本文围绕风电功率预测赛题展开,介绍了龙源电力提供的数据集,包括数据字段、采集方式及预测时间要求。阐述了用PaddleTS模型库处理数据的流程,如预处理、分析,还讲解了单模型和集成模型的训练、评估、保存等,以及回测、提交说明和常见问题解答。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

本赛题数据集由全球最大风电运营企业龙源电力提供,采集自真实风力发电数据。 预选赛训练数据和区域赛训练数据分别为不同10个风电场近一年的运行数据共30万余条,每15分钟采集一次,包括风速、风向、温度、湿度、气压和真实功率等,具体的数据字段中英文对应如下:
注:预测风速是由权威的气象机构,像是中央气象台、欧洲国家气象中心等发布的商业气象数据源。从时间线来说,实际功率预测需要提前36个小时、72个小时、240的小时等获得数值天气预报,从而进行功率的预测。
考虑到风电场的特殊性,不同风机间的地理位置也是序列预测的一个重要参考价值。但是本次比赛未给出相关信息,因此我们可以考虑用纯时间序列预测生成基线结果。
为更加真实地模拟风电企业生产运行的实际情况,在本次比赛中,用于评测的数据集中,除历史数据外,还会提供预测时间段从天气预报中获得的数据字段,包括:
本基线未使用到上述信息,选手们在优化模型时,可以尝试利用好天气预报数据,以取得更好的预测结果。
PaddleTS是一款基于飞桨深度学习框架的开源时序建模算法库,其具备统一的时序数据结构、全面的基础模型功能、丰富的数据处理和分析算子以及领先的深度时序算法,可以帮助开发者实现时序数据处理、分析、建模、预测全流程,在预测性维护、智慧能耗分析、价格销量预估等场景中有重要应用价值。
本文就以PaddleTS模型库的实现风机功率预测基线开发为例,介绍如何使用模型库快速、批量生成多路时间序列的预测结果。
# 安装模型库!pip install paddlets !pip install ray !pip install optuna
#导入需要的包%matplotlib inlineimport osimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.preprocessing import StandardScaler, MinMaxScalerimport datetimeimport paddletsfrom paddlets import TSDatasetfrom paddlets import TimeSeriesfrom paddlets.models.forecasting import MLPRegressor, LSTNetRegressorfrom paddlets.transform import Fill, StandardScalerfrom paddlets.metrics import MSE, MAEfrom paddlets.analysis import AnalysisReport, Summaryfrom paddlets.datasets.repository import get_datasetimport warnings
warnings.filterwarnings('ignore')/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlets/utils/backtest.py:6: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import defaultdict, Iterable
# 解压缩数据集!unzip -O GBK 功率预测竞赛赛题与数据集.zip
本次比赛重点侧重于模型算法的落地应用,因此,数据集高度贴近风电企业实际情况,选手开发数据集处理方法,需要同时适配不同格式的风机数据。预选赛提供10个风场的数据,区域赛会提供新的10个风场数据用于新的训练和预测,数据格式的情况可能会更为复杂,本文总结了风场数据可能存在的各种情况:
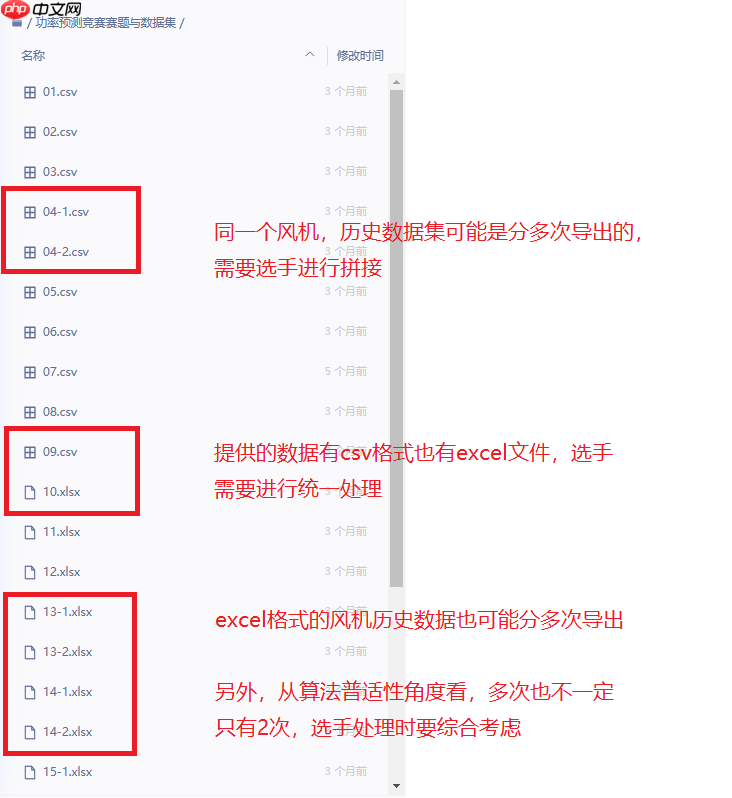
针对以上问题,可以确定如下的数据集处理思路:
def data_preprocess(data_dir):
files = os.listdir(data_dir) # 第一步,完成数据格式统一
for f in files: # 获取文件路径
data_file = os.path.join(data_dir, f) # 获取文件名后缀
data_type = os.path.splitext(data_file)[-1] # 获取文件名前缀
data_name = os.path.splitext(data_file)[0] # 如果是excel文件,进行转换
if data_type == '.xlsx': # 需要特别注意的是,在读取excel文件时要指定空值的显示方式,否则会在保存时以字符“.”代替,影响后续的数据分析
data_xls = pd.read_excel(data_file, index_col=0, na_values='')
data_xls.to_csv(data_name + '.csv', encoding='utf-8') # 顺便删除原文件
os.remove(data_file) # 第二步,完成多文件的合并,文件目录要重新更新一次
files = os.listdir(data_dir) for f in files: # 获取文件路径
data_file = os.path.join(data_dir, f) # 获取文件名前缀
data_basename = os.path.basename(data_file) # 检查风机数据是否有多个数据文件
if len(data_basename.split('-')) > 1:
merge_list = [] # 找出该风机的所有数据文件
matches = [ f for f in files if (f.find(data_basename.split('-')[0] + '-') > -1)] for i in matches: # 读取风机这部分数据
data_df = pd.read_csv(os.path.join(data_dir, i), index_col=False, keep_default_na=False)
merge_list.append(data_df) if len(merge_list) > 0:
all_data = pd.concat(merge_list,axis=0,ignore_index=True).fillna(".")
