pos_embed", self.cls_pos_embed) def forward(self, x):
B, C, H, W = x.shape if H == self.height and W == self.width:
pos_embed = self.pos_embed else:
pos_embed = F.interpolate(self.pos_embed, size=[H, W], mode='bilinear', align_corners=False) # ??
return self.cls_pos_embed, pos_embedclass LinearVisionTransformer(nn.Layer):
"""
Basically the same as the standard Vision Transformer, but with support for resizable
or sinusoidal positional embeddings.
"""
def __init__(self, *, patch_size=16, in_chans=3, num_classes=1000, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., hybrid_backbone=None, norm_layer=nn.LayerNorm,
positional_encoding='learned', learned_positional_encoding_size=(14, 14), block_cls=LinearBlock):
super().__init__() # Config
self.num_classes = num_classes
self.patch_size = patch_size
self.num_features = self.embed_dim = embed_dim # Patch embedding
self.patch_embed = PatchEmbed(patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim) # Class token
self.cls_token = self.create_parameter(shape=[1, 1, embed_dim], default_initializer=trunc_normal_)
self.add_parameter("cls_token", self.cls_token) # Positional encoding
if positional_encoding == 'learned':
height, width = self.learned_positional_encoding_size = learned_positional_encoding_size
self.pos_encoding = LearnedPositionalEncoding(height, width, embed_dim) else: raise NotImplementedError('Unsupposed positional encoding')
self.pos_drop = nn.Dropout(p=drop_rate) # Stochastic depth
dpr = [x for x in paddle.linspace(0, drop_path_rate, depth)]
self.blocks = nn.LayerList([
block_cls(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, num_tokens=1 + (224 // patch_size)**2) for i in range(depth)])
self.norm = norm_layer(embed_dim) # Classifier head
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else Identity()
self.apply(self._init_weights) def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) def forward_features(self, x):
# Patch embedding
B, C, H, W = x.shape # B x C x H x W
x = self.patch_embed(x) # B x E x H//p x W//p
# Positional encoding
# NOTE: cls_pos_embed for compatibility with pretrained models
cls_pos_embed, pos_embed = self.pos_encoding(x) # Flatten image, append class token, add positional encoding
cls_tokens = self.cls_token.expand([B, -1, -1])
x = x.flatten(2) # flatten
x = swapdim(x , 1, 2)
x = paddle.concat((cls_tokens, x), axis=1) # class token
pos_embed = pos_embed.flatten(2) # flatten
pos_embed = swapdim(pos_embed, 1, 2)
pos_embed = paddle.concat([cls_pos_embed, pos_embed], axis=1) # class pos emb
x = x + pos_embed
x = self.pos_drop(x) # Transformer
for blk in self.blocks:
x = blk(x) # Final layernorm
x = self.norm(x) return x[:, 0] def forward(self, x):
x = self.forward_features(x)
x = self.head(x) return xdef linear_tiny(**kwargs):
model = LinearVisionTransformer(
patch_size=16, embed_dim=192, depth=12, num_heads=3, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), **kwargs) return modeldef linear_base(**kwargs):
model = LinearVisionTransformer(
patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), **kwargs) return modeldef linear_large(**kwargs):
model = LinearVisionTransformer(
patch_size=32, embed_dim=1024, depth=24, num_heads=16, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), **kwargs) return modelpaddle.Model(linear_base()).summary((1,3,224,224))
--------------------------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
==================================================================================================
Conv2D-4 [[1, 3, 224, 224]] [1, 768, 14, 14] 590,592
PatchEmbed-4 [[1, 3, 224, 224]] [1, 768, 14, 14] 0
