






什么是BERT?
bert的全称为bidirectional encoder representation from transformers,是一个预训练的语言表征模型。
它强调了不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练,而是采用新的masked language model(MLM),因此能生成深度的双向语言表征。
该模型有以下主要优点:
1)采用MLM对双向的Transformers进行预训练,以生成深层的双向语言表征。
2)预训练后,只需要添加一个额外的输出层进行fine-tune,就可以在各种各样的下游任务中取得state-of-the-art的表现。在这过程中并不需要对BERT进行任务特定的结构修改。
BERT模型结构
以往的预训练模型的结构会受到单向语言模型(从左到右或者从右到左)的限制,因而也限制了模型的表征能力,使其只能获取单方向的上下文信息。
而BERT利用MLM进行预训练并且采用深层的双向Transformer组件来构建整个模型,因此最终生成能融合左右上下文信息的深层双向语言表征。
注:单向的Transformer一般被称为Transformer decoder,其每一个token(符号)只会attend到目前往左的token。而双向的Transformer则被称为Transformer encoder,其每一个token会attend到所有的token。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
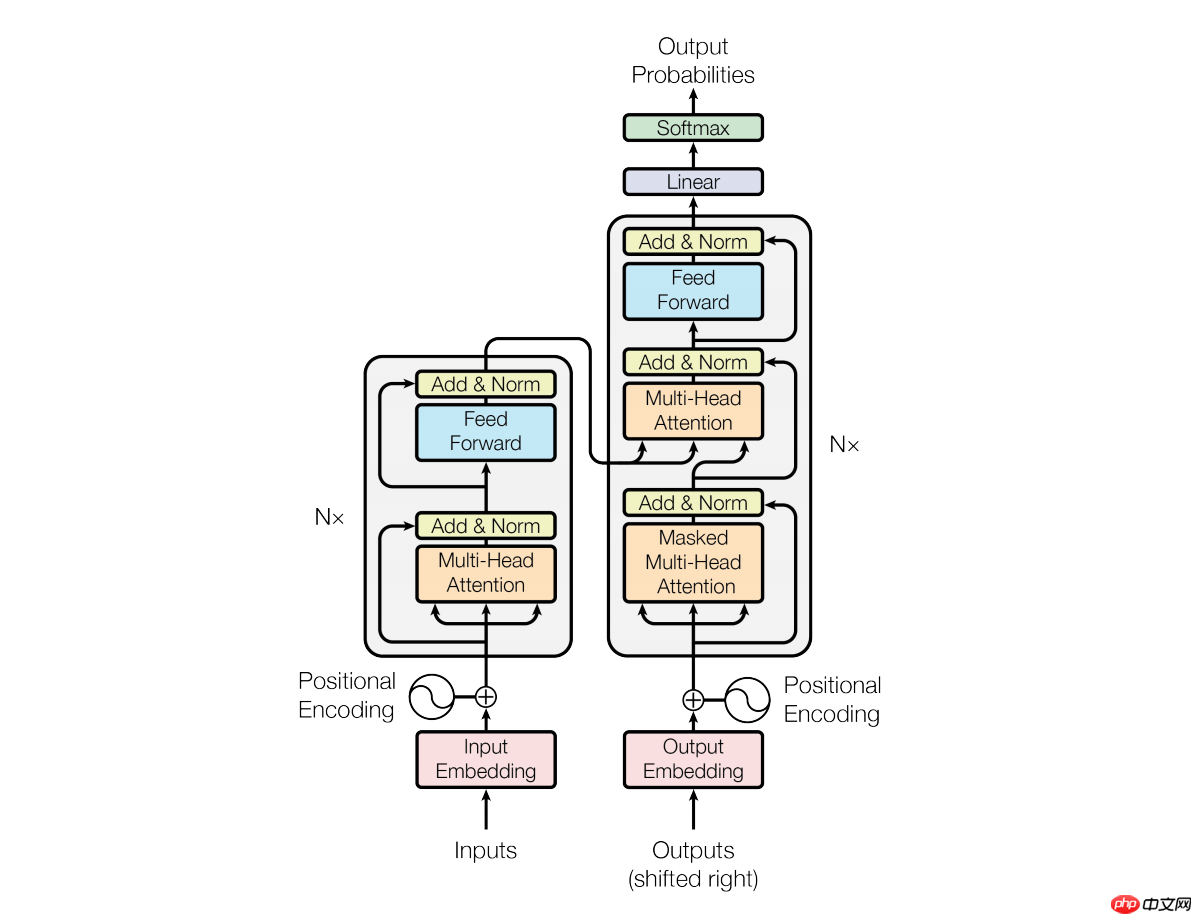
当隐藏了Transformer的详细结构后,我们用一个只有输入和输出的黑盒子来表示它,并且,Transformer又可以进行堆叠,形成一个更深的神经网络:
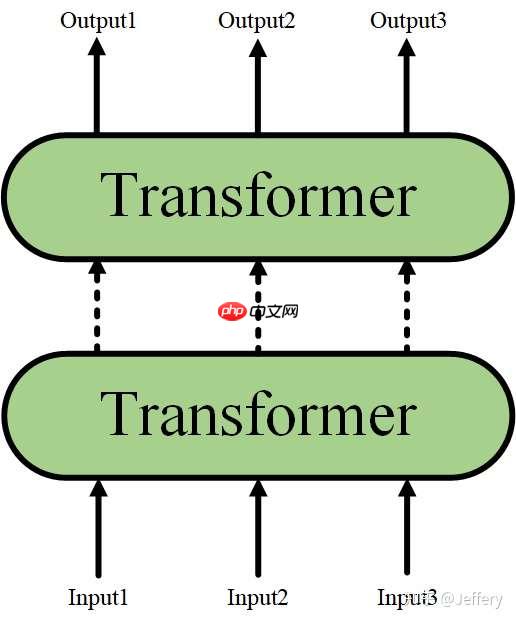
最终,经过多层Transformer结构的堆叠后,形成BERT的主体结构:
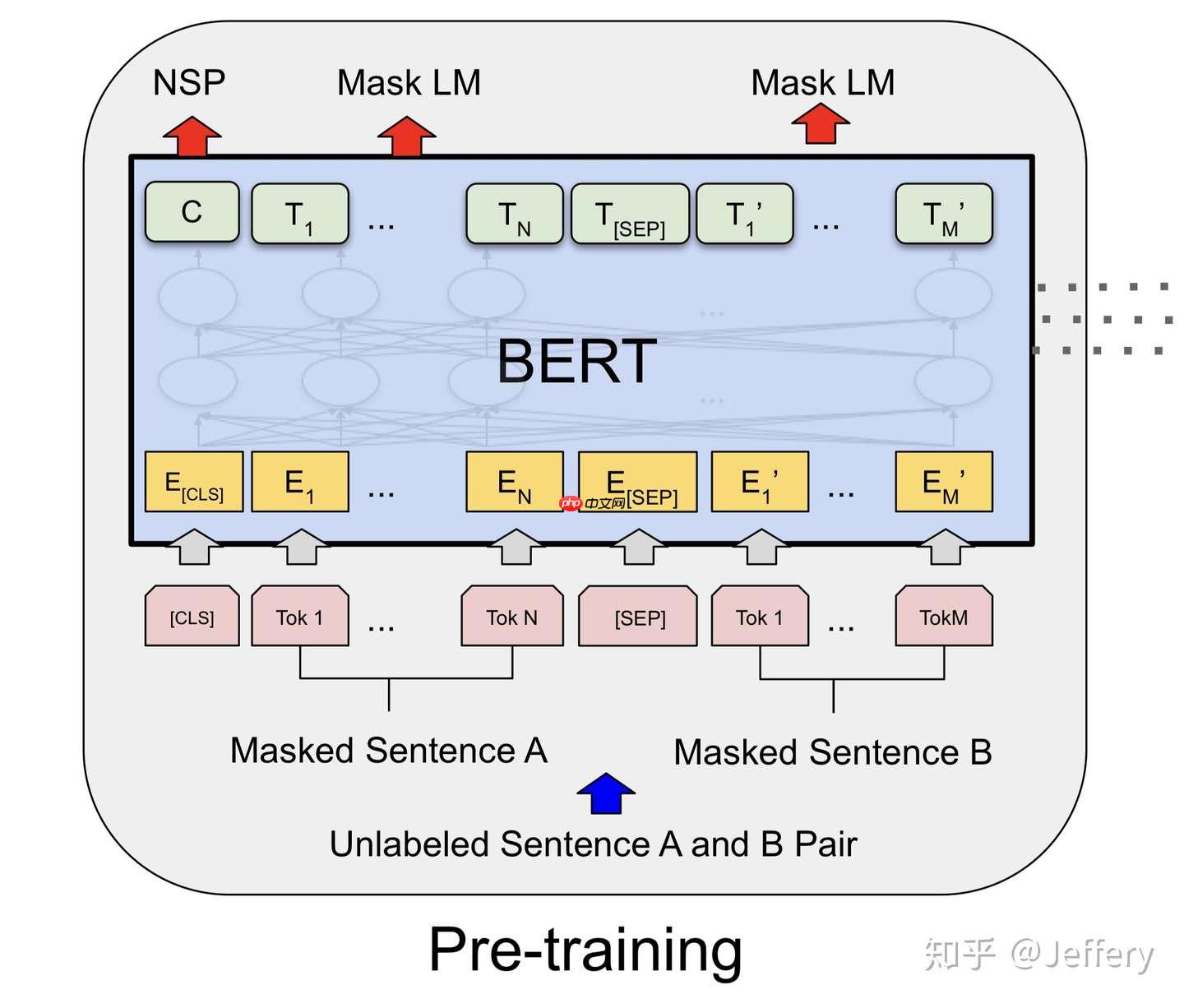
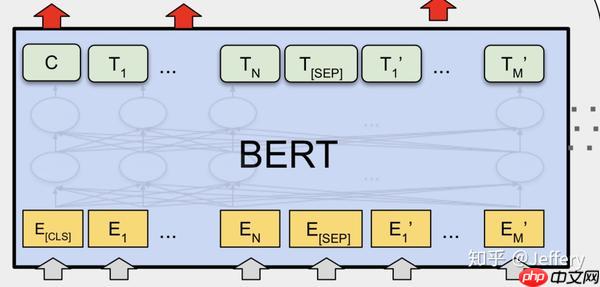
对于不同的下游任务,BERT的结构可能会有不同的轻微变化,因此接下来介绍预训练阶段的模型结构。
Embedding
BERT中,Embedding由三种Embedding求和而成:
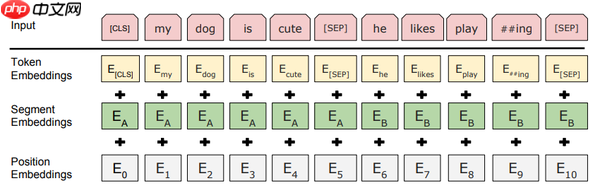
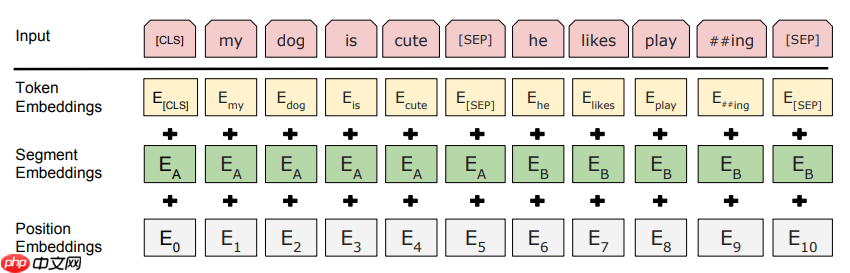
其中:
- Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
第一个预训练任务: Masked Language Model
第一步预训练的目标就是做语言模型,从上文模型结构中看到了这个模型的不同,即bidirectional。
Q:为什么要如此的bidirectional?
