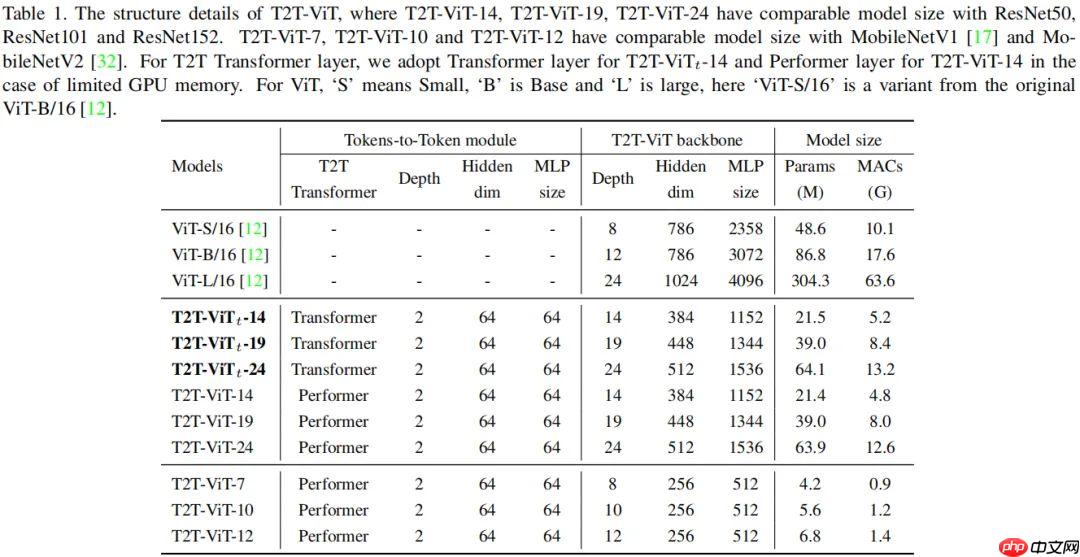
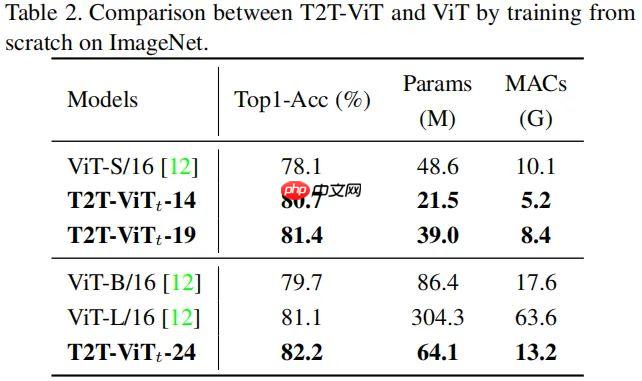
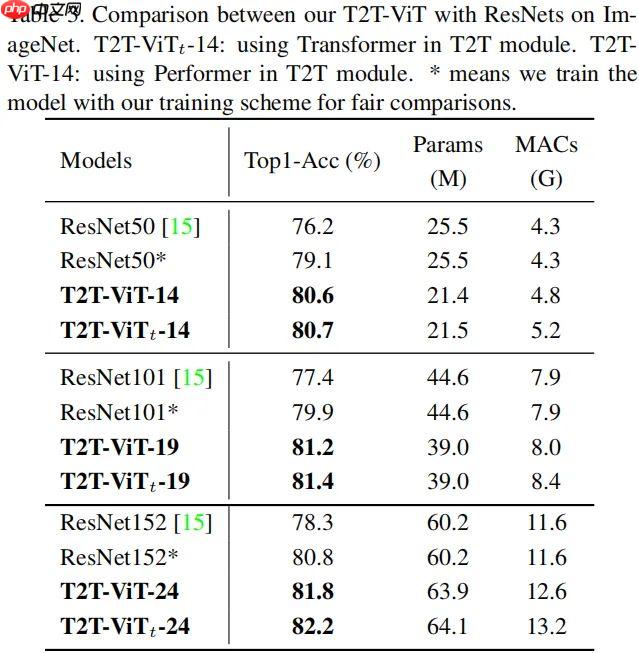
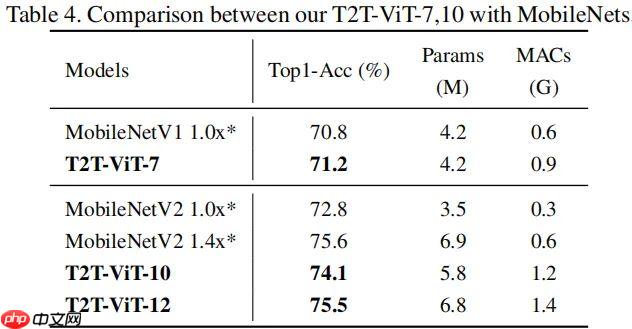
T2T-ViT提出渐进式Token化机制和深窄骨干结构,在ImageNet从头训练,超越CNN与ViT,参数和MAC减少200%,性能更优,如T2T-ViT-7验证集top1精度71.68%。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

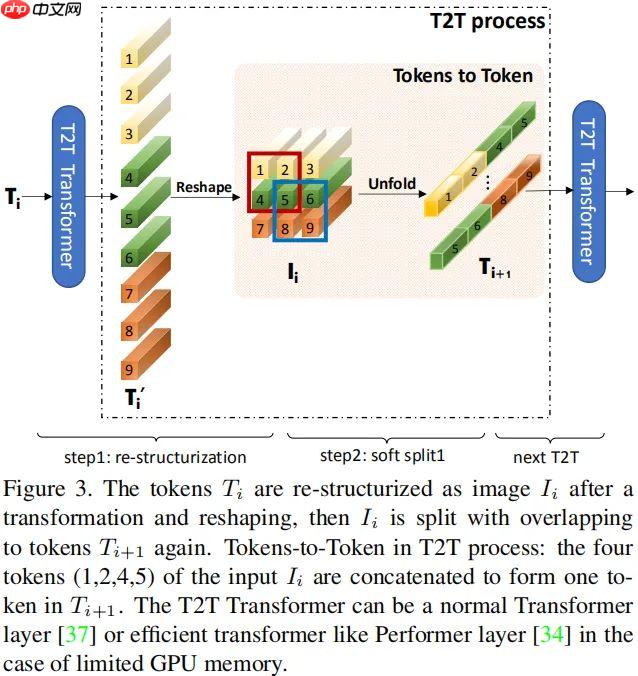
注:MSA表示多头自注意力模块,MLP表示多层感知器。经过上述变换后,Tokens将在空间维度上reshape为图像形式,描述如下:
注:Reshape表示将 转换为
注:每个拆分块尺寸为 。最后将所有块在空域维度上 flatten 为 Token 。这里所得到的输出 Token 将被送入到下一个 T2T 处理过程。
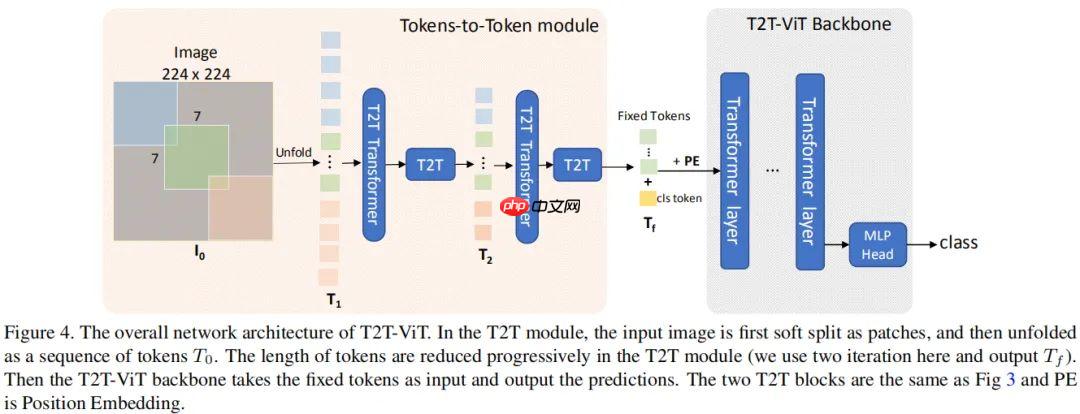
由于 ViT 骨干中的不少通道是无效的,故而作者计划设计一种高效骨干以降低冗余提升特征丰富性。
T2T-ViT 将 CNN 架构设计思想引入到 ViT 骨干设计以提升骨干的高效性、增强所学习特征的丰富性。
由于每个 Transformer 具有类似 ResNet 的跳过连接,一个最直接的想法是采用类似 DenseNet 的稠密连接提升特征丰富性;或者采用Wide-ResNet、ResNeXt结构改变通道维度。
本文从以下五个角度进行了系统性的比较:
结合上述五种结构设计,作者通过实验发现:
基于上述结构上的探索与发现,作者为 T2T-ViT 设计了 Deep-Narrow 形式的骨干结构,也就是说:更少的通道数、更深的层数。
对于定长 Token ,将类 Token 预期 Concat 融合并添加正弦位置嵌入 (Sinusoidal Position Embedding, SPE),
类似于 ViT 进行最后的分类:
import mathimport numpy as npimport paddleimport paddle.nn as nnfrom common import Attention as Attention_Pure # import pure Attention of ViTfrom common import Unfold # fix the bugs of nn.Unfoldfrom common import add_parameter # add the parametersfrom common import DropPath, Identity, Mlp # some common Layerfrom common import orthogonal_, trunc_normal_, zeros_, ones_ # some common initialization functiondef get_sinusoid_encoding(n_position, d_hid):
"""Sinusoid position encoding table"""
def get_position_angle_vec(position):
return [
position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)
]
sinusoid_table = np.array(
[get_position_angle_vec(pos_i) for pos_i in range(n_position)]
)
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
return sinusoid_table[None, ...].astype("float32")class Token_performer(nn.Layer):
def __init__(self, dim, in_dim, head_cnt=1, kernel_ratio=0.5, dp1=0.1, dp2=0.1):
super().__init__()
self.emb = in_dim * head_cnt # we use 1, so it is no need here
self.kqv = nn.Linear(dim, 3 * self.emb)
self.dp = nn.Dropout(dp1)
self.proj = nn.Linear(self.emb, self.emb)
self.head_cnt = head_cnt
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(self.emb)
self.epsilon = 1e-8 # for stable in division
self.mlp = nn.Sequential(
