本文改进注意力多尺度特征融合卷积神经网络,加入基于style的重新校准模块(SRM),通过样式池提取特征图通道样式信息,经通道无关的style集成估计权重,增强CNN表示能力且参数少。用Caltech101的16类数据集,对比VGG19、ResNet50等模型,改进模型性能提升较明显。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

① 项目背景
本文改进了注意力多尺度特征融合卷积神经网络,加入了一种基于style的重新校准模块(SRM),可以通过利用其style自适应地重新校准中间特征图。 SRM首先通过样式池从特征图的每个通道中提取样式信息,然后通过与通道无关的style集成来估计每个通道的重新校准权重。通过将各个style的相对重要性纳入特征图,SRM有效地增强了CNN的表示能力。重点是轻量级,引入的参数非常少,同时效果还不错。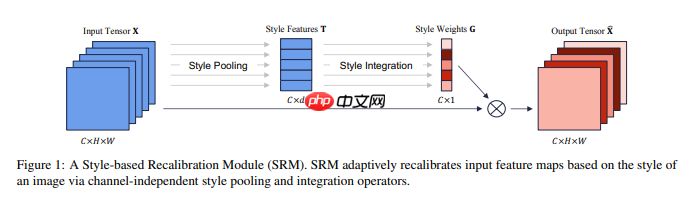
论文地址:https://arxiv.org/pdf/1903.10829.pdf
In [1]
!unzip -oq /home/aistudio/data/data69664/Images.zip -d work/dataset
In [2]
import paddleimport numpy as npfrom typing import Callable#参数配置config_parameters = { "class_dim": 16, #分类数
"target_path":"/home/aistudio/work/",
'train_image_dir': '/home/aistudio/work/trainImages', 'eval_image_dir': '/home/aistudio/work/evalImages', 'epochs':100, 'batch_size': 32, 'lr': 0.01}2.2 划分数据集
接下来我们使用标注好的文件进行数据集类的定义,方便后续模型训练使用。
In [3]
import osimport shutil
train_dir = config_parameters['train_image_dir']
eval_dir = config_parameters['eval_image_dir']
paths = os.listdir('work/dataset/Images')if not os.path.exists(train_dir):
os.mkdir(train_dir)if not os.path.exists(eval_dir):
os.mkdir(eval_dir)for path in paths:
imgs_dir = os.listdir(os.path.join('work/dataset/Images', path))
target_train_dir = os.path.join(train_dir,path)
target_eval_dir = os.path.join(eval_dir,path) if not os.path.exists(target_train_dir):
os.mkdir(target_train_dir) if not os.path.exists(target_eval_dir):
os.mkdir(target_eval_dir) for i in range(len(imgs_dir)): if ' ' in imgs_dir[i]:
new_name = imgs_dir[i].replace(' ', '_') else:
new_name = imgs_dir[i]
target_train_path = os.path.join(target_train_dir, new_name)
target_eval_path = os.path.join(target_eval_dir, new_name)
if i % 5 == 0:
shutil.copyfile(os.path.join(os.path.join('work/dataset/Images', path), imgs_dir[i]), target_eval_path) else:
shutil.copyfile(os.path.join(os.path.join('work/dataset/Images', path), imgs_dir[i]), target_train_path)print('finished train val split!')finished train val split!
