






本文介绍了Deep Layer Aggregation(DLA)模型,将聚合定义为网络不同层的组合,提出深度可聚合结构,通过迭代深层聚合(IDA)和分层深度聚合(HDA)融合特征。迁移了官方模型代码和预训练参数,验证了精度。还展示了模型细节、搭建、精度验证及训练示例,指出DLA能以较少参数和计算量获更高精度。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

引入
- 本文将聚合 aggregation 定义为跨越整个网络的不同层之间的组合。
- 在这篇文章中,作者团队把注意力放在一族可以更有效的聚合深度、分辨率和尺度的网络。
- 本文将可以组合的、非线性的、最先聚合的层可以通过多次聚合在整个网络中传递的结构称为深度可聚合的。
- 由于网络可以包含许多层和连接,模组化设计可以通过分组与复制来克服网络过于复杂的问题。
- 层组合为块,块根据其特征分辨率组合成层级。
- 本文主要探讨如何聚合块与层级(换句话说层级间的网络保持一致的分辨率,而语义融合一般发生在层级内,空间融合一般发生在层级间)。
项目说明
- 本项目迁移官方实现的模型代码和预训练模型参数文件
- 模型前向计算结果与官方实现无明显差异,预训练模型的精度与官方实现和论文标称的精度对齐
- 暂未也不打算重新进行模型训练,欢迎大家自行进行训练验证
- 如果项目中有任何问题,也欢迎大家在评论区留言交流
相关资料
论文:Deep Layer Aggregation
官方实现:ucbdrive/dla
-
验证集数据处理:
# 图像后端: pil# 输入大小: 224x224transforms = T.Compose([ T.Resize(256, interpolation='bilinear'), T.CenterCrop(224), T.ToTensor(), T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) -
模型细节:
Model Model Name Params (M) FLOPs (G) Top-1 (%) Top-5 (%) Pretrained Model DLA-34 dla_34 15.8 3.1 76.39 93.15 Download DLA-46-c dla_46_c 1.3 0.5 64.88 86.29 Download DLA-46x-c dla_46x_c 1.1 0.5 65.98 86.98 Download DLA-60 dla_60 22.0 4.2 77.02 93.31 Download DLA-60x dla_60x 17.4 3.5 78.24 94.02 Download DLA-60x-c dla_60x_c 1.3 0.6 67.91 88.43 Download DLA-102 dla_102 33.3 7.2 79.44 94.76 Download DLA-102x dla_102x 26.4 5.9 78.51 94.23 Download DLA-102x2 dla_102x2 41.4 9.3 79.45 94.64 Download DLA-169 dla_169 53.5 11.6 78.71 94.34 Download
- 其中 DLA-34、DLA-102 两个模型的预训练参数为官方提供的增加了 tricks 的预训练模型,精度会相比论文中的标称精度高一些
概述
- 视觉识别需要丰富的表示形式,其范围从低到高,范围从小到大,分辨率从精细到粗糙。
- 即使卷积网络中的要素深度很深,仅靠隔离层还是不够的:将这些表示法进行复合和聚合可改善对内容和位置的推断。
- 尽管已合并了残差连接以组合各层,但是这些连接本身是“浅”的,并且只能通过简单的一步操作来融合。
- 作者通过更深层的聚合来增强标准体系结构,以更好地融合各层的信息。
- Deep Layer Aggregation 结构迭代地和分层地合并了特征层次结构,以使网络具有更高的准确性和更少的参数。
- 跨体系结构和任务的实验表明,与现有的分支和合并方案相比,Deep Layer Aggregation 可提高识别和分辨率。
深层聚合(Deep Layer Aggregation)
- 首先,我们将聚合定义为网络中不同层之间的连接。
- 在这项工作中,我们专注于一系列架构,以有效地聚合深度,分辨率和尺度。
迭代深层聚合(Iterative Deep Aggregation)
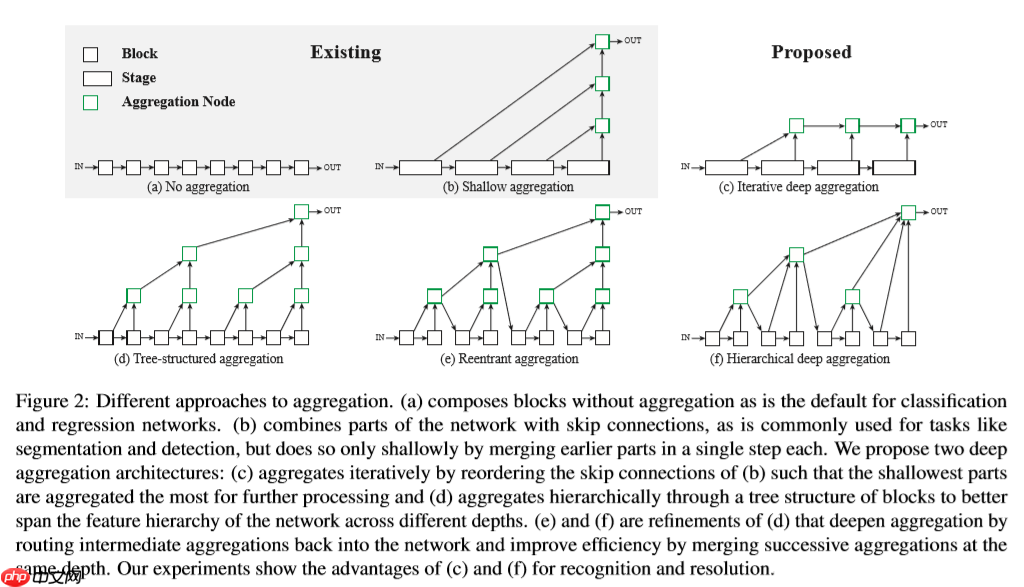
- 首先通过网络中堆叠的块根据分辨率划分为多个阶段。深层阶段的语义信息很丰富但是空间上比较粗糙。将低层阶段通过跳跃连接到高层阶段来融合尺寸和分辨率。但现有的跳跃连接都是线性的,并且最浅层的聚合最少,如图(b)。因此,我们提出IDA来聚合并加深特征的代表。聚合从最浅,最小的尺度开始,然后迭代地合并更深,更大的尺度。通过这种方式,浅层特征被重新定义,因为它们通过不同的聚合阶段传播。

x1,x2,,,xn代表n层,N是聚合结点。
分层深度聚合(Hierarchical Deep Aggregation)
- HDA通过融合在树形中块和阶段来保存并且结合特征通道。通过HDA将较浅和较深的层组合在一起,以学习跨越更多特征层次结构的更丰富的组合。尽管IDA在阶段方面的融合很有效果,但是在网络中多个块之间融合并不有效。IDA仅仅通过融合阶段是远远不够的,因为它还是顺序的。层次聚合的深层分支结构如图2(d)。
- 有了HDA的大体结构,我们便可以提高它的深度以及效率。通过将聚合节点的输出作为下一个子树的输入反馈到主干中,来代替仅将中间聚合路由到树的上方。也就是说将前两个块聚合后的结果反馈到骨干网络中继续参加训练。如此一来便会聚合所有先前的块而不是仅仅聚合前一个块。为提高效率,我们聚合了具有相同深度的结点,将父亲和左子树连接。
- HDA的公式如下:


N代表聚合节点。B代表一个卷积块。
聚合元素
聚合节点
- 聚合节点的作用是融合并压缩输入。聚合节点学着去选择并且处理重要的信息保证在输出中保持相同的维度作为单个输入。
- 在我们的结构中,IDA一直都是二进制的,HDA节点具有可变数量的参数,具体取决于树的深度。虽然聚合节点可以基于任何块或层,但为了简单和高效,我们选择单个卷积,然后进行批量归一化和非线性。这避免了聚合结构的开销。
- 在分类网络中,我们使用1x1卷积作为聚合结点;在语义分割中,我们添加了更多级别的迭代深度聚合来插入特征,在这种情况下使用3×3卷积。
- 另外,由于残差连接在组装深层网络很有效果,因此在我们的聚合节点出同样增加了残差连接。可实验证明残差连接对聚合并没有显著性的效果。在HDA中,从任何块到根的最短路径是层次结构的深度,因此沿着聚合路径可能不会出现递减或爆炸的渐变。在我们的实验中,加入残差可以在层次结构最深的有4层甚至更多的时候帮助到HDA。但同时可能会影响对小一点的层次的效果。在公式1和2中,对节点N的定义如下:


σ是非线性激活。公式4是相对于公式3加了残差连接。
Blocks and Stages(块和阶段)
- 深层融合是一个比较普遍的架构因为它可以和任何一个骨干网络兼容(如ResNet,ResNeXT,Densenet等)。
- 实验中我们使用到了三种不同的残差块:
- Basic blocks(即ResNet)将堆叠卷积与恒等映射跳过连接相结合;
- Bottleneck blocks通过1x1卷积降维;
- Split blocks(即ResNeXT)通过将通道分组为多个单独的路径(称为拆分的基数)来使功能多样化。
- 该工作中,我们将bottleneck和split neck的输出和中间通道数量之比减少一半,基数设置为32。
分类网络
- 分类网络例如ResNet 和ResNeXT都是阶段性的网络,每一个阶段都有多个残差网络组成,阶段之间通过下采样获得特征图。整个网络有32倍的降采样,最后通过对输出进行softmax得分,进而分类。
- 本文中,在阶段之间用IDA,在每个阶段内部使用HDA。通过共享聚合节点可以轻松组合这些类型的聚合。这种情况我们只需通过结合公式1和2来改变每个垂直方向的根节点。在各个阶段之间通过池化进行下采样。
- 对于不同的框架,我们采用不同的处理方式。比如在DRN(带有空洞卷积的ResNet)中,我们将前两个阶段的最大池化代替为多个卷积,阶段1是7x7卷积+ basic block,阶段2是basic block。

模型搭建
In [2]
import mathimport paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom paddle.nn.initializer import Constant, Normal# 初始化zeros_ = Constant(value=0.)
ones_ = Constant(value=1.)# 占位层class Identity(nn.Layer):
def __init__(self):
super(Identity, self).__init__() def forward(self, input):
return input# DLA Basic 模块(ConvBNs + Residual)class DlaBasic(nn.Layer):
def __init__(self, inplanes, planes, stride=1, dilation=1, **cargs):
super(DlaBasic, self).__init__()
self.conv1 = nn.Conv2D(
inplanes, planes, kernel_size=3, stride=stride, padding=dilation, bias_attr=False, dilation=dilation)
self.bn1 = nn.BatchNorm2D(planes)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2D(
planes, planes, kernel_size=3, stride=1, padding=dilation, bias_attr=False, dilation=dilation)
self.bn2 = nn.BatchNorm2D(planes)
self.stride = stride def forward(self, x, residual=None):
if residual is None:
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += residual
out = self.relu(out) return out# DLA Bottleneck 模块(ConvBNs + Residual)class DlaBottleneck(nn.Layer):
expansion = 2
def __init__(self, inplanes, outplanes, stride=1, dilation=1, cardinality=1, base_width=64):
super(DlaBottleneck, self).__init__()
self.stride = stride
mid_planes = int(math.floor(
outplanes * (base_width / 64)) * cardinality)
mid_planes = mid_planes // self.expansion
self.conv1 = nn.Conv2D(inplanes, mid_planes,
kernel_size=1, bias_attr=False)
self.bn1 = nn.BatchNorm2D(mid_planes)
self.conv2 = nn.Conv2D(
mid_planes, mid_planes, kernel_size=3, stride=stride, padding=dilation,
bias_attr=False, dilation=dilation, groups=cardinality)
self.bn2 = nn.BatchNorm2D(mid_planes)
self.conv3 = nn.Conv2D(mid_planes, outplanes,
kernel_size=1, bias_attr=False)
self.bn3 = nn.BatchNorm2D(outplanes)
self.relu = nn.ReLU() def forward(self, x, residual=None):
if residual is None:
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += residual
out = self.relu(out) return out# DLA 根节点class DlaRoot(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size, residual):
super(DlaRoot, self).__init__()
self.conv = nn.Conv2D(
in_channels, out_channels, 1, stride=1, bias_attr=False, padding=(kernel_size - 1) // 2)