nn.Linear(self.emb, 1 * self.emb),
nn.GELU(),
nn.Linear(1 * self.emb, self.emb),
nn.Dropout(dp2),
)
self.m = int(self.emb * kernel_ratio)
self.w = paddle.randn((self.m, self.emb))
self.w = add_parameter(self, orthogonal_(self.w) * math.sqrt(self.m)) def prm_exp(self, x):
# ==== positive random features for gaussian kernels ====
# x = (B, T, hs)
# w = (m, hs)
# return : x : B, T, m
# SM(x, y) = E_w[exp(w^T x - |x|/2) exp(w^T y - |y|/2)]
# therefore return exp(w^Tx - |x|/2)/sqrt(m)
xd = ((x * x).sum(axis=-1, keepdim=True)).tile([1, 1, self.m]) / 2
wtx = paddle.mm(x, self.w.transpose((1, 0))) return paddle.exp(wtx - xd) / math.sqrt(self.m) def single_attn(self, x):
x = self.kqv(x)
k, q, v = paddle.split(x, x.shape[-1] // self.emb, axis=-1)
kp, qp = self.prm_exp(k), self.prm_exp(q) # (B, T, m), (B, T, m)
# (B, T, m) * (B, m) -> (B, T, 1)
D = paddle.bmm(qp, kp.sum(axis=1).unsqueeze(axis=-1))
kptv = paddle.bmm(v.astype("float32").transpose((0, 2, 1)), kp) # (B, emb, m)
y = paddle.bmm(qp, kptv.transpose((0, 2, 1))) / (
D.tile([1, 1, self.emb]) + self.epsilon
) # (B, T, emb) / Diag
# skip connection
# same as token_transformer in T2T layer, use v as skip connection
y = v + self.dp(self.proj(y)) return y def forward(self, x):
x = self.single_attn(self.norm1(x))
x = x + self.mlp(self.norm2(x)) return xclass Attention(nn.Layer):
def __init__(
self,
dim,
num_heads=8,
in_dim=None,
qkv_bias=False,
qk_scale=None,
attn_drop=0.0,
proj_drop=0.0, ):
super().__init__()
self.num_heads = num_heads
self.in_dim = in_dim
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, in_dim * 3, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(in_dim, in_dim)
self.proj_drop = nn.Dropout(proj_drop) def forward(self, x):
B, N, C = x.shape
qkv = (
self.qkv(x)
.reshape((B, N, 3, self.num_heads, self.in_dim))
.transpose((2, 0, 3, 1, 4))
)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q.matmul(k.transpose((0, 1, 3, 2)))) * self.scale
attn = nn.functional.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((-1, N, self.in_dim))
x = self.proj(x)
x = self.proj_drop(x) # skip connection
# because the original x has different size with current x, use v to do skip connection
x = v.squeeze(1) + x return xclass Token_transformer(nn.Layer):