all_data.to_csv(os.path.join(data_dir, data_basename.split('-')[0]+ '.csv'),index=False)
for i in matches: # 删除这部分数据文件
os.remove(os.path.join(data_dir, i)) # 更新文件目录
files = os.listdir(data_dir)data_preprocess('功率预测竞赛赛题与数据集')至此,我们完成了数据集的批量预处理,将各种风机不同格式、不同数量文件的数据集进行了统一。这样,在后续的时序数据预测中,我们只需要对csv格式的时序数据进行处理即可。
os.listdir('功率预测竞赛赛题与数据集')在这里,我们也需要准备一个存放预测结果的文件目录。
!mkdir submit
由于赛题给出的不同风机采集数据字段都是一致的,仅仅是文件格式和数量不同。因此,在我们统一风机数据文件格式后,只需要抽出其中一两个风机的数据进行探索性数据分析即可——其它风机的情况是大体相同的。
在这里,我们取刚才转换格式并合并文件的一个风机数据进行分析,比如04号风机(如果前面的数据处理有错误,在这里就能发现)。
# 读取一份数据文件,这里需要特别注意时间戳字段的格式指定df = pd.read_csv('功率预测竞赛赛题与数据集/04.csv',parse_dates=['DATATIME'],infer_datetime_format=True,dayfirst=True)# 查看04号风机的运行工况数据df.head()
DATATIME WINDSPEED PREPOWER WINDDIRECTION TEMPERATURE \ 0 2021-10-02 00:00:00 4.1 6744.4 39 24.6 1 2021-10-02 00:00:00 4.1 7949.5 39 24.6 2 2021-10-02 00:15:00 4.1 6622.2 38 24.6 3 2021-10-02 00:15:00 4.1 7926.1 38 24.6 4 2021-10-02 00:30:00 4.0 6522.1 35 24.5 HUMIDITY PRESSURE ROUND(A.WS,1) ROUND(A.POWER,0) YD15 0 94 1008 4.0 7078.0 5906.0 1 94 1008 4.0 7078.0 5906.0 2 94 1008 4.5 11209.0 8721.0 3 94 1008 4.5 11209.0 8721.0 4 94 1008 4.6 11467.0 11973.0
df.columns
Index(['DATATIME', 'WINDSPEED', 'PREPOWER', 'WINDDIRECTION', 'TEMPERATURE',
'HUMIDITY', 'PRESSURE', 'ROUND(A.WS,1)', 'ROUND(A.POWER,0)', 'YD15'],
dtype='object')df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 89868 entries, 0 to 89867 Data columns (total 10 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 DATATIME 89868 non-null datetime64[ns] 1 WINDSPEED 89868 non-null float64 2 PREPOWER 89868 non-null float64 3 WINDDIRECTION 89868 non-null int64 4 TEMPERATURE 89868 non-null float64 5 HUMIDITY 89868 non-null int64 6 PRESSURE 89868 non-null int64 7 ROUND(A.WS,1) 89349 non-null float64 8 ROUND(A.POWER,0) 89349 non-null float64 9 YD15 89552 non-null float64 dtypes: datetime64[ns](1), float64(6), int64(3) memory usage: 6.9 MB
df.tail()
接下来,我们使用PaddleTS快速完成数据集的初步分析。 PaddleTS的Analsis模块能够帮助我们更简便地理解数据,同时,它还提供了多种多样的Anayzer帮助用户洞察数据,也提供了Report API给用户展示多种Analyzer组合分析的数据。
# 因为数据批次不同,数据集中有一些时间戳重复的脏数据,送入paddlets前要进行处理,本赛题要求保留第一个数据df.drop_duplicates(subset = ['DATATIME'],keep='first',inplace=True)
# 我们选取最后30天的风机工况数据进行可视化target_cov_dataset = TSDataset.load_from_dataframe(
df[-4*24*30:],
time_col='DATATIME',
target_cols='YD15',
observed_cov_cols=['WINDSPEED', 'PREPOWER', 'WINDDIRECTION', 'TEMPERATURE', 'HUMIDITY', 'PRESSURE', 'ROUND(A.WS,1)', 'ROUND(A.POWER,0)'],
freq='15min',
fill_missing_dates=False)# 由于不同指标的数值差异较大,在绘图时选取数值范围相近的组合分开绘制可视化图表target_cov_dataset.plot(['WINDSPEED', 'TEMPERATURE', 'ROUND(A.WS,1)'])<AxesSubplot:xlabel='DATATIME'>
<Figure size 1000x300 with 1 Axes>
target_cov_dataset.plot(['WINDDIRECTION', 'HUMIDITY', 'PRESSURE'])
<AxesSubplot:xlabel='DATATIME'>
<Figure size 1000x300 with 1 Axes>
target_cov_dataset.plot(['PREPOWER', 'ROUND(A.POWER,0)','YD15'])
<AxesSubplot:xlabel='DATATIME'>
<Figure size 1000x300 with 1 Axes>
target_cov_dataset.summary()
YD15 WINDSPEED PREPOWER WINDDIRECTION TEMPERATURE \
missing 0.032986 0.000000 0.000000 0.000000 0.000000
count 2785.000000 2880.000000 2880.000000 2880.000000 2880.000000
mean 14332.472531 4.243854 14898.320499 110.196875 27.239931
std 17475.732789 2.368603 16348.756167 101.818709 2.493907
min -841.000000 0.000000 1194.570760 0.000000 21.300000
25% 247.000000 2.400000 3507.291667 28.000000 25.300000
50% 5775.000000 3.900000 7376.846199 62.000000 26.700000
75% 25184.000000 5.900000 20275.775000 202.000000 29.200000
max 64725.000000 11.000000 75210.200000 359.000000 34.100000
HUMIDITY PRESSURE ROUND(A.WS,1) ROUND(A.POWER,0)
missing 0.000000 0.000000 0.034028 0.034028
count 2880.000000 2880.000000 2782.000000 2782.000000
mean 81.825694 1006.615972 5.030410 17404.443925
std 12.432304 2.870195 2.798523 20852.864000
min 49.000000 998.000000 0.700000 -355.000000
25% 72.000000 1005.000000 2.800000 902.500000
50% 84.000000 1007.000000 4.400000 7770.000000
75% 92.000000 1008.000000 6.800000 28848.500000
max 99.000000 1013.000000 15.100000 80409.000000target_cov_dataset.max()
YD15 64725.0 WINDSPEED 11.0 PREPOWER 75210.2 WINDDIRECTION 359.0 TEMPERATURE 34.1 HUMIDITY 99.0 PRESSURE 1013.0 ROUND(A.WS,1) 15.1 ROUND(A.POWER,0) 80409.0 dtype: float64
Analsis模块目前支持的分析器有:
Summary : 总结指标,目前支持均值、方差、最小值、25%中位数、50%中位数、75%中位数、最大值、缺失百分比、平稳性p值。
Max : 计算给定列的最大值。
FFT : 基于快速傅里叶变换的信号频域分析。
STFT : 基于短时傅里叶变换的信号时频分析。
CWT : 基于连续小波变换的信号时频分析。
我们也可以根据实际需求让它生成对应的时序数据分析报告。
report = AnalysisReport(target_cov_dataset, ["summary"])# 加入时频分析后,需要较长的计算时间# report = AnalysisReport(target_cov_dataset, ["summary","fft","stft","cwt"])
report.export_docx_report()
[2023-04-03 10:57:44,069] [paddlets.analysis.analysis_report] [INFO] save report succcess, save at ./analysis_report.docx
<Figure size 1000x300 with 1 Axes>