self.bn = nn.BatchNorm2D(out_channels)
self.relu = nn.ReLU()
self.residual = residual def forward(self, *x):
children = x
x = self.conv(paddle.concat(x, 1))
x = self.bn(x) if self.residual:
x += children[0]
x = self.relu(x) return x# DLA Tree(通过 Tree 的方式来组织模型网络)class DlaTree(nn.Layer):
def __init__(self, levels, block, in_channels, out_channels, stride=1,
dilation=1, cardinality=1, base_width=64,
level_root=False, root_dim=0, root_kernel_size=1, root_residual=False):
super(DlaTree, self).__init__() if root_dim == 0:
root_dim = 2 * out_channels if level_root:
root_dim += in_channels
self.downsample = nn.MaxPool2D(
stride, stride=stride) if stride > 1 else Identity()
self.project = Identity()
cargs = dict(dilation=dilation, cardinality=cardinality,
base_width=base_width) if levels == 1:
self.tree1 = block(in_channels, out_channels, stride, **cargs)
self.tree2 = block(out_channels, out_channels, 1, **cargs) if in_channels != out_channels:
self.project = nn.Sequential(
nn.Conv2D(in_channels, out_channels,
kernel_size=1, stride=1, bias_attr=False),
nn.BatchNorm2D(out_channels)) else:
cargs.update(dict(root_kernel_size=root_kernel_size,
root_residual=root_residual))
self.tree1 = DlaTree(
levels - 1, block, in_channels, out_channels, stride, root_dim=0, **cargs)
self.tree2 = DlaTree(
levels - 1, block, out_channels, out_channels, root_dim=root_dim + out_channels, **cargs) if levels == 1:
self.root = DlaRoot(root_dim, out_channels,
root_kernel_size, root_residual)
self.level_root = level_root
self.root_dim = root_dim
self.levels = levels def forward(self, x, residual=None, children=None):
children = [] if children is None else children
bottom = self.downsample(x)
residual = self.project(bottom) if self.level_root:
children.append(bottom)
x1 = self.tree1(x, residual) if self.levels == 1:
x2 = self.tree2(x1)
x = self.root(x2, x1, *children) else:
children.append(x1)
x = self.tree2(x1, children=children) return x# DLA 模型class DLA(nn.Layer):
def __init__(self, levels, channels, in_chans=3, cardinality=1,
base_width=64, block=DlaBottleneck, residual_root=False,
drop_rate=0.0, class_dim=1000, with_pool=True):
super(DLA, self).__init__()
self.channels = channels
self.class_dim = class_dim
self.with_pool = with_pool
self.cardinality = cardinality
self.base_width = base_width
self.drop_rate = drop_rate
self.base_layer = nn.Sequential(
nn.Conv2D(in_chans, channels[0], kernel_size=7,
stride=1, padding=3, bias_attr=False),
nn.BatchNorm2D(channels[0]),
nn.ReLU())
self.level0 = self._make_conv_level(
channels[0], channels[0], levels[0])
self.level1 = self._make_conv_level(
channels[0], channels[1], levels[1], stride=2)
cargs = dict(cardinality=cardinality,
base_width=base_width, root_residual=residual_root)
self.level2 = DlaTree(
levels[2], block, channels[1], channels[2], 2, level_root=False, **cargs)
self.level3 = DlaTree(
levels[3], block, channels[2], channels[3], 2, level_root=True, **cargs)
