






本项目在计算机视觉领域,针对空间和通道注意力机制,改进模型识别能力。通过解压数据集并划分训练集与验证集,定义数据集并展示。选取经典卷积神经网络对比,同时构建含SA模块的注意力残差卷积网络,经训练优化,改进模型性能较经典网络有大幅提升。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

① 项目背景
计算机视觉领域的注意力机制主要涵盖空间注意力和通道注意力两个方面。其中空间注意力用来捕获像素间的关系,而通道注意力用来捕获通道间的关系。
在网络结构方面,含有注意力机制的卷积网络主要有两种体现形式,一种是完整的将注意力和卷积相结合的网络结构,在本项目中的SA是一种可以在已有卷积网络中即插即用的网络模块,通过对模型增加SA注意力模块以及残差模块改进模型的识别能力。
In [ ]
# !unzip -oq /home/aistudio/data/data69664/Images.zip -d work/dataset
In [ ]
import paddleimport numpy as npfrom typing import Callable#参数配置config_parameters = { "class_dim": 16, #分类数
"target_path":"/home/aistudio/work/",
'train_image_dir': '/home/aistudio/work/trainImages', 'eval_image_dir': '/home/aistudio/work/evalImages', 'epochs':100, 'batch_size': 32, 'lr': 0.01}2.2 划分数据集与数据集的定义
接下来我们使用标注好的文件进行数据集类的定义,方便后续模型训练使用。
2.2.1 划分数据集
In [ ]
import osimport shutil
train_dir = config_parameters['train_image_dir']
eval_dir = config_parameters['eval_image_dir']
paths = os.listdir('work/dataset/Images')if not os.path.exists(train_dir):
os.mkdir(train_dir)if not os.path.exists(eval_dir):
os.mkdir(eval_dir)for path in paths:
imgs_dir = os.listdir(os.path.join('work/dataset/Images', path))
target_train_dir = os.path.join(train_dir,path)
target_eval_dir = os.path.join(eval_dir,path) if not os.path.exists(target_train_dir):
os.mkdir(target_train_dir) if not os.path.exists(target_eval_dir):
os.mkdir(target_eval_dir) for i in range(len(imgs_dir)): if ' ' in imgs_dir[i]:
new_name = imgs_dir[i].replace(' ', '_') else:
new_name = imgs_dir[i]
target_train_path = os.path.join(target_train_dir, new_name)
target_eval_path = os.path.join(target_eval_dir, new_name)
if i % 5 == 0:
shutil.copyfile(os.path.join(os.path.join('work/dataset/Images', path), imgs_dir[i]), target_eval_path) else:
shutil.copyfile(os.path.join(os.path.join('work/dataset/Images', path), imgs_dir[i]), target_train_path)print('finished train val split!')finished train val split!
2.3 数据集定义与数据集展示
2.3.1 数据集展示
我们先看一下解压缩后的数据集长成什么样子,对比分析经典模型在Caltech101抽取16类mini版数据集上的效果
In [ ]
import osimport randomfrom matplotlib import pyplot as pltfrom PIL import Image
imgs = []
paths = os.listdir('work/dataset/Images')for path in paths:
img_path = os.path.join('work/dataset/Images', path) if os.path.isdir(img_path):
img_paths = os.listdir(img_path)
