本项目复现相关论文,基于CNN-RNN框架实现医学影像报告自动生成,用印第安纳大学胸部X射线数据集,采两阶段方案。实验显示生成结果有医学语义,Paddle实现效果优于原论文,略逊于Pytorch版本。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

基于CNN-RNN的影像报告生成-Ⅰ
本项目对论文《Multimodal Recurrent Model with Attention for Automated Radiology Report Generation》进行详细解读并使用Paddle进行复现。
0 项目背景
随着近年来深度学习的飞速发展,深度学习在医疗行业展现出巨大的发展潜力。因此,如果能通过深度学习的方法,使用计算机代替医生进行机械的影像报告撰写工作,这样既避免了经验不足的医生在阅片诊断中产生的误诊情况,又使得更多的资深医生可以从繁重的重复性工作中解脱出来,将更多的时间投入病人的诊治中去。
医学影像报告自动生成是近年来计算机与医疗图像新兴的交叉方向之一。目前,影像报告自动生成模型主要借鉴了机器翻译领域的 Encoder-Decoder 框架,利用卷积 神经网络(Convolutional Neural Network, CNN)对图像特征进行提取进而利用循环神经网络(Recurrent Neural Network, RNN)来生成影像的文本描述
应用场景
场景1:医院影像科医生人手不足,引入该技术后,阅片写报告时间大大降低
场景2:某偏远医院引入该技术后,疾病诊断率大大提高
场景3:引入医院大厅后,病人可以便利的通过机器预先了解影像的解释,避免重复询问。
场景4:引入该技术后,更多的资深医生有时间投入疑难疾病的研究诊断中。
在项目『IMAGE-CAPTION』基于CNN-RNN的影像报告生成-PRE中,我们介绍了基于CNN-RNN框架的影像报告生成项目。
并在印第安纳大学胸部 X 射线数据集进行了实现。该项目中,由于选择的模型为简单CNN-RNN结构,生成的效果较为一般。
在本项目中基于MICCAI2018中提出的全新结构在该数据集上再次进行实现,对齐论文指标及展示生成效果。
1 数据集
印第安纳大学胸部 X 射线集合 (IU X 射线) 是一组胸部 X 射线图像及其相应的诊断报告。该数据集包含 7,470 对图像和报告(6470:500:500)。 每个报告由以下部分组成:印象、发现、标签、比较和指示。平均每张图像关联2.2个标签,5.7个句子,每个句子包含6.5个单词。
- 本项目使用Findings与Impression共同作为图像生成标签
由于使用Findings生成的句子长度较短,且丰富性不足。
因此该类模型常用的方案是分成两个阶段,先生成主题词,再根据主题词生成报告。
参考代码:
https://gitee.com/Dane_work/MedicalReportGeneration/
https://github.com/tengfeixue-victor/Medical-Report-Generation
2 论文解读

2.1 摘要
计算机辅助放射学报告生成系统可以大大减轻放射科医生的工作量,并帮助他们做出决策。
为了给医学图像生成详细的段落描述,本文提出了一种新的生成模型,可以自动生成完整的放射学报告。
该模型将预训练的Resnet152模型与基于注意力机制的LSTM结构结合起来。
它不仅能够产生高度概括的主题词,而且能够逐句产生详细的描述性结果来支持主题词。
此外,提出的多模态模型将图像编码和生成的句子结合起来,构建一个注意力输入模块来指导下一个句子的生成。
主要的创新点:
使用了先生成主题(Impression),再根据主题生成报告(Findings)的两阶段生成模型。
提出一种递归的Attention模型提高生成结果的一致性。

2.2 模型结构
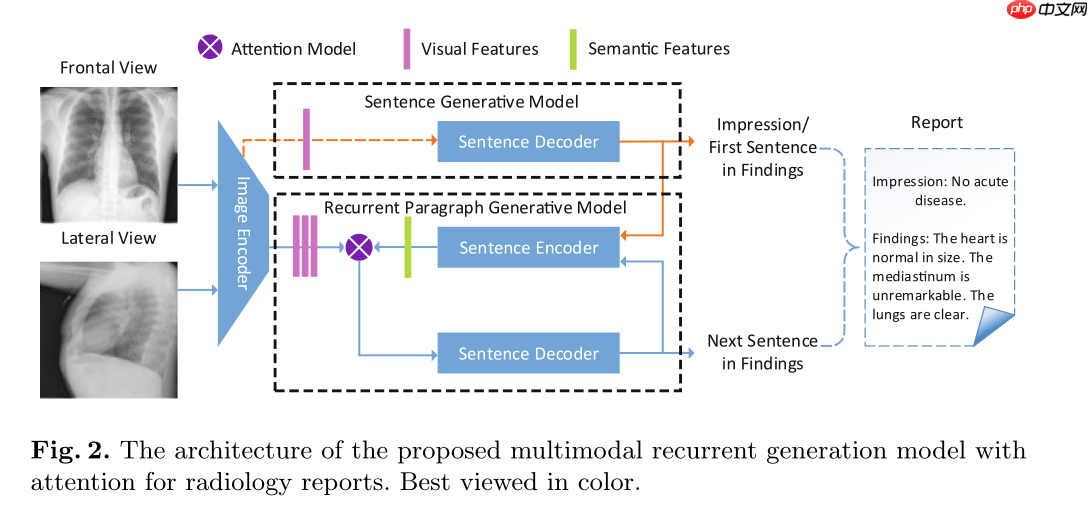
2.3 模型结果


3 评价指标介绍
该指标为自然语言处理经典评价指标,网络上已经有非常丰富的实现及公式推理,如果展开描述会使项目冗余。
因此本项目中仅简单介绍思想,更多的资料请读者自行查阅。
3.1 BLEU Score
随着深度自然语言的发展,对于模型结果的评估成为限制模型迭代的瓶颈。怎样快速的判断模型翻译语句的质量成为亟待解决的问题。BLEU的全名为:bilingual evaluation understudy,即:双语互译质量评估辅助工具。BLEU是做不到百分百的准确的,它只能做到一个大概判断,它的目标也只是给出一个快且不太差的自动评估解决方案。在BLEU的计算规则中,如果按单个词的去统计,我们统称为uni-grams(一元组集),在深度学习中因为模型和数据的复杂性,故常常都是面对n-grams(多元组集)的情况。3.2 ROUGE
ROUGE 指标的全称是 (Recall-Oriented Understudy for Gisting Evaluation),主要是基于召回率 (recall) 的,ROUGE 是一种常用的机器翻译和文章摘要评价指标,由 Chin-Yew Lin 提出,其在论文中提出了 4 种 ROUGE 方法:ROUGE-N: 在 N-gram 上计算召回率;ROUGE-L: 考虑了机器译文和参考译文之间的最长公共子序列;ROUGE-W: 改进了ROUGE-L,用加权的方法计算最长公共子序列;ROUGE-S:计算跳跃间隔的二原组(skip-bigram)同现的统计量。本项目选择ROUGE-L来验证模型生成的文本和真实文本的相似度。3.3 METEOR