def __init__(
self,
dim,
in_dim,
num_heads,
mlp_ratio=1.0,
qkv_bias=False,
qk_scale=None,
drop=0.0,
attn_drop=0.0,
drop_path=0.0,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm, ):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
in_dim=in_dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=drop,
)
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else Identity()
self.norm2 = norm_layer(in_dim)
self.mlp = Mlp(
in_features=in_dim,
hidden_features=int(in_dim * mlp_ratio),
out_features=in_dim,
act_layer=act_layer,
drop=drop,
) def forward(self, x):
x = self.attn(self.norm1(x))
x = x + self.drop_path(self.mlp(self.norm2(x))) return xclass Block(nn.Layer):
def __init__(
self,
dim,
num_heads,
mlp_ratio=4.0,
qkv_bias=False,
qk_scale=None,
drop=0.0,
attn_drop=0.0,
drop_path=0.0,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm, ):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention_Pure(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=drop,
)
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(
in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer,
drop=drop,
) def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x))) return xclass T2T_Layer(nn.Layer):
"""
Tokens-to-Token encoding module
"""
def __init__(
self,
img_size=224,
tokens_type="performer",
in_chans=3,
embed_dim=768,
token_dim=64, ):
super().__init__() if tokens_type == "transformer":
self.soft_split0 = Unfold(kernel_size=[7, 7], stride=[4, 4], padding=[2, 2])
self.soft_split1 = Unfold(kernel_size=[3, 3], stride=[2, 2], padding=[1, 1])
self.soft_split2 = Unfold(kernel_size=[3, 3], stride=[2, 2], padding=[1, 1])
self.attention1 = Token_transformer(
dim=in_chans * 7 * 7, in_dim=token_dim, num_heads=1, mlp_ratio=1.0
)
self.attention2 = Token_transformer(
dim=token_dim * 3 * 3, in_dim=token_dim, num_heads=1, mlp_ratio=1.0
)
self.project = nn.Linear(token_dim * 3 * 3, embed_dim) elif tokens_type == "performer":
self.soft_split0 = Unfold(kernel_size=[7, 7], stride=[4, 4], padding=[2, 2])
self.soft_split1 = Unfold(kernel_size=[3, 3], stride=[2, 2], padding=[1, 1])
self.soft_split2 = Unfold(kernel_size=[3, 3], stride=[2, 2], padding=[1, 1])
self.attention1 = Token_performer(
dim=in_chans * 7 * 7, in_dim=token_dim, kernel_ratio=0.5
