本实验围绕视频分类展开,旨在让学习者掌握相关知识、TSN模型原理及飞桨构建方法。内容包括用PaddleVideo套件,在UCF101数据集上实现TSN模型,涵盖数据准备(提取帧等)、模型构建、训练配置、训练、保存、评估及推理全流程。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

PaddleVideo:飞桨视频模型开发套件,旨在帮助开发者更好的进行视频领域的学术研究和产业实践。
特性
更多的数据集和模型结构 PaddleVideo 支持更多的数据集和模型结构,包括Kinectics400,ucf101,YoutTube8M等数据集,模型结构涵盖了视频分类模型TSN,TSM,SlowFast,AttentionLSTM和视频定位模型BMN等。
更高指标的模型算法 PaddleVideo 提供更高精度的模型结构解决方案,在基于TSM标准版改进的PP-TSM上,在Kinectics400数据集上达到2D网络SOTA效果,Top1 Acc 76.16% 相较标准版TSM模型参数量持平,且取得更快的模型速度。
更快的训练速度 PaddleVideo 提供更快速度的训练阶段解决方案,包括混合精度训练,分布式训练,针对Slowfast模型的Multigrid训练策略,OP融合策略以及更快的数据预处理模块等。
全流程可部署 PaddleVideo 提供全流程的预测部署方案,支持PaddlePaddle2.0动转静功能,方便产出可快速部署的模型,完成部署阶段最后一公里。
丰富的应用案例 PaddleVideo 提供了基于行为识别和动作检测技术的多个实用案例,包括FootballAction和VideoTag。
awesome-DeepLearning:一站式深度学习在线百科,内容涵盖零基础入门深度学习、产业实践深度学习、特色课程;深度学习百问、产业实践(开发中) 等等。从理论到实践,从科研到产业应用,各类学习材料一应俱全,旨在帮助开发者高效地学习和掌握深度学习知识,快速成为AI跨界人才。

随着互联网上视频的规模日益庞大,人们急切需要研究视频相关算法帮助人们更加容易地找到感兴趣内容的视频。而视频分类算法能够实现自动分析视频所包含的语义信息、理解其内容,对视频进行自动标注、分类和描述,达到与人媲美的准确率。视频分类是继图像分类问题后下一个急需解决的关键任务。
视频分类的主要目标是理解视频中包含的内容,确定视频对应的几个关键主题。视频分类(Video Classification)算法将基于视频的语义内容如人类行为和复杂事件等,将视频片段自动分类至单个或多个类别。视频分类不仅仅是要理解视频中的每一帧图像,更重要的是要识别出能够描述视频的少数几个最佳关键主题。本实验将在视频分类数据集上给大家介绍经典的视频分类模型 TSN(Temporal Segment Networks)。
本实验支持在实训平台或本地环境操作,建议您使用实训平台。
可以通过如下代码导入实验环境。
# coding=utf-8# 导入环境import osimport sysimport randomimport mathimport numpy as npimport scipy.ioimport cv2from PIL import Imageimport os.path as ospimport copyfrom tqdm import tqdmimport timeimport globimport fnmatchfrom multiprocessing import Pool, current_processimport paddlefrom paddle.io import Datasetfrom paddle.nn import Conv2D, MaxPool2D, Linear, Dropout, BatchNorm, AdaptiveAvgPool2D, AvgPool2D, BatchNorm2Dimport paddle.nn.functional as Fimport paddle.nn as nnimport paddle.nn.initializer as initfrom paddle import ParamAttrfrom paddle.regularizer import L2Decayfrom collections.abc import Sequencefrom collections import OrderedDictimport matplotlib.pyplot as plt# 在notebook中使用matplotlib.pyplot绘图时,需要添加该命令进行显示%matplotlib inline
实现方案如 图2 所示,对于一条输入的视频数据,首先使用卷积网络提取特征,获取特征表示;然后使用分类器获取属于每类视频动作的概率值。在训练阶段,通过模型输出的概率值与样本的真实标签构建损失函数,从而进行模型训练;在推理阶段,选出概率最大的类别作为最终的输出。

实验流程主要分为以下7个部分:
UCF101数据集 是一个动作识别数据集,包含现实的动作视频,从 YouTube 上收集,有 101 个动作类别。该数据集是 UCF50 数据集的扩展,该数据集有 50 个动作类别。从 101 个动作类的 13320 个视频中,UCF101 给出了最大的多样性,并且在摄像机运动、物体外观和姿态、物体尺度、视点、杂乱背景、光照条件等方面存在较大的差异,这是迄今为止最具挑战性的数据。
由于大多数可用的动作识别数据集都不现实,而且是由参与者进行的,UCF101 旨在通过学习和探索新的现实行动类别来鼓励进一步研究行动识别。 101 个动作类的视频中,动作类别可以分为5类,如图4中5种颜色的标注:

本小节代码只需要运行一次即可,根据需要注释或者取消注释。
以下程序大概需要运行1分多钟。
# 查看环境# 查看当前挂载的数据集目录,改目录下的变更重启环境后会自动还原! ls /home/aistudio/data# 查看工作区文件,该目录下的变更将会持久保存。请及时清理不必要的文件,避免加载过慢。! ls /home/aistudio/work# 以下代码运行一次即可,再次运行时请将代码注释掉# 工作区创建data文件夹用于存放数据#! mkdir /home/aistudio/work/data# data下ucf101文件夹用于存放ucf101数据集#! mkdir /home/aistudio/work/data/ucf101 # 将数据解压到/home/aistudio/work/data/ucf101目录下面#! unzip -d /home/aistudio/work/data/ucf101 /home/aistudio/data/data73202/UCF-101.zip#! mv /home/aistudio/work/data/ucf101/UCF-101 /home/aistudio/work/data/ucf101/videos# 将标注解压到/home/aistudio/work/data/ucf101目录下面#! unzip -d /home/aistudio/work/data/ucf101 /home/aistudio/data/data73202/UCF101TrainTestSplits-RecognitionTask.zip#! mv /home/aistudio/work/data/ucf101/ucfTrainTestlist/ /home/aistudio/work/data/ucf101/annotations
data73202 data models
提取视频文件的frames
为了加速网络的训练过程,我们首先对视频文件(ucf101视频文件为avi格式)提取帧 (frames)。相对于直接通过视频文件进行网络训练的方式,frames的方式能够加快网络训练的速度。视频文件frames提取完成后,会存储在./rawframes文件夹下。
以下程序运行大概需要26分钟,仅执行一次即可。
out_dir='/home/aistudio/work/data/ucf101/rawframes'src_dir = '/home/aistudio/work/data/ucf101/videos'ext = 'avi'num_worker = 8def dump_frames(vid_item):
full_path, vid_path, vid_id = vid_item
vid_name = vid_path.split('.')[0]
out_full_path = osp.join(out_dir, vid_name) try:
os.mkdir(out_full_path) except OSError: pass
vr = cv2.VideoCapture(full_path)
videolen = int(vr.get(cv2.CAP_PROP_FRAME_COUNT)) for i in range(videolen):
ret, frame = vr.read() if ret == False: continue
img = frame[:, :, ::-1] # covert the BGR img
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) if img is not None: # cv2.imwrite will write BGR into RGB images
cv2.imwrite('{}/img_{:05d}.jpg'.format(out_full_path, i + 1), img) else: print('[Warning] length inconsistent!'
