本文分享第十五届中国计算机设计大赛智慧导盲组第5名方案,基于PaddleDetection套件实现。分析赛题与数据集后,选PP-YOLOE的m模型,介绍训练策略,如batchsize等参数设置,还提及predict.py优化、模型选择技巧、数据集合并等提分方法,及复现流程。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

本项目是基于PaddleDetection套件实现的,在此我将尽可能详细地介绍我的模型训练策略以及提分技巧,大家可以试试能否复现。
一只导盲犬能够给盲人带来许多生活上的便利,但是导盲犬的培训周期长,费用高昂,因此,不是所有盲人能够拥有导盲犬,如果有机器狗代替导盲犬,将极大的造福盲人,此项比赛为智能导盲机器狗比赛,通过比赛来考评智能导盲机器狗的智能感知能力及综合运动性能,要求智能四足仿生机器人沿布置好的城市人行道场景走完全程并完成指定任务。
要求参赛者利用提供的训练数据,在统一的计算资源下,实现一个能够识别盲道、红绿灯(红灯状态)、红绿灯(绿灯状态)、红绿灯(不亮灯状态)、障碍物的深度学习模型,不限制深度学习任务。
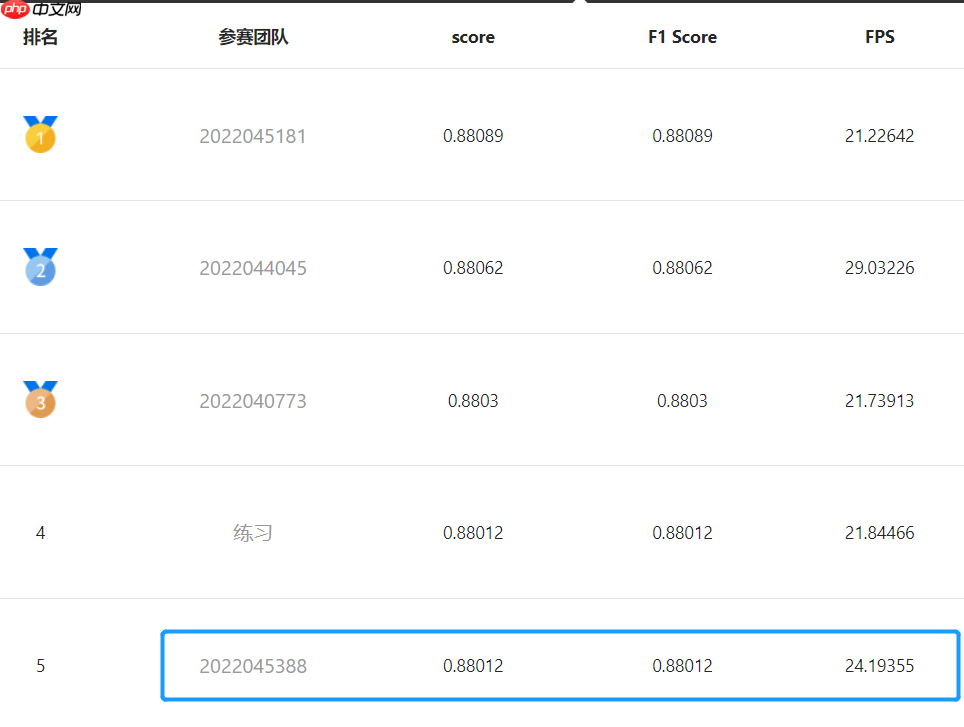
比赛链接
本次比赛要求选手使用飞桨PaddlePaddle2.2及以上版本生成端到端深度学习模型,并且model目录不能超过200M(不压缩)以及模型预测速度在v100显卡需达到20 FPS及以上。因此,本次预选赛的重点在于选择一个合适的模型,即所用模型不能太大、推理速度要快,这些都是为了接下来国赛中在机器狗上模型部署方便,服务于现实场景。而剩下的就是普通的目标检测任务,因为数据集的场景单一,所以不管是分类还是定位都没有太大问题。
本次比赛官方共提供了9994张图片,每类平均有2000张左右的图片,并已将其按8:2的比例划分为训练集和验证集,不过每张图片上可能有多个类别的标注信息,经测试后发现训练集中的标注信息个数为: {'1': 13841, '2': 1560, '3': 5437, '4': 2853, '5': 1574},验证集中的标注信息个数为:{'1': 3455, '2': 414, '3': 1389, '4': 673, '5': 410},其中'1':盲道;'2':绿灯;'3':障碍物;'4':未亮灯;'5':红灯
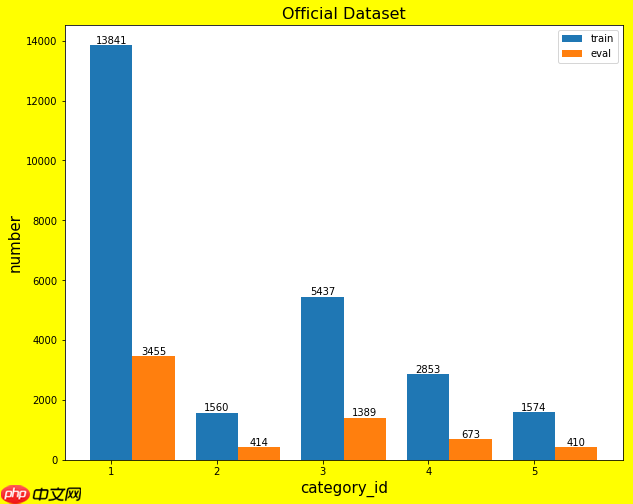
从上图可以看出,数据集还是存在类别不均衡问题的,为此我还尝试了对训练集的红绿灯进行copy-paste数据增强(简单来说,就是将一张图片的红绿灯复制粘贴到另一张图片;传送门),但最后发现好像多此一举了,因为就算红绿灯的数量少,而数据集里的场景单一,所含目标物较少,也很少重叠部分,所以红绿灯的识别效果还是挺好的,也就没必要用这种数据增强了。
由于我在报名这个比赛之前,已经在打另外一个目标检测的比赛了,不管是对PaddleDetection的熟悉度,还是模型选择、调参、后处理优化等等都有了一定的基础,所以在本次比赛中我就没走多少弯路。
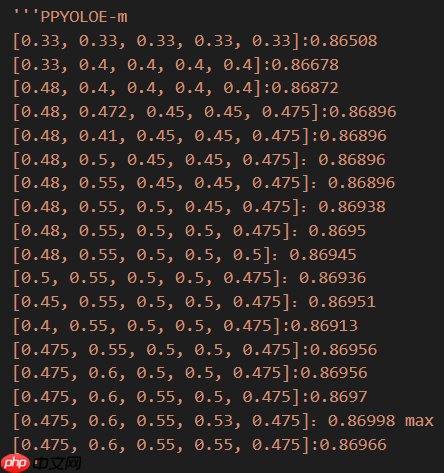
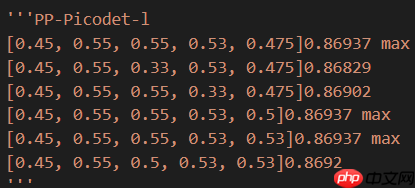
我选择的模型是PaddleDetection新推出的单阶段Anchor-free模型PP-YOLOE,而该系列的m模型既满足本次比赛对模型大小和推理速度的要求,又能在COCO数据集上达到较高的精度,极具性价比。 当然,我也尝试过PP-Picodet的large模型,最好的F1-score是0.869+(而且才跑80轮),但是我发现这个成绩很难再提高了,所以也就只能放弃它(或许多跑几轮能有效果,大家可以试试)。不过说实话,才20多MB的模型文件还是很香的,不愧是在移动端具有卓越性能的全新SOTA轻量级模型。
