






本文介绍基于PaddlePaddle2.0用RNN(含LSTM和GRU)进行文本分类的实现。先简述RNN及改进模型LSTM、GRU的原理,然后以中文谣言数据集为例,展示数据加载、生成词典、划分数据集、自定义数据集等处理步骤,最后分别构建LSTM和GRU模型,完成配置、训练与预测。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

RNN(LSTM&GRU)文本分类(PaddlePaddle2.0)
一、RNN简介
循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络(recursive neural network)。
它与DNN,CNN不同的是: 它不仅考虑前一时刻的输入,而且赋予了网络对前面的内容的一种'记忆'功能.
RNN之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
对循环神经网络的研究始于二十世纪80-90年代,并在二十一世纪初发展为深度学习(deep learning)算法之一,其中双向循环神经网络(Bidirectional RNN, Bi-RNN)和长短期记忆网络(Long Short-Term Memory networks,LSTM)是常见的循环神经网络。
循环神经网络具有记忆性、参数共享并且图灵完备(Turing completeness),因此在对序列的非线性特征进行学习时具有一定优势。循环神经网络在自然语言处理(Natural Language Processing, NLP),例如语音识别、语言建模、机器翻译等领域有应用,也被用于各类时间序列预报。引入了卷积神经网络(Convoutional Neural Network,CNN)构筑的循环神经网络可以处理包含序列输入的计算机视觉问题。