LearnedPositionalEncoding-4 [[1, 768, 14, 14]] [[1, 1, 768], [1, 768, 14, 14]] 151,296
Dropout-76 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-76 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-148 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-73 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-77 [[1, 197, 768]] [1, 197, 768] 0
Linear-149 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Mlp-73 [[1, 197, 768]] [1, 197, 768] 0
Identity-37 [[1, 768, 197]] [1, 768, 197] 0
LayerNorm-77 [[1, 768, 197]] [1, 768, 197] 394
Linear-150 [[1, 768, 197]] [1, 768, 788] 156,024
GELU-74 [[1, 768, 788]] [1, 768, 788] 0
Dropout-78 [[1, 768, 197]] [1, 768, 197] 0
Linear-151 [[1, 768, 788]] [1, 768, 197] 155,433
Mlp-74 [[1, 768, 197]] [1, 768, 197] 0
LinearBlock-37 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-78 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-152 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-75 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-79 [[1, 197, 768]] [1, 197, 768] 0
Linear-153 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Mlp-75 [[1, 197, 768]] [1, 197, 768] 0
Identity-38 [[1, 768, 197]] [1, 768, 197] 0
LayerNorm-79 [[1, 768, 197]] [1, 768, 197] 394
Linear-154 [[1, 768, 197]] [1, 768, 788] 156,024
GELU-76 [[1, 768, 788]] [1, 768, 788] 0
Dropout-80 [[1, 768, 197]] [1, 768, 197] 0
Linear-155 [[1, 768, 788]] [1, 768, 197] 155,433
Mlp-76 [[1, 768, 197]] [1, 768, 197] 0
LinearBlock-38 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-80 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-156 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-77 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-81 [[1, 197, 768]] [1, 197, 768] 0
Linear-157 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Mlp-77 [[1, 197, 768]] [1, 197, 768] 0
Identity-39 [[1, 768, 197]] [1, 768, 197] 0
LayerNorm-81 [[1, 768, 197]] [1, 768, 197] 394
Linear-158 [[1, 768, 197]] [1, 768, 788] 156,024
GELU-78 [[1, 768, 788]] [1, 768, 788] 0
Dropout-82 [[1, 768, 197]] [1, 768, 197] 0
Linear-159 [[1, 768, 788]] [1, 768, 197] 155,433
Mlp-78 [[1, 768, 197]] [1, 768, 197] 0
LinearBlock-39 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-82 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-160 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-79 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-83 [[1, 197, 768]] [1, 197, 768] 0
Linear-161 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Mlp-79 [[1, 197, 768]] [1, 197, 768] 0
Identity-40 [[1, 768, 197]] [1, 768, 197] 0
LayerNorm-83 [[1, 768, 197]] [1, 768, 197] 394
Linear-162 [[1, 768, 197]] [1, 768, 788] 156,024
GELU-80 [[1, 768, 788]] [1, 768, 788] 0
Dropout-84 [[1, 768, 197]] [1, 768, 197] 0
Linear-163 [[1, 768, 788]] [1, 768, 197] 155,433
Mlp-80 [[1, 768, 197]] [1, 768, 197] 0
LinearBlock-40 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-84 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-164 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-81 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-85 [[1, 197, 768]] [1, 197, 768] 0
Linear-165 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Mlp-81 [[1, 197, 768]] [1, 197, 768] 0
Identity-41 [[1, 768, 197]] [1, 768, 197] 0
LayerNorm-85 [[1, 768, 197]] [1, 768, 197] 394
Linear-166 [[1, 768, 197]] [1, 768, 788] 156,024
GELU-82 [[1, 768, 788]] [1, 768, 788] 0
Dropout-86 [[1, 768, 197]] [1, 768, 197] 0
Linear-167 [[1, 768, 788]] [1, 768, 197] 155,433
Mlp-82 [[1, 768, 197]] [1, 768, 197] 0