'Early stop with {} out of {} frames'.format(i + 1, videolen)) break
print('{} done with {} frames'.format(vid_name, videolen))
sys.stdout.flush() return True# 多进程的方式提取视频帧def extract_frames():
if not osp.isdir(out_dir): print('Creating folder: {}'.format(out_dir))
os.makedirs(out_dir) if level == 2:
classes = os.listdir(src_dir) for classname in classes:
new_dir = osp.join(out_dir, classname) if not osp.isdir(new_dir): print('Creating folder: {}'.format(new_dir))
os.makedirs(new_dir) print('Reading videos from folder: ', src_dir) print('Extension of videos: ', ext) if level == 2:
fullpath_list = glob.glob(src_dir + '/*/*.' + ext)
done_fullpath_list = glob.glob(out_dir + '/*/*') elif level == 1:
fullpath_list = glob.glob(src_dir + '/*.' + ext)
done_fullpath_list = glob.glob(out_dir + '/*') print('Total number of videos found: ', len(fullpath_list)) if level == 2:
vid_list = list( map(lambda p: osp.join('/'.join(p.split('/')[-2:])), fullpath_list)) elif level == 1:
vid_list = list(map(lambda p: p.split('/')[-1], fullpath_list))
pool = Pool(num_worker)
pool.map(dump_frames, zip(fullpath_list, vid_list, range(len(vid_list))))# extract_frames() #首次运行请取消注释生成frames和videos文件路径list。
level = 2num_split = 3shuffle = Falseout_path = '/home/aistudio/work/data/ucf101/'rgb_prefix = 'img_'def parse_directory(path,
key_func=lambda x: x[-11:],
rgb_prefix='img_',
level=1):
"""
Parse directories holding extracted frames from standard benchmarks
"""
print('parse frames under folder {}'.format(path)) if level == 1:
frame_folders = glob.glob(os.path.join(path, '*')) elif level == 2:
frame_folders = glob.glob(os.path.join(path, '*', '*')) else: raise ValueError('level can be only 1 or 2') def count_files(directory, prefix_list):
lst = os.listdir(directory)
cnt_list = [len(fnmatch.filter(lst, x + '*')) for x in prefix_list] return cnt_list # check RGB
frame_dict = {} for i, f in enumerate(frame_folders):
all_cnt = count_files(f, (rgb_prefix))
k = key_func(f)
x_cnt = all_cnt[1]
y_cnt = all_cnt[2] if x_cnt != y_cnt: raise ValueError('x and y direction have different number '
'of flow images. video: ' + f) if i % 200 == 0: print('{} videos parsed'.format(i))
frame_dict[k] = (f, all_cnt[0], x_cnt) print('frame folder analysis done') return frame_dictdef build_split_list(split, frame_info, shuffle=False):
def build_set_list(set_list):
rgb_list = list() for item in set_list: if item[0] not in frame_info: continue
elif frame_info[item[0]][1] > 0:
rgb_cnt = frame_info[item[0]][1]
rgb_list.append('{} {} {}\n'.format(item[0], rgb_cnt, item[1])) else:
rgb_list.append('{} {}\n'.format(item[0], item[1])) if shuffle:
random.shuffle(rgb_list) return rgb_list
train_rgb_list = build_set_list(split[0])
test_rgb_list = build_set_list(split[1]) return (train_rgb_list, test_rgb_list)def parse_ucf101_splits(level):
class_ind = [x.strip().split() for x in open('/home/aistudio/work/data/ucf101/annotations/classInd.txt')]
class_mapping = {x[1]: int(x[0]) - 1 for x in class_ind} def line2rec(line):
items = line.strip().split(' ')
vid = items[0].split('.')[0]
vid = '/'.join(vid.split('/')[-level:])
label = class_mapping[items[0].split('/')[0]] return vid, label
splits = [] for i in range(1, 4):
train_list = [
line2rec(x) for x in open('/home/aistudio/work/data/ucf101/annotations/trainlist{:02d}.txt'.format(i))
]
test_list = [
line2rec(x) for x in open('/home/aistudio/work/data/ucf101/annotations/testlist{:02d}.txt'.format(i))
]
splits.append((train_list, test_list)) return splitsdef key_func(x):
return '/'.join(x.split('/')[-2:])frame_path = '/home/aistudio/work/data/ucf101/rawframes'def get_frames_file_list():
frame_info = parse_directory(
frame_path,
key_func=key_func,
rgb_prefix=rgb_prefix,
level=level)
split_tp = parse_ucf101_splits(level) assert len(split_tp) == num_split for i, split in enumerate(split_tp):
lists = build_split_list(split_tp[i], frame_info, shuffle=shuffle)
filename = 'ucf101_train_split_{}_{}.txt'.format(i + 1, 'rawframes')
PATH = os.path.abspath(frame_path) with open(os.path.join(out_path, filename), 'w') as f:
f.writelines([os.path.join(PATH, item) for item in lists[0]])
filename = 'ucf101_val_split_{}_{}.txt'.format(i + 1, 'rawframes') with open(os.path.join(out_path, filename), 'w') as f:
f.writelines([os.path.join(PATH, item) for item in lists[1]])#get_frames_file_list() #首次运行取消注释def extract_videos_file_list():
video_list = glob.glob(os.path.join(frame_path, '*', '*'))
frame_info = {
os.path.relpath(x.split('.')[0], frame_path): (x, -1, -1) for x in video_list
}
split_tp = parse_ucf101_splits(level) assert len(split_tp) == num_split for i, split in enumerate(split_tp):
lists = build_split_list(split_tp[i], frame_info, shuffle=shuffle)
filename = 'ucf101_train_split_{}_{}.txt'.format(i + 1, 'videos')
PATH = os.path.abspath(frame_path) with open(os.path.join(out_path, filename), 'w') as f:
f.writelines([os.path.join(PATH, item) for item in lists[0]])
filename = 'ucf101_val_split_{}_{}.txt'.format(i + 1, 'videos') with open(os.path.join(out_path, filename), 'w') as f:
f.writelines([os.path.join(PATH, item) for item in lists[1]])#extract_videos_file_list()#首次运行取消注释UCF101 数据文件组织形式如下所示:
├── ucf101
│ ├── ucf101_{train,val}_split_{1,2,3}_rawframes.txt│ ├── ucf101_{train,val}_split_{1,2,3}_videos.txt│ ├── annotations
│ ├── videos
│ │ ├── ApplyEyeMakeup
│ │ │ ├── v_ApplyEyeMakeup_g01_c01.avi│ │ │ └── ...
│ │ ├── YoYo
│ │ │ ├── v_YoYo_g25_c05.avi│ │ │ └── ...
│ │ └── ...
│ ├── rawframes
│ │ ├── ApplyEyeMakeup
│ │ │ ├── v_ApplyEyeMakeup_g01_c01
│ │ │ │ ├── img_00001.jpg│ │ │ │ ├── img_00002.jpg│ │ │ │ ├── ...
│ │ │ │ ├── flow_x_00001.jpg│ │ │ │ ├── flow_x_00002.jpg│ │ │ │ ├── ...
│ │ │ │ ├── flow_y_00001.jpg│ │ │ │ ├── flow_y_00002.jpg│ │ ├── ...
│ │ ├── YoYo
│ │ │ ├── v_YoYo_g01_c01
│ │ │ ├── ...
│ │ │ ├── v_YoYo_g25_c05其中,ucf101_{train,val}_split_{1,2,3}_rawframes.txt 中存放的是帧信息,部分内容展示如下:
/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g08_c01 120 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g08_c02 117 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g08_c03 146 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g08_c04 224 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g08_c05 276 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c01 176 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c02 258 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c03 210 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c04 191 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c05 194 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c06 188 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c07 261 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g10_c01 153 0...
第一个元素表示视频帧目录,第二个元素表示目录下帧的个数,第三个元素表示该视频的类别。
ucf101_{train,val}_split_{1,2,3}_videos.txt 中存放的视频信息,部分内容展示如下:
/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c04 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c05 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c06 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g09_c07 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g10_c01 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g10_c02 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g10_c03 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g10_c04 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g10_c05 0/home/aistudio/work/data/ucf101/rawframes/ApplyEyeMakeup/v_ApplyEyeMakeup_g11_c01 0
第一个元素表示视频文件路径,第二个元素表示该视频文件中的帧数。
注:annotation 目录下存放的数据的类别信息和数据的划分信息;videos 目录下存放的数据集的原始视频文件;frames 目录下存放的是从原始视频文件中抽取出的帧信息。
设置数据处理的格式,这里将数据处理的格式设置为 frame。具体代码如下。
class FrameDecoder(object):
"""just parse results
"""
def __init__(self):
pass
def __call__(self, results):
# 加入数据的 format 格式信息,表示当前处理的数据类型为帧 frame
results['format'] = 'frame'
return results帧采样
对一段视频进行分段采样,大致思路:
1.对视频进行分段;
2.从每段视频随机选取一个起始位置;
3.从选取的起始位置采集连续的 k 帧;
帧采样的代码实现如下:
class Sampler(object):
"""
Sample frames id.
NOTE: Use PIL to read image here, has diff with CV2
Args:
num_seg(int): number of segments.
seg_len(int): number of sampled frames in each segment.
mode(str): 'train', 'valid'
Returns:
frames_idx: the index of sampled #frames.
"""
def __init__(self, num_seg, seg_len, valid_mode=False):
self.num_seg = num_seg # 视频分割段的数量
self.seg_len = seg_len # 每段中抽取帧数
self.valid_mode = valid_mode # train or valid
def _get(self, frames_idx, results):
data_format = results['format'] # 取出处理的数据类型
# 如果处理的数据类型为帧
if data_format == "frame": # 取出帧所在的目录
frame_dir = results['frame_dir']
imgs = [] # 存放读取到的帧图片
for idx in frames_idx: # 读取图片
img = Image.open(os.path.join(frame_dir, results['suffix'].format(idx))).convert('RGB') # 将读取到的图片存放到列表中
imgs.append(img) else: raise NotImplementedError
results['imgs'] = imgs # 添加 imgs 信息
return results def __call__(self, results):
"""
Args:
frames_len: length of frames.
return:
sampling id.