)
self.attention2 = Token_performer(
dim=token_dim * 3 * 3, in_dim=token_dim, kernel_ratio=0.5
)
self.project = nn.Linear(token_dim * 3 * 3, embed_dim) elif (
tokens_type == "convolution"
): # just for comparison with conolution, not our model
# for this tokens type, you need change forward as three convolution operation
self.soft_split0 = nn.Conv2D( 3, token_dim, kernel_size=(7, 7), stride=(4, 4), padding=(2, 2)
) # the 1st convolution
self.soft_split1 = nn.Conv2D(
token_dim, token_dim, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)
) # the 2nd convolution
self.project = nn.Conv2D(
token_dim, embed_dim, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)
) # the 3rd convolution
self.num_patches = (img_size // (4 * 2 * 2)) * (
img_size // (4 * 2 * 2)
) # there are 3 sfot split, stride are 4,2,2 seperately
def forward(self, x):
# step0: soft split
x = self.soft_split0(x).transpose((0, 2, 1)) # iteration1: re-structurization/reconstruction
x = self.attention1(x)
B, new_HW, C = x.shape
x = x.transpose((0, 2, 1)).reshape(
(B, C, int(np.sqrt(new_HW)), int(np.sqrt(new_HW)))
) # iteration1: soft split
x = self.soft_split1(x).transpose((0, 2, 1)) # iteration2: re-structurization/reconstruction
x = self.attention2(x)
B, new_HW, C = x.shape
x = x.transpose((0, 2, 1)).reshape(
(B, C, int(np.sqrt(new_HW)), int(np.sqrt(new_HW)))
) # iteration2: soft split
x = self.soft_split2(x).transpose((0, 2, 1)) # final tokens
x = self.project(x) return xclass T2T_ViT(nn.Layer):
def __init__(
self,
img_size=224,
tokens_type="performer",
in_chans=3,
embed_dim=768,
depth=12,
num_heads=12,
mlp_ratio=4.0,
qkv_bias=False,
qk_scale=None,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.0,
norm_layer=nn.LayerNorm,
token_dim=64,
class_dim=1000, ):
super().__init__()
self.class_dim = class_dim
self.num_features = (
self.embed_dim
) = embed_dim # num_features for consistency with other models
self.tokens_to_token = T2T_Layer(
img_size=img_size,
tokens_type=tokens_type,
in_chans=in_chans,
embed_dim=embed_dim,
token_dim=token_dim,
)
num_patches = self.tokens_to_token.num_patches
self.cls_token = add_parameter(self, paddle.zeros((1, 1, embed_dim)))
self.pos_embed = add_parameter(
self, get_sinusoid_encoding(n_position=num_patches + 1, d_hid=embed_dim)