self.level4 = DlaTree(
levels[4], block, channels[3], channels[4], 2, level_root=True, **cargs)
self.level5 = DlaTree(
levels[5], block, channels[4], channels[5], 2, level_root=True, **cargs)
self.feature_info = [ # rare to have a meaningful stride 1 level
dict(num_chs=channels[0], reduction=1, module='level0'), dict(num_chs=channels[1], reduction=2, module='level1'), dict(num_chs=channels[2], reduction=4, module='level2'), dict(num_chs=channels[3], reduction=8, module='level3'), dict(num_chs=channels[4], reduction=16, module='level4'), dict(num_chs=channels[5], reduction=32, module='level5'),
]
self.num_features = channels[-1] if with_pool:
self.global_pool = nn.AdaptiveAvgPool2D(1) if class_dim > 0:
self.fc = nn.Conv2D(self.num_features, class_dim, 1) for m in self.sublayers(): if isinstance(m, nn.Conv2D):
n = m._kernel_size[0] * m._kernel_size[1] * m._out_channels
normal_ = Normal(mean=0.0, std=math.sqrt(2. / n))
normal_(m.weight) elif isinstance(m, nn.BatchNorm2D):
ones_(m.weight)
zeros_(m.bias) def _make_conv_level(self, inplanes, planes, convs, stride=1, dilation=1):
modules = [] for i in range(convs):
modules.extend([
nn.Conv2D(inplanes, planes, kernel_size=3, stride=stride if i == 0 else 1,
padding=dilation, bias_attr=False, dilation=dilation),
nn.BatchNorm2D(planes),
nn.ReLU()])
inplanes = planes return nn.Sequential(*modules) def forward_features(self, x):
x = self.base_layer(x)
x = self.level0(x)
x = self.level1(x)
x = self.level2(x)
x = self.level3(x)
x = self.level4(x)
x = self.level5(x) return x def forward(self, x):
x = self.forward_features(x) if self.with_pool:
x = self.global_pool(x) if self.drop_rate > 0.:
x = F.dropout(x, p=self.drop_rate, training=self.training) if self.class_dim > 0:
x = self.fc(x)
x = x.flatten(1) return xdef dla_34(pretrained=False, **kwargs):
model = DLA(
levels=(1, 1, 1, 2, 2, 1),
channels=(16, 32, 64, 128, 256, 512),
block=DlaBasic,
**kwargs
) if pretrained:
params = paddle.load('/home/aistudio/data/data78316/dla34.pdparams')
model.set_dict(params) return modeldef dla_46_c(pretrained=False, **kwargs):
model = DLA(
levels=(1, 1, 1, 2, 2, 1),
channels=(16, 32, 64, 64, 128, 256),
block=DlaBottleneck,
**kwargs
) if pretrained:
params = paddle.load('/home/aistudio/data/data78316/dla46_c.pdparams')
model.set_dict(params) return modeldef dla_46x_c(pretrained=False, **kwargs):
model = DLA(
levels=(1, 1, 1, 2, 2, 1),
channels=(16, 32, 64, 64, 128, 256),
block=DlaBottleneck,
cardinality=32,
base_width=4,
**kwargs
) if pretrained:
params = paddle.load('/home/aistudio/data/data78316/dla46x_c.pdparams')
model.set_dict(params) return modeldef dla_60x_c(pretrained=False, **kwargs):
model = DLA(
levels=(1, 1, 1, 2, 3, 1),
channels=(16, 32, 64, 64, 128, 256),
block=DlaBottleneck,
cardinality=32,
base_width=4,
**kwargs
) if pretrained:
params = paddle.load('/home/aistudio/data/data78316/dla60x_c.pdparams')