在数据集分析时,我们可以不对数据缺失值进行处理以保持数据原貌。但是在模型训练时,则必须指定缺失值的处理方式,否则训练会报错。同时,PaddleTS要求输入的协变量为float格式,对于个别字段,需要进行指定。
df = pd.read_csv('功率预测竞赛赛题与数据集/01.csv',parse_dates=['DATATIME'],infer_datetime_format=True,dayfirst=True,dtype={'WINDDIRECTION':np.float64, 'HUMIDITY':np.float64, 'PRESSURE':np.float64})# 因为数据批次不同,数据集中有一些时间戳重复的脏数据,送入paddlets前要进行处理,本赛题要求保留第一个数据df.drop_duplicates(subset = ['DATATIME'],keep='first',inplace=True)
df.info()
<class 'pandas.core.frame.DataFrame'> Int64Index: 26208 entries, 0 to 34586 Data columns (total 10 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 DATATIME 26208 non-null datetime64[ns] 1 WINDSPEED 26208 non-null float64 2 PREPOWER 26208 non-null float64 3 WINDDIRECTION 26208 non-null float64 4 TEMPERATURE 26208 non-null float64 5 HUMIDITY 26208 non-null float64 6 PRESSURE 26208 non-null float64 7 ROUND(A.WS,1) 25943 non-null float64 8 ROUND(A.POWER,0) 25943 non-null float64 9 YD15 26113 non-null float64 dtypes: datetime64[ns](1), float64(9) memory usage: 2.2 MB
target_cov_dataset = TSDataset.load_from_dataframe(
df,
time_col='DATATIME',
target_cols=['ROUND(A.POWER,0)', 'YD15'],
observed_cov_cols=['WINDSPEED', 'PREPOWER', 'WINDDIRECTION', 'TEMPERATURE', 'HUMIDITY', 'PRESSURE', 'ROUND(A.WS,1)'],
freq='15min',
fill_missing_dates=True,
fillna_method = 'pre')关于数据集的切分,有两种方式。一是直接指定数据集切分比例;二是根据时序数据的特点,PaddleTS也支持通过时间戳的节点进行划分。
# train_dataset, val_test_dataset = target_cov_dataset.split(0.7)# val_dataset, test_dataset = val_test_dataset.split(0.3)# train_dataset.plot(add_data=[val_dataset,test_dataset], labels=['Val', 'Test'])
<AxesSubplot:xlabel='DATATIME'>
<Figure size 1000x300 with 1 Axes>
由于本项目是一个面向落地应用的场景,选手在设计数据集划分方式时,可以优先考虑通过时间戳划分数据集。
需要注意的是,赛题是这么要求的:
算法部分:要求选手基于PaddlePaddle根据官方提供的数据集,设计一种利用当日05:00之前的数据,预测次日00:00至23:45实际功率的方法。准确率按日统计,根据10个风电场平均准确率进行排名;准确率相同的情形下,根据每日单点的平均最大偏差绝对值排名。
所以我们在进行切分时,建议优先按照05:00这个时间点进行划分。
_ , train_dataset = target_cov_dataset.split('2021-04-30 04:45:00')
train_dataset, val_test_dataset = train_dataset.split('2021-07-31 04:45:00')
val_dataset, test_dataset = val_test_dataset.split('2021-08-31 04:45:00')# 最后一天的工况数据需要预测ROUND(A.POWER,0)和YD15两个字段,而且输入数据只到前一天的早上5点test_dataset, pred_dataset = test_dataset.split('2021-09-30 04:45:00')
train_dataset.plot(add_data=[val_dataset,test_dataset], labels=['Val', 'Test'])<AxesSubplot:xlabel='DATATIME'>
<Figure size 1000x300 with 1 Axes>
数据处理时,可以将指定列的值缩放为零均值和单位方差来实现归一化转换。
scaler = StandardScaler() scaler.fit(train_dataset) train_dataset_scaled = scaler.transform(train_dataset) val_test_dataset_scaled = scaler.transform(val_test_dataset) val_dataset_scaled = scaler.transform(val_dataset) test_dataset_scaled = scaler.transform(test_dataset)# 如果使用了归一化,在后续模型预测时要进行数据集逆转换# test_dataset = scaler.inverse_transform(ts_test_scaled)
lstm = LSTNetRegressor(
in_chunk_len = (24 + 19) * 7 * 4,
out_chunk_len = (24 + 19) * 4,
max_epochs=10,
optimizer_params= dict(learning_rate=5e-3),
)lstm.fit(train_dataset, val_dataset)
[2023-04-13 23:38:57,682] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 000| loss: 861660534.464798| val_0_mae: 15910.196289| 0:00:17s [2023-04-13 23:39:14,833] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 001| loss: 702688372.799785| val_0_mae: 13043.845703| 0:00:34s [2023-04-13 23:39:31,568] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 002| loss: 629983447.554781| val_0_mae: 12294.802734| 0:00:51s [2023-04-13 23:39:48,294] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 003| loss: 605644464.240311| val_0_mae: 12514.247070| 0:01:07s [2023-04-13 23:40:05,296] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 004| loss: 653346019.209870| val_0_mae: 12663.069336| 0:01:24s [2023-04-13 23:40:22,370] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 005| loss: 636977429.988467| val_0_mae: 12120.254883| 0:01:41s [2023-04-13 23:40:39,917] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 006| loss: 627197534.103258| val_0_mae: 12355.960938| 0:01:59s [2023-04-13 23:40:56,507] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 007| loss: 649966813.987394| val_0_mae: 15012.541992| 0:02:15s [2023-04-13 23:41:13,214] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 008| loss: 677125166.586027| val_0_mae: 14301.767578| 0:02:32s [2023-04-13 23:41:29,917] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 009| loss: 641291815.119218| val_0_mae: 11663.125977| 0:02:49s [2023-04-13 23:41:29,922] [paddlets.models.common.callbacks.callbacks] [INFO] Stop training because you reached max_epochs = 10 with best_epoch = 9 and best_val_0_mae = 11663.125977 [2023-04-13 23:41:29,923] [paddlets.models.common.callbacks.callbacks] [INFO] Best weights from best epoch are automatically used!
subset_test_pred_dataset = lstm.predict(val_dataset) subset_test_dataset, _ = test_dataset.split(len(subset_test_pred_dataset.target))