基于召回率的标准与单纯基于精度例如BLEU的标准相比,其结果具有较大的主观因素影响。METEOR测度基于单精度的加权调和平均数和单字召回率,能有效的改进BLEU中存在的固有缺陷。在METEOR中,也包含其他指标中所不具有的一些改进功能,例如同义词匹配等,在计算METEOR时需要预先给出一组校准(alignment)m,而这一校准是在Word的同义词库基础之上给出,通过对应语句中连续有序的块(chunks)ch进行最小化得到。4 代码实现
4.1 图像编码器
class EncoderCNN(nn.Layer):
def __init__(self):
"""Load the pretrained ResNet-152, and extract local and global features"""
super(EncoderCNN, self).__init__() # load pretrained model from ImageNet
resnet = models.resnet152(pretrained=True)
local_features_mod = list(resnet.children())[:8]
global_features_mod = list(resnet.children())[8]
self.resnet_local = nn.Sequential(*local_features_mod)
self.resnet_global = nn.Sequential(global_features_mod) def forward(self, frontal_image):
"""Extract feature vectors from input images"""
# Does not train convolutional layers
with paddle.no_grad():
local_features = self.resnet_local(frontal_image)
global_features = self.resnet_global(local_features).squeeze() return global_features
4.2 注意力编码器
class Atten_Sen_Decoder(nn.Layer):
def __init__(self, embed_size, hidden_size, vocab_size, decoder_num_layers, sen_enco_num_layers,
num_global_features, num_regions, num_conv1d_out=1024, teach_forcing_rate=1.0, max_seq_length=15,
max_sentence_num=7, dropout_rate=0):
"""Set the hyper-parameters and build the layers for attention decoder"""
super(Atten_Sen_Decoder, self).__init__()
self.embed_h = nn.Linear(num_global_features + num_conv1d_out * sen_enco_num_layers,
hidden_size * decoder_num_layers)
self.embed_c = nn.Linear(num_global_features + num_conv1d_out * sen_enco_num_layers,
hidden_size * decoder_num_layers)
self.lstm = nn.LSTM(embed_size, hidden_size, decoder_num_layers, dropout=dropout_rate)
self.word_embed = nn.Embedding(vocab_size, embed_size)
self.linear = nn.Linear(hidden_size, vocab_size)
self.dropout = nn.Dropout(dropout_rate)
self.sentence_encoder = Sen_Encoder(embed_size, vocab_size, max_seq_length, num_conv1d_out)
self.decoder_num_layers = decoder_num_layers
self.embed_size = embed_size
self.max_seq_length = max_seq_length
self.max_sentence_num = max_sentence_num
self.vocab_size = vocab_size
self.num_regions = num_regions
self.num_conv1d_out = num_conv1d_out
self.teach_forcing_rate = teach_forcing_rate def forward(self, global_features, topic_vector, findings, fin_lengths):
"""Generate findings"""
gt_packed, decoder_outputs_packed = None, None
last_input, last_state = self._combine_vis_text(global_features, topic_vector) # sentence recurrent loop
for num_sen in range(findings.shape[1]): # impressions embedding