最简单的RNN网络
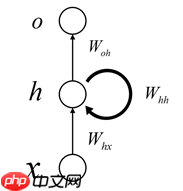
其展开可以表示为:
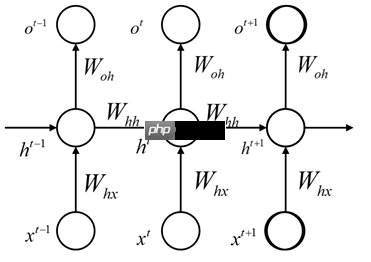
那么数学表示的公式为:
h∗t=Whxxt+Whhht−1+bhht=σ(h∗t)o∗t=Wohht+boot=θ(o∗t)
其中,xt表示t时刻的输入,ot表示t时刻的输出,ht表示t时刻隐藏层的状态。
由于每一步的输出不仅仅依赖当前步的网络,并且还需要前若干步网络的状态,那么这种BP改版的算法叫做Backpropagation Through Time(BPTT) , 也就是将输出端的误差值反向传递,运用梯度下降法进行更新.

LSTM算法(Long Short Term Memory, 长短期记忆网络 )
LSTM(Long short-term memory,长短期记忆)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失问题。
LSTM是有4个全连接层进行计算的,LSTM的内部结构如下图所示。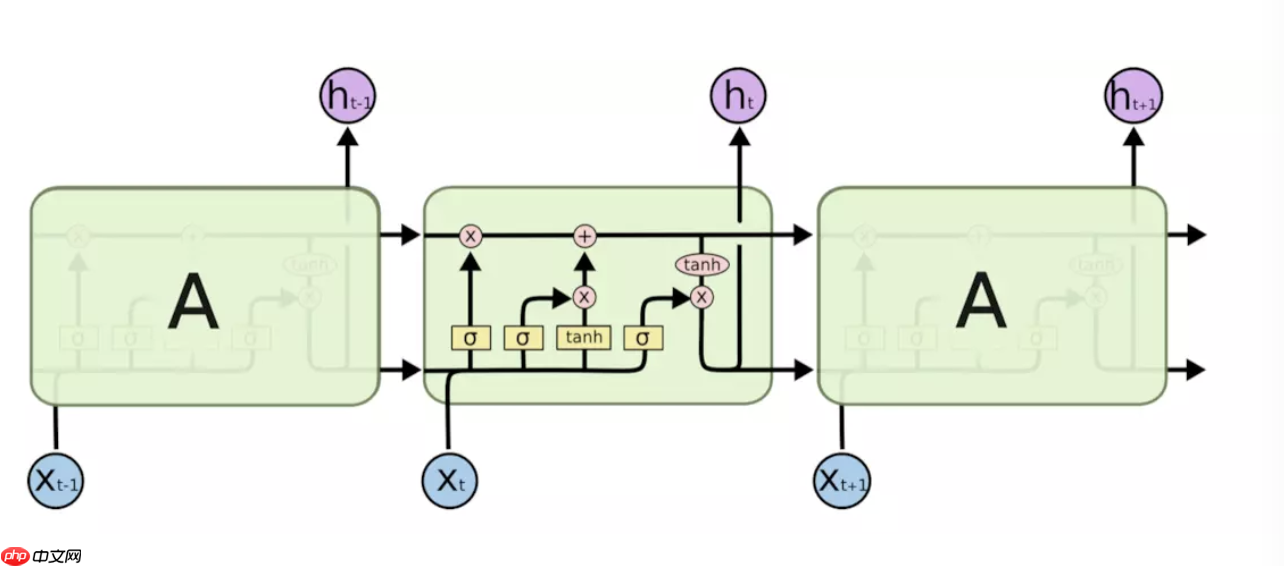
其中符号含义如下: 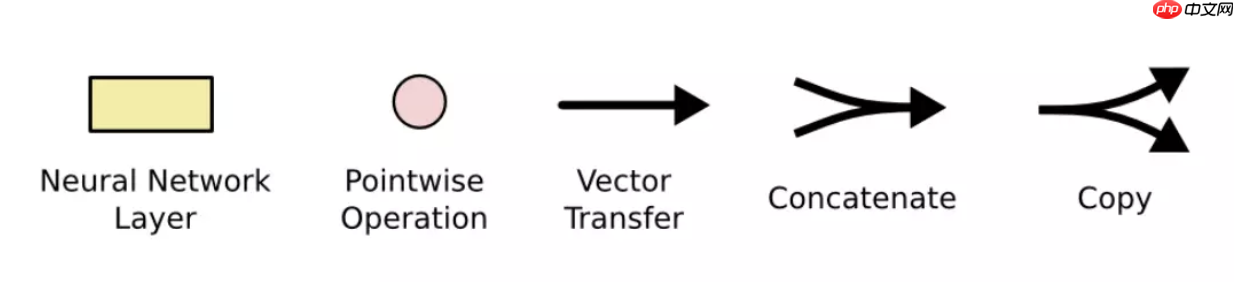
接下来看一下内部的具体内容: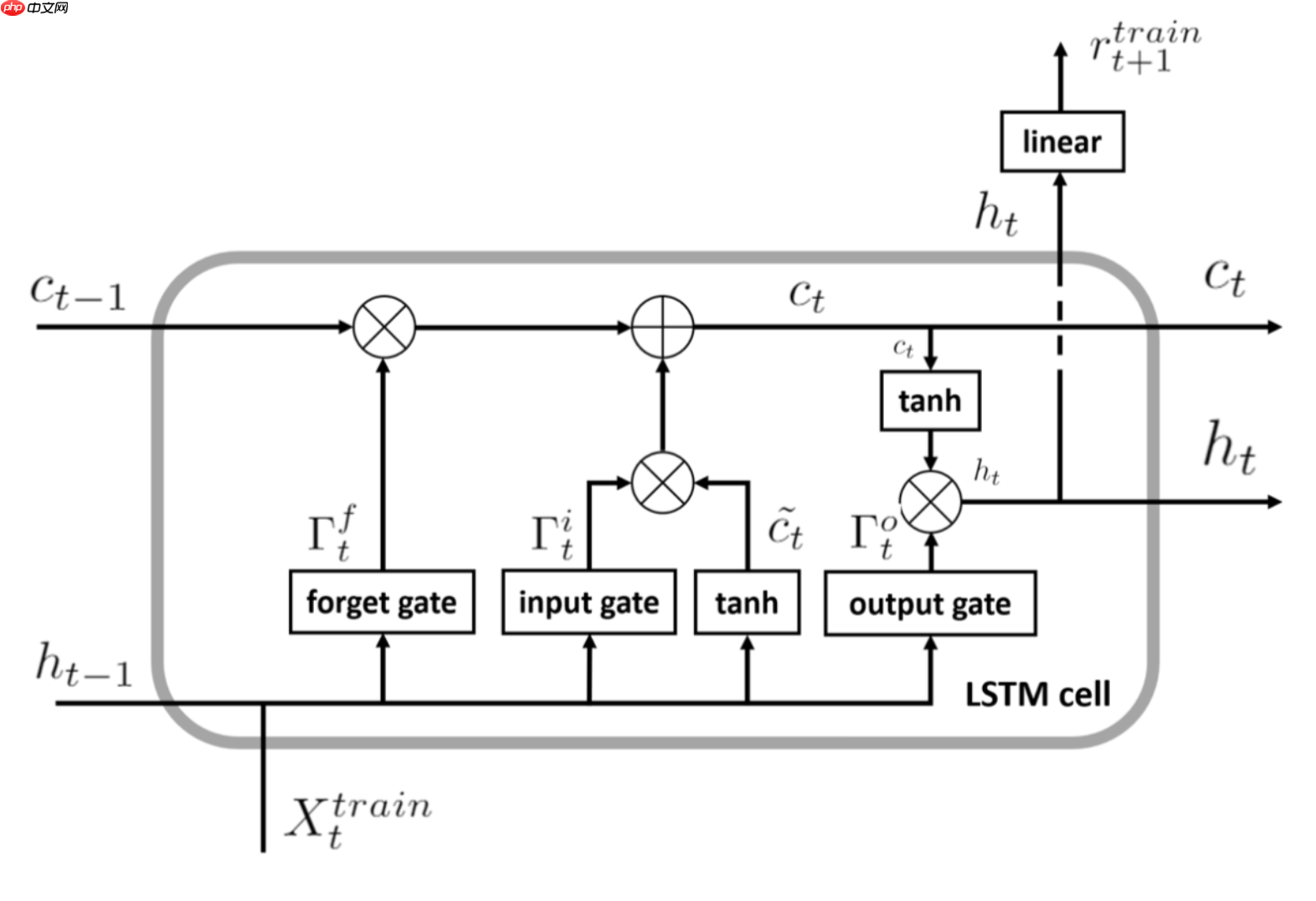
LSTM的核心是细胞状态——最上层的横穿整个细胞的水平线,它通过门来控制信息的增加或者删除。 STM共有三个门,分别是遗忘门,输入门和输出门。
