本文围绕乒乓球视频动作定位比赛展开,介绍赛题背景、重难点,指出乒乓球动作定位因动作短时、细微差异等更具挑战。还说明数据集、评价指标及数据处理方案,详述思路演进,最终采用特定改进的BMN网络,并给出基于PaddleVideo的训练、验证及预测流程。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

在众多大规模视频分析情景中,从冗长未经修剪的视频中定位并识别短时间内发生的人体动作成为一个备受关注的课题。当前针对人体动作检测的解决方案在大规模视频集上难以奏效,高效地处理大规模视频数据仍然是计算机视觉领域一个充满挑战的任务。其核心问题可以分为两部分,一是动作识别算法的复杂度仍旧较高,二是缺少能够产生更少视频提案数量的方法(更加关注短时动作本身的提案)。
这里所指的视频动作提案是指一些包含特定动作的候选视频片段。为了能够适应大规模视频分析任务,时序动作提案应该尽可能满足下面两个需求: (1)更高的处理效率,例如可以设计出使时序视频片段编码和打分更高效的机制; (2)更强的判别性能,例如可以准确定位动作发生的时间区间。
本次比赛旨在激发更多的开发者和研究人员关注并参与有关视频动作定位的研究,创建性能更出色的动作定位模型。赛题连接
乒乓球与其他运动项目相比,其动作类型的区分难度更大,这对识别任务来说是极大的挑战。对于乒乓球动作定位任务,主要难点如下:
本次比赛的数据集包含了19-21赛季兵乓球国际比赛(世界杯、世锦赛、亚锦赛,奥运会)和国内比赛(全运会,乒超联赛)中标准单机位高清转播画面的特征信息,共包含912条视频特征文件,每个视频时长在0~6分钟不等,特征维度为2048,以pkl格式保存。我们对特征数据中面朝镜头的运动员的回合内挥拍动作进行了标注,单个动作时常在0~2秒不等,训练数据为729条标注视频,而A榜测试集共91个未标注视频,B榜测试集共92个未标注视频,其中训练数据标签以json格式给出。更详细信息见赛题数据集及基线部分。
本次比赛我们采用AR@AN曲线下面积来评判模型效果。 AR(Average Recall) 即平均召回率,是由不同的时序交并比tIoU下计算得到的召回均值,tIoU 以0.05的步长从0.5取至0.9(包含0.5和0.9)。 AN(Average Number of Proposal per Video) 即平均提案数量,由提案总数除以测试集中视频总数得到。在计算AR@AN曲线下面积AUC时,AN以1为步长从0到100变化。 我们将对提交的文档进行打分,打分规则如下:
 详见赛题说明
详见赛题说明