"""
frames_len = results['frames_len'] # 视频中总的帧数
average_dur = int(int(frames_len) / self.num_seg) # 每段中视频的数量
frames_idx = [] # 将采样到的索引存放到 frames_idx
for i in range(self.num_seg):
idx = 0 # 当前段采样的起始位置
if not self.valid_mode: # 如果训练
if average_dur >= self.seg_len: # 如果每段中视频数大于每段中要采样的帧数
idx = random.randint(0, average_dur - self.seg_len) # 计算在当前段内采样的起点
idx += i * average_dur # i * average_dur 表示之前 i-1 段用过的帧
elif average_dur >= 1: # 如果每段中视频数大于 1
idx += i * average_dur # 直接以当前段的起始位置作为采样的起始位置
else:
idx = i # 直接以当前段的索引作为起始位置
else: # 如果测试
if average_dur >= self.seg_len:
idx = (average_dur - 1) // 2 # 当前段的中间帧数
idx += i * average_dur elif average_dur >= 1:
idx += i * average_dur else:
idx = i # 从采样位置采连续的 self.seg_len 帧
for jj in range(idx, idx + self.seg_len): if results['format'] == 'frame':
frames_idx.append(jj + 1) # 将采样到的帧索引加入到 frames_idx 中
else: raise NotImplementedError return self._get(frames_idx, results) # 依据采样到的帧索引读取对应的图片class Scale(object):
"""
Scale images.
Args:
short_size(float | int): Short size of an image will be scaled to the short_size.
"""
# 将图片中短边的长度 resize 到 short_size,另一个变做相应尺度的缩放
def __init__(self, short_size):
self.short_size = short_size # 短边长度
def __call__(self, results):
"""
Performs resize operations.
Args:
imgs (Sequence[PIL.Image]): List where each item is a PIL.Image.
For example, [PIL.Image0, PIL.Image1, PIL.Image2, ...]
return:
resized_imgs: List where each item is a PIL.Image after scaling.
"""
imgs = results['imgs'] # 取出图片集
resized_imgs = [] # 存放处理过的图片
for i in range(len(imgs)):
img = imgs[i]
w, h = img.size # 当前图片的宽和高
if (w <= h and w == self.short_size) or (h <= w and h == self.short_size):
resized_imgs.append(img) continue
if w < h:
ow = self.short_size
oh = int(self.short_size * 4.0 / 3.0)
resized_imgs.append(img.resize((ow, oh), Image.BILINEAR)) else:
oh = self.short_size
ow = int(self.short_size * 4.0 / 3.0)
resized_imgs.append(img.resize((ow, oh), Image.BILINEAR))
results['imgs'] = resized_imgs # 将处理过的图片复制给键值 imgs
return results多尺度裁剪
从多个尺度中随机选择一个裁剪尺度,并计算具体裁剪起始位置以及宽和高,之后从原图中裁剪出随机的固定区域。具体的实现代码如下。
class MultiScaleCrop(object):
def __init__(
self,
target_size, # NOTE: named target size now, but still pass short size in it!
scales=None,
max_distort=1,
fix_crop=True,
more_fix_crop=True):
# resize 后的宽高
self.target_size = target_size # resize 的尺度
self.scales = scales if scales else [1, .875, .75, .66]
self.max_distort = max_distort
self.fix_crop = fix_crop
self.more_fix_crop = more_fix_crop
def __call__(self, results):
"""
Performs MultiScaleCrop operations.
Args:
imgs: List where wach item is a PIL.Image.
XXX:
results:
"""
imgs = results['imgs'] # 取出图片集
input_size = [self.target_size, self.target_size]
im_size = imgs[0].size # 取出第一张的图片的尺寸
# get random crop offset
def _sample_crop_size(im_size):
# 图片的宽、图片的高
image_w, image_h = im_size[0], im_size[1] # 图片宽和高中的最小值
base_size = min(image_w, image_h) # 在宽和高中最小值的基础上计算多尺度的裁剪尺寸
crop_sizes = [int(base_size * x) for x in self.scales]
crop_h = [
input_size[1] if abs(x - input_size[1]) < 3 else x for x in crop_sizes
]
crop_w = [
input_size[0] if abs(x - input_size[0]) < 3 else x for x in crop_sizes
]
pairs = [] for i, h in enumerate(crop_h): for j, w in enumerate(crop_w): # |i-j| < self.max_distort
if abs(i - j) <= self.max_distort:
pairs.append((w, h)) # 随机选取一个裁剪 pair
crop_pair = random.choice(pairs) # 如果对裁剪 pair 进行修正
# (w_offset,h_offset) 裁剪起始点
if not self.fix_crop:
w_offset = random.randint(0, image_w - crop_pair[0])
h_offset = random.randint(0, image_h - crop_pair[1]) else:
w_step = (image_w - crop_pair[0]) / 4
h_step = (image_h - crop_pair[1]) / 4
ret = list()
ret.append((0, 0)) # upper left
if w_step != 0:
ret.append((4 * w_step, 0)) # upper right
if h_step != 0:
ret.append((0, 4 * h_step)) # lower left
if h_step != 0 and w_step != 0:
ret.append((4 * w_step, 4 * h_step)) # lower right
if h_step != 0 or w_step != 0:
ret.append((2 * w_step, 2 * h_step)) # center
if self.more_fix_crop:
ret.append((0, 2 * h_step)) # center left
ret.append((4 * w_step, 2 * h_step)) # center right
ret.append((2 * w_step, 4 * h_step)) # lower center
ret.append((2 * w_step, 0 * h_step)) # upper center
ret.append((1 * w_step, 1 * h_step)) # upper left quarter
ret.append((3 * w_step, 1 * h_step)) # upper right quarter
ret.append((1 * w_step, 3 * h_step)) # lower left quarter
ret.append((3 * w_step, 3 * h_step)) # lower righ quarter
w_offset, h_offset = random.choice(ret) # 返回裁剪的宽和高以及裁剪的起始点
return crop_pair[0], crop_pair[1], w_offset, h_offset # 获取裁剪的宽和高以及裁剪的起始点
crop_w, crop_h, offset_w, offset_h = _sample_crop_size(im_size) # 对 imgs 中的每张图片做裁剪
crop_img_group = [
img.crop((offset_w, offset_h, offset_w + crop_w, offset_h + crop_h)) for img in imgs
] # 将裁剪的后图片 resize 到 (input_size[0], input_size[1])
ret_img_group = [
img.resize((input_size[0], input_size[1]), Image.BILINEAR) for img in crop_img_group
] # 将处理过的图片复制给键值 imgs
results['imgs'] = ret_img_group return results随机裁剪
从图片中随机选择一个起始点,之后从起始点开始裁剪一个固定的区域。具体实现代码如下。
class RandomCrop(object):
"""
Random crop images.
Args:
target_size(int): Random crop a square with the target_size from an image.
"""
def __init__(self, target_size):
self.target_size = target_size
def __call__(self, results):
"""
Performs random crop operations.
Args:
imgs: List where each item is a PIL.Image.
For example, [PIL.Image0, PIL.Image1, PIL.Image2, ...]
return:
crop_imgs: List where each item is a PIL.Image after random crop.
"""
imgs = results['imgs']
w, h = imgs[0].size # 获取图片的宽和高
th, tw = self.target_size, self.target_size # resize 后的宽和高
assert (w >= self.target_size) and (h >= self.target_size), \ "image width({}) and height({}) should be larger than crop size".format(w, h, self.target_size)
crop_images = [] # 存放裁剪后的图片
# 计算随机裁剪的起始点,一段视频中对所帧裁剪的其实位置相同
x1 = random.randint(0, w - tw)
y1 = random.randint(0, h - th) # 访问每一张图片
for img in imgs: if w == tw and h == th: # 如果原始的宽高与裁剪后的宽高相同
crop_images.append(img) else:
crop_images.append(img.crop((x1, y1, x1 + tw, y1 + th)))
results['imgs'] = crop_images # 将处理过的图片复制给键值 imgs
return results随机翻转
对图片进行随机的翻转。具体实现代码如下。
class RandomFlip(object):
"""
Random Flip images.
Args:
p(float): Random flip images with the probability p.
"""
def __init__(self, p=0.5):
self.p = p def __call__(self, results):
"""
Performs random flip operations.
Args:
imgs: List where each item is a PIL.Image.
For example, [PIL.Image0, PIL.Image1, PIL.Image2, ...]
return:
flip_imgs: List where each item is a PIL.Image after random flip.