- 遗忘门:遗忘门决定丢弃哪些信息,输入是上一个神经元细胞的计算结果ht-1以及当前的输入向量xt,二者联接并通过遗忘门后(sigmoid会决定哪些信息留下,哪些信息丢弃),会生成一个0-1向量Γft(维度与上一个神经元细胞的输出向量Ct-1相同),Γft与Ct-1进行点乘操作后,就会获取上一个神经元细胞经过计算后保留的信息。
- 输入门:表示要保存的信息或者待更新的信息,如上图所示是ht-1与xt的连接向量,经过sigmoid层后得到的结果Γit,这就是输入门的输出结果了。
- 输出门:输出门决定当前神经原细胞输出的隐向量ht,ht与Ct不同,ht要稍微复杂一点,它是Ct进过tanh计算后与输出门的计算结果进行点乘操作后的结果,用公式描述是:ht = tanh(ct) · Γot
GRU(门控循环单元)
GRU是LSTM的变种,它也是一种RNN,因此是循环结构,相比LSTM而言,它的计算要简单一些,计算量也降低。
GRU 有两个有两个门,即一个重置门(reset gate)和一个更新门(update gate)。从直观上来说,重置门决定了如何将新的输入信息与前面的记忆相结合,更新门定义了前面记忆保存到当前时间步的量。如果我们将重置门设置为 1,更新门设置为 0,那么我们将再次获得标准 RNN 模型。使用门控机制学习长期依赖关系的基本思想和 LSTM 一致,但还是有一些关键区别:
GRU 有两个门(重置门与更新门),而 LSTM 有三个门(输入门、遗忘门和输出门)。
GRU 并不会控制并保留内部记忆(c_t),且没有 LSTM 中的输出门。
LSTM 中的输入与遗忘门对应于 GRU 的更新门,重置门直接作用于前面的隐藏状态。
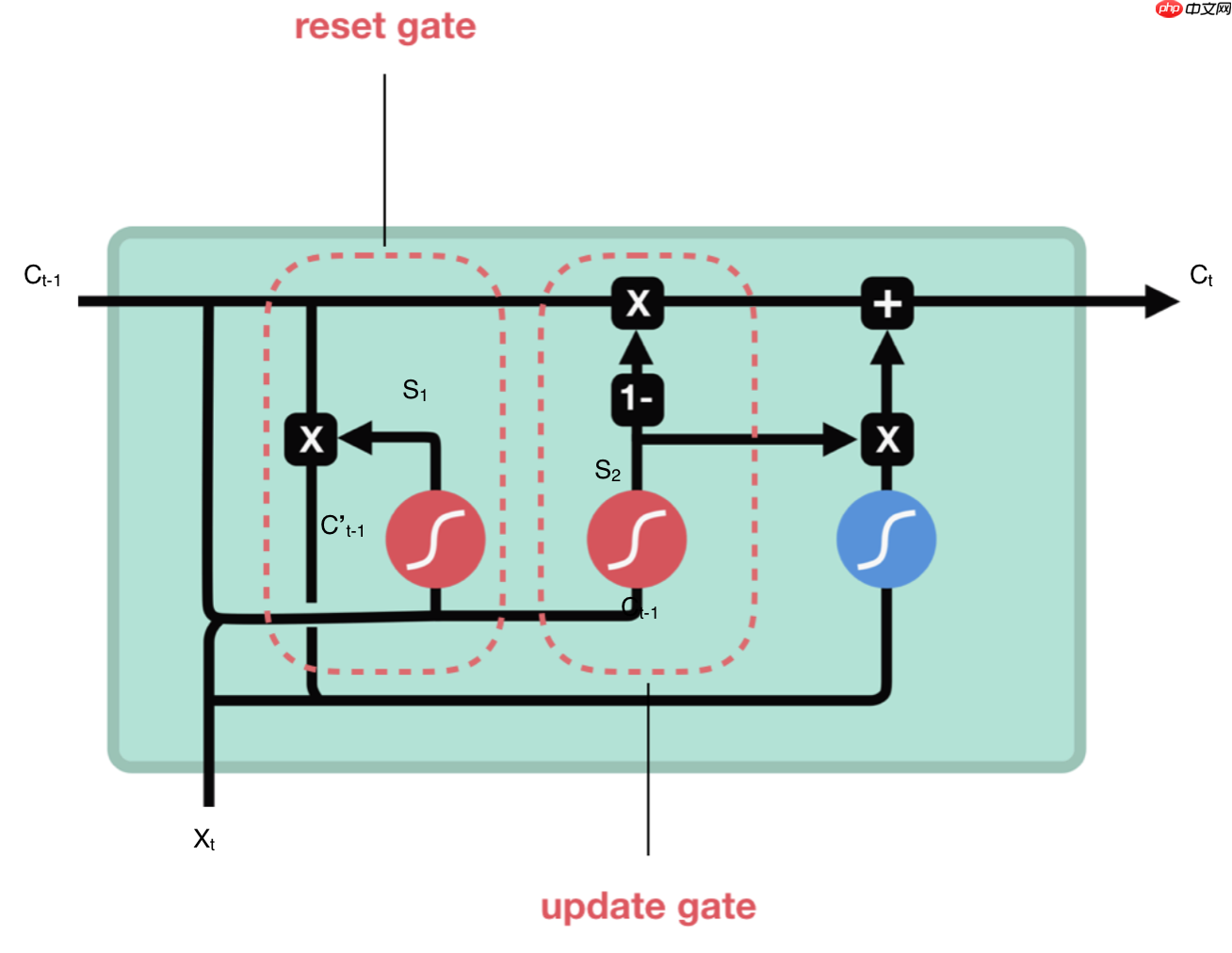