在本次比赛中我没有怎么调参,所用的配置文件是照搬我在另外一个比赛调参后的结果。最终选择的策略是batchsize=16,learning_rate=0.0025,SGD+Momentum+学习率余弦退火,epoch=220,多尺度训练:[576, 608, 640, 672, 704],唯一要注意的就是,预训练模型最好采用PaddlePaddle在coco数据集上训练好的模型作为预训练模型进行迁移学习,这样能避免neck和head的随机初始化,有助于模型收敛。详情请看:(当然这个参数应该也不是最优的,大家可以试着改一改) /home/aistudio/PaddleDetection/configs/ppyoloe/ppyoloe_crn_m_300e_coco.yml
至于我是怎么调参的,如果感兴趣请移步至我的另外一个项目:
第十七届全国大学生智能汽车竞赛:智慧交通组创意赛线上资格赛-冠军方案
另外,我跑的picodet模型的配置文件在: /home/aistudio/PaddleDetection/configs/picodet/picodet_l_640_coco_lcnet.yml
[05/05 01:37:27] ppdet.engine INFO: Epoch: [109] [400/499] learning_rate: 0.001064 loss: 1.084558 loss_cls: 0.477271 loss_iou: 0.112744 loss_dfl: 0.635325 loss_l1: 0.145152 eta: 3:26:26 batch_cost: 0.3447 data_cost: 0.0021 ips: 46.4110 images/s Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.693 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.983 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.801 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.542 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.662 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.768 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.661 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.747 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.749 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.625 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.740 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.809 [05/05 01:40:26] ppdet.engine INFO: Total sample number: 1998, averge FPS: 51.89114842229186 [05/05 01:40:26] ppdet.engine INFO: Best test bbox ap is 0.693.