model.set_dict(params) return modeldef dla_60(pretrained=False, **kwargs):
model = DLA(
levels=(1, 1, 1, 2, 3, 1),
channels=(16, 32, 128, 256, 512, 1024),
block=DlaBottleneck,
**kwargs
) if pretrained:
params = paddle.load('/home/aistudio/data/data78316/dla60.pdparams')
model.set_dict(params) return modeldef dla_60x(pretrained=False, **kwargs):
model = DLA(
levels=(1, 1, 1, 2, 3, 1),
channels=(16, 32, 128, 256, 512, 1024),
block=DlaBottleneck,
cardinality=32,
base_width=4,
**kwargs
) if pretrained:
params = paddle.load('/home/aistudio/data/data78316/dla60x.pdparams')
model.set_dict(params) return modeldef dla_102(pretrained=False, **kwargs):
model = DLA(
levels=(1, 1, 1, 3, 4, 1),
channels=(16, 32, 128, 256, 512, 1024),
block=DlaBottleneck,
residual_root=True,
**kwargs
) if pretrained:
params = paddle.load('/home/aistudio/data/data78316/dla102.pdparams')
model.set_dict(params) return modeldef dla_102x(pretrained=False, **kwargs):
model = DLA(
levels=(1, 1, 1, 3, 4, 1),
channels=(16, 32, 128, 256, 512, 1024),
block=DlaBottleneck,
cardinality=32,
base_width=4,
residual_root=True,
**kwargs
) if pretrained:
params = paddle.load('/home/aistudio/data/data78316/dla102x.pdparams')
model.set_dict(params) return modeldef dla_102x2(pretrained=False, **kwargs):
model = DLA(
levels=(1, 1, 1, 3, 4, 1),
channels=(16, 32, 128, 256, 512, 1024),
block=DlaBottleneck,
cardinality=64,
base_width=4,
residual_root=True,
**kwargs
) if pretrained:
params = paddle.load('/home/aistudio/data/data78316/dla102x2.pdparams')
model.set_dict(params) return modeldef dla_169(pretrained=False, **kwargs):
model = DLA(
levels=(1, 1, 2, 3, 5, 1),
channels=(16, 32, 128, 256, 512, 1024),
block=DlaBottleneck,
residual_root=True,
**kwargs
) if pretrained:
params = paddle.load('/home/aistudio/data/data78316/dla169.pdparams')
model.set_dict(params) return model
模型精度验证
In [ ]
# 解压数据集!mkdir ~/data/ILSVRC2012 !tar -xf ~/data/data68594/ILSVRC2012_img_val.tar -C ~/data/ILSVRC2012
In [1]
import osimport cv2import numpy as npimport paddleimport paddle.vision.transforms as Tfrom PIL import Image# 构建数据集class ILSVRC2012(paddle.io.Dataset):
def __init__(self, root, label_list, transform, backend='pil'):
self.transform = transform
self.root = root
self.label_list = label_list
self.backend = backend
self.load_datas() def load_datas(self):
self.imgs = []
self.labels = [] with open(self.label_list, 'r') as f: for line in f:
img, label = line[:-1].split(' ')
self.imgs.append(os.path.join(self.root, img))
self.labels.append(int(label)) def __getitem__(self, idx):
label = self.labels[idx]
image = self.imgs[idx] if self.backend=='cv2':
image = cv2.imread(image) else:
image = Image.open(image).convert('RGB')
image = self.transform(image) return image.astype('float32'), np.array(label).astype('int64') def __len__(self):
return len(self.imgs)# 配置模型val_transforms = T.Compose([
T.Resize(256, interpolation='bilinear'),
T.CenterCrop(224),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
