本文围绕科大讯飞中-英机器翻译质量评估赛事展开,介绍赛事任务、数据及评审规则。采用MTransQuest模型作为基线方案,用WMT20-task1数据训练,处理数据并分析分布与长度。经训练、验证和预测,得出不同模型表现,还给出优化思路,为参赛队伍提供参考。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

举办方:科大讯飞股份有限公司
任务类型:质量评估(QE)、自然语言回归
赛事背景
机器翻译质量评估(QE)指在没有人工翻译参考下对机器翻译系统译文进行自动打分。一方面,QE技术可以协助人工校正机器翻译后编辑(PE)过程,通过QE评分指示机器翻译结果是否值得译后编辑;另一方面,QE技术可以用来改善机器翻译系统,通过QE技术挖掘机器翻译系统存在的死点问题,从而进行数据清洗,迭代优化机器翻译模型质量。
当前基于神经网络模型的QE技术受到学术界关注,但是工业级QE技术应用尚不成熟,由于人工评分数据稀疏、评分主观性较大、数据多样性差等问题,QE技术还需要研究和优化。
赛事任务
本次大赛提供非受限场景,可使用任何数据资源和模型,在提供的500句中->英方向的翻译数据上进行质量评估(0-100分)。数据如下:
训练集:无
开发集:500句中-英机翻数据及人工评分数据;
测试集:500句中-英机翻数据;
评审规则
1.数据说明 所有文件均要求为UTF-8编码,其中评测组织方发放的开发集(含人工评分数据)、测试集以及参评单位最终提交的机翻评分结果文件为纯文本文件。
评测组织方发放的数据有两种,分别为:开发集和测试集。下面具体说明这些数据文件的格式。
1)开发集
本次比赛为参赛选手提供开发集包含机器翻译句对及人工评分数据(0-100分,打分最小粒度为5分)。训练集由逐行对应的源语言文件和目标语言文件组成,每行为一个句子。训练集由平行句对数据文件和单语数据文件组成,平行句对数据文件中每行包含马来语-中文对齐句子,源/目标语言句子间采用’\t’分隔,文件命名valid.txt。
2)测试集
为了方便组织评测,在评测阶段组织方发放测试集文件中只包含机器翻译句对(删除最后一栏评分数据),参赛选手需要提交QE系统评分数据,并按照开发集数据格式提交(不要打乱文件数据顺序),文件命名test.txt。
评估指标
本次比赛采用按与人工评分的pearson相关系数进行评价。 机器翻译效果人工评测标准:分别就“忠实度”和“流利度”两个维度制定评价标准,最终人工分为忠实度和流利度打分的算术平均值。
忠实度(fidelity):评测译文是否忠实地表达了原文的内容。按0–100分打分,打分最小粒度5分。
| 分数 | 得分标准 |
|---|---|
| 0 | 完全没有译出来 |
| 20 | 译文中只有个别词被孤立地翻译 |
| 40 | 译文中有少数短语或比词大的语法成分被翻译 |
| 60 | 原文中60%的概念及其之间的关系被正确翻译,或原文中的主谓宾及其关系被正确的翻译 |
| 80 | 原文中80%的概念及其之间的关系被正确翻译 |
| 100 | 原文中100%的概念及其之间的关系被正确翻译 |
流利度(fluency):评测译文是否流畅和地道。按0–100分打分,打分最小粒度5分。
| 分数 | 得分标准 |
|---|---|
| 0 | 完全不可理解 |
| 20 | 译文晦涩难懂(只有个别短语或比词大的语法成分可以理解) |
| 40 | 40%的部分基本流畅(少数的短语或比词大的语法成分可以理解) |
| 60 | 译文60%的部分基本流畅 |
| 80 | 译文80%的部分基本流畅,或原文中的主谓宾部分基本流畅,只是个别词语或搭配不地道 |
| 100 | 译文流畅而且地道 |
系统要求
本赛题为“非受限场景”,参评单位可以自由选择所采用技术方案和训练数据。
非受限场景,具体说明如下:
• 对于以基于规则的QE技术为主的参评系统,允许采用通过人工方式构造的翻译知识(如规则、模板、词典等),但要在系统描述和技术报告中对所使用的翻译知识的规模、构造和使用方式等给出清晰的说明。
• 可以使用开源工具/库来进行数据处理或方案优化,如词法分析、句法分析及命名实体识别工具等,使用时需要注明开源工具来源;禁止直接或间接使用开源质量评估工具。
• 鼓励使用开源数据,使用时需要注明开源数据来源。
• 可以使用开源的预训练模型比如mBERT、mBART等,使用时需要注明使用开源模型描述与地址,不可使用m2m100等开源翻译模型。
本塞题属于句子级翻译质量评估(QE)任务,通常被视为有监督的回归问题。笔者是首次接触机器翻译质量评估相关的任务,对于笔者来说本任务有两个难点:
1.比赛不允许直接或间接使用开源质量评估工具,但可以学习开源质量评估框架是如何工作的,复现其模型方法再重新训练以搭建一个Baseline方案。通过查询文献资料,发现TransQuest是目前SOTA级别的开源质量评估框架。其论文发表在EMNLP2020会议上,其中作者提出了两个不同神经网络框架MonoTransQuest (MTransQuest)和SiameseTransQuest (STransQuest)执行句子级翻译质量评估任务,如下图所示:
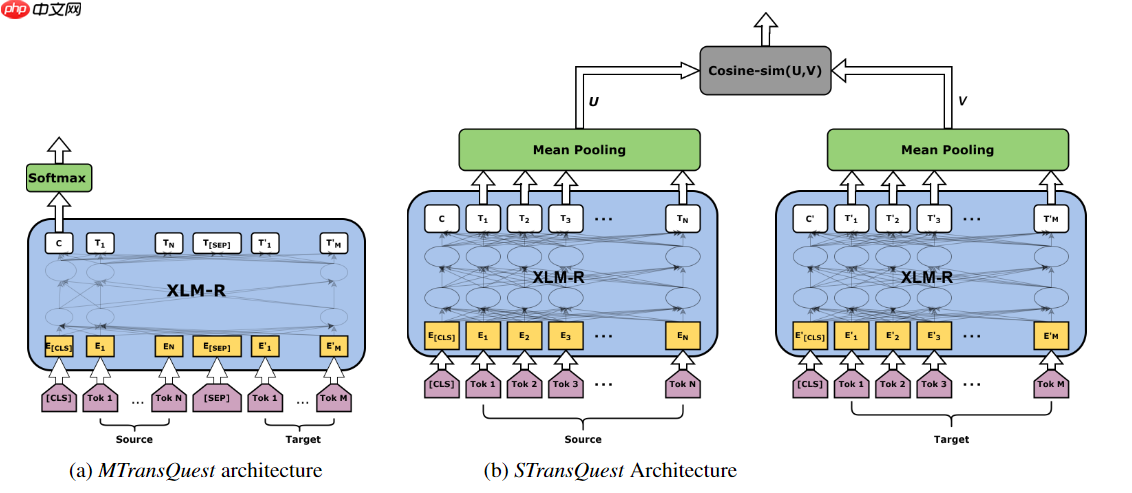
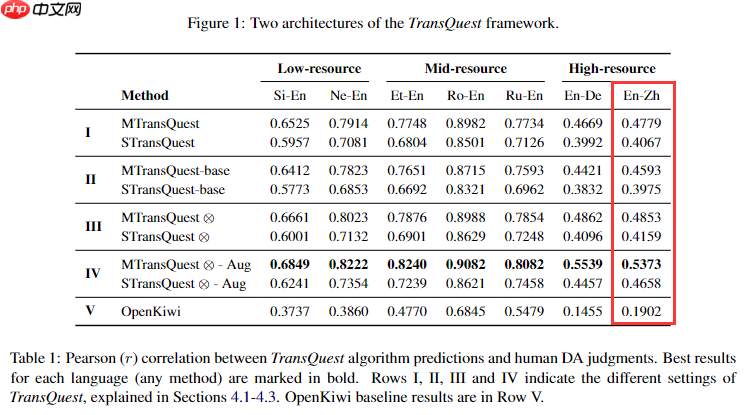
从模型结构上看MTransQuest和STransQuest并不复杂,尝试复现简单模型以搭建Baseline,根据论文实验显示,TransQuest提出的两个框架在En-Zh数据上Pearson系数至少到达0.4,并且MTransQuest的STransQuest要优于STransQuest,经过数据增强后两个框架分数有明显改善(数据增强可能是后续Baseline优化的重要方向),故尝试以MTransQuest模型作为Baseline方案,在模型选择上论文使用XLM-R模型,由于当前版本的Paddlenlp尚未加入XLM系列的预训练模型,本文使用bert-base-multilingual-cased和bert-base-multilingual-uncased替代XLM-R模型。