先解压训练集和测试集(A榜或B榜),对于训练集,我们按照9:1或者39:1划分,前者是新的训练集,后者是验证集。对于训练,我们按照BMN论文单元3.5中Training Data Construction所讲,以一个滑动窗口对每一个长视频序列进行切分,其中步长为窗口长度的一半,实验中我们最终采取窗口大小为100,注意的是我们只保留包含至少一个完整提案的切片用于训练期间的模型训练与验证,保留的切片存放在/home/aistudio/data/pre_feat中。划分之后每个用于训练或验证的切片对应的标签等信息存放在/home/aistudio/PaddleVideo/data/bmn/annotations_win.json文件中,其中训练视频切片与验证视频切片用"subset"属性区分,"train"为训练视频切片,"validation"为验证视频切片。
除此以外,为了在训练完模型之后对保存的模型进行筛选得到其中较好的模型,我们先后设计了两种验证方案。第一种,就是基于以上提到的验证集视频切片划分,将每个切片当成一个完整视频,这样所得到的仅包含验证视频切片对应的标签等信息的json文件为/home/aistudio/PaddleVideo/data/bmn/annotations_val_gt.json。但是这样的一种验证方案是与测试集预测方案不符的。对于测试集,它是无标签的,所以按照相同的滑动窗口划分切片方式,它所保留的是所有的切片,即每个切片不一定包含提案,而且预测之后是要将每个视频对应的所有切片预测的提案进行汇总并进一步使用soft nms等方法筛选之后作为原未划分视频的提案信息。因此为了与预测方案保持一致,我们采取第二种验证方案,即我们对验证集视频采取相同的滑动窗口划分方式,但保留所有的切片,即每个切片不一定包含提案,最后将每个视频对应的所有切片预测的提案进行汇总筛选之后,基于验证集原未划分视频来进行评价指标AUC筛选出验证集上较好模型用于预测。其中第二种方案切片视频存放在/home/aistudio/data/val_feat,验证集原未划分视频对应标签信息保存在/home/aistudio/PaddleVideo/data/bmn/annotations_val_gt_merged.json。
对于测试集切片划分,与上一段所讲一致,即以一个滑动窗口对每一个长视频序列进行切分,其中步长为窗口长度的一半,实验中我们最终采取窗口大小为100,产生的所有切片保留,即每个切片不一定包含提案,存放在/home/aistudio/data/test_feat,切片信息存放在/home/aistudio/PaddleVideo/data/bmn/annotations_test.json。使用所有切片预测之后,要对预测提案进行后处理,即将每个视频对应的所有切片预测的提案进行汇总并进一步使用soft nms等方法筛选之后作为原未划分视频的提案信息,保存在submission.json中,打包之后即可提交A榜或B榜。