2.3 数据集定义与数据集展示
2.3.1 数据集展示
我们先看一下解压缩后的数据集长成什么样子,对比分析经典模型在Caltech101抽取16类mini版数据集上的效果
In [5]
import osimport randomfrom matplotlib import pyplot as pltfrom PIL import Image
imgs = []
paths = os.listdir('work/dataset/Images')for path in paths:
img_path = os.path.join('work/dataset/Images', path) if os.path.isdir(img_path):
img_paths = os.listdir(img_path)
img = Image.open(os.path.join(img_path, random.choice(img_paths)))
imgs.append((img, path))
f, ax = plt.subplots(4, 4, figsize=(12,12))for i, img in enumerate(imgs[:16]):
ax[i//4, i%4].imshow(img[0])
ax[i//4, i%4].axis('off')
ax[i//4, i%4].set_title('label: %s' % img[1])
plt.show()2.3.2 导入数据集的定义实现
In [6]
#数据集的定义class Dataset(paddle.io.Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, transforms: Callable, mode: str ='train'):
"""
步骤二:实现构造函数,定义数据读取方式
"""
super(Dataset, self).__init__()
self.mode = mode
self.transforms = transforms
train_image_dir = config_parameters['train_image_dir']
eval_image_dir = config_parameters['eval_image_dir']
train_data_folder = paddle.vision.DatasetFolder(train_image_dir)
eval_data_folder = paddle.vision.DatasetFolder(eval_image_dir)
if self.mode == 'train':
self.data = train_data_folder elif self.mode == 'eval':
self.data = eval_data_folder def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
data = np.array(self.data[index][0]).astype('float32')
data = self.transforms(data)
label = np.array([self.data[index][1]]).astype('int64')
return data, label
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.data)In [7]
from paddle.vision import transforms as T#数据增强transform_train =T.Compose([T.Resize((256,256)), #T.RandomVerticalFlip(10),
#T.RandomHorizontalFlip(10),
T.RandomRotation(10),
T.Transpose(),
T.Normalize(mean=[0, 0, 0], # 像素值归一化
std =[255, 255, 255]), # transforms.ToTensor(), # transpose操作 + (img / 255),并且数据结构变为PaddleTensor
T.Normalize(mean=[0.50950350, 0.54632660, 0.57409690],# 减均值 除标准差
std= [0.26059777, 0.26041326, 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
transform_eval =T.Compose([ T.Resize((256,256)),
T.Transpose(),
T.Normalize(mean=[0, 0, 0], # 像素值归一化
std =[255, 255, 255]), # transforms.ToTensor(), # transpose操作 + (img / 255),并且数据结构变为PaddleTensor
T.Normalize(mean=[0.50950350, 0.54632660, 0.57409690],# 减均值 除标准差
std= [0.26059777, 0.26041326, 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
In [8]
train_dataset =Dataset(mode='train',transforms=transform_train)
eval_dataset =Dataset(mode='eval', transforms=transform_eval )#数据异步加载train_loader = paddle.io.DataLoader(train_dataset,
places=paddle.CUDAPlace(0),
batch_size=32,
shuffle=True, #num_workers=2,
#use_shared_memory=True
)
eval_loader = paddle.io.DataLoader (eval_dataset,
places=paddle.CUDAPlace(0),
batch_size=32, #num_workers=2,
#use_shared_memory=True
)print('训练集样本量: {},验证集样本量: {}'.format(len(train_loader), len(eval_loader)))训练集样本量: 45,验证集样本量: 12
③ 模型选择和开发
3.1 对比网络构建
本次我们选取了经典的卷积神经网络resnet50,vgg19,mobilenet_v2来进行实验比较。
In [ ]
network = paddle.vision.models.vgg19(num_classes=16)#模型封装model = paddle.Model(network)#模型可视化model.summary((-1, 3,256 , 256))
In [ ]
network = paddle.vision.models.resnet50(num_classes=16)#模型封装model2 = paddle.Model(network)#模型可视化model2.summary((-1, 3,256 , 256))
3.2 对比网络训练
In [12]
#优化器选择class SaveBestModel(paddle.callbacks.Callback):
def __init__(self, target=0.5, path='work/best_model', verbose=0):
self.target = target
self.epoch = None
self.path = path def on_epoch_end(self, epoch, logs=None):
self.epoch = epoch def on_eval_end(self, logs=None):
if logs.get('acc') > self.target:
self.target = logs.get('acc')
self.model.save(self.path) print('best acc is {} at epoch {}'.format(self.target, self.epoch))
callback_visualdl = paddle.callbacks.VisualDL(log_dir='work/vgg19')
callback_savebestmodel = SaveBestModel(target=0.5, path='work/best_model')
callbacks = [callback_visualdl, callback_savebestmodel]
base_lr = config_parameters['lr']
epochs = config_parameters['epochs']def make_optimizer(parameters=None):
momentum = 0.9
learning_rate= paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=base_lr, T_max=epochs, verbose=False)
weight_decay=paddle.regularizer.L2Decay(0.0001)
optimizer = paddle.optimizer.Momentum(
learning_rate=learning_rate,
momentum=momentum,
weight_decay=weight_decay,
parameters=parameters) return optimizer
optimizer = make_optimizer(model.parameters())
model.prepare(optimizer,
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
model.fit(train_loader,
eval_loader,
epochs=100,
batch_size=1, # 是否打乱样本集
callbacks=callbacks,
verbose=1) # 日志展示格式3.3 改进的注意力多尺度特征融合卷积神经网络SRM-Inception-Net
3.3.1 SRM模块的介绍
SRM首先通过样式池从特征图的每个通道中提取样式信息,然后通过与通道无关的style集成来估计每个通道的重新校准权重。通过将各个style的相对重要性纳入特征图,SRM有效地增强了CNN的表示能力。重点是轻量级,引入的参数非常少,其中Style Pooling是avgpool和stdpool拼接,Style Intergration就是一个自适应加权融合.