LinearBlock-41 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-86 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-168 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-83 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-87 [[1, 197, 768]] [1, 197, 768] 0
Linear-169 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Mlp-83 [[1, 197, 768]] [1, 197, 768] 0
Identity-42 [[1, 768, 197]] [1, 768, 197] 0
LayerNorm-87 [[1, 768, 197]] [1, 768, 197] 394
Linear-170 [[1, 768, 197]] [1, 768, 788] 156,024
GELU-84 [[1, 768, 788]] [1, 768, 788] 0
Dropout-88 [[1, 768, 197]] [1, 768, 197] 0
Linear-171 [[1, 768, 788]] [1, 768, 197] 155,433
Mlp-84 [[1, 768, 197]] [1, 768, 197] 0
LinearBlock-42 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-88 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-172 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-85 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-89 [[1, 197, 768]] [1, 197, 768] 0
Linear-173 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Mlp-85 [[1, 197, 768]] [1, 197, 768] 0
Identity-43 [[1, 768, 197]] [1, 768, 197] 0
LayerNorm-89 [[1, 768, 197]] [1, 768, 197] 394
Linear-174 [[1, 768, 197]] [1, 768, 788] 156,024
GELU-86 [[1, 768, 788]] [1, 768, 788] 0
Dropout-90 [[1, 768, 197]] [1, 768, 197] 0
Linear-175 [[1, 768, 788]] [1, 768, 197] 155,433
Mlp-86 [[1, 768, 197]] [1, 768, 197] 0
LinearBlock-43 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-90 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-176 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-87 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-91 [[1, 197, 768]] [1, 197, 768] 0
Linear-177 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Mlp-87 [[1, 197, 768]] [1, 197, 768] 0
Identity-44 [[1, 768, 197]] [1, 768, 197] 0
LayerNorm-91 [[1, 768, 197]] [1, 768, 197] 394
Linear-178 [[1, 768, 197]] [1, 768, 788] 156,024
GELU-88 [[1, 768, 788]] [1, 768, 788] 0
Dropout-92 [[1, 768, 197]] [1, 768, 197] 0
Linear-179 [[1, 768, 788]] [1, 768, 197] 155,433
Mlp-88 [[1, 768, 197]] [1, 768, 197] 0
LinearBlock-44 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-92 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-180 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-89 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-93 [[1, 197, 768]] [1, 197, 768] 0
Linear-181 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Mlp-89 [[1, 197, 768]] [1, 197, 768] 0
Identity-45 [[1, 768, 197]] [1, 768, 197] 0
LayerNorm-93 [[1, 768, 197]] [1, 768, 197] 394
Linear-182 [[1, 768, 197]] [1, 768, 788] 156,024
GELU-90 [[1, 768, 788]] [1, 768, 788] 0
Dropout-94 [[1, 768, 197]] [1, 768, 197] 0
Linear-183 [[1, 768, 788]] [1, 768, 197] 155,433
Mlp-90 [[1, 768, 197]] [1, 768, 197] 0
LinearBlock-45 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-94 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-184 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-91 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-95 [[1, 197, 768]] [1, 197, 768] 0
Linear-185 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Mlp-91 [[1, 197, 768]] [1, 197, 768] 0
Identity-46 [[1, 768, 197]] [1, 768, 197] 0
LayerNorm-95 [[1, 768, 197]] [1, 768, 197] 394
Linear-186 [[1, 768, 197]] [1, 768, 788] 156,024
GELU-92 [[1, 768, 788]] [1, 768, 788] 0
Dropout-96 [[1, 768, 197]] [1, 768, 197] 0
Linear-187 [[1, 768, 788]] [1, 768, 197] 155,433
Mlp-92 [[1, 768, 197]] [1, 768, 197] 0
LinearBlock-46 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-96 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-188 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-93 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-97 [[1, 197, 768]] [1, 197, 768] 0