2.比赛并未提供训练数据,根据相关文献在机器翻译质量评估任务上,用较多的是WMT系列数据集,其中WMT20数据集的Task1:Sentence-Level Direct Assessment与赛题接近,拟采用WMT20-task1的EN-ZH英汉数据进行微调训练。

| model | 线下 | 线上 | Gap |
|---|---|---|---|
| MTransQuest-BM_cased | 0.36163 | 0.15237 | 0.20926 |
| MTransQuest-BM_uncased | 0.36847 | 0.17389 | 0.19458 |
(2022.06.29)排名rank1 发现不区分大小写bert-base-multilingual-uncased在线上线下都取的了更好的效果
首次接触QE任务和自然语言回归任务,希望本Baseline能够参加比赛的队伍带来思路,希望榜前的大佬多多分享比赛思路!
# 注意请将paddlenlp更新至最新版本!pip install -U paddlenlp
import osimport jsonimport randomimport numpy as npimport pandas as pdfrom tqdm import tqdmfrom sklearn.metrics import accuracy_scorefrom sklearn.model_selection import train_test_splitimport paddleimport paddlenlpimport paddle.nn.functional as Ffrom functools import partialfrom paddlenlp.data import Stack, Dict, Padfrom paddlenlp.datasets import load_datasetfrom paddlenlp.transformers.bert.tokenizer import BertTokenizerimport matplotlib.pyplot as pltimport seaborn as snsfrom scipy.stats import pearsonr
seed = 12345def set_seed(seed):
paddle.seed(seed)
random.seed(seed)
np.random.seed(seed)
set_seed(seed)# 查看可用的预训练模型BertTokenizer.pretrained_resource_files_map['vocab_file'].keys()
dict_keys(['bert-base-uncased', 'bert-large-uncased', 'bert-base-cased', 'bert-large-cased', 'bert-base-multilingual-uncased', 'bert-base-multilingual-cased', 'bert-base-chinese', 'bert-wwm-chinese', 'bert-wwm-ext-chinese', 'macbert-large-chinese', 'macbert-base-chinese', 'simbert-base-chinese', 'uer/chinese-roberta-base', 'uer/chinese-roberta-medium', 'uer/chinese-roberta-6l-768h', 'uer/chinese-roberta-small', 'uer/chinese-roberta-mini', 'uer/chinese-roberta-tiny'])
# 超参数MODEL_NAME = 'bert-base-multilingual-uncased' # bert-base-multilingual-cased# 给出的标签均为文本,创建label_map构建映射关系max_seq_length = 400train_batch_size = 16valid_batch_size = 8test_batch_size = 8# 训练过程中的最大学习率learning_rate = 1e-5# 训练轮次epochs = 5# 学习率预热比例warmup_proportion = 0.1# 权重衰减系数,类似模型正则项策略,避免模型过拟合weight_decay = 0.01max_grad_norm = 1.0# 训练结束后,存储模型参数save_dir_curr = "checkpoint/model"# 记录训练epoch、损失等值loggiing_print = 50loggiing_eval = 50# 提交文件名称sumbit_name = "work/sumbit.csv"
# WMT20-task1数据 使用pandas 读取存在问题,改用open方式读取# 舍弃部分字段如scores,z_scores、z_mean,以平均分作为scoresdef read_wmt20(file_name):
wmt20_data = [] with open(file_name,"r") as f: for idx,line in enumerate(f.readlines()): if idx!=0:
task_list = line.split("\t")
scores = int(eval(task_list[4])) if scores % 10 <4:
scores = scores - scores % 10
elif scores < 7:
scores = scores //10 * 10 + 5
else:
scores = (scores //10 + 1) * 10