model = dla_60(pretrained=True)
model = paddle.Model(model)
model.prepare(metrics=paddle.metric.Accuracy(topk=(1, 5)))# 配置数据集val_dataset = ILSVRC2012('data/ILSVRC2012', transform=val_transforms, label_list='data/data68594/val_list.txt', backend='pil')# 模型验证acc = model.evaluate(val_dataset, batch_size=128, num_workers=0, verbose=0)print(acc)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:143: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations if data.dtype == np.object: /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dataloader/dataloader_iter.py:89: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations if isinstance(slot[0], (np.ndarray, np.bool, numbers.Number)): /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return (isinstance(seq, collections.Sequence) and
模型训练
- 由于 ImageNet 数据集过大,不太好加载
- 这里使用 Cifar100 演示一下模型的训练操作
In [ ]
# 导入 Paddleimport paddleimport paddle.nn as nnimport paddle.vision.transforms as Tfrom paddle.vision import Cifar100# 加载模型model = dla_60(pretrained=True, class_dim=100)# 使用高层 API 进行模型封装model = paddle.Model(model)# 配置优化器opt = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())# 配置损失函数loss = nn.CrossEntropyLoss()# 配置评价指标metric = paddle.metric.Accuracy(topk=(1, 5))# 模型准备model.prepare(optimizer=opt, loss=loss, metrics=metric)# 配置数据增广train_transforms = T.Compose([
T.Resize(256, interpolation='bilinear'),
T.RandomCrop(224),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
val_transforms = T.Compose([
T.Resize(256, interpolation='bilinear'),
T.CenterCrop(224),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 配置数据集train_dataset = Cifar100(mode='train', transform=train_transforms, backend='pil')
val_dataset = Cifar100(mode='test', transform=val_transforms, backend='pil')# 模型微调model.fit(
train_data=train_dataset,
eval_data=val_dataset,
batch_size=64,
epochs=1,
eval_freq=1,
log_freq=1,
save_dir='save_models',
save_freq=1,
verbose=1,
drop_last=False,
shuffle=True,
num_workers=0)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1303: UserWarning: Skip loading for fc.weight. fc.weight receives a shape [1000, 1024, 1, 1], but the expected shape is [100, 1024, 1, 1].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1303: UserWarning: Skip loading for fc.bias. fc.bias receives a shape [1000], but the expected shape is [100].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
Cache file /home/aistudio/.cache/paddle/dataset/cifar/cifar-100-python.tar.gz not found, downloading https://dataset.bj.bcebos.com/cifar/cifar-100-python.tar.gz
Begin to download
Download finished
The loss value printed in the log is the current step, and the metric is the average value of previous step. Epoch 1/1
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:648: UserWarning: When training, we now always track global mean and variance. "When training, we now always track global mean and variance.")