重置门:用来决定需要丢弃哪些上一个神经元细胞的信息,它的计算过程是将Ct-1与当前输入向量xt进行连接后,输入sigmoid层进行计算,结果为S1,再将S1与Ct-1进行点乘计算,则结果为保存的上个神经元细胞信息,用C’t-1表示。公式表示为:C’t-1 = Ct-1 · S1,S1 = sigmoid(concat(Ct-1,Xt))
更新门:更新门类似于LSTM的遗忘门和输入门,它决定哪些信息会丢弃,以及哪些新信息会增加。
完整公式描述为: 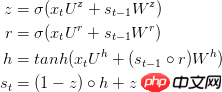
二、数据简介
本次使用的分类数据是从新浪微博不实信息举报平台抓取的中文谣言数据,数据集中一共包含1538条谣言和1849条非谣言。 更多数据集介绍请参考https://github.com/thunlp/Chinese_Rumor_Dataset
三、数据处理
加载数据集
import pandas as pd
all_data = pd.read_csv("data/data69671/all_data.tsv", sep="\t")
all_data.head()
label text 0 0 #广州#【广州游行打砸抢罪犯资料公布!居然是日本jian谍!】 1 0 【政协委员提议恢复大清王朝】康熙十世孙、广州政协委员金复新表示,他准备走遍中国收集100万人... 2 1 有木有人和我一样。睡觉时头总爱靠在枕头的一角。据说这样的孩纸,都没安全感。 3 1 据说,看到这张图的人,许个愿,在十秒内转发的,就能美梦成真!!我们也试试!!! 4 0 【老小子走了!李登辉今天凌晨心脏病复发身亡】台北消息:原国民党、台联党主席,有“tai独教父”之...