wmt20_data.append({ "index":task_list[0], "original":task_list[2], "translation":task_list[1], "scores":scores / 100 ,
}) return wmt20_data# 读取讯飞比赛数据,处理为相同格式def read_xfqe(df,istrain=True):
xfqe_data = [] for idx,rows in df.iterrows(): if istrain:
xfqe_data.append({ "index":idx, "original":rows["original"], "translation":rows["translation"], "scores":int(rows["scores"]) / 100,
}) else:
xfqe_data.append({ "index":idx, "original":rows["original"], "translation":rows["translation"],
}) return xfqe_data
valid = pd.read_csv("data/data154704/valid.txt",sep='\t',names=["original","translation","scores"])
test = pd.read_csv("data/data154704/test.txt",sep='\t',names=["original","translation"])
valid = valid[valid["scores"].notna()]
xfqe_valid = read_xfqe(valid)
xfqe_test = read_xfqe(test,istrain=False)
wmt20_train = read_wmt20("data/data154704/train.enzh.df.short.tsv")
wmt20_dev = read_wmt20("data/data154704/dev.enzh.df.short.tsv")print(len(wmt20_train),len(wmt20_dev))print(len(xfqe_valid),len(xfqe_test))
wmt20_train = wmt20_train + wmt20_devprint("train size: %d \nvalid size %d \ntest size %d" % (len(wmt20_train),len(xfqe_valid),len(xfqe_test)))7000 1000 494 500 train size: 8000 valid size 494 test size 500
# 绘制wmt20的质量分数分布pd.DataFrame(wmt20_train)['scores'].hist()
<matplotlib.axes._subplots.AxesSubplot at 0x7f3d3d0497d0>
<Figure size 432x288 with 1 Axes>
# 绘制wmt20-task1数据集的文本长度分布states_wmt20 = pd.DataFrame(wmt20_train)
states_wmt20['original_len'] = [len(i) for i in states_wmt20["original"]]
states_wmt20['translation_len'] = [len(i) for i in states_wmt20["translation"]]
states_wmt20['concat_len'] = [i+j for i,j in zip(states_wmt20["original_len"],states_wmt20["translation_len"])]
plt.title("wmt20 text length")
sns.distplot(states_wmt20['original_len'],bins=10,color='r')
sns.distplot(states_wmt20['translation_len'],bins=10,color='g')
sns.distplot(states_wmt20['concat_len'],bins=10,color='b')
plt.show()<Figure size 432x288 with 1 Axes>
# 绘制讯飞数据集的文本长度分布states_valid = valid.copy()
states_valid['original_len'] = [len(i) for i in states_valid["original"]]
states_valid['translation_len'] = [len(i) for i in states_valid["translation"]]
states_valid['concat_len'] = [i+j for i,j in zip(states_valid["original_len"],states_valid["translation_len"])]
plt.title("xf valid text length")
sns.distplot(states_valid['original_len'],bins=10,color='r')
sns.distplot(states_valid['translation_len'],bins=10,color='g')
sns.distplot(states_valid['concat_len'],bins=10,color='b')
plt.show()<Figure size 432x288 with 1 Axes>
# 绘制讯飞数据集的文本长度分布states_test = test.copy()
states_test['original_len'] = [len(i) for i in states_test["original"]]