A:如果使用预训练模型处理其他任务,那人们想要的肯定不止某个词左边的信息,而是左右两边的信息。而考虑到这点的模型ELMo只是将left-to-right和right-to-left分别训练拼接起来。
直觉上来讲我们其实想要一个deeply bidirectional的模型,但是普通的LM又无法做到,因为在训练时可能会“穿越”,所以作者用了一个加mask的trick。
参考:作者在reddit上的解释。
在训练过程中作者随机mask 15%的token,而不是把像cbow一样把每个词都预测一遍。最终的损失函数只计算被mask掉那个token。

Mask如何做也是有技巧的,如果一直用标记[MASK]代替(在实际预测时是碰不到这个标记的)会影响模型,所以随机mask的时候10%的单词会被替代成其他单词,10%的单词不替换,剩下80%才被替换为[MASK]。要注意的是Masked LM预训练阶段模型是不知道真正被mask的是哪个词,所以模型每个词都要关注。
因为序列长度太大(512)会影响训练速度,所以90%的steps都用seq_len=128训练,余下的10%步数训练512长度的输入。
第二个预训练任务: Next Sentence Prediction
因为涉及到QA和NLI之类的任务,增加了第二个预训练任务,目的是让模型理解两个句子之间的联系。训练的输入是句子A和B,B有一半的几率是A的下一句,输入这两个句子,模型预测B是不是A的下一句。预训练的时候可以达到97%-98%的准确度。
注意:作者特意说了语料的选取很关键,要选用document-level的而不是sentence-level的,这样可以具备抽象连续长序列特征的能力。
Fine-tunning
分类:对于sequence-level的分类任务,BERT直接取第一个[CLS]token的final hidden state  ,加一层权重
,加一层权重  后softmax预测label proba:
后softmax预测label proba: 
其他预测任务需要进行一些调整,如图:
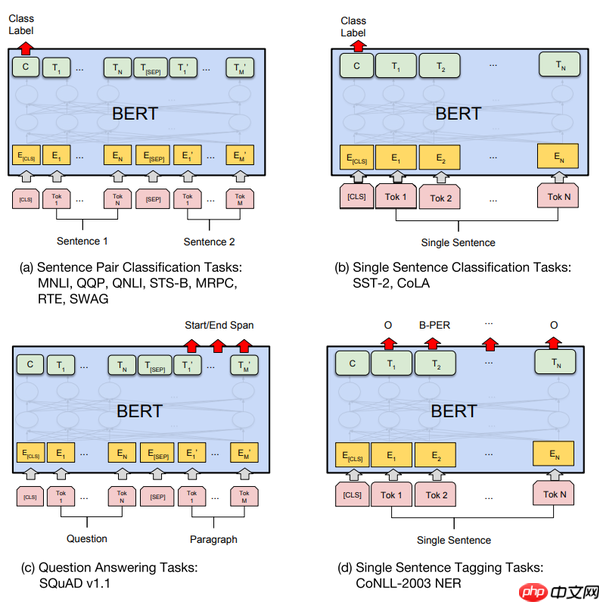
可以调整的参数和取值范围有:
- Batch size: 16, 32
- Learning rate (Adam): 5e-5, 3e-5, 2e-5
- Number of epochs: 3, 4
因为大部分参数都和预训练时一样,精调会快一些,所以作者推荐多试一些参数。
PaddleNLP2.0上BERT模型的应用
一键加载预训练模型
在PaddleNLP Transformer API中,为用户提供了常用的BERT、ERNIE、ALBERT、RoBERTa、XLNet经典结构预训练模型,让开发者能够方便快捷应用各类Transformer预训练模型及其下游任务。 目前PaddleNLP支持的BERT预训练模型,可以完成问答、文本分类、序列标注、文本生成等任务。同时PaddleNLP还提供了预训练的参数权重,其中也包含了中文语言模型的预训练权重。
| Model | Tokenizer | Supported Task | Pretrained Weight |
|---|---|---|---|