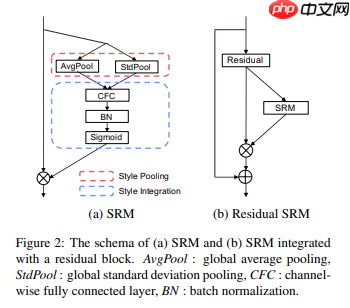
图1 SRM模块细节示意图
In [9]
import paddle.nn as nnclass srm_layer(nn.Layer):
def __init__(self, channel):
super(srm_layer, self).__init__()
self.cfc = self.create_parameter(shape=[channel, 2], default_initializer=nn.initializer.Assign(paddle.zeros([channel, 2])))
self.bn = nn.BatchNorm2D(channel)
self.activation = nn.Sigmoid() setattr(self.cfc, 'srm_param', True) setattr(self.bn.weight, 'srm_param', True) setattr(self.bn.bias, 'srm_param', True) def _style_pooling(self, x, eps=1e-5):
N, C, _, _ = x.shape
channel_mean = paddle.mean(paddle.reshape(x, [N, C, -1]), axis=2, keepdim=True)
channel_var = paddle.var(paddle.reshape(x, [N, C, -1]), axis=2, keepdim=True) + eps
channel_std = paddle.sqrt(channel_var)
t = paddle.concat((channel_mean, channel_std), axis=2) return t
def _style_integration(self, t):
z = t*paddle.reshape(self.cfc, [-1, self.cfc.shape[0], self.cfc.shape[1]])
tmp = paddle.sum(z, axis=2)
z = paddle.reshape(tmp, [tmp.shape[0], tmp.shape[1], 1, 1]) # B x C x 1 x 1
z_hat = self.bn(z)
g = self.activation(z_hat) return g def forward(self, x):
# B x C x 2
t = self._style_pooling(x) # B x C x 1 x 1
g = self._style_integration(t) return x * g3.3.2 注意力多尺度特征融合卷积神经网络的搭建
In [10]
import paddle.nn.functional as F# 构建模型(Inception层)class Inception(paddle.nn.Layer):
def __init__(self, in_channels, c1, c2, c3, c4):
super(Inception, self).__init__() # 路线1,卷积核1x1
self.route1x1_1 = paddle.nn.Conv2D(in_channels, c1, kernel_size=1) # 路线2,卷积层1x1、卷积层3x3
self.route1x1_2 = paddle.nn.Conv2D(in_channels, c2[0], kernel_size=1)
self.route3x3_2 = paddle.nn.Conv2D(c2[0], c2[1], kernel_size=3, padding=1) # 路线3,卷积层1x1、卷积层5x5
self.route1x1_3 = paddle.nn.Conv2D(in_channels, c3[0], kernel_size=1)
self.route5x5_3 = paddle.nn.Conv2D(c3[0], c3[1], kernel_size=5, padding=2) # 路线4,池化层3x3、卷积层1x1
self.route3x3_4 = paddle.nn.MaxPool2D(kernel_size=3, stride=1, padding=1)
self.route1x1_4 = paddle.nn.Conv2D(in_channels, c4, kernel_size=1) def forward(self, x):
route1 = F.relu(self.route1x1_1(x))
route2 = F.relu(self.route3x3_2(F.relu(self.route1x1_2(x))))
route3 = F.relu(self.route5x5_3(F.relu(self.route1x1_3(x))))
route4 = F.relu(self.route1x1_4(self.route3x3_4(x)))
out = [route1, route2, route3, route4] return paddle.concat(out, axis=1) # 在通道维度(axis=1)上进行连接# 构建 BasicConv2d 层def BasicConv2d(in_channels, out_channels, kernel, stride=1, padding=0):
layer = paddle.nn.Sequential(
paddle.nn.Conv2D(in_channels, out_channels, kernel, stride, padding),
paddle.nn.BatchNorm2D(out_channels, epsilon=1e-3),
paddle.nn.ReLU()) return layer# 搭建网络class TowerNet(paddle.nn.Layer):
def __init__(self, in_channel, num_classes):