"""
imgs = results['imgs']
v = random.random() if v < self.p: # 如果 v 小于 0.5
results['imgs'] = [img.transpose(Image.FLIP_LEFT_RIGHT) for img in imgs] else:
results['imgs'] = imgs return results中心裁剪
中心裁剪与随机裁剪类似,具体的差异在于选取裁剪起始点的方法不同。具体实现代码如下。
class CenterCrop(object):
"""
Center crop images.
Args:
target_size(int): Center crop a square with the target_size from an image.
"""
def __init__(self, target_size):
self.target_size = target_size
def __call__(self, results):
"""
Performs Center crop operations.
Args:
imgs: List where each item is a PIL.Image.
For example, [PIL.Image0, PIL.Image1, PIL.Image2, ...]
return:
ccrop_imgs: List where each item is a PIL.Image after Center crop.
"""
imgs = results['imgs']
ccrop_imgs = [] for img in imgs:
w, h = img.size # 图片的宽和高
th, tw = self.target_size, self.target_size assert (w >= self.target_size) and (h >= self.target_size), \ "image width({}) and height({}) should be larger than crop size".format(w, h, self.target_size)
x1 = int(round((w - tw) / 2.))
y1 = int(round((h - th) / 2.))
ccrop_imgs.append(img.crop((x1, y1, x1 + tw, y1 + th)))
results['imgs'] = ccrop_imgs return results数据格式转换
将数据转换为 numpy 类型。具体的实现代码如下。
class Image2Array(object):
"""
transfer PIL.Image to Numpy array and transpose dimensions from 'dhwc' to 'dchw'.
Args:
transpose: whether to transpose or not, default False. True for tsn.
"""
def __init__(self, transpose=True):
self.transpose = transpose def __call__(self, results):
"""
Performs Image to NumpyArray operations.
Args:
imgs: List where each item is a PIL.Image.
For example, [PIL.Image0, PIL.Image1, PIL.Image2, ...]
return:
np_imgs: Numpy array.
"""
imgs = results['imgs'] # 将 list 转为 numpy
np_imgs = (np.stack(imgs)).astype('float32') if self.transpose: # 对维度进行交换
np_imgs = np_imgs.transpose(0, 3, 1, 2) # nchw
results['imgs'] = np_imgs # 将处理过的图片复制给键值 imgs
return results归一化
通过使用均值和方差,对数据集做归一化处理。具体的代码如下。
class Normalization(object):
"""
Normalization.
Args:
mean(Sequence[float]): mean values of different channels.
std(Sequence[float]): std values of different channels.
tensor_shape(list): size of mean, default [3,1,1]. For slowfast, [1,1,1,3]
"""
def __init__(self, mean, std, tensor_shape=[3, 1, 1]):
if not isinstance(mean, Sequence): raise TypeError(f'Mean must be list, tuple or np.ndarray, but got {type(mean)}') if not isinstance(std, Sequence): raise TypeError(f'Std must be list, tuple or np.ndarray, but got {type(std)}')
self.mean = np.array(mean).reshape(tensor_shape).astype(np.float32)
self.std = np.array(std).reshape(tensor_shape).astype(np.float32) def __call__(self, results):
"""
Performs normalization operations.
Args:
imgs: Numpy array.
return:
np_imgs: Numpy array after normalization.
"""
imgs = results['imgs']
norm_imgs = imgs / 255. # 除以 255
norm_imgs -= self.mean # 减去均值
norm_imgs /= self.std # 除以方差
results['imgs'] = norm_imgs # 将处理过的图片复制给键值 imgs
return results为了方便处理,对上述所有的数据预处理模块进行封装。
class Compose(object):
"""
Composes several pipelines(include decode func, sample func, and transforms) together.
Note: To deal with ```list``` type cfg temporaray, like:
transform:
- Crop: # A list
attribute: 10
- Resize: # A list
attribute: 20
every key of list will pass as the key name to build a module.
XXX: will be improved in the future.
Args:
pipelines (list): List of transforms to compose.
Returns:
A compose object which is callable, __call__ for this Compose
object will call each given :attr:`transforms` sequencely.
"""
def __init__(self, train_mode=False):
# assert isinstance(pipelines, Sequence)
self.pipelines = list()
self.pipelines.append(FrameDecoder()) if train_mode:
self.pipelines.append(Sampler(num_seg=8, seg_len=1, valid_mode=False)) else:
self.pipelines.append(Sampler(num_seg=8, seg_len=1, valid_mode=True))
self.pipelines.append(Scale(short_size=256)) if train_mode:
self.pipelines.append(MultiScaleCrop(target_size=256))
self.pipelines.append(RandomCrop(target_size=224))
self.pipelines.append(RandomFlip()) else:
self.pipelines.append(CenterCrop(target_size=224))
self.pipelines.append(Image2Array())
self.pipelines.append(Normalization(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])) def __call__(self, data):
# 将传入的 data 依次经过 pipelines 中对象处理
for p in self.pipelines: try:
data = p(data) except Exception as e:
stack_info = traceback.format_exc() print("fail to perform transform [{}] with error: "
"{} and stack:\n{}".format(p, e, str(stack_info))) raise e return data接下来我们通过继承 paddle 的 Dataset API 来构建一个数据读取器,方便每次从数据中获取一个样本和对应的标签。
class FrameDataset(paddle.io.Dataset):
def __init__(self,
file_path,
pipeline,
num_retries=5,
data_prefix=None,
test_mode=False,
suffix='img_{:05}.jpg'):
super(FrameDataset, self).__init__()
self.num_retries = num_retries # 重试的次数
self.suffix = suffix
self.file_path = file_path
self.data_prefix = osp.realpath(data_prefix) if \
data_prefix is not None and osp.isdir(data_prefix) else data_prefix
self.test_mode = test_mode
self.pipeline = pipeline
self.info = self.load_file() def load_file(self):
"""Load index file to get video information."""
# 从文件中加载数据信息
info = [] with open(self.file_path, 'r') as fin: for line in fin:
line_split = line.strip().split() # 数据信息(帧目录-目录下存放帧的数量-标签)
frame_dir, frames_len, labels = line_split if self.data_prefix is not None:
frame_dir = osp.join(self.data_prefix, frame_dir) # 视频数据信息<视频目录,后缀,帧数,标签>
info.append(dict(frame_dir=frame_dir,
suffix=self.suffix,
frames_len=frames_len,
labels=int(labels))) return info
def prepare_train(self, idx):
"""Prepare the frames for training/valid given index. """
# Try to catch Exception caused by reading missing frames files
# 重试的次数
for ir in range(self.num_retries): # 从数据信息中取出索引对应的视频信息,self.info 中每个元素对应的是一段视频
results = copy.deepcopy(self.info[idx]) try: # 将 <视频目录,后缀,视频帧数,视频标签> 交给 pipeline 处理
results = self.pipeline(results) except Exception as e: print(e) if ir < self.num_retries - 1: print("Error when loading {}, have {} trys, will try again".format(results['frame_dir'], ir))
idx = random.randint(0, len(self.info) - 1) continue
# 返回图片集和其对应的 labels
return results['imgs'], np.array([results['labels']])
def prepare_test(self, idx):
"""Prepare the frames for test given index. """
# Try to catch Exception caused by reading missing frames files
for ir in range(self.num_retries):
results = copy.deepcopy(self.info[idx]) try:
results = self.pipeline(results) except Exception as e: print(e) if ir < self.num_retries - 1: print("Error when loading {}, have {} trys, will try again".format(results['frame_dir'], ir))
idx = random.randint(0, len(self.info) - 1) continue
return results['imgs'], np.array([results['labels']]) def __len__(self):
"""get the size of the dataset."""
