






本文介绍CondenseNet V2模型的实现,该模型基于密集连接,针对DenseNet和CondenseNet特征复用问题,引入稀疏特征重激活,对冗余特征裁剪与更新,提升复用效率。文中给出基于Paddle的代码实现,包括各组件及预设模型,并测试了模型输出,还列出不同模型在ImageNet-1k上的精度表现。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

引入
- 最近各种 Transformer 的视觉模型层出不穷,偶然看到一些新的 CNN 模型居然有一丝小兴奋
- 这次就来大致实现一下 CPVR 2021 新鲜出炉的新模型 —— CondenseNet V2
相关资料
- 论文:CondenseNet V2: Sparse Feature Reactivation for Deep Networks
- 官方实现:jianghaojun/CondenseNetV2
- 参考文章:CVPR2021 | 密集连接网络中的稀疏特征重激活
论文概述
- 本文提出了一种基于密集连接的高效轻量级神经网络。
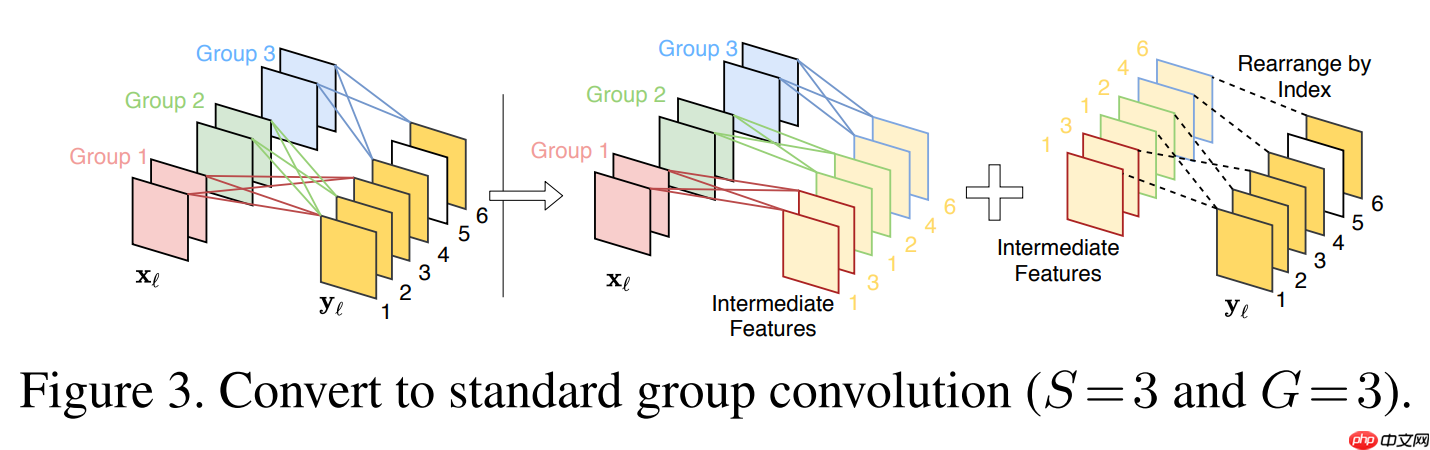
- 针对 DenseNet 的特征复用冗余,CondenseNet 提出利用可学习分组卷积来裁剪掉冗余连接。
- 然而,DenseNet 的和 CondenseNet 中特征一旦产生将不再发生任何更改,这就导致了部分特征的潜在价值被严重忽略。
- 本文提出:与其直接删掉冗余,不妨给冗余特征一个“翻身”机会。
- 因此我们提出一种可学习的稀疏特征重激活的方法,来有选择地更新冗余特征,从而增强特征的复用效率。
- CondenseNet V2 在 CondenseNet 的基础上引入了稀疏特征重激活,对冗余特征同时进行了裁剪和更新,有效提升了密集连接网络的特征复用效率,在图像分类和检测任务上取得的出色表现。
- 更多详情请看上面的参考文章的内容

In [1]
!pip install ppim
In [2]
import paddleimport paddle.nn as nnimport paddle.vision.transforms as Tfrom ppim.models.common import kaiming_normal_, zeros_, ones_class SELayer(nn.Layer):
def __init__(self, inplanes, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2D(1)
self.fc = nn.Sequential(
nn.Linear(inplanes, inplanes // reduction, bias_attr=False),
nn.ReLU(),
nn.Linear(inplanes // reduction, inplanes, bias_attr=False),
nn.Sigmoid()
) def forward(self, x):
b, c, _, _ = x.shape
y = self.avg_pool(x).reshape((b, c))
y = self.fc(y).reshape((b, c, 1, 1)) return x * y.expand_as(x)class HS(nn.Layer):
def __init__(self):
super(HS, self).__init__()
self.relu6 = nn.ReLU6() def forward(self, inputs):
return inputs * self.relu6(inputs + 3) / 6class Conv(nn.Sequential):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, groups=1, activation='ReLU', bn_momentum=0.9):
super(Conv, self).__init__()
self.add_sublayer('norm', nn.BatchNorm2D(
in_channels, momentum=bn_momentum)) if activation == 'ReLU':
self.add_sublayer('activation', nn.ReLU()) elif activation == 'HS':
self.add_sublayer('activation', HS()) else: raise NotImplementedError
self.add_sublayer('conv', nn.Conv2D(in_channels, out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding, bias_attr=False,
groups=groups))def ShuffleLayer(x, groups):
batchsize, num_channels, height, width = x.shape
channels_per_group = num_channels // groups # reshape
x = x.reshape((batchsize, groups, channels_per_group, height, width)) # transpose
x = x.transpose((0, 2, 1, 3, 4)) # reshape
x = x.reshape((batchsize, -1, height, width)) return xdef ShuffleLayerTrans(x, groups):
batchsize, num_channels, height, width = x.shape
channels_per_group = num_channels // groups # reshape
x = x.reshape((batchsize, channels_per_group, groups, height, width)) # transpose
x = x.transpose((0, 2, 1, 3, 4)) # reshape
x = x.reshape((batchsize, -1, height, width)) return xclass CondenseLGC(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, groups=1, activation='ReLU'):
super(CondenseLGC, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.groups = groups
self.norm = nn.BatchNorm2D(self.in_channels) if activation == 'ReLU':
self.activation = nn.ReLU() elif activation == 'HS':
self.activation = HS() else: raise NotImplementedError
self.conv = nn.Conv2D(self.in_channels, self.out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=self.groups,
bias_attr=False)
self.register_buffer('index', paddle.zeros(
(self.in_channels,), dtype='int64')) def forward(self, x):
x = paddle.index_select(x, self.index, axis=1)
x = self.norm(x)
x = self.activation(x)
x = self.conv(x)