生成词典
all_str = all_data["text"].values.tolist()
dict_set = set() # 保证每个字符只有唯一的对应数字for content in all_str: for s in content:
dict_set.add(s)# 添加未知字符dict_set.add("")# 把元组转换成字典,一个字对应一个数字dict_list = []
i = 0for s in dict_set:
dict_list.append([s, i])
i += 1dict_txt = dict(dict_list)# 字典保存到本地with open("dict.txt", 'w', encoding='utf-8') as f:
f.write(str(dict_txt))
# 获取字典的长度def get_dict_len(dict_path):
with open(dict_path, 'r', encoding='utf-8') as f:
line = eval(f.readlines()[0]) return len(line.keys())
print(get_dict_len("dict.txt"))
4410
划分训练集、验证集以及测试集
all_data_list = all_data.values.tolist()
train_length = len(all_data) // 10 * 7dev_length = len(all_data) // 10 * 2train_data = []
dev_data = []
test_data = []for i in range(train_length):
text = ""
for s in all_data_list[i][1]:
text = text + str(dict_txt[s]) + ","
text = text[:-1]
train_data.append([text, all_data_list[i][0]])for i in range(train_length, train_length+dev_length):
text = ""
for s in all_data_list[i][1]:
text = text + str(dict_txt[s]) + ","
text = text[:-1]
dev_data.append([text, all_data_list[i][0]])for i in range(train_length+dev_length, len(all_data)):
text = ""
for s in all_data_list[i][1]:
text = text + str(dict_txt[s]) + ","
text = text[:-1]
test_data.append([text, all_data_list[i][0]])print(len(train_data))print(len(dev_data))print(len(test_data))
df_train = pd.DataFrame(columns=["text", "label"], data=train_data)
df_dev = pd.DataFrame(columns=["text", "label"], data=dev_data)
df_test = pd.DataFrame(columns=["text", "label"], data=test_data)
df_train.to_csv("train_data.csv", index=False)
df_dev.to_csv("dev_data.csv", index=False)
df_test.to_csv("test_data.csv", index=False)
2366 676 345
自定义数据集
import numpy as npimport paddlefrom paddle.io import Dataset, DataLoaderimport pandas as pd
class MyDataset(Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, mode='train'):
"""
步骤二:实现构造函数,定义数据读取方式,划分训练和测试数据集
"""
super(MyDataset, self).__init__()
self.label = True
if mode == 'train':
text = pd.read_csv("train_data.csv")["text"].values.tolist()
label = pd.read_csv("train_data.csv")["label"].values.tolist()
self.data = [] for i in range(len(text)):
self.data.append([])
self.data[-1].append(np.array([int(i) for i in text[i].split(",")]))
self.data[-1][0] = self.data[-1][0][:256].astype('int64')if len(self.data[-1][0])>=256 else np.concatenate([self.data[-1][0], np.array([dict_txt[""]]*(256-len(self.data[-1][0])))]).astype('int64')
self.data[-1].append(np.array(int(label[i])).astype('int64')) elif mode == 'dev':
text = pd.read_csv("dev_data.csv")["text"].values.tolist()
label = pd.read_csv("dev_data.csv")["label"].values.tolist()
self.data = [] for i in range(len(text)):
self.data.append([])
self.data[-1].append(np.array([int(i) for i in text[i].split(",")]))
self.data[-1][0] = self.data[-1][0][:256].astype('int64')if len(self.data[-1][0])>=256 else np.concatenate([self.data[-1][0], np.array([dict_txt[""]]*(256-len(self.data[-1][0])))]).astype('int64')
self.data[-1].append(np.array(int(label[i])).astype('int64')) else:
text = pd.read_csv("test_data.csv")["text"].values.tolist()
label = pd.read_csv("test_data.csv")["label"].values.tolist()
self.data = [] for i in range(len(text)):
self.data.append([])
self.data[-1].append(np.array([int(i) for i in text[i].split(",")]))
self.data[-1][0] = self.data[-1][0][:256].astype('int64')if len(self.data[-1][0])>=256 else np.concatenate([self.data[-1][0], np.array([dict_txt[""]]*(256-len(self.data[-1][0])))]).astype('int64')
self.data[-1].append(np.array(int(label[i])).astype('int64'))
self.label = False
def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
text_ = self.data[index][0]
label_ = self.data[index][1]
if self.label: return text_, label_ else: return text_ def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.data)
train_data = MyDataset(mode="train") dev_data = MyDataset(mode="dev") test_data = MyDataset(mode="test")
BATCH_SIZE = 128
train_loader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True) dev_loader = DataLoader(dev_data, batch_size=BATCH_SIZE, shuffle=True) test_loader = DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=False)
四、配置网络
LSTM
import paddle.nn as nn
inputs_dim = get_dict_len("dict.txt")
class myLSTM(nn.Layer):
def __init__(self):
super(myLSTM, self).__init__() # num_embeddings (int) - 嵌入字典的大小, input中的id必须满足 0 =< id < num_embeddings 。 。
# embedding_dim (int) - 每个嵌入向量的维度。
# padding_idx (int|long|None) - padding_idx的配置区间为 [-weight.shape[0], weight.shape[0],如果配置了padding_idx,那么在训练过程中遇到此id时会被用
# sparse (bool) - 是否使用稀疏更新,在词嵌入权重较大的情况下,使用稀疏更新能够获得更快的训练速度及更小的内存/显存占用。
# weight_attr (ParamAttr|None) - 指定嵌入向量的配置,包括初始化方法,具体用法请参见 ParamAttr ,一般无需设置,默认值为None。
self.embedding = nn.Embedding(inputs_dim, 256) # input_size (int) - 输入的大小。
# hidden_size (int) - 隐藏状态大小。
# num_layers (int,可选) - 网络层数。默认为1。
# direction (str,可选) - 网络迭代方向,可设置为forward或bidirect(或bidirectional)。默认为forward。
# time_major (bool,可选) - 指定input的第一个维度是否是time steps。默认为False。
# dropout (float,可选) - dropout概率,指的是出第一层外每层输入时的dropout概率。默认为0。
# weight_ih_attr (ParamAttr,可选) - weight_ih的参数。默认为None。
# weight_hh_attr (ParamAttr,可选) - weight_hh的参数。默认为None。
# bias_ih_attr (ParamAttr,可选) - bias_ih的参数。默认为None。
# bias_hh_attr (ParamAttr,可选) - bias_hh的参数。默认为None。
self.lstm = nn.LSTM(256, 256, num_layers=2, direction='bidirectional',dropout=0.5) # in_features (int) – 线性变换层输入单元的数目。
# out_features (int) – 线性变换层输出单元的数目。
# weight_attr (ParamAttr, 可选) – 指定权重参数的属性。默认值为None,表示使用默认的权重参数属性,将权重参数初始化为0。具体用法请参见 ParamAttr 。
# bias_attr (ParamAttr|bool, 可选) – 指定偏置参数的属性。 bias_attr 为bool类型且设置为False时,表示不会为该层添加偏置。 bias_attr 如果设置为True或者None,则表示使用默认的偏置参数属性,将偏置参数初始化为0。具体用法请参见 ParamAttr 。默认值为None。
# name (str,可选) – 具体用法请参见 Name ,一般无需设置,默认值为None。
self.linear = nn.Linear(in_features=256*2, out_features=2)
self.dropout = nn.Dropout(0.5)
def forward(self, inputs):
emb = self.dropout(self.embedding(inputs))
output, (hidden, _) = self.lstm(emb) #output形状大小为[batch_size,seq_len,num_directions * hidden_size]
#hidden形状大小为[num_layers * num_directions, batch_size, hidden_size]
#把前向的hidden与后向的hidden合并在一起
hidden = paddle.concat((hidden[-2,:,:], hidden[-1,:,:]), axis = 1)