step 782/782 [==============================] - loss: 2.2643 - acc_top1: 0.3284 - acc_top5: 0.6364 - 328ms/step save checkpoint at /home/aistudio/save_models/0 Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 157/157 [==============================] - loss: 2.3870 - acc_top1: 0.4577 - acc_top5: 0.7807 - 171ms/step Eval samples: 10000 save checkpoint at /home/aistudio/save_models/final
模型精度对比
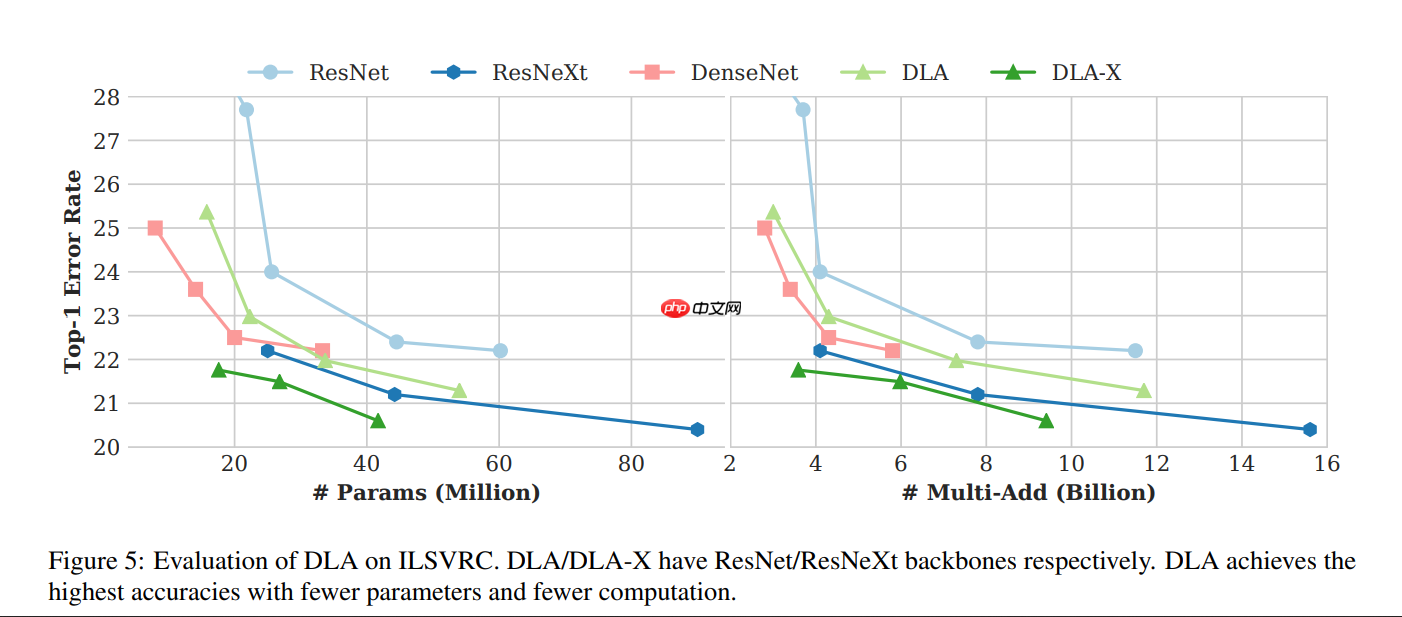
- 对比一些常见的 CNN 模型的结果如下:
总结
- DLA 通过特别设计的多层级的深层聚合模块,提升了模型的精度和效率
- 对比其他常见的 CNN 模型,DLA 可以以较少的参数和较少的计算量获得更高的精度




