x = ShuffleLayer(x, self.groups) return xclass CondenseSFR(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, groups=1, activation='ReLU'):
super(CondenseSFR, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.groups = groups
self.norm = nn.BatchNorm2D(self.in_channels) if activation == 'ReLU':
self.activation = nn.ReLU() elif activation == 'HS':
self.activation = HS() else: raise NotImplementedError
self.conv = nn.Conv2D(self.in_channels, self.out_channels,
kernel_size=kernel_size,
padding=padding,
groups=self.groups,
bias_attr=False,
stride=stride)
self.register_buffer('index', paddle.zeros(
(self.out_channels, self.out_channels))) def forward(self, x):
x = self.norm(x)
x = self.activation(x)
x = ShuffleLayerTrans(x, self.groups)
x = self.conv(x) # SIZE: N, C, H, W
N, C, H, W = x.shape
x = x.reshape((N, C, H * W))
x = x.transpose((0, 2, 1)) # SIZE: N, HW, C
# x SIZE: N, HW, C; self.index SIZE: C, C; OUTPUT SIZE: N, HW, C
x = paddle.matmul(x, self.index)
x = x.transpose((0, 2, 1)) # SIZE: N, C, HW
x = x.reshape((N, C, H, W)) # SIZE: N, C, HW
return xclass _SFR_DenseLayer(nn.Layer):
def __init__(self, in_channels, growth_rate, group_1x1, group_3x3, group_trans, bottleneck, activation, use_se=False):
super(_SFR_DenseLayer, self).__init__()
self.group_1x1 = group_1x1
self.group_3x3 = group_3x3
self.group_trans = group_trans
self.use_se = use_se # 1x1 conv i --> b*k
self.conv_1 = CondenseLGC(in_channels, bottleneck * growth_rate,
kernel_size=1, groups=self.group_1x1,
activation=activation) # 3x3 conv b*k --> k
self.conv_2 = Conv(bottleneck * growth_rate, growth_rate,
kernel_size=3, padding=1, groups=self.group_3x3,
activation=activation) # 1x1 res conv k(8-16-32)--> i (k*l)
self.sfr = CondenseSFR(growth_rate, in_channels, kernel_size=1,
groups=self.group_trans, activation=activation) if self.use_se:
self.se = SELayer(inplanes=growth_rate, reduction=1) def forward(self, x):
x_ = x
x = self.conv_1(x)
x = self.conv_2(x) if self.use_se:
x = self.se(x)
sfr_feature = self.sfr(x)
y = x_ + sfr_feature return paddle.concat([y, x], 1)class _SFR_DenseBlock(nn.Sequential):
def __init__(self, num_layers, in_channels, growth_rate, group_1x1,
group_3x3, group_trans, bottleneck, activation, use_se):
super(_SFR_DenseBlock, self).__init__() for i in range(num_layers):
layer = _SFR_DenseLayer(
in_channels + i * growth_rate, growth_rate, group_1x1, group_3x3, group_trans, bottleneck, activation, use_se)
self.add_sublayer('denselayer_%d' % (i + 1), layer)class _Transition(nn.Layer):
def __init__(self):
super(_Transition, self).__init__()
self.pool = nn.AvgPool2D(kernel_size=2, stride=2) def forward(self, x):
x = self.pool(x) return xclass CondenseNetV2(nn.Layer):
def __init__(self, stages, growth, HS_start_block, SE_start_block, fc_channel, group_1x1,
group_3x3, group_trans, bottleneck, last_se_reduction, class_dim=1000):
super(CondenseNetV2, self).__init__()
self.stages = stages
self.growth = growth
self.class_dim = class_dim
self.last_se_reduction = last_se_reduction assert len(self.stages) == len(self.growth)
self.progress = 0.0
self.init_stride = 2
self.pool_size = 7
self.features = nn.Sequential() # Initial nChannels should be 3
self.num_features = 2 * self.growth[0] # Dense-block 1 (224x224)
self.features.add_sublayer('init_conv', nn.Conv2D(3, self.num_features,
kernel_size=3,
stride=self.init_stride,
padding=1,
bias_attr=False)) for i in range(len(self.stages)):
activation = 'HS' if i >= HS_start_block else 'ReLU'
use_se = True if i >= SE_start_block else False