这里我们从这两个月中我们对网络进行几十次修改的方案中拿出来几个典型的案例(与最终方案相关)。
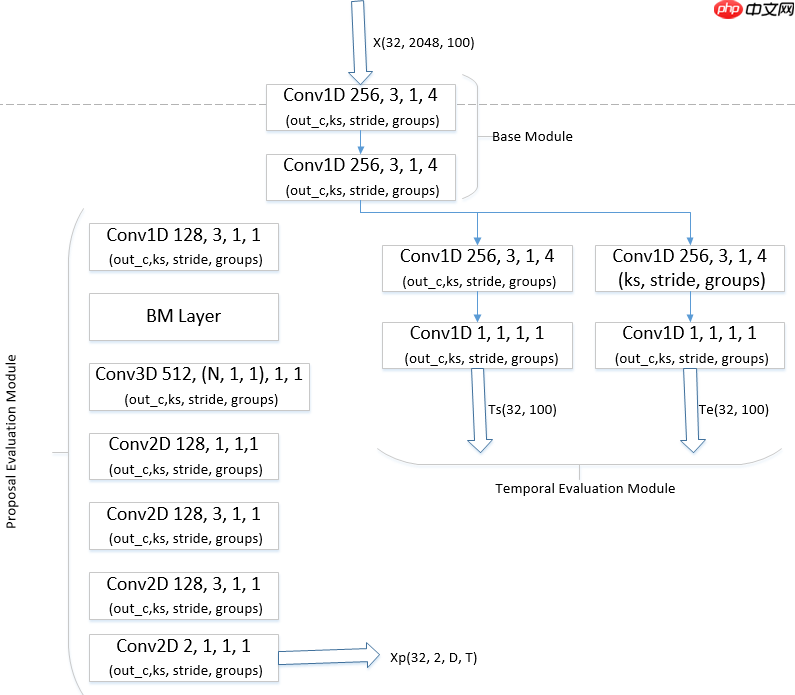
BMN模型是百度自研,2019年ActivityNet夺冠方案,为视频动作定位问题中proposal的生成提供高效的解决方案,在PaddlePaddle上首次开源。此模型引入边界匹配(Boundary-Matching, BM)机制来评估proposal的置信度,按照proposal开始边界的位置及其长度将所有可能存在的proposal组合成一个二维的BM置信度图,图中每个点的数值代表其所对应的proposal的置信度分数。网络由三个模块组成,基础模块作为主干网络处理输入的特征序列,TEM模块预测每一个时序位置属于动作开始、动作结束的概率,PEM模块生成BM置信度图。 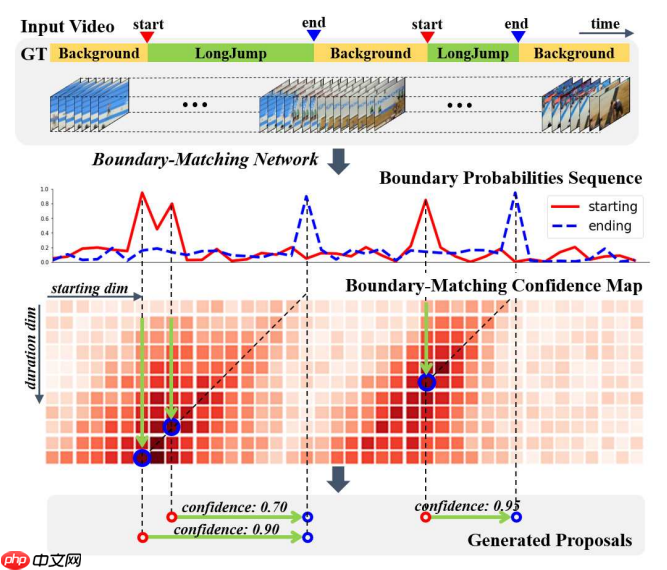
| batch size | A榜分数 |
|---|---|
| 16 | 46.595 |
| 32 | 46.895 |
其中bs=4, bs=8的结果分不清了,只列举bs=16,32的,至此所有模型训练基本使用bs=32
| D,T | A榜分数 |
|---|---|
| 100 | 46.895 |
| 200 | 45.459 |
其中D=100使用bs=32,D=200使用bs=8(再大会报错)。而且我们做了数据分析,发现D=60即可覆盖到99%的完整提案,因此之后均选择D=100(T==D)
也进行过学习率和优化器、衰减策略调整,不再赘述,之后所有实验基本按照原PaddleVideo的默认配置,除了把epochs调为20
使用soft nms再对汇总的提案进行筛选可进一步提高分数。
| 使用soft nms | A榜分数 |
|---|---|
| 否 | 37.428 |
| 是 | 45.459 |
这里我们在BMN网络基础上在Base Module部分增加SE注意力机制。如下图所示: 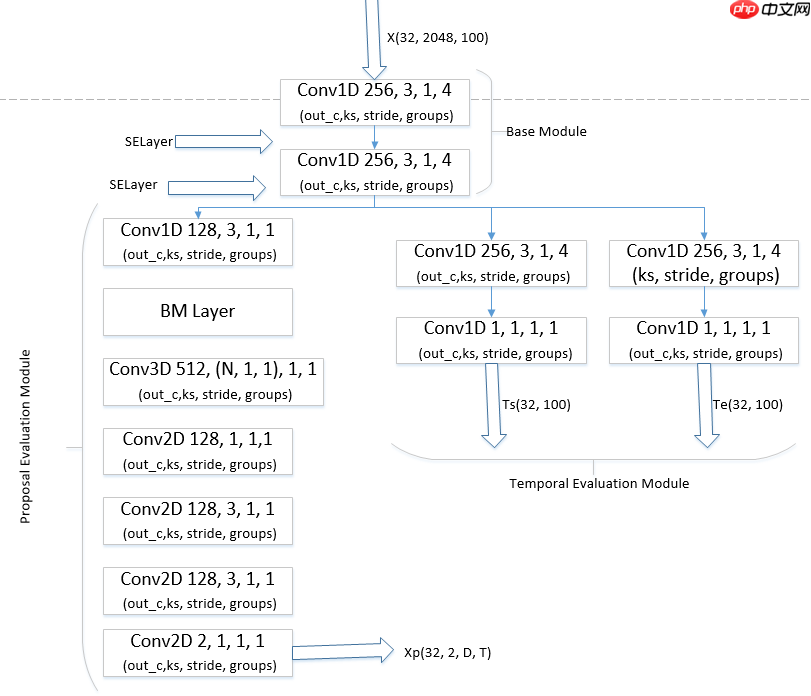
| 模型 | A榜分数 |
|---|---|
| BMN | 46.895 |
| BMN+se | 46.996 |