)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = np.linspace(0, drop_path_rate, depth) # stochastic depth decay rule
self.blocks = nn.LayerList(
[
Block(
dim=embed_dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[i],
norm_layer=norm_layer,
) for i in range(depth)
]
)
self.norm = norm_layer(embed_dim) # Classifier head
if class_dim > 0:
self.head = nn.Linear(embed_dim, class_dim)
trunc_normal_(self.cls_token)
self.apply(self._init_weights) def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) def forward_features(self, x):
B = x.shape[0]
x = self.tokens_to_token(x)
cls_tokens = self.cls_token.expand((B, -1, -1))
x = paddle.concat((cls_tokens, x), axis=1)
x = x + self.pos_embed
x = self.pos_drop(x) for blk in self.blocks:
x = blk(x)
x = self.norm(x) return x[:, 0] def forward(self, x):
x = self.forward_features(x) if self.class_dim > 0:
x = self.head(x) return xdef t2t_vit_7(pretrained=False, **kwargs):
model = T2T_ViT(
tokens_type='performer', embed_dim=256, depth=7,
num_heads=4, mlp_ratio=2., **kwargs
) if pretrained:
params = paddle.load('data/data94963/T2T_ViT_7.pdparams')
model.set_dict(params) return modeldef t2t_vit_10(pretrained=False, **kwargs):
model = T2T_ViT(
tokens_type='performer', embed_dim=256, depth=10,
num_heads=4, mlp_ratio=2., **kwargs
) if pretrained:
params = paddle.load('data/data94963/T2T_ViT_10.pdparams')
model.set_dict(params) return modeldef t2t_vit_12(pretrained=False, **kwargs):
model = T2T_ViT(
tokens_type='performer', embed_dim=256, depth=12,
num_heads=4, mlp_ratio=2., **kwargs
) if pretrained:
params = paddle.load('data/data94963/T2T_ViT_12.pdparams')
model.set_dict(params) return modeldef t2t_vit_14(pretrained=False, **kwargs):
model = T2T_ViT(
tokens_type='performer', embed_dim=384, depth=14,
num_heads=6, mlp_ratio=3., **kwargs
) if pretrained:
params = paddle.load('data/data94963/T2T_ViT_14.pdparams')
model.set_dict(params) return modeldef t2t_vit_19(pretrained=False, **kwargs):
model = T2T_ViT(
tokens_type='performer', embed_dim=448, depth=19,
num_heads=7, mlp_ratio=3., **kwargs
) if pretrained:
params = paddle.load('data/data94963/T2T_ViT_19.pdparams')
model.set_dict(params) return modeldef t2t_vit_24(pretrained=False, **kwargs):