hidden = self.dropout(hidden) #hidden形状大小为[batch_size, hidden_size * num_directions]
return self.linear(hidden)
封装模型
lstm_model = paddle.Model(myLSTM())
配置优化器等参数
lstm_model.prepare(paddle.optimizer.Adam(learning_rate=0.001, parameters=lstm_model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
模型训练
lstm_model.fit(train_loader,
dev_loader,
epochs=10,
batch_size=BATCH_SIZE,
verbose=1,
save_dir="work/lstm")
模型预测
result = lstm_model.predict(test_loader)
Predict begin... step 3/3 [==============================] - 38ms/step Predict samples: 345
GRU
class myGRU(nn.Layer):
def __init__(self):
super(myGRU, self).__init__() # num_embeddings (int) - 嵌入字典的大小, input中的id必须满足 0 =< id < num_embeddings 。 。
# embedding_dim (int) - 每个嵌入向量的维度。
# padding_idx (int|long|None) - padding_idx的配置区间为 [-weight.shape[0], weight.shape[0],如果配置了padding_idx,那么在训练过程中遇到此id时会被用
# sparse (bool) - 是否使用稀疏更新,在词嵌入权重较大的情况下,使用稀疏更新能够获得更快的训练速度及更小的内存/显存占用。
# weight_attr (ParamAttr|None) - 指定嵌入向量的配置,包括初始化方法,具体用法请参见 ParamAttr ,一般无需设置,默认值为None。
self.embedding = nn.Embedding(inputs_dim, 256) # input_size (int) - 输入的大小。
# hidden_size (int) - 隐藏状态大小。
# num_layers (int,可选) - 网络层数。默认为1。
# direction (str,可选) - 网络迭代方向,可设置为forward或bidirect(或bidirectional)。默认为forward。
# time_major (bool,可选) - 指定input的第一个维度是否是time steps。默认为False。
# dropout (float,可选) - dropout概率,指的是出第一层外每层输入时的dropout概率。默认为0。
# weight_ih_attr (ParamAttr,可选) - weight_ih的参数。默认为None。
# weight_hh_attr (ParamAttr,可选) - weight_hh的参数。默认为None。
# bias_ih_attr (ParamAttr,可选) - bias_ih的参数。默认为None。
# bias_hh_attr (ParamAttr,可选) - bias_hh的参数。默认为None。
self.gru = nn.GRU(256, 256, num_layers=2, direction='bidirectional',dropout=0.5) # in_features (int) – 线性变换层输入单元的数目。
# out_features (int) – 线性变换层输出单元的数目。
# weight_attr (ParamAttr, 可选) – 指定权重参数的属性。默认值为None,表示使用默认的权重参数属性,将权重参数初始化为0。具体用法请参见 ParamAttr 。
# bias_attr (ParamAttr|bool, 可选) – 指定偏置参数的属性。 bias_attr 为bool类型且设置为False时,表示不会为该层添加偏置。 bias_attr 如果设置为True或者None,则表示使用默认的偏置参数属性,将偏置参数初始化为0。具体用法请参见 ParamAttr 。默认值为None。
# name (str,可选) – 具体用法请参见 Name ,一般无需设置,默认值为None。
self.linear = nn.Linear(in_features=256*2, out_features=2)
self.dropout = nn.Dropout(0.5)
def forward(self, inputs):
emb = self.dropout(self.embedding(inputs))
output, hidden = self.gru(emb) #output形状大小为[batch_size,seq_len,num_directions * hidden_size]
#hidden形状大小为[num_layers * num_directions, batch_size, hidden_size]
#把前向的hidden与后向的hidden合并在一起
hidden = paddle.concat((hidden[-2,:,:], hidden[-1,:,:]), axis = 1)
hidden = self.dropout(hidden) #hidden形状大小为[batch_size, hidden_size * num_directions]
return self.linear(hidden)
封装模型
GRU_model = paddle.Model(myGRU())
配置优化器等参数
GRU_model.prepare(paddle.optimizer.Adam(learning_rate=0.001, parameters=GRU_model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
模型训练
GRU_model.fit(train_loader,
dev_loader,
epochs=10,
batch_size=BATCH_SIZE,
verbose=1,
save_dir="work/GRU")
模型预测
result = GRU_model.predict(test_loader)
Predict begin... step 3/3 [==============================] - 35ms/step Predict samples: 345



