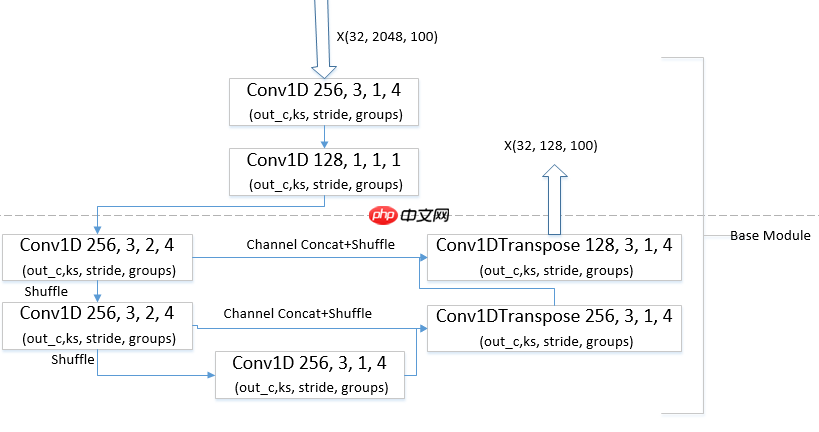
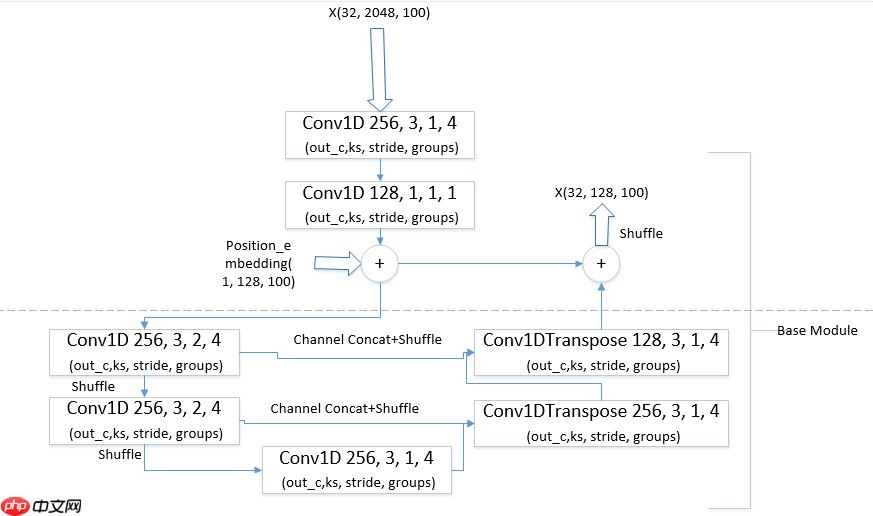
注意到BMN网络的Base Module的一维卷积使用的分组卷积,且连续使用两次,考虑到ShufffleNet,我们也使用通道Shuffle来使得不同组间交流信息。见下图: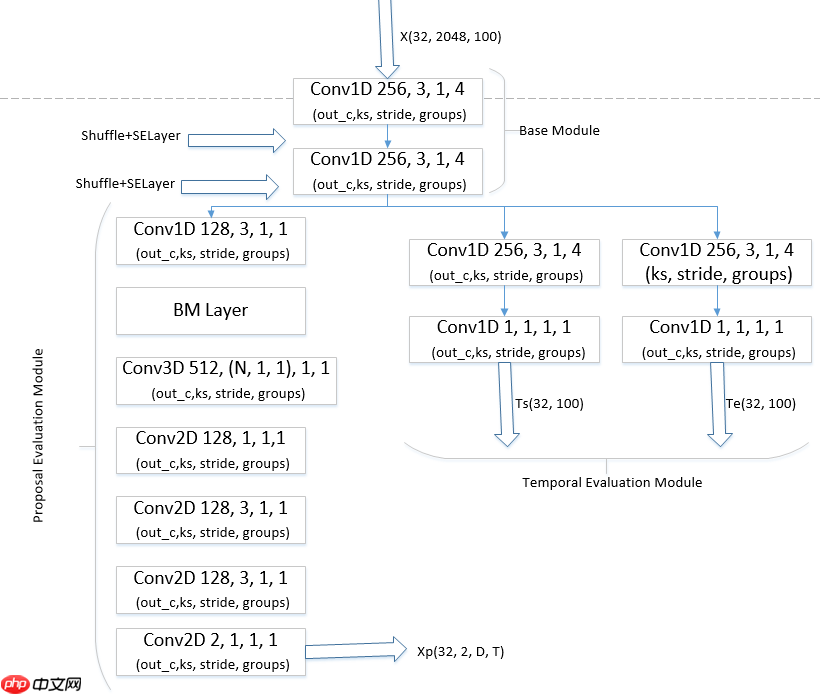
| 模型 | A榜分数 |
|---|---|
| BMN | 46.895 |
| BMN+se | 46.996 |
| BMN+se+s | 47.23 |
将BMN网络的Base Module部分改为降维模块+Unet结构来提升模型表达能力,为了降低增加卷积数量带来的参数量和浮点数运算量,我们均使用分组卷积和1x1卷积,同时尽可能使用相对较少的通道数。模型细节见下图: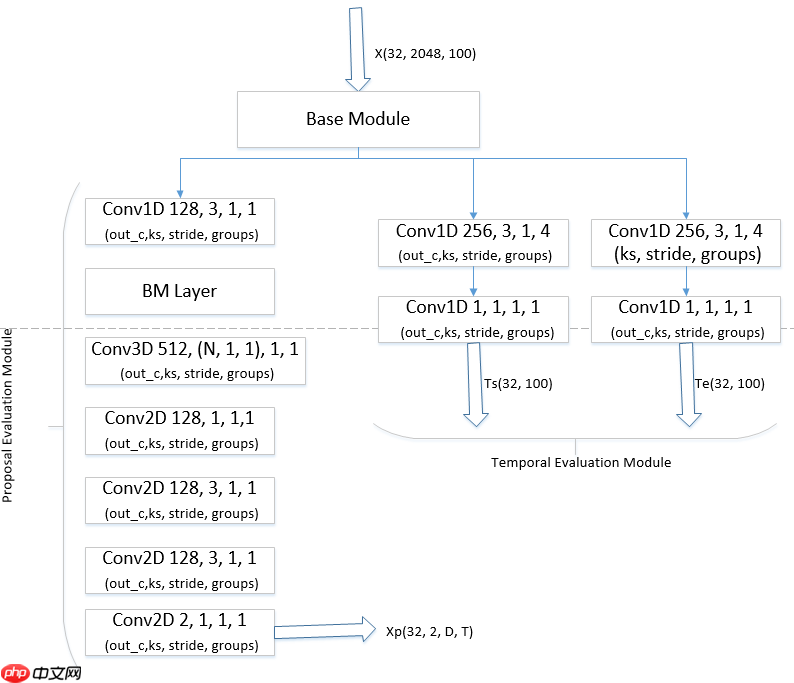
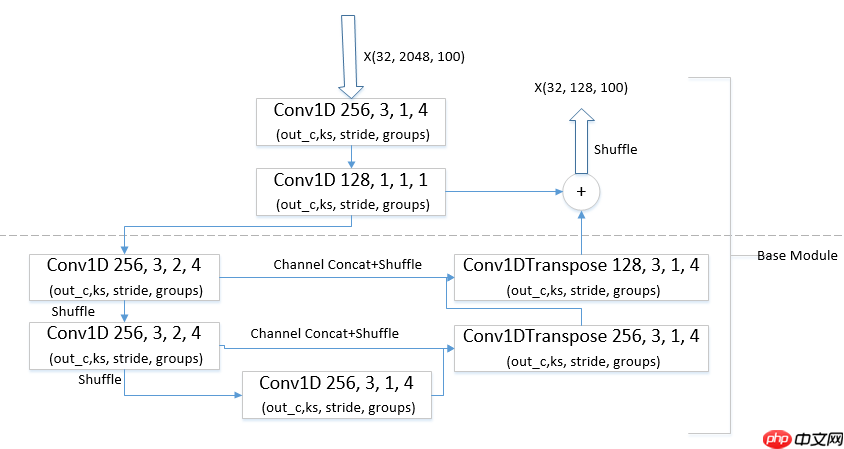
增加残差跳过连接res之后的Base Module,如下图所示:
| 模型 | A榜分数 |
|---|---|
| BMN | 46.895 |
| BMN+se | 46.996 |
| BMN+se+s | 47.23 |
| BMN+se+s+bunet | 47.227 |
| BMN+s+bunet | 47.649 |
| BMN+s+bunet+res | 47.72 |
因此,我们又放弃了se注意力机制。
原来:
tmp_width = tend[max_index] - tstart[max_index] if tmp_iou > t1 + (t2 - t1) * tmp_width:
修改之后:
tmp_width = (tend[max_index] - tstart[max_index])/dscale
if tmp_iou > t1 + (t2 - t1) * tmp_width:
对长视频序列的提案间隔进行了归一化操作,dscale即视频切片持续时间,当然这不是最优的方案,大家可以进一步的超参搜索。
| 修改 | A榜分数 |
|---|---|
| 前 | 47.542 |
| 后 | 48.123 |
因此之后均使用修改后的soft nms对测试视频提案进行后处理筛选。
划分改为39:1的原因是,如果验证集视频数量多,使用AUC的第二种的验证方案验证所有模型权重的时间较长,而使用39:1减少验证视频数量,要的时间短了,但可靠性降低了,因此只能作为一种参考,所以大家自己可以权衡。