return len(self.info) def __getitem__(self, idx):
""" Get the sample for either training or testing given index"""
if self.test_mode: return self.prepare_test(idx) else: return self.prepare_train(idx)数据预处理耗时较长,推荐使用 paddle.io.DataLoader API 中的 num_workers 参数,设置进程数量,实现多进程读取数据。
class paddle.io.DataLoader(dataset, batch_size=1, shuffle=False, num_workers=0)
关键参数含义如下:
train_file_path = '/home/aistudio/work/data/ucf101/ucf101_train_split_1_rawframes.txt'pipeline = Compose()
data = FrameDataset(file_path=train_file_path, pipeline=pipeline, suffix='img_{:05}.jpg')
data_loader = paddle.io.DataLoader(
data,num_workers=0,
batch_size=16,
shuffle=True,
drop_last=True,
places=paddle.set_device('gpu'),
return_list=True)for item in data_loader():
x, y = item print('图片数据的 shape:', x.shape) print('标签数据的 shape:', y.shape) break图片数据的 shape: [16, 8, 3, 224, 224] 标签数据的 shape: [16, 1]
TSN(Temporal Segment Networks)是ECCV 2016的一篇用于动作识别的文章,网络结构如图2所示。TSN可以看做是对双流(two stream)模型的改进。 在此基础上,文章主要解决了两个问题:
1、长时间视频的行为判断问题(有些视频的动作时间较长)。
2、解决数据少的问题,数据量少会使得一些深层的网络难以应用到视频数据中,因为过拟合会比较严重。
双流结构网络难以学习到视频的长时间信息,因为其针对的主要是单帧图像或者短时间内的一堆帧图像数据,但这对于时间跨度较长的视频动作检测而言是不够的。因此采用更加密集的图像帧采样方式来获取视频的长时间信息是比较常用的方法,但是这样做会增加不少时间成本,同时作者发现视频的连续帧之间存在冗余,因此想到用稀疏采样代替密集采样,也就是说在对视频做抽帧的时候采取较为稀疏的抽帧方式,这样可以去除一些冗余信息,同时降低了计算量。
对于数据少问题,可通过常规的数据增强方式,比如随机裁剪,水平翻转等;另外还有作者提到的交叉预训练,dropout等方式来减少过拟合。
论文的主要贡献点如下:
1)提出Temporal Segment Network(TSN)网络模型:
a.TSN采样具备稀疏性和全局性的特征,能够建模间隔更长帧之间时间依赖关系,确保获取视频级信息; b.TSN包含提取空间信息和提取时间信息两路模型,并基于后期融合方式来融合两路模型的结果。
2)提出了一系列最佳实践方案,如数据增强、正则化、交叉模态预训练等,并取得了非常好的效果。
TSN采用多模态数据增强方式来解决样本量较少的问题,具体如图3所示。

TNS(Temporal Segment Networks)模型结构如下:
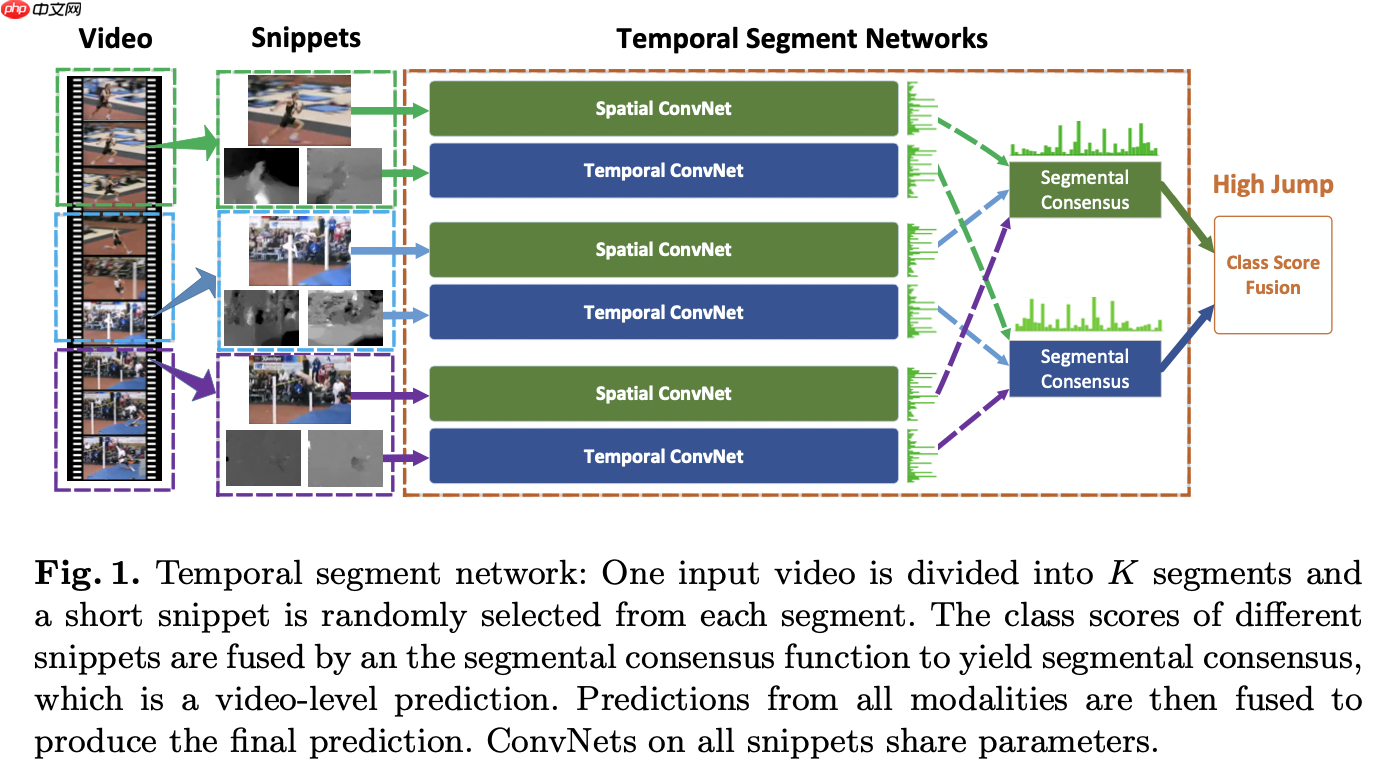
给定一个video V,首先将其切分成K(原文中采用3)个等长的segments{S1,S2,...,SK},然后从每个segment (SK)中随机地选取一个snippet (TK),每个snippet包含一帧图像和两个光流特征图(如图2所示)。最后将不同snippet(小片段)的分类结果进行融合得到整个视频的分类结果。
TSN网络公式: TSN(T1,T2,...,TK)=H(g(F(T1;W),F(T2;W),...,F(TK;W)))
上面式子中的W就是网络的参数,因此F(TK;W)就是网络的输出,也就是该snippet属于每个类的得分。可以看图2中convnet图后面的绿色条形图,代表的就是socre在类别上的分布。g是一个融合函数,在文中采用的是均值函数,就是对所有snippet的属于同一类别的得分做个均值。
主干网络
def weight_init_(layer,
func,
weight_name=None,
bias_name=None,
bias_value=0.0,
**kwargs):
"""
In-place params init function.
Usage:
.. code-block:: python
import paddle
import numpy as np
data = np.ones([3, 4], dtype='float32')
linear = paddle.nn.Linear(4, 4)
input = paddle.to_tensor(data)
print(linear.weight)
linear(input)
weight_init_(linear, 'Normal', 'fc_w0', 'fc_b0', std=0.01, mean=0.1)
print(linear.weight)
"""
if hasattr(layer, 'weight') and layer.weight is not None: getattr(init, func)(**kwargs)(layer.weight) if weight_name is not None: # override weight name
layer.weight.name = weight_name if hasattr(layer, 'bias') and layer.bias is not None:
init.Constant(bias_value)(layer.bias) if bias_name is not None: # override bias name
layer.bias.name = bias_namedef load_ckpt(model, weight_path):
"""
"""
# model.set_state_dict(state_dict)
if not osp.isfile(weight_path): raise IOError(f'{weight_path} is not a checkpoint file') # state_dicts = load(weight_path)
state_dicts = paddle.load(weight_path)
tmp = {}
total_len = len(model.state_dict()) with tqdm(total=total_len,
position=1,
bar_format='{desc}',
desc="Loading weights") as desc: for item in tqdm(model.state_dict(), total=total_len, position=0):
name = item
desc.set_description('Loading %s' % name)
tmp[name] = state_dicts[name]
time.sleep(0.01)
ret_str = "loading {:<20d} weights completed.".format( len(model.state_dict()))
desc.set_description(ret_str)
model.set_state_dict(tmp)class ConvBNLayer(nn.Layer):
"""Conv2D and BatchNorm2D layer.
Args:
in_channels (int): Number of channels for the input.
out_channels (int): Number of channels for the output.
kernel_size (int): Kernel size.
stride (int): Stride in the Conv2D layer. Default: 1.
groups (int): Groups in the Conv2D, Default: 1.
act (str): Indicate activation after BatchNorm2D layer.
name (str): the name of an instance of ConvBNLayer.
Note: weight and bias initialization include initialize values and name the restored parameters, values initialization are explicit declared in the ```init_weights``` method.