# 模型评估mae = MAE() mae(subset_test_dataset, subset_test_pred_dataset)
{'ROUND(A.POWER,0)': 16030.454186816549, 'YD15': 15601.535719760628}# 预测结果可视化subset_test_dataset, _ = test_dataset.split(len(subset_test_pred_dataset.target)) subset_test_dataset.plot(add_data=subset_test_pred_dataset, labels=['Pred'])
<AxesSubplot:xlabel='DATATIME'>
<Figure size 1000x300 with 1 Axes>
上图显示的是训练模型对1号风机未来(19+24)小时预测结果与测试集实际趋势的对比。
# 模型保存lstm.save("lstm")# 也可以动转静保存lstm.save("./model", network_model=True, dygraph_to_static=True)# 模型加载from paddlets.models.model_loader import load
loaded_lstm = load("lstm")# 模型预测result = loaded_lstm.predict(test_dataset) result.to_dataframe()[19*4:]
ROUND(A.POWER,0) YD15 2021-10-01 00:00:00 29912.177734 29194.886719 2021-10-01 00:15:00 20358.554688 21656.388672 2021-10-01 00:30:00 29699.613281 29963.566406 2021-10-01 00:45:00 27510.537109 26607.953125 2021-10-01 01:00:00 16971.984375 16437.027344 ... ... ... 2021-10-01 22:45:00 -7202.264648 -7223.247070 2021-10-01 23:00:00 -7145.840332 -6936.324219 2021-10-01 23:15:00 -3206.446045 -3385.208252 2021-10-01 23:30:00 2323.184082 2423.130371 2021-10-01 23:45:00 87.688187 660.455383 [96 rows x 2 columns]
# 截取次日预测数据result = result.to_dataframe()[19*4:]
result = result.reset_index()# 传入风场风机IDresult['TurbID'] = 1# 重新调整字段名称和顺序result.rename(columns={"index": "Datetime"}, inplace=True)
result = result[['TurbID', 'Datetime', 'ROUND(A.POWER,0)', 'YD15']]result.to_csv('submit/01.csv',index=False)集成模型是用集成学习的思想去把多个PaddleTS的预测器集合成一个预测器。目前PaddleTS支持两种集成预测器StackingEnsembleForecaster 和 WeightingEnsembleForecaster
步骤包括:
1.准备数据
2.准备模型
3.组装和拟合模型
4.进行回测
5.模型保存与加载
接下来,我们用集成模型来预测1号风机的输出功率变化。首先是准备集成预测器需要的底层模型,这里我们选择RNN,LSTM和MLP。
from paddlets.models.forecasting import MLPRegressorfrom paddlets.models.forecasting import LSTNetRegressorfrom paddlets.models.forecasting import RNNBlockRegressor
lstm_params = { 'sampling_stride': (24 + 19) * 4, 'eval_metrics':["mse", "mae"], 'batch_size': 8, 'max_epochs': 20, 'patience': 10}
rnn_params = { 'sampling_stride': (24 + 19) * 4, 'eval_metrics': ["mse", "mae"], 'batch_size': 8, 'max_epochs': 20, 'patience': 10}
mlp_params = { 'sampling_stride': (24 + 19) * 4, 'eval_metrics': ["mse", "mae"], 'batch_size': 8, 'max_epochs': 20, 'patience': 10, 'use_bn': True,
}为了保持模型预测的一致性, in_chunk_len, out_chunk_len, skip_chunk_len, 这三个参数已经被提取到集成模型中,在组装模型时统一设定。
from paddlets.ensemble import StackingEnsembleForecaster reg = StackingEnsembleForecaster( in_chunk_len= (24 + 19) * 7 * 4, out_chunk_len= (24 + 19) * 4, skip_chunk_len=0, estimators=[(LSTNetRegressor, lstm_params),(RNNBlockRegressor, rnn_params), (MLPRegressor, mlp_params)])
# 模型拟合reg.fit(train_dataset, val_dataset)
[2023-04-13 23:45:41,784] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 000| loss: 2157854766.545455| val_0_mse: 434634944.000000| val_0_mae: 15134.261719| 0:00:00s [2023-04-13 23:45:42,201] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 001| loss: 1274874944.000000| val_0_mse: 404811008.000000| val_0_mae: 14455.226562| 0:00:00s [2023-04-13 23:45:42,616] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 002| loss: 864954938.181818| val_0_mse: 383082656.000000| val_0_mae: 13955.348633| 0:00:01s [2023-04-13 23:45:43,028] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 003| loss: 654667089.454545| val_0_mse: 364152256.000000| val_0_mae: 13681.997070| 0:00:01s [2023-04-13 23:45:43,452] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 004| loss: 520725451.636364| val_0_mse: 367876256.000000| val_0_mae: 13655.694336| 0:00:02s [2023-04-13 23:45:43,903] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 005| loss: 426495889.454545| val_0_mse: 358582400.000000| val_0_mae: 13374.958984| 0:00:02s [2023-04-13 23:45:44,328] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 006| loss: 366549453.090909| val_0_mse: 364607712.000000| val_0_mae: 13544.072266| 0:00:02s [2023-04-13 23:45:44,741] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 007| loss: 314228002.909091| val_0_mse: 362071616.000000| val_0_mae: 13440.303711| 0:00:03s [2023-04-13 23:45:45,167] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 008| loss: 262892445.090909| val_0_mse: 360921376.000000| val_0_mae: 13412.265625| 0:00:03s [2023-04-13 23:45:45,584] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 009| loss: 221938609.454545| val_0_mse: 358694112.000000| val_0_mae: 13378.511719| 0:00:04s [2023-04-13 23:45:45,999] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 010| loss: 190502526.545455| val_0_mse: 360426240.000000| val_0_mae: 13350.240234| 0:00:04s [2023-04-13 23:45:46,464] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 011| loss: 170810132.363636| val_0_mse: 356882144.000000| val_0_mae: 13284.953125| 0:00:05s [2023-04-13 23:45:46,906] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 012| loss: 148189114.909091| val_0_mse: 360419648.000000| val_0_mae: 13336.097656| 0:00:05s [2023-04-13 23:45:47,352] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 013| loss: 132365503.272727| val_0_mse: 358436960.000000| val_0_mae: 13260.419922| 0:00:05s [2023-04-13 23:45:47,787] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 014| loss: 118677271.272727| val_0_mse: 359307424.000000| val_0_mae: 13311.393555| 0:00:06s [2023-04-13 23:45:48,202] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 015| loss: 105317205.454545| val_0_mse: 363960896.000000| val_0_mae: 13361.411133| 0:00:06s [2023-04-13 23:45:48,613] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 016| loss: 90016433.454545| val_0_mse: 363362176.000000| val_0_mae: 13335.208984| 0:00:07s [2023-04-13 23:45:49,026] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 017| loss: 80012225.090909| val_0_mse: 366721696.000000| val_0_mae: 13422.874023| 0:00:07s [2023-04-13 23:45:49,438] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 018| loss: 73471033.454545| val_0_mse: 367162976.000000| val_0_mae: 13388.984375| 0:00:08s [2023-04-13 23:45:49,861] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 019| loss: 65201690.909091| val_0_mse: 373351680.000000| val_0_mae: 13544.246094| 0:00:08s [2023-04-13 23:45:49,865] [paddlets.models.common.callbacks.callbacks] [INFO] Stop training because you reached max_epochs = 20 with best_epoch = 13 and best_val_0_mae = 13260.419922 [2023-04-13 23:45:49,866] [paddlets.models.common.callbacks.callbacks] [INFO] Best weights from best epoch are automatically used! /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlets/automl/searcher.py:4: DeprecationWarning: The module `ray.tune.suggest` has been moved to `ray.tune.search` and the old location will be deprecated soon. Please adjust your imports to point to the new location. Example: Do a global search and replace `ray.tune.suggest` with `ray.tune.search`. from ray.tune.suggest import BasicVariantGenerator /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlets/automl/searcher.py:5: DeprecationWarning: The module `ray.tune.suggest.optuna` has been moved to `ray.tune.search.optuna` and the old location will be deprecated soon. Please adjust your imports to point to the new location. Example: Do a global search and replace `ray.tune.suggest.optuna` with `ray.tune.search.optuna`. from ray.tune.suggest.optuna import OptunaSearch /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlets/automl/searcher.py:6: DeprecationWarning: The module `ray.tune.suggest.flaml` has been moved to `ray.tune.search.flaml` and the old location will be deprecated soon. Please adjust your imports to point to the new location. Example: Do a global search and replace `ray.tune.suggest.flaml` with `ray.tune.search.flaml`. from ray.tune.suggest.flaml import CFO /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlets/automl/searcher.py:8: DeprecationWarning: The module `ray.tune.suggest.bohb` has been moved to `ray.tune.search.bohb` and the old location will be deprecated soon. Please adjust your imports to point to the new location. Example: Do a global search and replace `ray.tune.suggest.bohb` with `ray.tune.search.bohb`. from ray.tune.suggest.bohb import TuneBOHB /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddlets/automl/search_space_configer.py:8: DeprecationWarning: The module `ray.tune.sample` has been moved to `ray.tune.search.sample` and the old location will be deprecated soon. Please adjust your imports to point to the new location. Example: Do a global search and replace `ray.tune.sample` with `ray.tune.search.sample`. from ray.tune.sample import Float, Integer, Categorical [2023-04-13 23:45:52,255] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 000| loss: 1096603042.909091| val_0_mse: 332518752.000000| val_0_mae: 11341.488281| 0:00:00s [2023-04-13 23:45:52,481] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 001| loss: 1096600740.363636| val_0_mse: 332517600.000000| val_0_mae: 11341.460938| 0:00:00s [2023-04-13 23:45:52,691] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 002| loss: 1096598539.636364| val_0_mse: 332516480.000000| val_0_mae: 11341.433594| 0:00:00s [2023-04-13 23:45:52,899] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 003| loss: 1096596171.636364| val_0_mse: 332515360.000000| val_0_mae: 11341.407227| 0:00:00s [2023-04-13 23:45:53,107] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 004| loss: 1096593943.272727| val_0_mse: 332514336.000000| val_0_mae: 11341.378906| 0:00:01s [2023-04-13 23:45:53,316] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 005| loss: 1096591592.727273| val_0_mse: 