img = Image.open(os.path.join(img_path, random.choice(img_paths)))
imgs.append((img, path))
f, ax = plt.subplots(4, 4, figsize=(12,12))for i, img in enumerate(imgs[:16]):
ax[i//4, i%4].imshow(img[0])
ax[i//4, i%4].axis('off')
ax[i//4, i%4].set_title('label: %s' % img[1])
plt.show()2.3.2 导入数据集的定义实现
In [ ]
#数据集的定义class Dataset(paddle.io.Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, transforms: Callable, mode: str ='train'):
"""
步骤二:实现构造函数,定义数据读取方式
"""
super(Dataset, self).__init__()
self.mode = mode
self.transforms = transforms
train_image_dir = config_parameters['train_image_dir']
eval_image_dir = config_parameters['eval_image_dir']
train_data_folder = paddle.vision.DatasetFolder(train_image_dir)
eval_data_folder = paddle.vision.DatasetFolder(eval_image_dir)
if self.mode == 'train':
self.data = train_data_folder elif self.mode == 'eval':
self.data = eval_data_folder def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
data = np.array(self.data[index][0]).astype('float32')
data = self.transforms(data)
label = np.array([self.data[index][1]]).astype('int64')
return data, label
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.data)In [ ]
from paddle.vision import transforms as T#数据增强transform_train =T.Compose([T.Resize((256,256)), #T.RandomVerticalFlip(10),
#T.RandomHorizontalFlip(10),
T.RandomRotation(10),
T.Transpose(),
T.Normalize(mean=[0, 0, 0], # 像素值归一化
std =[255, 255, 255]), # transforms.ToTensor(), # transpose操作 + (img / 255),并且数据结构变为PaddleTensor
T.Normalize(mean=[0.50950350, 0.54632660, 0.57409690],# 减均值 除标准差
std= [0.26059777, 0.26041326, 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
transform_eval =T.Compose([ T.Resize((256,256)),
T.Transpose(),
T.Normalize(mean=[0, 0, 0], # 像素值归一化
std =[255, 255, 255]), # transforms.ToTensor(), # transpose操作 + (img / 255),并且数据结构变为PaddleTensor
T.Normalize(mean=[0.50950350, 0.54632660, 0.57409690],# 减均值 除标准差
std= [0.26059777, 0.26041326, 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
In [ ]
train_dataset =Dataset(mode='train',transforms=transform_train)
eval_dataset =Dataset(mode='eval', transforms=transform_eval )#数据异步加载train_loader = paddle.io.DataLoader(train_dataset,
places=paddle.CUDAPlace(0),
batch_size=32,
shuffle=True, #num_workers=2,
#use_shared_memory=True
)