states_test['translation_len'] = [len(i) for i in states_test["translation"]]
states_test['concat_len'] = [i+j for i,j in zip(states_test["original_len"],states_test["translation_len"])]
plt.title("xf test text length")
sns.distplot(states_test['original_len'],bins=10,color='r')
sns.distplot(states_test['translation_len'],bins=10,color='g')
sns.distplot(states_test['concat_len'],bins=10,color='b')
plt.show()<Figure size 432x288 with 1 Axes>
# 加载tokenizerif MODEL_NAME == 'bert-base-multilingual-cased':
tokenizer = BertTokenizer.from_pretrained(MODEL_NAME,do_lower_case=False)else:
tokenizer = BertTokenizer.from_pretrained(MODEL_NAME)def read(df,istrain=True):
if istrain: for data in df: yield { "original":data['original'], "translation":data['translation'], "labels":data['scores']
} else: for data in df: yield { "original":data['original'], "translation":data['translation'],
}# 将生成器传入load_datasettrain_ds = load_dataset(read, df=wmt20_train, lazy=False)
valid_ds = load_dataset(read, df=xfqe_valid, lazy=False)# 查看数据for idx in range(1,3): print(train_ds[idx]) print("==="*30)for idx in range(1,3): print(valid_ds[idx]) print("==="*30){'original': '他把欧文扔进了挖掘机挖出儿子心脏的坑里.', 'translation': "He shoves Owen into the pit where Digger rips out his son's heart.", 'labels': 0.6}
==========================================================================================
{'original': "Alpha Phi Alpha 还参加了 Dimes 'WalkAmerica 的 3 月活动 , 并在 2006 年筹集了 181 000 美元。", 'translation': "Alpha Phi Alpha also participates in the March of Dimes' WalkAmerica and raised over $181,000 in 2006.", 'labels': 0.7}
==========================================================================================
{'original': '屏幕需要稍加区别对待。', 'translation': 'The screen needs to be treated a little differently.', 'labels': 1.0}
==========================================================================================
{'original': 'He told the referee that he had not been fouled, but the referee insisted he take the penalty kick.', 'translation': '他 告诉 裁判 他 并 没有 犯规 , 但是 裁判 坚持 让 他 踢 点球 。', 'labels': 1.0}
==========================================================================================# 编码def convert_example(example, tokenizer, max_seq_len=512, mode='train'):
# 调用tokenizer的数据处理方法把文本转为id
tokenized_input = tokenizer(
example['original'] + '[SEP]' + example['translation'],
is_split_into_words=True,
max_seq_len=max_seq_len) if mode == "test": return tokenized_input # 把意图标签转为数字id
tokenized_input['labels'] = example['labels'] return tokenized_input
train_trans_func = partial(
convert_example,
tokenizer=tokenizer,