"""
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride=1,
groups=1,
act=None,
name=None):
super(ConvBNLayer, self).__init__()
self._conv = Conv2D(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=(kernel_size - 1) // 2,
groups=groups,
weight_attr=ParamAttr(name=name + "_weights"),
bias_attr=False) if name == "conv1":
bn_name = "bn_" + name else:
bn_name = "bn" + name[3:]
self._act = act
self._batch_norm = BatchNorm2D(out_channels,
weight_attr=ParamAttr(name=bn_name + "_scale"),
bias_attr=ParamAttr(bn_name + "_offset"))
def forward(self, inputs):
y = self._conv(inputs)
y = self._batch_norm(y) if self._act:
y = getattr(paddle.nn.functional, self._act)(y) return yclass BottleneckBlock(nn.Layer):
def __init__(self,
in_channels,
out_channels,
stride,
shortcut=True,
name=None):
super(BottleneckBlock, self).__init__()
self.conv0 = ConvBNLayer(in_channels=in_channels,
out_channels=out_channels,
kernel_size=1,
act="relu",
name=name + "_branch2a")
self.conv1 = ConvBNLayer(in_channels=out_channels,
out_channels=out_channels,
kernel_size=3,
stride=stride,
act="relu",
name=name + "_branch2b")
self.conv2 = ConvBNLayer(in_channels=out_channels,
out_channels=out_channels * 4,
kernel_size=1,
act=None,
name=name + "_branch2c") if not shortcut:
self.short = ConvBNLayer(in_channels=in_channels,
out_channels=out_channels * 4,
kernel_size=1,
stride=stride,
name=name + "_branch2")
self.shortcut = shortcut def forward(self, inputs):
y = self.conv0(inputs)
conv1 = self.conv1(y)
conv2 = self.conv2(conv1) if self.shortcut:
short = inputs else:
short = self.short(inputs)
y = paddle.add(x=short, y=conv2) return F.relu(y)class BasicBlock(nn.Layer):
def __init__(self,
in_channels,
out_channels,
stride,
shortcut=True,
name=None):
super(BasicBlock, self).__init__()
self.stride = stride
self.conv0 = ConvBNLayer(in_channels=in_channels,
out_channels=out_channels,
filter_size=3,
stride=stride,
act="relu",
name=name + "_branch2a")
self.conv1 = ConvBNLayer(in_channels=out_channels,
out_channels=out_channels,
filter_size=3,
act=None,
name=name + "_branch2b")
if not shortcut:
self.short = ConvBNLayer(in_channels=in_channels,
out_channels=out_channels,
filter_size=1,
stride=stride,
name=name + "_branch2")
self.shortcut = shortcut
def forward(self, inputs):
y = self.conv0(inputs)
conv1 = self.conv1(y) if self.shortcut:
short = inputs else:
short = self.short(inputs)
y = paddle.add(short, conv1)
y = F.relu(y) return yclass ResNet(nn.Layer):
"""ResNet backbone.
Args:
depth (int): Depth of resnet model.
pretrained (str): pretrained model. Default: None.
"""
def __init__(self, depth, pretrained=None,name='conv1'):
super(ResNet, self).__init__()
self.pretrained = pretrained
self.layers = depth
self.name = name
supported_layers = [18, 34, 50, 101, 152] assert self.layers in supported_layers, \ "supported layers are {} but input layer is {}".format(
supported_layers, self.layers) if self.layers == 18:
depth = [2, 2, 2, 2] elif self.layers == 34 or self.layers == 50:
depth = [3, 4, 6, 3] elif self.layers == 101:
depth = [3, 4, 23, 3] elif self.layers == 152:
depth = [3, 8, 36, 3]
in_channels = [64, 256, 512, 1024]
out_channels = [64, 128, 256, 512]
self.conv = ConvBNLayer(in_channels=3,
out_channels=64,
kernel_size=7,
stride=2,
act="relu",
name=self.name)
self.pool2D_max = MaxPool2D(kernel_size=3, stride=2, padding=1)
self.block_list = [] if self.layers >= 50: for block in range(len(depth)):
shortcut = False
for i in range(depth[block]): if self.layers in [101, 152] and block == 2: if i == 0:
conv_name = "res" + str(block + 2) + "a"
else:
conv_name = "res" + str(block + 2) + "b" + str(i) else:
conv_name = "res" + str(block + 2) + chr(97 + i)
bottleneck_block = self.add_sublayer(
conv_name,
BottleneckBlock(
in_channels=in_channels[block] if i == 0 else out_channels[block] * 4,
out_channels=out_channels[block],
stride=2 if i == 0 and block != 0 else 1,
shortcut=shortcut,
name=conv_name))
self.block_list.append(bottleneck_block)
shortcut = True
else: for block in range(len(depth)):
shortcut = False
for i in range(depth[block]):
conv_name = "res" + str(block + 2) + chr(97 + i)
basic_block = self.add_sublayer(
conv_name,
BasicBlock(in_channels=in_channels[block] if i == 0 else out_channels[block],
out_channels=out_channels[block],
stride=2 if i == 0 and block != 0 else 1,
shortcut=shortcut,
name=conv_name))
self.block_list.append(basic_block)
shortcut = True
def init_weights(self):
"""Initiate the parameters.
Note:
1. when indicate pretrained loading path, will load it to initiate backbone.
2. when not indicating pretrained loading path, will follow specific initialization initiate backbone. Always, Conv2D layer will be initiated by KaimingNormal function, and BatchNorm2d will be initiated by Constant function.
Please refer to https://www.paddlepaddle.org.cn/documentation/docs/en/develop/api/paddle/nn/initializer/kaiming/KaimingNormal_en.html
"""
#XXX: check bias!!! check pretrained!!!
if isinstance(self.pretrained, str) and self.pretrained.strip() != "":
load_ckpt(self, self.pretrained) elif self.pretrained is None or self.pretrained.strip() == "": for layer in self.sublayers(): if isinstance(layer, nn.Conv2D): #XXX: no bias
weight_init_(layer, 'KaimingNormal') elif isinstance(layer, nn.BatchNorm2D):
weight_init_(layer, 'Constant', value=1)
def forward(self, inputs):
"""Define how the backbone is going to run.
"""
#NOTE: Already merge axis 0(batches) and axis 1(channels) before extracting feature phase,
# please refer to paddlevideo/modeling/framework/recognizers/recognizer2d.py#L27
#y = paddle.reshape(
# inputs, [-1, inputs.shape[2], inputs.shape[3], inputs.shape[4]])
y = self.conv(inputs)
y = self.pool2D_max(y) for block in self.block_list:
y = block(y) return yclass TSNHead(nn.Layer):
"""TSN Head.
Args:
num_classes (int): The number of classes to be classified.
in_channels (int): The number of channles in input feature.
loss_cfg (dict): Config for building config. Default: dict(name='CrossEntropyLoss').
drop_ratio(float): drop ratio. Default: 0.4.
std(float): Std(Scale) value in normal initilizar. Default: 0.01.
kwargs (dict, optional): Any keyword argument to initialize.
"""
def __init__(self,
num_classes,
in_channels,
drop_ratio=0.4,
ls_eps=0.,
std=0.01,
**kwargs):
super().__init__()
self.num_classes = num_classes
self.in_channels = in_channels # 分类层输入的通道数
self.drop_ratio = drop_ratio # dropout 比例
self.stdv = 1.0 / math.sqrt(self.in_channels * 1.0)
self.std = std #NOTE: global pool performance
self.avgpool2d = AdaptiveAvgPool2D((1, 1)) if self.drop_ratio != 0:
self.dropout = Dropout(p=self.drop_ratio) else:
self.dropout = None
self.fc = Linear(self.in_channels, self.num_classes)
self.loss_func = paddle.nn.CrossEntropyLoss() # 损失函数
self.ls_eps = ls_eps # 标签平滑系数
def init_weights(self):
"""Initiate the FC layer parameters"""
weight_init_(self.fc, 'Normal', 'fc_0.w_0', 'fc_0.b_0',
mean=0.,
std=self.std)
def forward(self, x, seg_num):
"""Define how the head is going to run.
Args:
x (paddle.Tensor): The input data.
num_segs (int): Number of segments.
Returns:
score: (paddle.Tensor) The classification scores for input samples.
"""
#XXX: check dropout location!
# [N * num_segs, in_channels, 7, 7]
x = self.avgpool2d(x) # [N * num_segs, in_channels, 1, 1]
x = paddle.reshape(x, [-1, seg_num, x.shape[1]]) # [N, seg_num, in_channels]
x = paddle.mean(x, axis=1) # [N, in_channels]
if self.dropout is not None:
x = self.dropout(x) # [N, in_channels]
score = self.fc(x) # [N, num_class]
#x = F.softmax(x) #NOTE remove
return score
def loss(self, scores, labels, reduce_sum=False, **kwargs):
"""Calculate the loss accroding to the model output ```scores```,
and the target ```labels```.
Args:
scores (paddle.Tensor): The output of the model.
labels (paddle.Tensor): The target output of the model.
Returns:
losses (dict): A dict containing field 'loss'(mandatory) and 'top1_acc', 'top5_acc'(optional).