eval_loader = paddle.io.DataLoader (eval_dataset,
places=paddle.CUDAPlace(0),
batch_size=32, #num_workers=2,
#use_shared_memory=True
)print('训练集样本量: {},验证集样本量: {}'.format(len(train_loader), len(eval_loader)))训练集样本量: 45,验证集样本量: 12
③ 模型选择和开发
3.1 对比网络构建
本次我们选取了经典的卷积神经网络resnet50,vgg19,mobilenet_v2来进行实验比较。
In [43]
network = paddle.vision.models.vgg19(num_classes=16)#模型封装model = paddle.Model(network)#模型可视化model.summary((-1, 3,256 , 256))
3.2 对比网络训练
In [44]
#优化器选择class SaveBestModel(paddle.callbacks.Callback):
def __init__(self, target=0.5, path='work/best_model', verbose=0):
self.target = target
self.epoch = None
self.path = path def on_epoch_end(self, epoch, logs=None):
self.epoch = epoch def on_eval_end(self, logs=None):
if logs.get('acc') > self.target:
self.target = logs.get('acc')
self.model.save(self.path) print('best acc is {} at epoch {}'.format(self.target, self.epoch))
callback_visualdl = paddle.callbacks.VisualDL(log_dir='work/vgg19')
callback_savebestmodel = SaveBestModel(target=0.5, path='work/best_model')
callbacks = [callback_visualdl, callback_savebestmodel]
base_lr = config_parameters['lr']
epochs = config_parameters['epochs']def make_optimizer(parameters=None):
momentum = 0.9
learning_rate= paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=base_lr, T_max=epochs, verbose=False)
weight_decay=paddle.regularizer.L2Decay(0.0001)
optimizer = paddle.optimizer.Momentum(
learning_rate=learning_rate,
momentum=momentum,
weight_decay=weight_decay,
parameters=parameters) return optimizer
optimizer = make_optimizer(model.parameters())
model.prepare(optimizer,
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
model.fit(train_loader,
eval_loader,
epochs=100,
batch_size=1, # 是否打乱样本集
callbacks=callbacks,
verbose=1) # 日志展示格式3.3 改进的注意力残差卷积网络SA-Residual-Inception-Net
3.3.1 SA模块的介绍
SA-NET是2021年ICASSP上的一篇论文SA-Net: Shuffle Attention for Deep Convolutional Neural Networks中提出的基于注意力机制的卷积网络模型。
SA-NET网络的核心思想是提出了SA模块。该模块对分组卷积的每个组采取通道分割。对于通道注意力分支,采用全局平均池化产生通道相关的统计信息,然后使用参数来缩放和平移通道矢量并生成通道特征表达。对于空间注意力分支,采用组归一化来产生空间相关的统计信息并生成空间特征表达。将两个分支的特征合并后,使用channel shuffle操作来进行不同子特征间的通信。如图9所示。
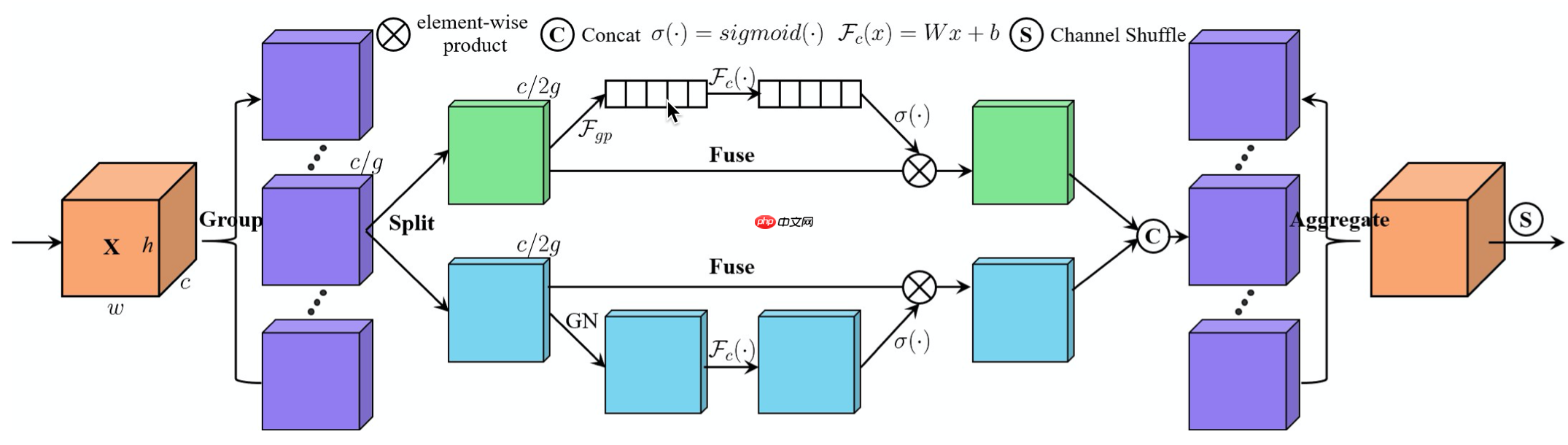
图9 SA模块细节示意图
3.3.2 注意力残差卷积网络的搭建
In [45]
import paddle.nn as nnclass sa_layer(nn.Layer):
"""Constructs a Channel Spatial Group module.