但是当我选择model_final的时候,虽然它的指标没那么好,但是提交结果却是0.873+!(这是第179轮训练得到的结果)
[05/05 13:30:05] ppdet.engine INFO: Epoch: [179] [400/499] learning_rate: 0.000063 loss: 0.930625 loss_cls: 0.430781 loss_iou: 0.082502 loss_dfl: 0.587093 loss_l1: 0.100883 eta: 0:00:34 batch_cost: 0.3192 data_cost: 0.0044 ips: 50.1271 images/s Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.673 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.978 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.754 Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.518 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.637 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.752 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.651 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.728 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.730 Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.611 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.711 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.798 [05/05 13:33:20] ppdet.engine INFO: Total sample number: 1998, averge FPS: 52.37545462954398 [05/05 13:33:20] ppdet.engine INFO: Best test bbox ap is 0.693.
结论就是:大家不要只根据ap值选择模型,至于哪个模型才是最好咱也不知道,只能多试几个。后来我都是在best_model附近找,或者直接用model_final(因为最后一个模型训练的次数比较多,loss也更低,当然,过拟合又是另外一回事了)

从上图可以看到,障碍物后面的盲道没有被识别出来。真实的标注信息是这样的:

所以大家很难提升成绩的主要原因也就是因为这种盲道不能识别出来。对此,大家可以进行随机亮度、饱和度等手段进行数据增强,提升模型对这种光线影响问题的泛化能力。但是我并没有这么做,我觉得既然模型在验证集的这些图片不能很好地识别盲道,那就把验证集加入到训练集中,这样模型就能直接地学到这些信息了(主要是我觉得测评系统的图片应该也和现有的数据集是同一地点同一时间采集的,那图片中的场景应该是差不多的,多一些图片训练模型,那它的识别效果应该会更好!)
事实证明,我的猜想是有效的,合并数据集后训练得到的模型提交结果F1-score提升了约0.6%!!