"""
if len(labels) == 1:
labels = labels[0] else: raise NotImplemented
# 如果标签平滑系数不等于 0
if self.ls_eps != 0.:
labels = F.one_hot(labels, self.num_classes)
labels = F.label_smooth(labels, epsilon=self.ls_eps) # reshape [bs, 1, num_classes] to [bs, num_classes]
# NOTE: maybe squeeze is helpful for understanding.
labels = paddle.reshape(labels, shape=[-1, self.num_classes]) # labels.stop_gradient = True #XXX(shipping): check necessary
losses = dict() # NOTE(shipping): F.crossentropy include logsoftmax and nllloss !
# NOTE(shipping): check the performance of F.crossentropy
loss = self.loss_func(scores, labels, **kwargs) # 计算损失
avg_loss = paddle.mean(loss)
top1 = paddle.metric.accuracy(input=scores, label=labels, k=1)
top5 = paddle.metric.accuracy(input=scores, label=labels, k=5) # _, world_size = get_dist_info()
#
# # NOTE(shipping): deal with multi cards validate
# if world_size > 1 and reduce_sum:
# top1 = paddle.distributed.all_reduce(top1, op=paddle.distributed.ReduceOp.SUM) / world_size
# top5 = paddle.distributed.all_reduce(top5, op=paddle.distributed.ReduceOp.SUM) / world_size
losses['top1'] = top1
losses['top5'] = top5
losses['loss'] = avg_loss return lossesclass Recognizer2D(paddle.nn.Layer):
def __init__(self, backbone=None, head=None):
super().__init__()
self.backbone = backbone
self.backbone.init_weights()
self.head = head
self.head.init_weights()
def extract_feature(self, imgs):
"""Extract features through a backbone.
Args:
imgs (paddle.Tensor) : The input images.
Returns:
feature (paddle.Tensor) : The extracted features.
"""
feature = self.backbone(imgs) return feature
def forward(self, imgs, **kwargs):
"""Define how the model is going to run, from input to output.
"""
batches = imgs.shape[0] # 批次大小
num_segs = imgs.shape[1] # 分割的帧数
# 对 imgs 进行 reshape,[N,T,C,H,W]->[N*T,C,H,W]
imgs = paddle.reshape(imgs, [-1] + list(imgs.shape[2:]))
feature = self.extract_feature(imgs)
cls_score = self.head(feature, num_segs) return cls_score """2D recognizer model framework."""
def train_step(self, data_batch, reduce_sum=False):
"""Define how the model is going to train, from input to output.
"""
# NOTE: As the num_segs is an attribute of dataset phase, and didn't pass to build_head phase,
# should obtain it from imgs(paddle.Tensor) now, then call self.head method.
# labels = labels.squeeze()
# XXX: unsqueeze label to [label] ?
imgs = data_batch[0] # 从批次中取出训练数据
labels = data_batch[1:] # 从批次中取出数据对应的标签
cls_score = self(imgs) # 计算预测分数
loss_metrics = self.head.loss(cls_score, labels, reduce_sum) # 计算损失
return loss_metrics
def val_step(self, data_batch, reduce_sum=True):
return self.train_step(data_batch, reduce_sum=reduce_sum) def test_step(self, data_batch, reduce_sum=False):
"""Define how the model is going to test, from input to output."""
# NOTE: (shipping) when testing, the net won't call head.loss,
# we deal with the test processing in /paddlevideo/metrics
imgs = data_batch[0] # 从批次中取出训练数据
cls_score = self(imgs) # 计算预测分数
return cls_score# datasuffix = 'img_{:05}.jpg' # 图片后缀名batch_size = 16 # 批次大小num_workers = 0 # 使用 work drop_last = True return_list = True## train datatrain_file_path = '/home/aistudio/work/data/ucf101/ucf101_train_split_1_rawframes.txt' # 训练数据train_shuffle = True # 是否进行混淆操作## valid datavalid_file_path = '/home/aistudio/work/data/ucf101/ucf101_val_split_1_rawframes.txt' # 验证数据valid_shuffle = False # 是否进行混淆操作# modelframework = 'Recognizer2D'model_name = 'TSN' # 模型名depth = 50 # ResNet 网络深度num_classes = 101 # 类别数in_channels = 2048 # 最后一层 channel 数drop_ratio = 0.5 # dropout 比例pretrained = '/home/aistudio/work/models/ResNet50_pretrain.pdparams' # 预训练模型参数文件# lrboundaries = [40, 60] # 学习率更新的轮values = [0.01, 0.001, 0.0001] # 学习率修改对映的值# optimizermomentum = 0.9 # 动量更新系数weight_decay = 1e-4 # 权重衰减系数# trainlog_interval = 20 # 每隔多少步打印一次信息save_interval = 10 # 每隔多少轮保存一次模型参数epochs = 80 # 总共训练的伦数log_level = 'INFO'总共训练 80 个epoch,每个 epoch 都需要在训练集与测试集上运行,并打印出训练集上的 loss 和模型在训练和验证集上的准确率。
Color = { 'RED': '\033[31m', 'HEADER': '\033[35m', # deep purple
'PURPLE': '\033[95m', # purple
'OKBLUE': '\033[94m', 'OKGREEN': '\033[92m', 'WARNING': '\033[93m', 'FAIL': '\033[91m', 'ENDC': '\033[0m'}def coloring(message, color="OKGREEN"):
assert color in Color.keys() if os.environ.get('COLORING', True): return Color[color] + str(message) + Color["ENDC"] else: return messagedef build_record(framework_type):
record_list = [
("loss", AverageMeter('loss', '7.5f')),
("lr", AverageMeter('lr', 'f', need_avg=False)),
("batch_time", AverageMeter('elapse', '.3f')),
("reader_time", AverageMeter('reader', '.3f')),
] if 'Recognizer' in framework_type:
record_list.append(("top1", AverageMeter("top1", '.5f')))
record_list.append(("top5", AverageMeter("top5", '.5f')))
record_list = OrderedDict(record_list) return record_listdef log_batch(metric_list, batch_id, epoch_id, total_epoch, mode, ips):
metric_str = ' '.join([str(m.value) for m in metric_list.values()])
epoch_str = "epoch:[{:>3d}/{:<3d}]".format(epoch_id, total_epoch)
step_str = "{:s} step:{:<4d}".format(mode, batch_id) print("{:s} {:s} {:s}s {}".format(
coloring(epoch_str, "HEADER") if batch_id == 0 else epoch_str,
coloring(step_str, "PURPLE"), coloring(metric_str, 'OKGREEN'), ips))def log_epoch(metric_list, epoch, mode, ips):
metric_avg = ' '.join([str(m.mean) for m in metric_list.values()] +
[metric_list['batch_time'].total])
end_epoch_str = "END epoch:{:<3d}".format(epoch) print("{:s} {:s} {:s}s {}".format(coloring(end_epoch_str, "RED"),
coloring(mode, "PURPLE"),
coloring(metric_avg, "OKGREEN"),
ips))class AverageMeter(object):
"""
Computes and stores the average and current value
"""
def __init__(self, name='', fmt='f', need_avg=True):
self.name = name
self.fmt = fmt
self.need_avg = need_avg
self.reset() def reset(self):
""" reset """
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
""" update """
if isinstance(val, paddle.Tensor):
val = val.numpy()[0]
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count @property
def total(self):
return '{self.name}_sum: {self.sum:{self.fmt}}'.format(self=self) @property
def total_minute(self):
return '{self.name}_sum: {s:{self.fmt}} min'.format(s=self.sum / 60,
self=self) @property
def mean(self):
return '{self.name}_avg: {self.avg:{self.fmt}}'.format(
self=self) if self.need_avg else '' @property
def value(self):
return '{self.name}: {self.val:{self.fmt}}'.format(self=self) def train_model(validate=True):
# 模型输出目录
output_dir = f"/home/aistudio/work/output/{model_name}"
if not os.path.exists(output_dir): try:
os.makedirs(output_dir) except: pass
# 1. Construct model (创建模型)
tsn = ResNet(depth=depth, pretrained=pretrained)
head = TSNHead(num_classes=num_classes, in_channels=in_channels)
model = Recognizer2D(backbone=tsn, head=head) # 2. Construct dataset and dataloader
train_pipeline = Compose(train_mode=True)
train_dataset = FrameDataset(file_path=train_file_path, pipeline=train_pipeline, suffix=suffix)
train_sampler = paddle.io.DistributedBatchSampler(
train_dataset,
batch_size=batch_size,
shuffle=train_shuffle,
drop_last=drop_last
)
train_loader = paddle.io.DataLoader(
train_dataset,
batch_sampler=train_sampler,
places=paddle.set_device('gpu'),
num_workers=num_workers,
return_list=return_list
) if validate:
valid_pipeline = Compose(train_mode=False)
valid_dataset = FrameDataset(file_path=valid_file_path, pipeline=valid_pipeline, suffix=suffix)
valid_sampler = paddle.io.DistributedBatchSampler(
valid_dataset,
batch_size=batch_size,
shuffle=valid_shuffle,
drop_last=drop_last
)
valid_loader = paddle.io.DataLoader(
valid_dataset,
batch_sampler=valid_sampler,
places=paddle.set_device('gpu'),
num_workers=num_workers,
return_list=return_list
)
# 3. Construct solver.
# 学习率的衰减策略
lr = paddle.optimizer.lr.PiecewiseDecay(boundaries=boundaries, values=values) # 使用的优化器
optimizer = paddle.optimizer.Momentum(
learning_rate=lr,
momentum=momentum,
parameters=model.parameters(),
weight_decay=paddle.regularizer.L2Decay(weight_decay)
) # 4. Train Model
best = 0.