本来是打算增加位置编码之后,确定视频开始与结束的差异,从而将视频时间正向,反向两次传入模型的时域评估模块,利用类似集成的方式来提高提案开始点和结束点的预测精度,但考虑到两次可能增加一部分计算量,没有采用,但增加位置编码之后仍然显著提高了精度。 第一种增加位置编码的位置(仅对Base Module修改, 其他相同与BMN):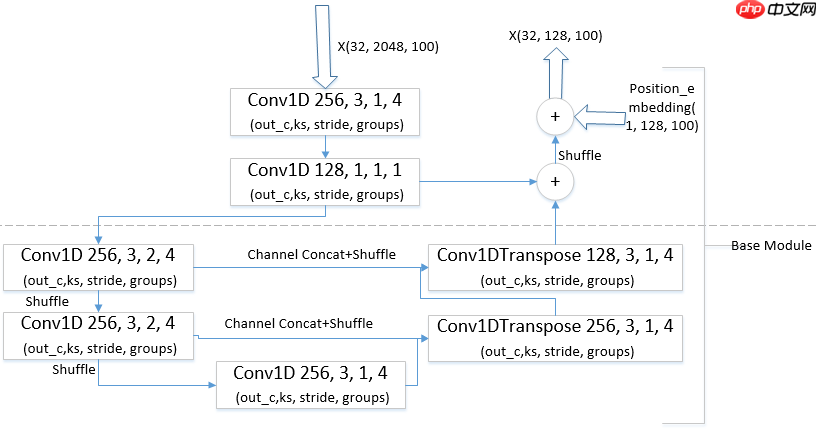
第二种,即我们的最终方案: 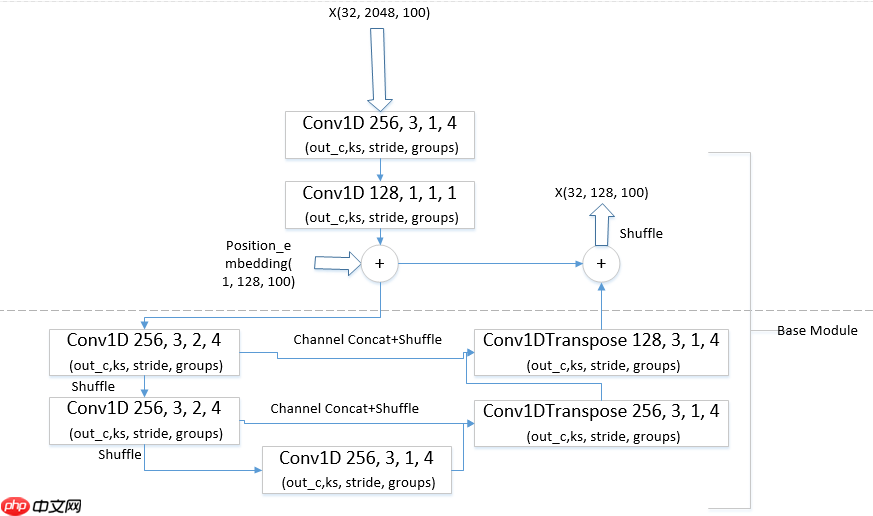
| 位置编码位置 | A榜分数 |
|---|---|
| 第一种 | 48.5126 |
| 第二种 | 48.82818 |
我们采用3.1.5 的第二种增加位置编码方式的与Unet结构结合使用Shuffle的BMN网络,结构如下所示: 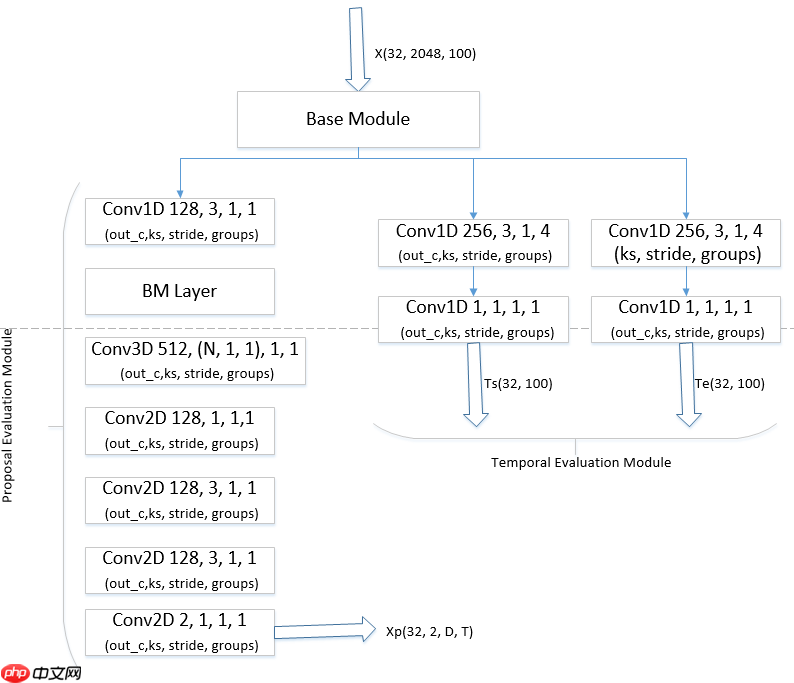
数据处理方案见2.3,参数选择可以见3.1
模型训练是基于PaddleVideo套件,并增加了generate_data_for_training.py和utils.py两个文件进行数据处理。除此之外,还对PaddleVideo套件做了略微的修改,以满足训练过程可视化等要求。模型验证是在PaddleVideo/paddlevideo/tasks/下增加了一个val.py文件,同时对PaddleVideo/下的main.py进行修改以控制训练、验证、测试三种模式,而且对PaddleVideo/paddlevideo/metrics/下的bmn_metric.py进行修改以可以汇总每个未划分原视频相应的切片对应的提案,并对汇总的提案逐原视频进行进一步的soft nms后处理,最后利用bmn_metric.py中的cal_metrics函数计算出每个模型相应的AUC分数,从而选出其中的较好模型。模型测试是对PaddleVideo/paddlevideo/loader/dataset/下的bmn_dataset.py进行修改,即增加了一个prepare_predict函数,可以通过将PaddleVideo/configs/localization/my_yaml/bmn_test.yaml中的test_model设为"predict"来控制进行预测模式,就可以使用4.4.2的命令来进行预测了,即