super(TowerNet, self).__init__()
self.b1 = paddle.nn.Sequential(
BasicConv2d(in_channel, out_channels=64, kernel=3, stride=2, padding=1),
paddle.nn.MaxPool2D(2, 2))
self.b2 = paddle.nn.Sequential(
BasicConv2d(64, 128, kernel=3, padding=1),
paddle.nn.MaxPool2D(2, 2))
self.b3 = paddle.nn.Sequential(
BasicConv2d(128, 256, kernel=3, padding=1),
paddle.nn.MaxPool2D(2, 2),
srm_layer(256))
self.b4 = paddle.nn.Sequential(
BasicConv2d(256, 256, kernel=3, padding=1),
paddle.nn.MaxPool2D(2, 2),
srm_layer(256))
self.b5 = paddle.nn.Sequential(
Inception(256, 64, (64, 128), (16, 32), 32),
paddle.nn.MaxPool2D(2, 2),
srm_layer(256),
Inception(256, 64, (64, 128), (16, 32), 32),
paddle.nn.MaxPool2D(2, 2),
srm_layer(256),
Inception(256, 64, (64, 128), (16, 32), 32))
self.AvgPool2D=paddle.nn.AvgPool2D(2)
self.flatten=paddle.nn.Flatten()
self.b6 = paddle.nn.Linear(256, num_classes) def forward(self, x):
x = self.b1(x)
x = self.b2(x)
x = self.b3(x)
x = self.b4(x)
x = self.b5(x)
x = self.AvgPool2D(x)
x = self.flatten(x)
x = self.b6(x) return xIn [11]
model = paddle.Model(TowerNet(3, config_parameters['class_dim'])) model.summary((-1, 3, 256, 256))
④改进模型的训练和优化器的选择
In [12]
#优化器选择class SaveBestModel(paddle.callbacks.Callback):
def __init__(self, target=0.5, path='work/best_model', verbose=0):
self.target = target
self.epoch = None
self.path = path def on_epoch_end(self, epoch, logs=None):
self.epoch = epoch def on_eval_end(self, logs=None):
if logs.get('acc') > self.target:
self.target = logs.get('acc')
self.model.save(self.path) print('best acc is {} at epoch {}'.format(self.target, self.epoch))
callback_visualdl = paddle.callbacks.VisualDL(log_dir='work/SRM_Inception_Net')
callback_savebestmodel = SaveBestModel(target=0.5, path='work/best_model')
callbacks = [callback_visualdl, callback_savebestmodel]
base_lr = config_parameters['lr']
epochs = config_parameters['epochs']def make_optimizer(parameters=None):
momentum = 0.9
learning_rate= paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=base_lr, T_max=epochs, verbose=False)
weight_decay=paddle.regularizer.L2Decay(0.0002)
optimizer = paddle.optimizer.Momentum(
learning_rate=learning_rate,
momentum=momentum,
weight_decay=weight_decay,
parameters=parameters) return optimizer
optimizer = make_optimizer(model.parameters())In [13]
model.prepare(optimizer,
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())In [14]
model.fit(train_loader,
eval_loader,
epochs=100,
batch_size=1, # 是否打乱样本集
callbacks=callbacks,
verbose=1) # 日志展示格式⑤模型训练效果展示
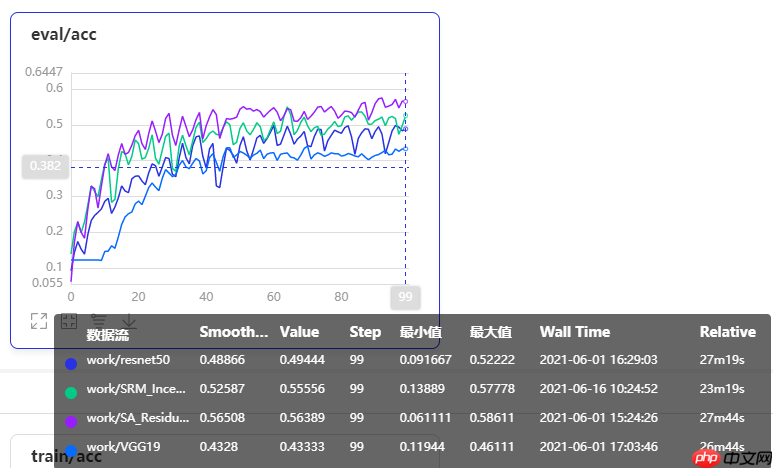
绿色曲线为本次改进模型训练曲线,在增加了SRM模块的注意力机制后,性能和其他经典网络有了较大幅度的提升,但相较于SA注意力机制还稍差些。