model = T2T_ViT(
tokens_type='performer', embed_dim=512, depth=24,
num_heads=8, mlp_ratio=3., **kwargs
) if pretrained:
params = paddle.load('data/data94963/T2T_ViT_24.pdparams')
model.set_dict(params) return modelmodel = t2t_vit_7(True) random_input = paddle.randn((1, 3, 224, 224)) out = model(random_input)print(out.shape) model.eval() out = model(random_input)print(out.shape)
[1, 1000] [1, 1000]
!mkdir ~/data/ILSVRC2012 !tar -xf ~/data/data68594/ILSVRC2012_img_val.tar -C ~/data/ILSVRC2012
import osimport cv2import numpy as npimport paddleimport paddle.vision.transforms as Tfrom PIL import Image# 构建数据集class ILSVRC2012(paddle.io.Dataset):
def __init__(self, root, label_list, transform, backend='pil'):
self.transform = transform
self.root = root
self.label_list = label_list
self.backend = backend
self.load_datas() def load_datas(self):
self.imgs = []
self.labels = [] with open(self.label_list, 'r') as f: for line in f:
img, label = line[:-1].split(' ')
self.imgs.append(os.path.join(self.root, img))
self.labels.append(int(label)) def __getitem__(self, idx):
label = self.labels[idx]
image = self.imgs[idx] if self.backend=='cv2':
image = cv2.imread(image) else:
image = Image.open(image).convert('RGB')
image = self.transform(image) return image.astype('float32'), np.array(label).astype('int64') def __len__(self):
return len(self.imgs)
val_transforms = T.Compose([
T.Resize(248, interpolation='bicubic'),
T.CenterCrop(224),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 配置模型model = t2t_vit_7(pretrained=True)
model = paddle.Model(model)
model.prepare(metrics=paddle.metric.Accuracy(topk=(1, 5)))# 配置数据集val_dataset = ILSVRC2012('data/ILSVRC2012', transform=val_transforms, label_list='data/data68594/val_list.txt', backend='pil')# 模型验证acc = model.evaluate(val_dataset, batch_size=768, num_workers=0, verbose=1)print(acc)Eval begin...
The loss value printed in the log is the current batch, and the metric is the average value of previous step.
step 66/66 [==============================] - acc_top1: 0.7168 - acc_top5: 0.9089 - 8s/step
Eval samples: 50000
{'acc_top1': 0.71676, 'acc_top5': 0.90886}以上就是Paddle2.0:浅析并实现 T2T-ViT 模型的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 317
317

