DATASET: #DATASET field batch_size: 32 #single card bacth size test_batch_size: 1 num_workers: 8 train: format: "BMNDataset" file_path: "data/bmn/annotations_win.json" subset: "train" valid: format: "BMNDataset" file_path: "data/bmn/annotations_win.json" subset: "validation" test: format: "BMNDataset" test_mode: "predict" # 这里为"predict" file_path: "data/bmn/annotations_test.json" subset: "validation"
注意,模型验证也是用的test_mode: "predict"模式,区别在于file_path不同,可以看PaddleVideo/configs/localization/my_yaml/bmn_val_merge.yaml进行对比。由于模型预测无标签,则需要去除test部分的一些关于标签的数据处理操作,即:
test: #Mandatory, indicate the pipeline to deal with the validing data. associate to the 'paddlevideo/loader/pipelines/'
load_feat:
name: "LoadFeat"
feat_path: "/home/aistudio/data/test_feat"
transform: #Mandotary, image transfrom operator
- GetMatchMap:
tscale: 100
#- GetVideoLabel:
# tscale: 100
# dscale: 100还有模型预测时不需要计算AUC,因此可以设置get_metrics: False来避免,即:
METRIC: name: 'BMNMetric' tscale: 100 dscale: 100 file_path: "data/bmn/annotations_test.json" ground_truth_filename: "" subset: "validation" output_path: "data/bmn/BMN_Test_output" result_path: "data/bmn/BMN_Test_results" get_metrics: False
而模型验证时需要计算AUC,则需设置get_metrics: True.