| BERT | BertTokenizer | BertModel BertForQuestionAnswering BertForSequenceClassification BertForTokenClassification |
bert-base-uncased bert-large-uncased bert-base-multilingual-uncased bert-base-cased bert-base-chinese bert-base-multilingual-cased bert-large-cased bert-wwm-chinese bert-wwm-ext-chinese |
NOTE:其中中文的预训练模型有bert-base-chinese, bert-wwm-chinese, bert-wwm-ext-chinese。
预训练模型适用任务汇总
本小节按照模型适用的不同任务类型,对上表Transformer预训练模型汇总的Task进行分类汇总。主要包括文本分类、序列标注、问答任务、文本生成、机器翻译等。
| 任务 | 模型 | 应用场景 | 预训练权重 |
|---|---|---|---|
| 文本分类 SequenceClassification |
BertForSequenceClassification | 文本分类、阅读理解等 | 见上表 |
| 序列标注 TokenClassification |
BertForTokenClassification | 命名实体标注等 | 见上表 |
| 问答任务 QuestionAnswering |
BertForQuestionAnswering | 阅读理解等 | 见上表 |
注意事项
由于PaddleNLP迭代较快,API变动也比较大,因此,参考PaddleNLP的文档进行开发时,一定要注意依赖库的版本问题。比如要使用下面这个文档中提供的BERT预训练模型使用方法,就一定要从源码安装安装最新的PaddleNLP develop分支。from functools import partialimport numpy as npimport paddlefrom paddlenlp.datasets import load_datasetfrom paddlenlp.transformers import BertForSequenceClassification, BertTokenizer
train_ds, dev_ds, test_ds = load_dataset("chnsenticorp", splits=["train", "dev", "test"])
model = BertForSequenceClassification.from_pretrained("bert-wwm-chinese", num_classes=len(train_ds.label_list))
tokenizer = BertTokenizer.from_pretrained("bert-wwm-chinese")def convert_example(example, tokenizer):