332513280.000000| val_0_mae: 11341.353516| 0:00:01s [2023-04-13 23:45:53,525] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 006| loss: 1096589457.454545| val_0_mse: 332512160.000000| val_0_mae: 11341.325195| 0:00:01s [2023-04-13 23:45:53,747] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 007| loss: 1096587252.363636| val_0_mse: 332511008.000000| val_0_mae: 11341.296875| 0:00:01s [2023-04-13 23:45:53,965] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 008| loss: 1096585006.545455| val_0_mse: 332509888.000000| val_0_mae: 11341.268555| 0:00:01s [2023-04-13 23:45:54,175] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 009| loss: 1096582626.909091| val_0_mse: 332508768.000000| val_0_mae: 11341.241211| 0:00:02s [2023-04-13 23:45:54,392] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 010| loss: 1096580346.181818| val_0_mse: 332507712.000000| val_0_mae: 11341.212891| 0:00:02s [2023-04-13 23:45:54,603] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 011| loss: 1096578077.090909| val_0_mse: 332506624.000000| val_0_mae: 11341.184570| 0:00:02s [2023-04-13 23:45:54,815] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 012| loss: 1096575848.727273| val_0_mse: 332505504.000000| val_0_mae: 11341.157227| 0:00:02s [2023-04-13 23:45:55,038] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 013| loss: 1096573777.454545| val_0_mse: 332504480.000000| val_0_mae: 11341.129883| 0:00:03s [2023-04-13 23:45:55,258] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 014| loss: 1096571537.454545| val_0_mse: 332503328.000000| val_0_mae: 11341.101562| 0:00:03s [2023-04-13 23:45:55,470] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 015| loss: 1096569122.909091| val_0_mse: 332502272.000000| val_0_mae: 11341.075195| 0:00:03s [2023-04-13 23:45:55,692] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 016| loss: 1096566970.181818| val_0_mse: 332501216.000000| val_0_mae: 11341.047852| 0:00:03s [2023-04-13 23:45:55,903] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 017| loss: 1096564654.545455| val_0_mse: 332500128.000000| val_0_mae: 11341.020508| 0:00:03s [2023-04-13 23:45:56,115] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 018| loss: 1096562478.545455| val_0_mse: 332498976.000000| val_0_mae: 11340.991211| 0:00:04s [2023-04-13 23:45:56,341] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 019| loss: 1096560087.272727| val_0_mse: 332497888.000000| val_0_mae: 11340.962891| 0:00:04s [2023-04-13 23:45:56,344] [paddlets.models.common.callbacks.callbacks] [INFO] Stop training because you reached max_epochs = 20 with best_epoch = 19 and best_val_0_mae = 11340.962891 [2023-04-13 23:45:56,345] [paddlets.models.common.callbacks.callbacks] [INFO] Best weights from best epoch are automatically used! [2023-04-13 23:45:57,232] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 000| loss: 1096593489.454545| val_0_mse: 332512032.000000| val_0_mae: 11341.327148| 0:00:00s [2023-04-13 23:45:57,250] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 001| loss: 1096573323.636364| val_0_mse: 332509792.000000| val_0_mae: 11341.268555| 0:00:00s [2023-04-13 23:45:57,267] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 002| loss: 1096560116.363636| val_0_mse: 332507104.000000| val_0_mae: 11341.200195| 0:00:00s [2023-04-13 23:45:57,284] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 003| loss: 1096545108.363636| val_0_mse: 332503424.000000| val_0_mae: 11341.111328| 0:00:00s [2023-04-13 23:45:57,301] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 004| loss: 1096528826.181818| val_0_mse: 332500064.000000| val_0_mae: 11341.030273| 0:00:00s [2023-04-13 23:45:57,317] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 005| loss: 1096513128.727273| val_0_mse: 332497216.000000| val_0_mae: 11340.960938| 0:00:00s [2023-04-13 23:45:57,336] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 006| loss: 1096494036.363636| val_0_mse: 332495008.000000| val_0_mae: 11340.905273| 0:00:00s [2023-04-13 23:45:57,355] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 007| loss: 1096474176.000000| val_0_mse: 332495168.000000| val_0_mae: 11340.908203| 0:00:00s [2023-04-13 23:45:57,379] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 008| loss: 1096451537.454545| val_0_mse: 332496992.000000| val_0_mae: 11340.953125| 0:00:00s [2023-04-13 23:45:57,398] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 009| loss: 1096427194.181818| val_0_mse: 332501024.000000| val_0_mae: 11341.063477| 0:00:00s [2023-04-13 23:45:57,416] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 010| loss: 1096412264.727273| val_0_mse: 332499232.000000| val_0_mae: 11341.024414| 0:00:00s [2023-04-13 23:45:57,435] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 011| loss: 