Args:
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, groups=64):
super(sa_layer, self).__init__()
self.groups = groups
self.avg_pool = nn.AdaptiveAvgPool2D(1)
self.cweight = self.create_parameter(shape=[1, channel // (2 * groups), 1, 1],default_initializer=paddle.nn.initializer.Assign(paddle.zeros([1, channel // (2 * groups), 1, 1])))#paddle.nn.initializer.Assign=初始化参数
self.cbias = self.create_parameter(shape=[1, channel // (2 * groups), 1, 1],default_initializer=paddle.nn.initializer.Assign(paddle.ones([1, channel // (2 * groups), 1, 1])))#paddle.zeros=全为0的tensor
self.sweight = self.create_parameter(shape=[1, channel // (2 * groups), 1, 1],default_initializer=paddle.nn.initializer.Assign(paddle.zeros([1, channel // (2 * groups), 1, 1])))
self.sbias = self.create_parameter(shape=[1, channel // (2 * groups), 1, 1],default_initializer=paddle.nn.initializer.Assign(paddle.ones([1, channel // (2 * groups), 1, 1])))
self.sigmoid = nn.Sigmoid()
self.gn = nn.GroupNorm(channel // (2 * groups), channel // (2 * groups)) @staticmethod
def channel_shuffle(x, groups):
b, c, h, w = x.shape
x = paddle.reshape(x, [b, groups, -1, h, w])# x.shape=[1,2,3,4] -1为x全部元素相乘然后除其他元素
x = paddle.transpose(x, [0, 2, 1, 3, 4]) # flatten
x = paddle.reshape(x, [b, -1, h, w]) return x def forward(self, x):
b, c, h, w = x.shape
x = paddle.reshape(x, [b * self.groups, -1, h, w])
x_0, x_1 = paddle.chunk(x, 2, axis=1) # channel attention
xn = self.avg_pool(x_0)
xn = self.cweight * xn + self.cbias
xn = x_0 * self.sigmoid(xn) # spatial attention
xs = self.gn(x_1)
xs = self.sweight * xs + self.sbias
xs = x_1 * self.sigmoid(xs) # concatenate along channel axis
out = paddle.concat([xn, xs], axis=1)
out = paddle.reshape(out, [b, -1, h, w])
out = self.channel_shuffle(out, 2) return outIn [ ]
import paddle.nn.functional as F# 构建模型(Inception层)class Inception(paddle.nn.Layer):
def __init__(self, in_channels, c1, c2, c3, c4):
super(Inception, self).__init__() # 路线1,卷积核1x1
self.route1x1_1 = paddle.nn.Conv2D(in_channels, c1, kernel_size=1) # 路线2,卷积层1x1、卷积层3x3
self.route1x1_2 = paddle.nn.Conv2D(in_channels, c2[0], kernel_size=1)
self.route3x3_2 = paddle.nn.Conv2D(c2[0], c2[1], kernel_size=3, padding=1) # 路线3,卷积层1x1、卷积层5x5
self.route1x1_3 = paddle.nn.Conv2D(in_channels, c3[0], kernel_size=1)
self.route5x5_3 = paddle.nn.Conv2D(c3[0], c3[1], kernel_size=5, padding=2) # 路线4,池化层3x3、卷积层1x1
self.route3x3_4 = paddle.nn.MaxPool2D(kernel_size=3, stride=1, padding=1)
self.route1x1_4 = paddle.nn.Conv2D(in_channels, c4, kernel_size=1) def forward(self, x):
route1 = F.relu(self.route1x1_1(x))
route2 = F.relu(self.route3x3_2(F.relu(self.route1x1_2(x))))
route3 = F.relu(self.route5x5_3(F.relu(self.route1x1_3(x))))
route4 = F.relu(self.route1x1_4(self.route3x3_4(x)))
out = [route1, route2, route3, route4] return paddle.concat(out, axis=1) # 在通道维度(axis=1)上进行连接# 构建 BasicConv2d 层def BasicConv2d(in_channels, out_channels, kernel, stride=1, padding=0):
layer = paddle.nn.Sequential(
paddle.nn.Conv2D(in_channels, out_channels, kernel, stride, padding),