3.由于郑先生在之前的直播(第十五届中国计算机设计大赛智慧导盲组专场培训4月20日)(大约在35分钟的时候)中提到同一张图片中只有一个block是正确的,而墙角的杂物是错误的。为此,我查看了数据集中对这种图片的标注信息,发现所给数据集其实并不是如他所说的那样,以下是对red_light_1922.png标注信息的可视化:

可以看到墙角的block也是有标注框的。为了进一步验证这个说法,我还对predict.py进行了修改(具体代码见predict_block测试.py),对测评系统里的图片标注情况进行测试。
最后结果如下:
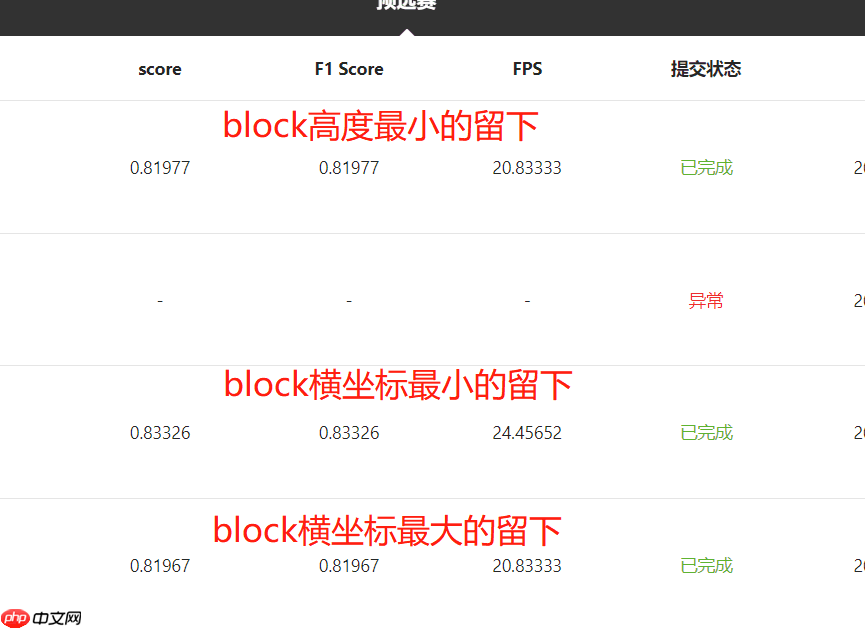
结论是:测评系统的所有图片中最多包含两个block,至少包含一个block,也就是删掉墙角的block是不行的。但是在第2点中我们可以看到在真实的标注信息中,墙角那个障碍物又是没有标注框的,所以我觉得这个数据集的标注质量是不太好的。
4.另外PPYOLOE的l模型是可以试试的,由于时间不够我就没有尝试跑这个模型(如果参数设置的合适,它的效果应该是比m模型要好的)。这里有同学可能会有疑问:跑这个模型最后导出的model文件夹不是大于200MB吗?是的,的确如此。但还是有办法的,模型压缩是一种,可自行探索,这里我们看看导出的静态图模型文件都有哪些:
├── infer_cfg.yml # 模型配置文件信息├── model.pdiparams # 静态图模型参数├── model.pdiparams.info # 参数额外信息,一般无需关注└── model.pdmodel # 静态图模型文件
虽然我的模型也超过了200MB,可是也就超过了几KB(按照我的超参数设置训练出来的模型大小几乎都是这种情况),所以我将model.pdiparams.info文件删除后就能正常提交结果了。
合并数据集的代码在work/json_merge.py,合并方法很简单:分别读取instance_train.json和instance_val.json文件,对其中相同的字段进行合并,这里唯一要注意的就是'images'和'annotations'下的id不能有重复!下面将会展示如何使用这个代码。
而图片直接从val文件夹copy到train文件夹下即可。注意:我只是将验证集复制到训练集中,也就是训练的时候还是可以评估的,但是这个评估指标就没什么参考价值了,最终的epoch是根据合并数据集前的经验事先确定的。
# 安装相关依赖,每次启动环境都要运行!%cd PaddleDetection !pip install -r requirements.txt# 编译安装paddledet!python setup.py install %cd ~
# 解压缩数据集(为了便于跑后台任务,将数据集解压到data文件夹下)!mkdir /home/aistudio/data/dog !tar -zxf /home/aistudio/data/data137625/WisdomGuide.tar.gz -C /home/aistudio/data/dog
# 将验证集的json文件与训练集的融合,并覆盖原训练集的json文件!python /home/aistudio/work/json_merge.py \
--json1_path=/home/aistudio/data/dog/WisdomGuide/annotations/instance_train.json \
--json2_path=/home/aistudio/data/dog/WisdomGuide/annotations/instance_val.json \
--save_path=/home/aistudio/data/dog/WisdomGuide/annotations/instance_train.json# 将验证集图片复制到训练集中!cp -r /home/aistudio/data/dog/WisdomGuide/val/* /home/aistudio/data/dog/WisdomGuide/train/
# 模型训练 # 如果要恢复训练,则加上 -r output/ppyoloe_crn_m_300e_coco/best_model# 如果要边训练边评估,则加上--eval%cd ~ %cd PaddleDetection !python tools/train.py \ -c configs/ppyoloe/ppyoloe_crn_m_300e_coco.yml --eval \ --use_vdl=true \ --vdl_log_dir=VisualDL
# # 删除早期训练保存的模型文件# !python /home/aistudio/work/delete.py
训练完成后,你可以在/home/aistudio/PaddleDetection/VisualDL下找到训练的日志文件(现在这个文件夹下放的是0.88012的训练日志),大家可以通过VisualDL可视化这个文件,从而直观、清晰地查看数据的特征与变化趋势,有助于分析数据、及时发现错误,进而改进神经网络模型的设计。