fin_sen_embedded = self.word_embed(findings[:, num_sen, :])
decoder_input = paddle.concat((last_input, fin_sen_embedded), axis=1) # The num of words for each sentence in the finding
fin_sen_lengths = fin_lengths[:, num_sen] if num_sen == 0:
gt_packed = findings[:, num_sen, :] else:
gt_packed = paddle.concat((gt_packed, findings[:, num_sen, :]), axis=0)
padded_outs, _ = self.lstm(decoder_input, last_state,sequence_length = fin_sen_lengths) #padded_outs, _ = pad_packed_sequence(out_lstm, batch_first=True)
fin_sen_outputs = F.log_softmax(self.dropout(self.linear(padded_outs)), axis=-1) if num_sen == 0:
decoder_outputs_packed = fin_sen_outputs else:
decoder_outputs_packed = paddle.concat((decoder_outputs_packed, fin_sen_outputs), axis=0)
predicted_sentences = paddle.argmax(fin_sen_outputs,axis = -1) if random.random() < self.teach_forcing_rate:
sen_vector = self.sentence_encoder(findings[:, num_sen, :]) else:
sen_vector = self.sentence_encoder(predicted_sentences)
last_input, last_state = self._combine_vis_text(global_features, sen_vector) # img add —— length changed
return gt_packed, decoder_outputs_packed[:,:-1,:] def sampler(self, global_features, topic_vector, max_single_sen_len, max_sen_num, ini_decoder_state=None):
""""Generate findings in the testing process"""
last_input, last_state = self._combine_vis_text(global_features, topic_vector) # The dimension of predicted_findings is denoted at the end
predicted_findings = [] # sentence recurrent loop
for num_sen in range(max_sen_num): # predicted sentences (indices), used for generating the preceding topic vector
predicted_single_sentence = [] # word recurrent loop
for time_step in range(max_single_sen_len):
decoder_output_t, decoder_state_t = self._word_step(last_input, last_state)
last_state = decoder_state_t
pre_indices = paddle.argmax(decoder_output_t,axis = -1)
pre_indices = pre_indices.unsqueeze(1)
predicted_single_sentence.append(pre_indices)
last_input = self.word_embed(pre_indices)
predicted_single_sentence = paddle.concat(predicted_single_sentence, axis=1)
sen_vector = self.sentence_encoder(predicted_single_sentence)
last_input, last_state = self._combine_vis_text(global_features, sen_vector)
predicted_single_sentence = predicted_single_sentence.unsqueeze(-1)
predicted_findings.append(predicted_single_sentence)
predicted_findings = paddle.concat(predicted_findings, axis=2)
predicted_findings = paddle.transpose(predicted_findings, perm=[0, 2, 1]) return predicted_findings def _combine_vis_text(self, global_features, sen_vec):