paddle.nn.BatchNorm2D(out_channels, epsilon=1e-3),
paddle.nn.ReLU()) return layerclass Residual(paddle.nn.Layer):
def __init__(self, in_channel, out_channel, stride=1):
super(Residual, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channel, out_channel, kernel_size=1, stride=1)
self.b5 = paddle.nn.Sequential(Inception(256, 64, (64, 128), (16, 32), 32)) def forward(self, x):
y = self.b5(x)
x = self.conv1(x)
out = F.relu(y+x) #核心代码
return out# 搭建网络class TowerNet(paddle.nn.Layer):
def __init__(self, in_channel, num_classes):
super(TowerNet, self).__init__()
self.b1 = paddle.nn.Sequential(
BasicConv2d(in_channel, out_channels=64, kernel=3, stride=2, padding=1),
paddle.nn.MaxPool2D(2, 2))
self.b2 = paddle.nn.Sequential(
BasicConv2d(64, 128, kernel=3, padding=1),
paddle.nn.MaxPool2D(2, 2))
self.b3 = paddle.nn.Sequential(
BasicConv2d(128, 256, kernel=3, padding=1),
paddle.nn.MaxPool2D(2, 2),
sa_layer(256))
self.b4 = paddle.nn.Sequential(
BasicConv2d(256, 256, kernel=3, padding=1),
paddle.nn.MaxPool2D(2, 2),
sa_layer(256))
self.b5 = paddle.nn.Sequential(
Residual(256,256),
paddle.nn.MaxPool2D(2, 2),
sa_layer(256),
Residual(256,256),
paddle.nn.MaxPool2D(2, 2),
sa_layer(256),
Residual(256,256))
self.AvgPool2D=paddle.nn.AvgPool2D(2)
self.flatten=paddle.nn.Flatten()
self.b6 = paddle.nn.Linear(256, num_classes) def forward(self, x):
x = self.b1(x)
x = self.b2(x)
x = self.b3(x)
x = self.b4(x)
x = self.b5(x)
x = self.AvgPool2D(x)
x = self.flatten(x)
x = self.b6(x) return xIn [ ]
model = paddle.Model(TowerNet(3, config_parameters['class_dim'])) model.summary((-1, 3, 256, 256))
④ 改进模型的训练和优化器的选择
In [ ]
#优化器选择class SaveBestModel(paddle.callbacks.Callback):
def __init__(self, target=0.5, path='work/best_model1', verbose=0):
self.target = target
self.epoch = None
self.path = path def on_epoch_end(self, epoch, logs=None):
self.epoch = epoch def on_eval_end(self, logs=None):
if logs.get('acc') > self.target:
self.target = logs.get('acc')
self.model.save(self.path) print('best acc is {} at epoch {}'.format(self.target, self.epoch))
callback_visualdl = paddle.callbacks.VisualDL(log_dir='work/SA_Residual_Inception_Net1')
callback_savebestmodel = SaveBestModel(target=0.5, path='work/best_model1')
callbacks = [callback_visualdl, callback_savebestmodel]
base_lr = config_parameters['lr']
epochs = config_parameters['epochs']def make_optimizer(parameters=None):
momentum = 0.9
learning_rate= paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=base_lr, T_max=epochs, verbose=False)
weight_decay=paddle.regularizer.L2Decay(0.0002)
optimizer = paddle.optimizer.Momentum(
learning_rate=learning_rate,
momentum=momentum,
weight_decay=weight_decay,
parameters=parameters) return optimizer
optimizer = make_optimizer(model.parameters())In [ ]
model.prepare(optimizer,
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())In [ ]
model.fit(train_loader,
eval_loader,
epochs=100,
batch_size=1, # 是否打乱样本集
callbacks=callbacks,
verbose=1) # 日志展示格式⑤模型训练效果展示及总结
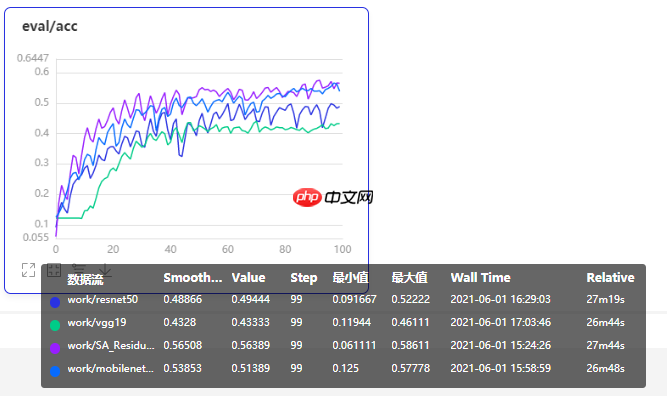
紫色曲线为本次改进模型训练曲线,在增加了SA模块的注意力机制后,性能和其他经典网络有了较大幅度的提升。




