encoded_inputs = tokenizer(text=example["text"], max_seq_len=512, pad_to_max_seq_len=True) return tuple([np.array(x, dtype="int64") for x in [
encoded_inputs["input_ids"], encoded_inputs["token_type_ids"], [example["label"]]]])
train_ds = train_ds.map(partial(convert_example, tokenizer=tokenizer))
batch_sampler = paddle.io.BatchSampler(dataset=train_ds, batch_size=8, shuffle=True)
train_data_loader = paddle.io.DataLoader(dataset=train_ds, batch_sampler=batch_sampler, return_list=True)
optimizer = paddle.optimizer.AdamW(learning_rate=0.001, parameters=model.parameters())
criterion = paddle.nn.loss.CrossEntropyLoss()for input_ids, token_type_ids, labels in train_data_loader():
logits = model(input_ids, token_type_ids)
loss = criterion(logits, labels)
probs = paddle.nn.functional.softmax(logits, axis=1)
loss.backward()
optimizer.step()
optimizer.clear_grad()
典型报错信息与解决方案
这里总结了一些最近使用BERT模型进行finetune常见的报错信息和解决方案。数据集加载问题
/opt/conda/envs/python35-paddle120-env/lib/python3.7/importlib/__init__.py in import_module(name, package)
125 break
126 level += 1
--> 127 return _bootstrap._gcd_import(name[level:], package, level)
128
129
/opt/conda/envs/python35-paddle120-env/lib/python3.7/importlib/_bootstrap.py in _gcd_import(name, package, level)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/importlib/_bootstrap.py in _find_and_load(name, import_)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/importlib/_bootstrap.py in _find_and_load_unlocked(name, import_)