""" Combine visual features with semantic sentence vector to get hidden and cell state"""
ini_input = paddle.zeros([global_features.shape[0]],dtype='int64')
last_input = self.word_embed(ini_input).unsqueeze(1)
con_features = paddle.concat((global_features, sen_vec), axis=1)
h_stat = self.embed_h(con_features)
h_stat = paddle.transpose(paddle.reshape(h_stat,(h_stat.shape[0], self.decoder_num_layers, -1)),perm=[1, 0,2])
c_stat = self.embed_c(con_features)
c_stat = paddle.transpose(paddle.reshape(c_stat,(c_stat.shape[0], self.decoder_num_layers, -1)),perm=[1, 0,2])
last_state = (h_stat, c_stat) return last_input, last_state def _word_step(self, input_t, state_t):
"""generate sentence word by word"""
output_t, state_t = self.lstm(input_t, state_t)
out_t_squ = output_t.squeeze(1)
out_fc = F.log_softmax(self.linear(out_t_squ), axis=-1) return out_fc, state_t
4.3 Impression编码器
class Impression_Decoder(nn.Layer):
def __init__(self, embed_size, hidden_size, vocab_size, num_layers, num_global_features, num_conv1d_out=1024,
teach_forcing_rate=0.5, max_seq_length=15, dropout_rate=0):
"""Set the hyper-parameters and build the layers for impression decoder"""
super(Impression_Decoder, self).__init__() # from frontal images
self.visual_embed = nn.Linear(num_global_features, embed_size)
self.word_embed = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, hidden_size, num_layers, dropout=dropout_rate)
self.linear = nn.Linear(hidden_size, vocab_size)
self.dropout = nn.Dropout(dropout_rate)
self.sentence_encoder = Sen_Encoder(embed_size, vocab_size, max_seq_length, num_conv1d_out)
self.max_seq_length = max_seq_length
self.vocab_size = vocab_size
self.teach_forcing_rate = teach_forcing_rate
self.embed_size = embed_size
self.vocab_size = vocab_size
self.num_conv1d_out = num_conv1d_out def forward(self, global_features, impressions, imp_lengths):
"""Decode image feature vectors and generates the impression, and also global topic vector"""
vis_embeddings = self.visual_embed(global_features)
ini_input = vis_embeddings.unsqueeze(1) # impressions embedding
imp_embedded = self.word_embed(impressions)
decoder_input = paddle.concat((ini_input, imp_embedded), axis = 1) ####
padded_outs, _ = self.lstm(decoder_input,sequence_length = imp_lengths)
decoder_outputs = F.log_softmax(self.dropout(self.linear(padded_outs)), axis=-1)
predicted_sentences = paddle.argmax(decoder_outputs,axis = -1) if random.random() < self.teach_forcing_rate:
topic_vector = self.sentence_encoder(impressions) else:
topic_vector = self.sentence_encoder(predicted_sentences) return impressions, decoder_outputs[:,:-1,:], topic_vector def sampler(self, global_features, max_len, ini_decoder_state=None):
""""Generate the impression in the testing process"""
vis_embeddings = self.visual_embed(global_features)
ini_input = vis_embeddings.unsqueeze(1)
decoder_input_t = ini_input
decoder_state_t = ini_decoder_state
impression_ids = [] for i in range(max_len):
decoder_output_t, decoder_state_t = self._forward_step(decoder_input_t, decoder_state_t)
pre_indices = paddle.argmax(decoder_output_t,axis = -1)
pre_indices = pre_indices.unsqueeze(1)
impression_ids.append(pre_indices)
decoder_input_t = self.word_embed(pre_indices)
impression_ids = paddle.concat(impression_ids, axis=1)
topic_vector = self.sentence_encoder(impression_ids) return impression_ids, topic_vector def _forward_step(self, input_t, state_t):
"""Used in testing process to generate word by word for impression"""
output_t, state_t = self.lstm(input_t, state_t)
out_t_squ = output_t.squeeze(1)
out_fc = F.log_softmax(self.linear(out_t_squ), axis=-1) return out_fc, state_t
# 解压数据集!unzip -oq /home/aistudio/data/data130561/NLMCXR_Frontal.zip -d /home/aistudio/work/IUdata/# 解压项目!unzip -oq /home/aistudio/data/data130561/code.zip -d /home/aistudio/work/
# numpy降级 解决警告!pip install -U numpy==1.19.2
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple Requirement already satisfied: numpy==1.19.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (1.19.2)
# 切换工作目录%cd /home/aistudio/work/Medical-Report-Generation-master
/home/aistudio/work/Medical-Report-Generation-master
## 训练代码#!python trainer.py
## 测试代码!python tester.py
Namespace(crop_size=224, embed_size=512, eval_batch_size=75, eval_json_dir='IUdata/IUdata_test.json', fin_num_layers=2, hidden_size=512, image_dir='IUdata/NLMCXR_Frontal', imp_fin_only=False, imp_layers_num=1, log_step=100, max_impression_len=15, max_sen_num=7, max_single_sen_len=15, model_path='model_weights', num_conv1d_out=1024, num_global_features=2048, num_local_features=2048, num_regions=49, num_workers=2, resize_size=256, save_step=1000, sen_enco_num_layers=3, single_punc=True, teach_rate=0.0, vocab_path='IUdata/IUdata_vocab_0threshold.pkl')
W0427 01:15:13.766130 723 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0427 01:15:13.769623 723 device_context.cc:465] device: 0, cuDNN Version: 7.6.