1096390341.818182| val_0_mse: 332495904.000000| val_0_mae: 11340.942383| 0:00:00s [2023-04-13 23:45:57,476] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 012| loss: 1096363077.818182| val_0_mse: 332491328.000000| val_0_mae: 11340.830078| 0:00:00s [2023-04-13 23:45:57,494] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 013| loss: 1096338699.636364| val_0_mse: 332490176.000000| val_0_mae: 11340.796875| 0:00:00s [2023-04-13 23:45:57,512] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 014| loss: 1096300602.181818| val_0_mse: 332488480.000000| val_0_mae: 11340.750977| 0:00:00s [2023-04-13 23:45:57,529] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 015| loss: 1096276672.000000| val_0_mse: 332485792.000000| val_0_mae: 11340.683594| 0:00:00s [2023-04-13 23:45:57,547] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 016| loss: 1096274327.272727| val_0_mse: 332479360.000000| val_0_mae: 11340.515625| 0:00:00s [2023-04-13 23:45:57,581] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 017| loss: 1096231005.090909| val_0_mse: 332478176.000000| val_0_mae: 11340.479492| 0:00:00s [2023-04-13 23:45:57,600] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 018| loss: 1096195223.272727| val_0_mse: 332475232.000000| val_0_mae: 11340.405273| 0:00:00s [2023-04-13 23:45:57,617] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 019| loss: 1096174196.363636| val_0_mse: 332471264.000000| val_0_mae: 11340.309570| 0:00:00s [2023-04-13 23:45:57,619] [paddlets.models.common.callbacks.callbacks] [INFO] Stop training because you reached max_epochs = 20 with best_epoch = 19 and best_val_0_mae = 11340.309570 [2023-04-13 23:45:57,620] [paddlets.models.common.callbacks.callbacks] [INFO] Best weights from best epoch are automatically used!
subset_test_pred_dataset = reg.predict(val_dataset) subset_test_dataset, _ = test_dataset.split(len(subset_test_pred_dataset.target))
# 模型评估mae = MAE() mae(subset_test_dataset, subset_test_pred_dataset)
{'ROUND(A.POWER,0)': 6370.233882897048, 'YD15': 6344.061808114118}从评估指标的表现看,集成模型的表现进步较大。当然,它牺牲了一些训练时间,实际开发时,选手需要综合用户体验和预测效果,进行适当取舍。
subset_test_dataset, _ = test_dataset.split(len(subset_test_pred_dataset.target)) subset_test_dataset.plot(add_data=subset_test_pred_dataset, labels=['Pred'])
<AxesSubplot:xlabel='DATATIME'>
<Figure size 1000x300 with 1 Axes>
顾名思义,集成模型保存的时候是分了多个模型,因此,加载的时候是分别加载的。
reg.save("reg")# 集成模型加载loaded_model0 = load("./reg/paddlets-ensemble-model0")
loaded_model1 = load("./reg/paddlets-ensemble-model1")
loaded_model2 = load("./reg/paddlets-ensemble-model2")尽管分开加载集成模型显得有些麻烦,但是,我们此时还可以设置不同集成模型的权重,比如:让表现更好的模型权重更大。这样,或许可以进一步提升预测效果。
# 输出集成模型预测结果loaded_model0.predict(test_dataset).to_dataframe()[19*4:]*0.2 + loaded_model1.predict(test_dataset).to_dataframe()[19*4:]*0.4 + loaded_model2.predict(test_dataset).to_dataframe()[19*4:]*0.4
ROUND(A.POWER,0) YD15 2021-10-01 00:00:00 11058.841797 11355.408203 2021-10-01 00:15:00 5787.002930 5482.896973 2021-10-01 00:30:00 8437.157227 8588.436523 2021-10-01 00:45:00 11250.096680 11751.430664 2021-10-01 01:00:00 -1825.403076 -1882.670776 ... ... ... 2021-10-01 22:45:00 9834.172852 9847.228516 2021-10-01 23:00:00 -2804.005127 -2564.677979 2021-10-01 23:15:00 3135.439209 3154.819336 2021-10-01 23:30:00 6587.747559 6881.853027 2021-10-01 23:45:00 -523.073730 -509.810883 [96 rows x 2 columns]
# 保存集成模型预测结果# result = (loaded_model0.predict(test_dataset).to_dataframe()[19*4:]*0.2 + loaded_model1.predict(test_dataset).to_dataframe()[19*4:]*0.4 + loaded_model2.predict(test_dataset).to_dataframe()[19*4:]*0.4).to_csv('01.csv')# result = result.reset_index()# # 传入风场风机ID# result['TurbID'] = 1# # 重新调整字段名称和顺序# result.rename(columns={"index": "datetime"}, inplace=True)# result = result[['TurbID', 'Datetime', 'ROUND(A.POWER,0)', 'YD15']]# result.to_csv('submit/01.csv',index=False)回测用给定模型获得的历史上的模拟预测,是用来评测模型预测准确率的重要工具。
回测是一个迭代过程,回测用固定预测窗口在数据集上进行重复预测,然后通过固定步长向前移动到训练集的末尾。如上图所示,桔色部分是长度为3的预测窗口。在每次迭代中,预测窗口会向前移动3个长度,同样训练集也会向后扩张三个长度。这个过程会持续到窗口移动到数据末尾。
在PaddleTS中,可以通过下面的方式实现回测。
from paddlets.utils import backtestfrom paddlets.metrics import MAE
mae, ts_pred = backtest(data=test_dataset,
model=lstm,
start=0.5, # the point after "start" as the first point
metric=MAE(),
return_predicts=True
)[2023-04-13 23:50:25,982] [paddlets.utils.backtest] [INFO] Parameter 'predict_window' not set, default set to model.out_chunk_len 172 [2023-04-13 23:50:25,983] [paddlets.utils.backtest] [INFO] Parameter 'stride' not set, default set to predict_window 172 Backtest Progress: 100%|██████████| 9/9 [00:00<00:00, 18.41it/s]
mae
{'ROUND(A.POWER,0)': 19261.904, 'YD15': 19188.62}从赛题给的风机数据中我们可以发现,不同风机数据起始时间、预测日期均不一致。因此,选手需要逐个风机进行预测并生成提交文件。从另一个角度说,不同风机可以使用同一个时序模型、超参数,也可以使用不同的模型、超参数,选手可以自行设置。
提交方法:
问题1:预测指标是什么?为什么会有ROUND(A.POWER,0)和YD15之分?