mode='train',
max_seq_len=max_seq_length)
valid_trans_func = partial(
convert_example,
tokenizer=tokenizer,
mode='dev',
max_seq_len=max_seq_length)
train_ds.map(train_trans_func, lazy=False)
valid_ds.map(valid_trans_func, lazy=False)# 初始化BatchSamplertrain_batch_sampler = paddle.io.BatchSampler(train_ds, batch_size=train_batch_size, shuffle=True)
valid_batch_sampler = paddle.io.BatchSampler(valid_ds, batch_size=valid_batch_size, shuffle=False)# 定义batchify_fnbatchify_fn = lambda samples, fn = Dict({ "input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id),
"token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id), "labels": Stack(dtype="float32"),
}): fn(samples)# 初始化DataLoadertrain_data_loader = paddle.io.DataLoader(
dataset=train_ds,
batch_sampler=train_batch_sampler,
collate_fn=batchify_fn,
return_list=True)
valid_data_loader = paddle.io.DataLoader(
dataset=valid_ds,
batch_sampler=valid_batch_sampler,
collate_fn=batchify_fn,
return_list=True)import paddlefrom paddle import nnfrom paddlenlp.transformers.bert.modeling import BertPretrainedModel# Modelclass MTransQuestErnieM(BertPretrainedModel):
def __init__(self, bert, labels_dim=1, dropout=None):
super().__init__() # 预训练模型
self.bert = bert
self.dropout = nn.Dropout(self.bert.config['hidden_dropout_prob'])
self.classifier = nn.Linear(self.bert.config['hidden_size'],labels_dim)
self.sigmoid = nn.Sigmoid()
self.apply(self.init_weights) def forward(self,
input_ids,
token_type_ids=None):
sequence_output,_ = self.bert(
input_ids,
token_type_ids=token_type_ids)
sequence_output = self.dropout(sequence_output[:,0,:])
sequence_output = self.classifier(sequence_output)
logits = self.sigmoid(sequence_output) return logits# 创建MTransQuest modelmodel = MTransQuestErnieM.from_pretrained(MODEL_NAME)
# 训练总步数num_training_steps = len(train_data_loader) * epochs# 学习率衰减策略lr_scheduler = paddlenlp.transformers.LinearDecayWithWarmup(learning_rate, num_training_steps,warmup_proportion)
decay_params = [
p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])
]# 定义优化器optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params,
grad_clip=paddle.nn.ClipGradByGlobalNorm(max_grad_norm))# 验证部分@paddle.no_grad()def evaluation(model, data_loader):
model.eval()
real_s = []
pred_s = [] for batch in data_loader:
input_ids, token_type_ids, labels = batch
logits = model(input_ids, token_type_ids)
logits = paddle.reshape(logits,[-1])
labels = labels
pred_s.extend(logits.numpy())
real_s.extend(labels.numpy())
score = pearsonr(pred_s,real_s)[0] return score# 训练阶段def do_train(model,data_loader):
model_total_epochs = 0
best_score = 0.