for epoch in range(0, epochs):
model.train() # 将模型设置为训练模式
record_list = build_record(framework)
tic = time.time() # 访问每一个 batch
for i, data in enumerate(train_loader):
record_list['reader_time'].update(time.time() - tic) # 4.1 forward
outputs = model.train_step(data) # 执行前向推断
# 4.2 backward
# 反向传播
avg_loss = outputs['loss']
avg_loss.backward() # 4.3 minimize
# 梯度更新
optimizer.step()
optimizer.clear_grad()
# log record
record_list['lr'].update(optimizer._global_learning_rate(), batch_size) for name, value in outputs.items():
record_list[name].update(value, batch_size)
record_list['batch_time'].update(time.time() - tic)
tic = time.time() if i % log_interval == 0:
ips = "ips: {:.5f} instance/sec.".format(batch_size / record_list["batch_time"].val)
log_batch(record_list, i, epoch + 1, epochs, "train", ips)
# learning rate epoch step
lr.step()
ips = "ips: {:.5f} instance/sec.".format(
batch_size * record_list["batch_time"].count / record_list["batch_time"].sum
)
log_epoch(record_list, epoch + 1, "train", ips) def evaluate(best):
model.eval()
record_list = build_record(framework)
record_list.pop('lr')
tic = time.time() for i, data in enumerate(valid_loader):
outputs = model.val_step(data) # log_record
for name, value in outputs.items():
record_list[name].update(value, batch_size)
record_list['batch_time'].update(time.time() - tic)
tic = time.time() if i % log_interval == 0:
ips = "ips: {:.5f} instance/sec.".format(batch_size / record_list["batch_time"].val)
log_batch(record_list, i, epoch + 1,epochs, "val", ips)
ips = "ips: {:.5f} instance/sec.".format(
batch_size * record_list["batch_time"].count / record_list["batch_time"].sum
)
log_epoch(record_list, epoch + 1, "val", ips)
best_flag = False
for top_flag in ['hit_at_one', 'top1']: if record_list.get(top_flag) and record_list[top_flag].avg > best:
best = record_list[top_flag].avg
best_flag = True
return best, best_flag
# 5. Validation
if validate or epoch == epochs - 1: with paddle.fluid.dygraph.no_grad():
best, save_best_flag = evaluate(best) # save best
if save_best_flag:
paddle.save(optimizer.state_dict(), osp.join(output_dir, model_name + "_best.pdopt"))
paddle.save(model.state_dict(), osp.join(output_dir, model_name + "_best.pdparams")) if model_name == "AttentionLstm": print(f"Already save the best model (hit_at_one){best}") else: print(f"Already save the best model (top1 acc){int(best * 10000) / 10000}") # 6. Save model and optimizer
if epoch % save_interval == 0 or epoch == epochs - 1:
paddle.save(optimizer.state_dict(), osp.join(output_dir, model_name + f"_epoch_{epoch + 1:05d}.pdopt"))
paddle.save(model.state_dict(), osp.join(output_dir, model_name + f"_epoch_{epoch + 1:05d}.pdparams")) print(f'training {model_name} finished')# 在执行代码过程中,如果出现 ‘ValueError: parameter name [conv1_weights] have be been used’ 问题,# 可以点击上方的第三个按钮 ‘重启并运行全部’ 来解决train_model(True) # 训练模型时取消注释为了能够有一个比较好的评估效果,这里我们选用训练好的模型,模型存放在 /home/aistudio/output/TSN 目录下。具体评估代码如下。
class CenterCropMetric(object):
def __init__(self, data_size, batch_size, log_interval=20):
"""prepare for metrics
"""
super().__init__()
self.data_size = data_size
self.batch_size = batch_size
self.log_interval = log_interval
self.top1 = []
self.top5 = [] def update(self, batch_id, data, outputs):
"""update metrics during each iter
"""
labels = data[1]
top1 = paddle.metric.accuracy(input=outputs, label=labels, k=1)
top5 = paddle.metric.accuracy(input=outputs, label=labels, k=5)
self.top1.append(top1.numpy())
self.top5.append(top5.numpy()) # preds ensemble
if batch_id % self.log_interval == 0: print("[TEST] Processing batch {}/{} ...".format(batch_id, self.data_size // self.batch_size)) def accumulate(self):
"""accumulate metrics when finished all iters.
"""
print('[TEST] finished, avg_acc1= {}, avg_acc5= {} '.format(
np.mean(np.array(self.top1)), np.mean(np.array(self.top5)))
)
@paddle.no_grad()def test_model(weights):
# 1. Construct dataset and dataloader.
test_pipeline = Compose(train_mode=False)
test_dataset = FrameDataset(file_path=valid_file_path, pipeline=test_pipeline, suffix=suffix)
test_sampler = paddle.io.DistributedBatchSampler(
test_dataset,
batch_size=batch_size,
shuffle=valid_shuffle,
drop_last=drop_last
)
test_loader = paddle.io.DataLoader(
test_dataset,
batch_sampler=test_sampler,
places=paddle.set_device('gpu'),
num_workers=num_workers,
return_list=return_list
) # 1. Construct model.
# 创建模型
tsn_test = ResNet(depth=depth, pretrained=None)#,name='conv1_test'
head = TSNHead(num_classes=num_classes, in_channels=in_channels)
model = Recognizer2D(backbone=tsn_test, head=head) # 将模型设置为评估模式
model.eval() # 加载权重
state_dicts = paddle.load(weights)
model.set_state_dict(state_dicts) # add params to metrics
data_size = len(test_dataset)
metric = CenterCropMetric(data_size=data_size, batch_size=batch_size) for batch_id, data in enumerate(test_loader): # 预测
outputs = model.test_step(data)
metric.update(batch_id, data, outputs)
metric.accumulate()
model_file = '/home/aistudio/output/TSN/TSN_best.pdparams'# 在执行代码过程中,如果出现 ‘ValueError: parameter name [conv1_weights] have be been used’ 问题,# 可以点击上方的第三个按钮 ‘重启并运行全部’ 来解决# test_model(model_file) # 模型评估时取消注释这部分将随机抽取 UCF101 中的若干条数据集,演示模型预测的结果。
index_class = [x.strip().split() for x in open('/home/aistudio/work/data/ucf101/annotations/classInd.txt')]@paddle.no_grad()def inference():
model_file = '/home/aistudio/output/TSN/TSN_best.pdparams'
# 1. Construct dataset and dataloader.
test_pipeline = Compose(train_mode=False)
test_dataset = FrameDataset(file_path=valid_file_path, pipeline=test_pipeline, suffix=suffix)
test_sampler = paddle.io.DistributedBatchSampler(
test_dataset,
batch_size=1,
shuffle=True,
drop_last=drop_last
)
test_loader = paddle.io.DataLoader(
test_dataset,
batch_sampler=test_sampler,
places=paddle.set_device('gpu'),
num_workers=num_workers,
return_list=return_list
) # 1. Construct model.
# 创建模型
tsn = ResNet(depth=depth, pretrained=None)
head = TSNHead(num_classes=num_classes, in_channels=in_channels)
model = Recognizer2D(backbone=tsn, head=head) # 将模型设置为评估模式
model.eval() # 加载权重
state_dicts = paddle.load(model_file)
model.set_state_dict(state_dicts) for batch_id, data in enumerate(test_loader):
_, labels = data # 预测
outputs = model.test_step(data) # 经过 softmax 输出置信度分数
scores = F.softmax(outputs) # 从预测结果中取出置信度分数最高的
class_id = paddle.argmax(scores, axis=-1)
pred = class_id.numpy()[0]
label = labels.numpy()[0][0]
print('真实类别:{}, 模型预测类别:{}'.format(index_class[pred][1], index_class[label][1])) if batch_id > 5: break# 启动推理# 在执行代码过程中,如果出现 ‘ValueError: parameter name [conv1_weights] have be been used’ 问题,# 可以点击上方的第三个按钮 ‘重启并运行全部’ 来解决# inference() # 模型推理时取消注释以上就是【实践】TSN视频分类的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 534
534