# Dense-block i
self.add_block(i, group_1x1, group_3x3, group_trans,
bottleneck, activation, use_se)
self.fc = nn.Linear(self.num_features, fc_channel)
self.fc_act = HS() # Classifier layer
if class_dim > 0:
self.classifier = nn.Linear(fc_channel, class_dim)
self._initialize() def add_block(self, i, group_1x1, group_3x3, group_trans, bottleneck, activation, use_se):
# Check if ith is the last one
last = (i == len(self.stages) - 1)
block = _SFR_DenseBlock(
num_layers=self.stages[i],
in_channels=self.num_features,
growth_rate=self.growth[i],
group_1x1=group_1x1,
group_3x3=group_3x3,
group_trans=group_trans,
bottleneck=bottleneck,
activation=activation,
use_se=use_se,
)
self.features.add_sublayer('denseblock_%d' % (i + 1), block)
self.num_features += self.stages[i] * self.growth[i] if not last:
trans = _Transition()
self.features.add_sublayer('transition_%d' % (i + 1), trans) else:
self.features.add_sublayer('norm_last',
nn.BatchNorm2D(self.num_features))
self.features.add_sublayer('relu_last',
nn.ReLU())
self.features.add_sublayer('pool_last',
nn.AvgPool2D(self.pool_size)) # if useSE:
self.features.add_sublayer('se_last',
SELayer(self.num_features, reduction=self.last_se_reduction)) def forward(self, x):
features = self.features(x)
out = features.reshape((features.shape[0], -1))
out = self.fc(out)
out = self.fc_act(out) if self.class_dim > 0:
out = self.classifier(out) return out def _initialize(self):
# initialize
for m in self.sublayers(): if isinstance(m, nn.Conv2D):
kaiming_normal_(m.weight) elif isinstance(m, nn.BatchNorm2D):
ones_(m.weight)
zeros_(m.bias)/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int):
预设模型
In [3]
def cdnv2_a(pretrained=False, **kwargs):
model = CondenseNetV2(
stages=[1, 1, 4, 6, 8],
growth=[8, 8, 16, 32, 64],
HS_start_block=2,
SE_start_block=3,
fc_channel=828,
group_1x1=8,
group_3x3=8,
group_trans=8,
bottleneck=4,
last_se_reduction=16,
**kwargs
) if pretrained:
params = paddle.load('data/data80680/cdnv2_a.pdparams')
model.set_dict(params) return modeldef cdnv2_b(pretrained=False, **kwargs):
model = CondenseNetV2(
stages=[2, 4, 6, 8, 6],
growth=[6, 12, 24, 48, 96],
HS_start_block=2,
SE_start_block=3,
fc_channel=1024,
group_1x1=6,
group_3x3=6,
group_trans=6,
bottleneck=4,
last_se_reduction=16,
**kwargs
) if pretrained:
params = paddle.load('data/data80680/cdnv2_b.pdparams')
model.set_dict(params) return modeldef cdnv2_c(pretrained=False, **kwargs):
model = CondenseNetV2(
stages=[4, 6, 8, 10, 8],
growth=[8, 16, 32, 64, 128],
HS_start_block=2,
SE_start_block=3,
fc_channel=1024,
group_1x1=8,
group_3x3=8,
group_trans=8,
bottleneck=4,
last_se_reduction=16,
**kwargs
) if pretrained:
params = paddle.load('data/data80680/cdnv2_c.pdparams')
model.set_dict(params) return model模型测试
In [5]
model = cdnv2_a() out = model(paddle.randn((1, 3, 224, 224)))print(out.shape) model.eval() out = model(paddle.randn((1, 3, 224, 224)))print(out.shape)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:648: UserWarning: When training, we now always track global mean and variance. "When training, we now always track global mean and variance.")
[1, 1000] [1, 1000]
精度表现
- 具体的模型精度表现如下(ImageNet-1k):
| Model | Model Name | Params (M) | FLOPs (G) | Top-1 (%) | Top-5 (%) | Pretrained Model |
|---|---|---|---|---|---|---|
| CondenseNetV2-A | cdnv2_a | 2.0 | 0.05 | 64.38 | 85.24 | Download |
| CondenseNetV2-B | cdnv2_b | 3.6 | 0.15 | 71.89 | 90.27 | Download |
| CondenseNetV2-C | cdnv2_c | 6.1 | 0.31 | 75.87 | 92.64 | Download |





