100%|████████████████████████████████| 355826/355826 [00:04<00:00, 71365.09it/s]
{'testlen': 1752, 'reflen': 2924, 'guess': [1752, 1452, 1152, 852], 'correct': [985, 426, 206, 89]}
ratio: 0.5991792065661425
{'testlen': 12006, 'reflen': 10539, 'guess': [12006, 11706, 11406, 11106], 'correct': [4721, 2252, 1125, 595]}
ratio: 1.139197267292804
{'testlen': 13758, 'reflen': 13463, 'guess': [13758, 13458, 13158, 12858], 'correct': [5874, 2852, 1452, 744]}
ratio: 1.0219119067071958
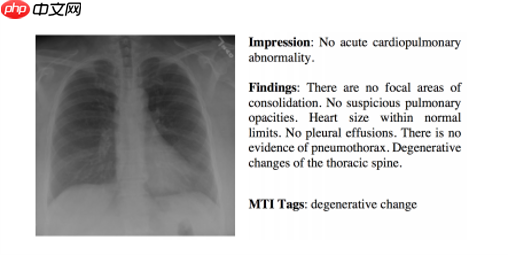
Impression: bleu = [0.288, 0.208, 0.1583, 0.1207], meteor = 0.1385, rouge = 0.5113, cider = 1.5829
Finding: bleu = [0.3932, 0.275, 0.1954, 0.1414], meteor = 0.1841, rouge = 0.3206, cider = 0.1415
Impression + Finding: bleu = [0.427, 0.3008, 0.2153, 0.155], meteor = 0.1799, rouge = 0.3459, cider = 0.1384
5 实验结果
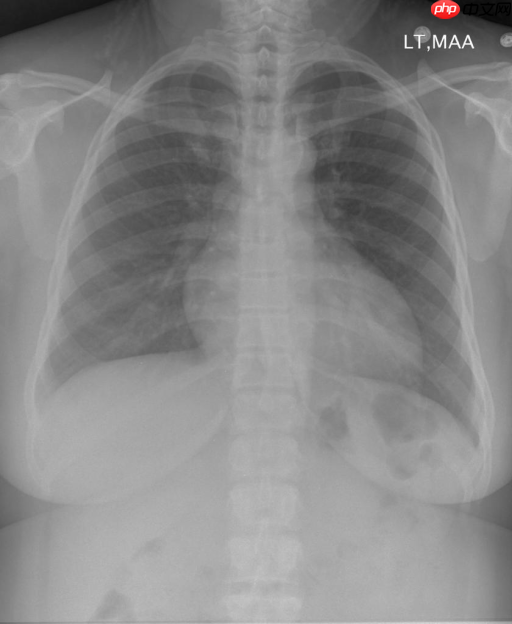
5.1 视觉效果对比
| 图片-CXR2230_IM-0831-1001 |
|---|
| @@##@@ |
Findings
- (真实)
mediastinal contours are normal .
heart size is upper limits of normal .
lungs are clear .
there is no pneumothorax or large pleural effusion .
no bony abnormality.
- (预测)
the heart size is normal .
the lungs are clear .
there is no pneumothorax or pleural effusion .
there are no focal areas of consolidation .
no pneumothorax .
no pleural effusion .
no pneumothorax .
Impression
- (真实)
no acute cardiopulmonary abnormality
- (预测)
no acute cardiopulmonary abnormality
根据生成结果,可以发现生成的结果是具有一定的医学语义的。
5.2 量化效果对比
| 模型 | BLEU_1 | BLEU_2 | BLEU_3 | BLEU_4 | METEOR | ROUGE |
|---|---|---|---|---|---|---|
| Orignal-Paper [1] | 0.416 | 0.298 | 0.217 | 0.163 | 0.227 | 0.309 |
| Pytorch-Result | 0.444 | 0.315 | 0.224 | 0.162 | 0.189 | 0.364 |
| Paddle-Result | 0.4296 | 0.3054 | 0.2175 | 0.1593 | 0.1797 | 0.3478 |
- 论文是基于TensorFlow实现的代码,参考仓库是基于Pytorch实现,本项目使用Paddle实现,最终结果优于原始实现,但略低于Pytorch实现。
参考论文
[1] Xue, Y., Xu, T., Long, L.R., Xue, Z., Antani, S., Thoma, G.R., Huang, X.: Multimodal recurrent model with attention for automated radiology report generation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 457–466. Springer (2018)
[2] Demner-Fushman, D., Kohli, M.D., Rosenman, M.B., Shooshan, S.E., Rodriguez, L., Antani, S., Thoma, G.R., McDonald, C.J.: Preparing a collection of radiology examinations for distribution and retrieval. J. Am. Med. Inform. Assoc. 23(2), 304–310 (2015)