training_loss = 0
# 训练
print("train ...")
model.train() for epoch in range(0, epochs): for step, batch in enumerate(data_loader, start=1):
input_ids, token_type_ids, labels = batch
logits = model(input_ids, token_type_ids)
logits = paddle.reshape(logits,[-1])
labels = labels
loss = F.mse_loss(logits,labels)
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
training_loss += loss.numpy()
model_total_epochs += 1
if model_total_epochs % loggiing_print == 0: print("step: %d / %d, training loss: %.5f" % (model_total_epochs, num_training_steps, training_loss / model_total_epochs))
if model_total_epochs % loggiing_eval == 0:
eval_score = evaluation(model, valid_data_loader) print("eval pearsonr: %.5f" % eval_score) if best_score < eval_score: print("pearsonr update %.5f ---> %.5f " % (best_score,eval_score))
best_score = eval_score # 保存模型
os.makedirs(save_dir_curr,exist_ok=True)
save_param_path = os.path.join(save_dir_curr, 'model_best.pdparams')
paddle.save(model.state_dict(), save_param_path) # 保存tokenizer
tokenizer.save_pretrained(save_dir_curr) else: print("but best score %.5f" % best_score )
model.train() return best_scorebest_score = do_train(model,train_data_loader)
print("best pearsonr score: %.5f" % best_score)best pearsonr score: 0.36847
# 相同方式构造测试集test_ds = load_dataset(read,df=xfqe_test, istrain=False, lazy=False)
test_trans_func = partial(
convert_example,
tokenizer=tokenizer,
mode='test',
max_seq_len=max_seq_length)
test_ds.map(test_trans_func, lazy=False)
test_batch_sampler = paddle.io.BatchSampler(test_ds, batch_size=test_batch_size, shuffle=False)
test_batchify_fn = lambda samples, fn = Dict({ "input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id),
"token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
}): fn(samples)
test_data_loader = paddle.io.DataLoader(
dataset=test_ds,
batch_sampler=test_batch_sampler,
collate_fn=test_batchify_fn,
return_list=True)# 预测阶段def do_sample_predict(model,data_loader):
model.eval()
preds = [] for batch in data_loader:
input_ids, token_type_ids= batch
logits = model(input_ids, token_type_ids)
logits = paddle.reshape(logits * 100,[-1])
preds.extend(logits.numpy()) return preds# 读取最佳模型state_dict = paddle.load(os.path.join(save_dir_curr,'model_best.pdparams'))
model.load_dict(state_dict)# 预测print("predict start ...")
pred_score = []
pred_score_continuous = do_sample_predict(model,test_data_loader)# 将连续的预测值 转化 离散的分数(以5作为最小的粒度)for scores in pred_score_continuous: if scores % 10 <4:
scores = scores - scores % 10
elif scores < 7:
scores = scores //10 * 10 + 5
else:
scores = (scores //10 + 1) * 10
pred_score.append(int(scores))print("predict end ...")predict start ... predict end ...
sumbit = pd.DataFrame([],columns=['pred'])
sumbit["pred"] = pred_score
sumbit.to_csv("work/sumbit_{}.csv".format(MODEL_NAME),index=False,header=False)| model | 线下 | 线上 | Gap |
|---|---|---|---|
| MTransQuest-BM_cased | 0.36163 | 0.15237 | 0.20926 |
| MTransQuest-BM_uncased | 0.36847 | 0.17389 | 0.19458 |
发现不区分大小写bert-base-multilingual-uncased在线上线下都取的了更好的效果 提交测试文件,baseline方案取得了0.17389的线上分数(2022.06.29)排名rank1
以上就是讯飞机器翻译质量评估挑战赛Baseline(PaddlePaddle)的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 686
686






