ModuleNotFoundError: No module named 'paddlenlp.datasets.experimental.chnsenticorp'
问题原因:paddlenlp.datasets.experimental.chnsenticorp这个API,目前是最新的PaddleNLP develop分支才有。 解决方案:下面两种方案二选一。
- 安装最新的PaddleNLP develop分支。
- 使用原有API加载chnsenticorp数据集:
train_ds, dev_ds, test_ds = ppnlp.datasets.ChnSentiCorp.get_datasets(['train','dev','test'])#获得标签列表label_list = train_ds.get_labels()
token_type_ids问题
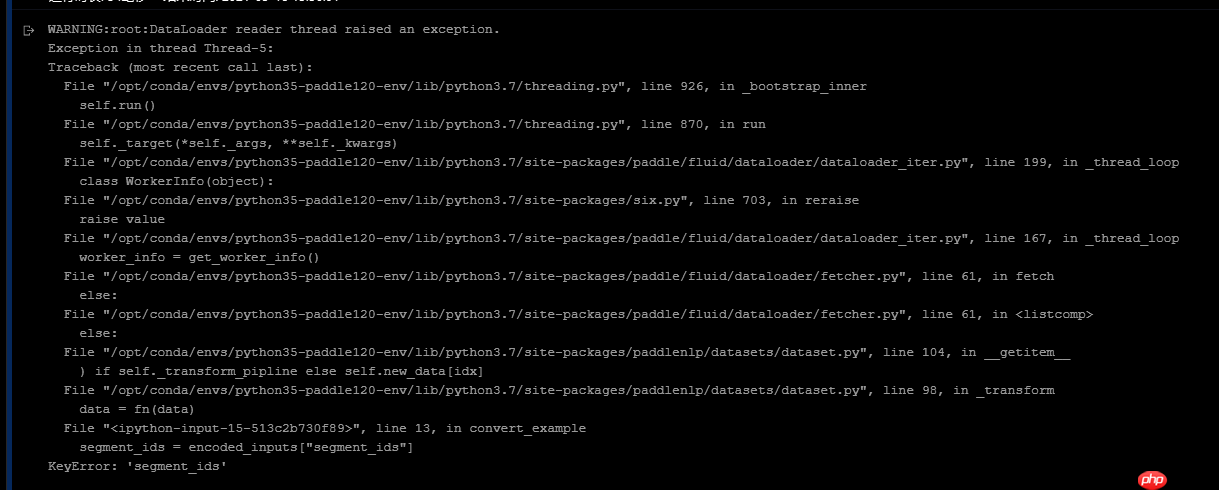 报错代码:
报错代码:
#数据预处理def convert_example(example,tokenizer,label_list,max_seq_length=256,is_test=False):
if is_test:
text = example else:
text, label = example #tokenizer.encode方法能够完成切分token,映射token ID以及拼接特殊token
encoded_inputs = tokenizer.encode(text=text, max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
segment_ids = encoded_inputs["segment_ids"]
其实报错信息提示已经比较明显了,就是encoded_inputs里没有segment_ids,其原因是现在PaddleNLP的tokenizer返回内容里不再是segment_ids,而是token_type_ids,参考最新文档里的写法:
def convert_example(example, tokenizer):
encoded_inputs = tokenizer(text=example["text"], max_seq_len=512, pad_to_max_seq_len=True) return tuple([np.array(x, dtype="int64") for x in [
encoded_inputs["input_ids"], encoded_inputs["token_type_ids"], [example["label"]]]])
所以,解决方案就是将segment_ids改为token_type_ids即可。
数据集格式问题
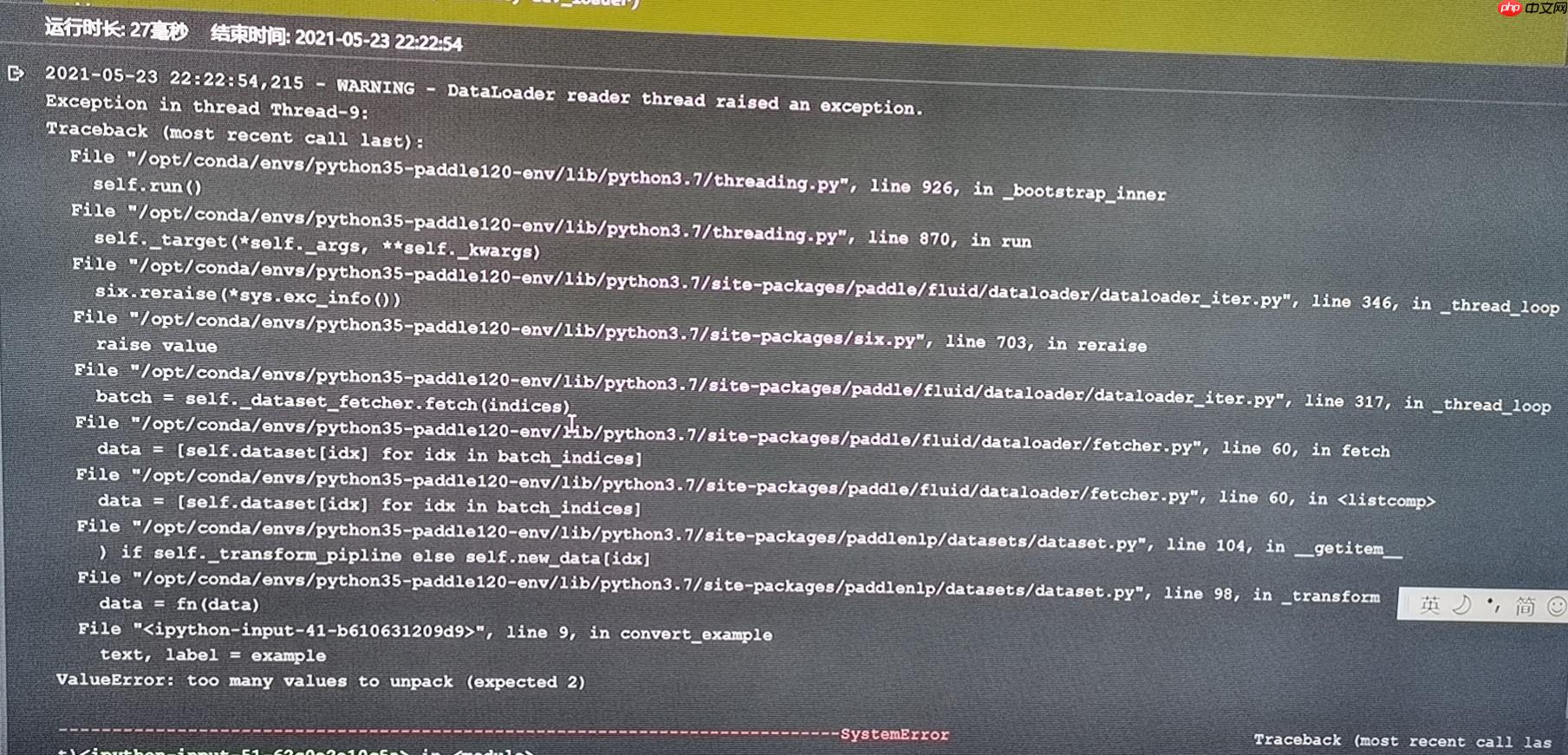 这是个短文本分类任务,检查训练集和测试集,发现数据格式如下:
这是个短文本分类任务,检查训练集和测试集,发现数据格式如下:
文本 0 文本 1 0 文本 1
说明是因为遇到了脏数据,将脏数据清洗掉即可。




