复现我们的预测结果的话,可以运行4.1.2之后直接到4.4部分。
%cd /home/aistudio/data/ %mkdir data122998/Features_competition_train !tar -xf data122998/Features_competition_train.tar.gz -C /home/aistudio/data/data122998/Features_competition_train --strip-components 1 && rm -rf data122998/Features_competition_train.tar.gz %cd /home/aistudio/
/home/aistudio/data /home/aistudio
大家可以在generate_data_for_training.py中查看每个参数的help信息来了解每个参数的作用,还不清楚的话,可以留言。现在的默认设置是可以使后续跑通的。
!python /home/aistudio/generate_data_for_training.py
Namespace(feat_root='/home/aistudio/data/data122998/Features_competition_train', orig_val_gt_json_path='/home/aistudio/PaddleVideo/data/bmn/annotations_val_gt_merged.json', train_feat_path='/home/aistudio/data/pre_feat', train_json_path='/home/aistudio/PaddleVideo/data/bmn/annotations_win.json', val_feat_path='/home/aistudio/data/val_feat', val_gt_json_path='/home/aistudio/PaddleVideo/data/bmn/annotations_val_gt.json', val_json_path='/home/aistudio/PaddleVideo/data/bmn/annotations_val_win.json', val_ratio=0.025, video_info_path='/home/aistudio/data/data122998/label_cls14_train.json', win_T=100)
准备划分并筛选得到用于训练验证的视频切片数据...
总共729条视频,其中710条视频划分后用于训练,其余19条视频用于验证!
开始以窗口大小为100,步长为50来划分每一条视频(保存的每个视频切片至少包含一个完整的提案)...
被丢弃的无效数据: {'url': 'bff88e62f7934de7b2685c4f776b80ce.mp4', 'total_frames': 4613, 'actions': []}
/home/aistudio/data/pre_feat中一共有19595条切片数据!
准备划分得到训练完用于验证模型AUC的视频切片数据...
开始以窗口大小为100,步长为50来划分每一条视频(保存的每个视频切片不必包含提案)...
100%|███████████████████████████████████████████| 19/19 [00:05<00:00, 3.51it/s]
/home/aistudio/data/val_feat中一共有3242条切片数据!%cd /home/aistudio/PaddleVideo !python3.7 -m pip install --upgrade pip !python3.7 -m pip install --upgrade -r requirements.txt %cd /home/aistudio/
import sys
sys.path.append("/home/aistudio/")from utils import set_seed_paddle, merging_output_per_video, checking_submission先设置随机数种子,再启动训练命令。注意由于每次启动的机器不同,即使设置了随机数种子,但底层cudnn中卷积算法的不确定性仍然存在,会导致每次的训练结果有波动。 配置文件为PaddleVideo/configs/localization/my_yaml/bmn.yaml。
OPTIMIZER: #OPTIMIZER field
name: 'Adam'
learning_rate:
iter_step: True
name: 'CustomPiecewiseDecay'
boundaries: [4200] values: [0.001, 0.0001] weight_decay:
name: 'L2'
value: 1e-4model_name: BMN epochs: 20 #Mandatory, total epoch log_level: "INFO"#resume_epoch: 2log_interval: 10resume_from: "" #checkpoint path.
# 设置随机数种子set_seed_paddle(1024)
# 训练%cd /home/aistudio/PaddleVideo#!python -B main.py -c configs/localization/my_yaml/bmn.yaml!python -B main.py --validate -c configs/localization/my_yaml/bmn.yaml %cd /home/aistudio/
训练之后得到一组模型权重,通过验证即可筛选出哪些模型权重在验证集上表现较好。如2.3数据处理方案所说,这里存在两种验证方案,但第二种模拟了预测方案,相对更为可靠。
这里使用configs/localization/my_yaml/bmn_val.yaml为配置文件, 主要是这三处相应文件的路径可以按需修改,目前是和generate_data_for_training.py中的配合好的。file_path对应train_json_path,feat_path对应train_feat_path,ground_truth_filename对应val_gt_json_path。
test: format: "BMNDataset"
test_mode: "predict"
file_path: "data/bmn/annotations_win.json"
subset: "validation"test: #Mandatory, indicate the pipeline to deal with the validing data. associate to the 'paddlevideo/loader/pipelines/'
load_feat:
name: "LoadFeat"
feat_path: "/home/aistudio/data/pre_feat"METRIC: name: 'BMNMetric' tscale: 100 dscale: 100 file_path: "data/bmn/annotations_win.json" ground_truth_filename: "data/bmn/annotations_val_gt.json" subset: "validation" output_path: "data/bmn/val/BMN_Test_output" result_path: "data/bmn/val/BMN_Test_results" get_metrics: True
# 验证%cd /home/aistudio/PaddleVideo !python main.py --eval_model -c configs/localization/my_yaml/bmn_val.yaml -w output/BMN -o DATASET.test_batch_size=1%cd /home/aistudio/
运行完会在模型权重保存路径下生成一个eval_metrics_results.txt文件存放所有模型的AUC分数。
这里使用configs/localization/my_yaml/bmn_val_merge.yaml为配置文件, 与第一种不同,第二种是要将未划分原视频相应的切片对应的提案汇总且soft nms后处理后再进行AUC计算(详见2.3),与测试更相符。因此这三处相应文件的路径有所不同,但目前是和generate_data_for_training.py中的配合好的。file_path对应val_json_path,feat_path对应val_feat_path,ground_truth_filename对应orig_val_gt_json_path。