Linear-189 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Mlp-93 [[1, 197, 768]] [1, 197, 768] 0
Identity-47 [[1, 768, 197]] [1, 768, 197] 0
LayerNorm-97 [[1, 768, 197]] [1, 768, 197] 394
Linear-190 [[1, 768, 197]] [1, 768, 788] 156,024
GELU-94 [[1, 768, 788]] [1, 768, 788] 0
Dropout-98 [[1, 768, 197]] [1, 768, 197] 0
Linear-191 [[1, 768, 788]] [1, 768, 197] 155,433
Mlp-94 [[1, 768, 197]] [1, 768, 197] 0
LinearBlock-47 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-98 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-192 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-95 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-99 [[1, 197, 768]] [1, 197, 768] 0
Linear-193 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Mlp-95 [[1, 197, 768]] [1, 197, 768] 0
Identity-48 [[1, 768, 197]] [1, 768, 197] 0
LayerNorm-99 [[1, 768, 197]] [1, 768, 197] 394
Linear-194 [[1, 768, 197]] [1, 768, 788] 156,024
GELU-96 [[1, 768, 788]] [1, 768, 788] 0
Dropout-100 [[1, 768, 197]] [1, 768, 197] 0
Linear-195 [[1, 768, 788]] [1, 768, 197] 155,433
Mlp-96 [[1, 768, 197]] [1, 768, 197] 0
LinearBlock-48 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-100 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-196 [[1, 768]] [1, 1000] 769,000
==================================================================================================
Total params: 61,942,252
Trainable params: 61,942,252
Non-trainable params: 0
--------------------------------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 365.91
Params size (MB): 236.29
Estimated Total Size (MB): 602.77
--------------------------------------------------------------------------------------------------/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/numpy/core/fromnumeric.py:87: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray. return ufunc.reduce(obj, axis, dtype, out, **passkwargs)
{'total_params': 61942252, 'trainable_params': 61942252}# ff tinyff_tiny = linear_tiny()
ff_tiny.set_state_dict(paddle.load('/home/aistudio/data/data96150/linear_tiny.pdparams'))# ff baseff_base = linear_base()
ff_base.set_state_dict(paddle.load('/home/aistudio/data/data96150/linear_base.pdparams'))采用Cifar10数据集,无过多的数据增强
import paddle.vision.transforms as Tfrom paddle.vision.datasets import Cifar10# 开启 GPUpaddle.set_device('gpu')# 数据准备transform = T.Compose([
T.Resize(size=(224,224)),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225],data_format='HWC'),
T.ToTensor()
])
train_dataset = Cifar10(mode='train', transform=transform)
val_dataset = Cifar10(mode='test', transform=transform)Cache file /home/aistudio/.cache/paddle/dataset/cifar/cifar-10-python.tar.gz not found, downloading https://dataset.bj.bcebos.com/cifar/cifar-10-python.tar.gz Begin to download Download finished
ff_base = linear_base(num_classes=10)
ff_base.set_state_dict(paddle.load('/home/aistudio/data/data96150/linear_base.pdparams'))
model = paddle.Model(ff_base)由于时间篇幅只训练5轮,感兴趣的同学可以继续训练
model.prepare(optimizer=paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())# 开启训练可视化visualdl=paddle.callbacks.VisualDL(log_dir='visual_log')
model.fit(
train_data=train_dataset,
eval_data=val_dataset,
batch_size=64,
epochs=5,
verbose=1,
callbacks=[visualdl]
)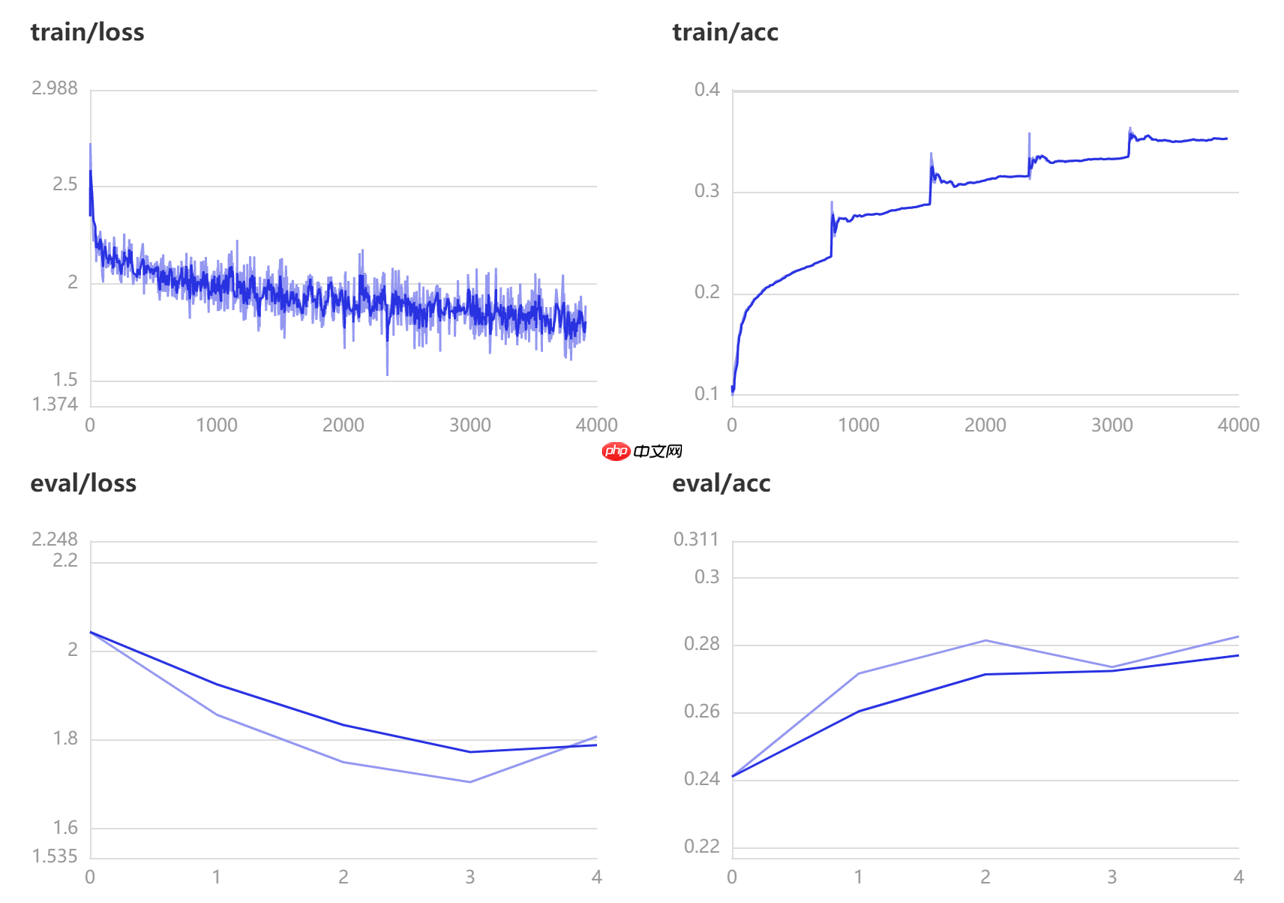
这些结果表明,除了注意力以外,视觉Transformer的其他方面(例如patch embedding)可能比以前认为的要重要。我们希望这些结果能促使社区花费更多时间来理解为什么我们当前的模型如此有效。
以上就是FF Only:Attention真的需要吗?的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 496
496