答:最终用于评估的预测指标只有YD15。ROUND(A.POWER,0)和YD15都是要预测的实际功率,只是二者在业务上计量口径不同。由于比赛使用的是风电企业真实生产过程中的数据,由于测量设备和网络传输问题,YD15可能出现数据异常(包括用于评测的输入数据)。此时业务上可以使用ROUND(A.POWER,0)作为替代;如果ROUND(A.POWER,0)也存在异常,则需要用PREPOWER字段进行替代。选手在设计方案时,需要考虑到这种情况。
问题2:PREPOWER字段的含义?与YD15的区别?
答:PREPOWER是风机系统自己生成的预测功率。我们可以认为,是风电企业目前通过自有的算法模型生成的功率预测结果,而本次比赛,正是为了寻找比原有预测方案效果更好的模型。实际选手需要预测的是YD15。
问题3:如何定义YD15存在异常? 在本赛题中,YD15异常包括两种情况:
除以上两种情况之外,YD15的数值变化都可认为是正常现象,如为0或负值。
测评数据的格式如下:
| --- ./infile(内置于测评系统中,参赛选手不可见)
| --- 0001in.csv
| --- 0002in.csv
| --- ...参赛选手需要提交一个命名为submission.zip(示例可参考项目提供的同名文件)的压缩包,并且压缩包内应包含:
| --- ./model # 存放模型的目录,并且大小不超过200M(必选)| --- ./env # 存放依赖库的目录(可选)| --- predict.py # 评估代码(必选)| --- pip-requirements.txt # 存放依赖库的文件(可选)| --- …
参赛选手在代码提交页面提交压缩包后,测评系统会解压选手提交的压缩包,并执行如下命令:
python predict.py
测评文件predict.py应该完成的功能是:读取infile文件夹下的测评数据,并将预测结果保存到pred文件夹中。
预测结果的保存格式如下:
| --- ./pred(需要选手生成)
| --- 0001out.csv
| --- 0002out.csv
| --- …注意:存放模型参数的model文件夹、存放预测结果的文件夹pred的名称以及predict.py的文件命名应与要求一致。
最后将按照平均日准确率高低进行排名。
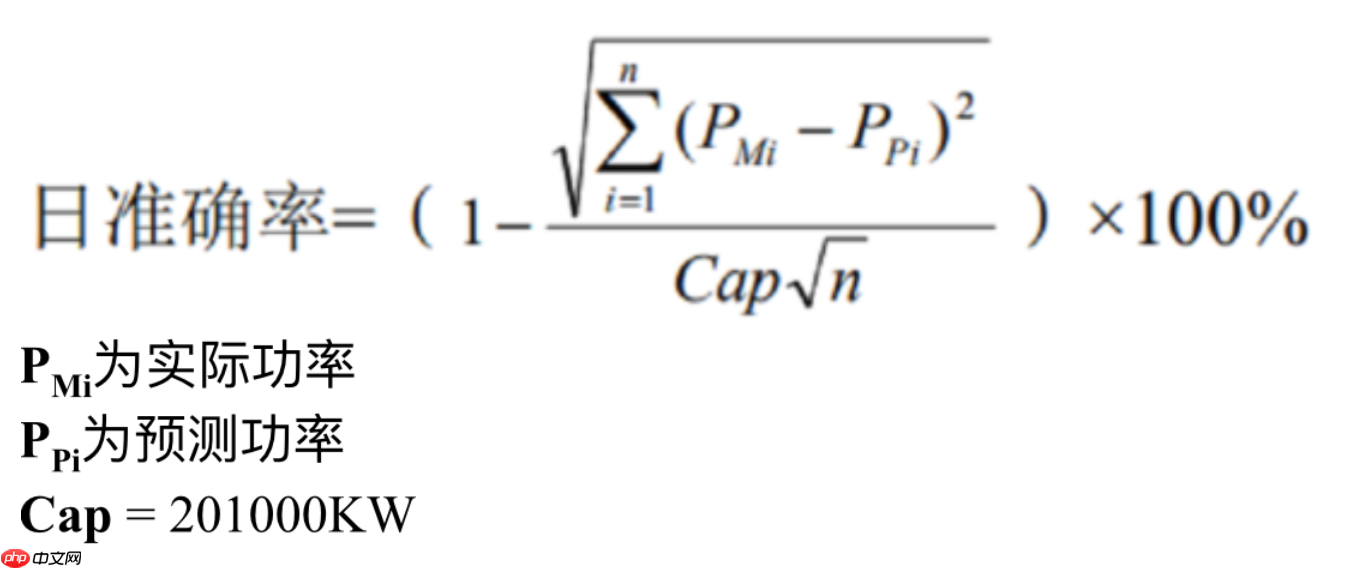
为便于选手理解,本项目同时提供了测评数据示例,请选手查看项目的infile和outfile两个目录。说明如下:
在项目用Gradio实现PaddleTS时序预测全流程可视化:以风电预测任务为例中,给出了简易的模型测试demo,选手可以参照修改,仿照测评数据示例,自行进行线下测评。
以上就是“中国软件杯”大学生软件设计大赛——龙源风电赛道比赛预测基线的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 638
638