test: format: "BMNDataset"
test_mode: "predict"
file_path: "data/bmn/annotations_val_win.json"
subset: "validation"test: #Mandatory, indicate the pipeline to deal with the validing data. associate to the 'paddlevideo/loader/pipelines/'
load_feat:
name: "LoadFeat"
feat_path: "/home/aistudio/data/val_feat"METRIC: name: 'BMNMetric' tscale: 100 dscale: 100 file_path: "data/bmn/annotations_val_win.json" ground_truth_filename: "data/bmn/annotations_val_gt_merged.json" subset: "validation" output_path: "data/bmn/val_merged/BMN_Test_output" result_path: "data/bmn/val_merged/BMN_Test_results" get_metrics: True to_merge: True
注意,这里使用通过to_merge参数来控制两种验证模式,为True进行第二种,反之为第一种。
# 验证%cd /home/aistudio/PaddleVideo !python main.py --eval_model -c configs/localization/my_yaml/bmn_val_merge.yaml -w output/BMN/ -o DATASET.test_batch_size=1%cd /home/aistudio/
同样,运行完会在模型权重保存路径下生成一个eval_metrics_results.txt文件存放所有模型的AUC分数。可以通过resume_epoch命令在eval_metrics_results.txt中追加后续epoch对应模型权重的验证AUC分数。
model_name: BMNepochs: 9 #Mandatory, total epochlog_level: "INFO"#resume_epoch: 13log_interval: 10
%cd /home/aistudio/data/ %mkdir data123009/Features_competition_test_B !tar -xf data123009/Features_competition_test_B.tar.gz -C /home/aistudio/data/data123009/Features_competition_test_B --strip-components 1 && rm -rf data123009/Features_competition_test_B.tar.gz %cd /home/aistudio/
/home/aistudio/data /home/aistudio
# 划分测试视频!python /home/aistudio/generate_data_for_testing.py
Namespace(feat_root='/home/aistudio/data/data123009/Features_competition_test_B', fps=25, test_feat_path='/home/aistudio/data/test_feat', test_json_path='/home/aistudio/PaddleVideo/data/bmn/annotations_test.json', win_T=100) 准备划分得到测试集视频的切片数据... 开始以窗口大小为100,步长为50来划分每一条视频(保存的每个视频切片不必包含提案)... 100%|███████████████████████████████████████████| 92/92 [00:28<00:00, 3.21it/s] /home/aistudio/data/test_feat中一共有15815条切片数据!
我们对PaddleVideo修改从而可以利用以下命令获得测试集视频切片的提案,详见第四部分开始的介绍。配置见PaddleVideo/configs/localization/my_yaml/bmn_test.yaml,主要是这三处相应文件的路径可以按需修改,目前是和generate_data_for_testing.py中的配合好的。file_path对应test_json_path,feat_path对应test_feat_path,ground_truth_filename可以不写。
test: format: "BMNDataset"
test_mode: "predict"
file_path: "data/bmn/annotations_test.json"
subset: "validation"test: #Mandatory, indicate the pipeline to deal with the validing data. associate to the 'paddlevideo/loader/pipelines/'
load_feat:
name: "LoadFeat"
feat_path: "/home/aistudio/data/test_feat"METRIC: name: 'BMNMetric' tscale: 100 dscale: 100 file_path: "data/bmn/annotations_test.json" ground_truth_filename: "" subset: "validation" output_path: "data/bmn/BMN_Test_output" result_path: "data/bmn/BMN_Test_results" get_metrics: False
注意,设置get_metrics为False即可以避免预测时进行AUC计算。
# 预测 #test A有16102条切片数据,而test B有15815条%cd /home/aistudio/PaddleVideo !python main.py --test -c configs/localization/my_yaml/bmn_test.yaml -w output/BMN_best/BMN_epoch_00008.pdparams -o DATASET.test_batch_size=1%cd /home/aistudio/
见2.3数据处理方案详细介绍
#合并切片视频的提案信息并逐源未切分视频再次进行soft nms来分别筛选得到100个提案用于提交merging_output_per_video(test_root="/home/aistudio/data/data123009/Features_competition_test_B", #未划分的原视频特征存放路径
proposal_filename='PaddleVideo/data/bmn/BMN_Test_results/bmn_results_validation.json', #预测的待拼接回每个原视频的切片提案信息文件路径
merging_output_filename="submission_B.json", #合并后每个视频对应的预测提案信息,用于提交
win_T=100,
fps=25,
snms_alpha=0.4,
snms_t1=0.55,
snms_t2=0.9)100%|██████████| 92/92 [01:41<00:00, 1.10s/it]
#核查输出的submission.json与我们A榜或B榜提交的是否一致checking_submission(json_path2="submission_B.json", json_path2="submission_A_B/submission_B.json")
两份提交文件完全一致!
以上就是基于飞桨实现乒乓球时序动作定位大赛 :B榜第2名方案的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 189
189






