用验证集(或者测试集)评估模型的效果
%cd ~
%cd PaddleDetection# output_eval表示Evaluation directory, default is current directory.# classwise表示是否计算每一类的AP和画P-R曲线,PR曲线图默认存放在bbox_pr_curve文件夹下!python tools/eval.py -c configs/ppyoloe/ppyoloe_crn_m_300e_coco.yml \
--output_eval=/home/aistudio/data/dog/WisdomGuide/val \
--classwise \
-o weights=/home/aistudio/PaddleDetection/output/ppyoloe_crn_m_300e_coco/best_model.pdparamsCOCO目标检测比赛中的模型评价指标介绍

预测结果可视化
%cd ~
%cd PaddleDetection# infer_dir表示对该路径下的所有图片进行预测# draw_threshold表示置信度大于该值的框才画出来# 生成的图片保存在/home/aistudio/PaddleDetection/infer_output!python tools/infer.py -c configs/ppyoloe/ppyoloe_crn_m_300e_coco.yml \
--infer_dir=/home/aistudio/data/dog/WisdomGuide/val \
--output_dir=infer_output/ \
--draw_threshold=0.5 \
-o weights=/home/aistudio/PaddleDetection/output/ppyoloe_crn_m_300e_coco/best_model.pdparams%cd ~
%cd PaddleDetection# 将"-o weights"里的模型路径换成你自己训好的模型!python tools/export_model.py -c configs/ppyoloe/ppyoloe_crn_m_300e_coco.yml \
-o weights=/home/aistudio/PaddleDetection/output/ppyoloe_crn_m_300e_coco/best_model.pdparams \
TestReader.fuse_normalize=true%cd ~# 在work目录下整理提交代码# 创建model文件夹import osif not os.path.exists('/home/aistudio/work/submission/model/'):
os.makedirs('/home/aistudio/work/submission/model/') #创建路径# 将检测模型拷贝到model文件夹中!cp -r /home/aistudio/PaddleDetection/output_inference/ppyoloe_crn_m_300e_coco/* /home/aistudio/work/submission/model/这里为了让压缩包更小,我直接把PaddleDetection下多余的文件删掉了,只剩下deploy文件夹
# 测试predict.py是否能跑通(data.txt包括所有验证集图片)%cd /home/aistudio/work/submission !python predict.py data.txt result.json
# 打包代码%cd /home/aistudio/work/submission/ !zip -r -q -o submission.zip model/ PaddleDetection/ train.py predict.py
以上就是第十五届中国计算机设计大赛智慧导盲组-第5名方案分享的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 559
559























