本项目针对血细胞图像分类任务,使用ResNet18和MobileNetV1模型,基于含12515张图像的数据集(分4类)展开研究。通过数据加载、预处理(计算均值方差等)、定义数据集与数据加载器,设置相同超参数训练。结果显示,ResNet18准确率0.878,MobileNetV1为0.786,验证了自动化分类在医学检测中的潜力。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

基于血液的疾病的诊断通常涉及识别和表征患者的血液样本,通过计算机视觉的方法利用人工智能技术来检测和分类血细胞亚型的自动化方法具有重要的医学应用,通过自动化分类检测这一手段,我们可以提高血细胞分类精度并降低检测成本,有利于更加精确的分析血液样本的各项指标,从而为病人提供更加精准的检测报告。我们可以将模型部署在相关硬件上来实现落地应用。
总共包括两个文件夹:dataset和dataset2 dataset文件夹下包括JPEGImages共411张图片,Annotations包含的411张图像对应的标注文件,包括类别,图像大小,每个锚框位置大小,labels.csv文件内部是411张图片内包含的目标的label(一个或多个)
dataset2文件夹下包括TEST、TEST_SIMPLE、TRAIN三个文件夹,每个文件夹内都有四个子文件夹,文件夹名即为对应的label。 TEST_SIMPLE中包括一些样本图片,71张 TEST包括2487张图片,做测试集 TRAIN包括9957张图片,做训练集
# 解压血细胞图像数据集!unzip -oq /home/aistudio/data/data106627/cell.zip -d work/
# 查看数据集文件夹树形结构! tree /home/aistudio/work -d
/home/aistudio/work
├── dataset2-master
│ └── dataset2-master
│ └── images
│ ├── TEST
│ │ ├── EOSINOPHIL
│ │ ├── LYMPHOCYTE
│ │ ├── MONOCYTE
│ │ └── NEUTROPHIL
│ ├── TEST_SIMPLE
│ │ ├── EOSINOPHIL
│ │ ├── LYMPHOCYTE
│ │ ├── MONOCYTE
│ │ └── NEUTROPHIL
│ └── TRAIN
│ ├── EOSINOPHIL
│ ├── LYMPHOCYTE
│ ├── MONOCYTE
│ └── NEUTROPHIL
└── dataset-master
└── dataset-master
├── Annotations
└── JPEGImages
22 directories# 血细胞图像数据集抽样可视化import cv2import matplotlib.pyplot as pltimport osimport glob
%matplotlib inline# 读取图像#获取dataset2-master目录下的所有子目录名称,并分类保存路径test_img_list = glob.glob("/home/aistudio/work/dataset2-master/dataset2-master/images/TEST/*/*.jpeg")
test_simple_img_list = glob.glob("/home/aistudio/work/dataset2-master/dataset2-master/images/TEST_SIMPLE/*/*.jpeg")
train_img_list = glob.glob("/home/aistudio/work/dataset2-master/dataset2-master/images/TRAIN/*/*.jpeg")print(len(test_img_list), len(test_simple_img_list), len(train_img_list))#获取dataset-master目录下的所有子目录名称,保存进一个列表之中(暂时不做处理,未来将会将其中图片用于目标检测任务)img_path_list = os.listdir("/home/aistudio/work/dataset-master/dataset-master/JPEGImages")
img_list = []for img_path in img_path_list:
img_list.append("/home/aistudio/work/dataset-master/dataset-master/JPEGImages/"+img_path)# 可视化部分图像for i in range(6):
plt.subplot(2,3,i+1)
img_bgr = cv2.imread(img_list[i])
img_gbr = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
plt.imshow(img_gbr)2487 71 9957
<Figure size 432x288 with 6 Axes>
# 计算图像数据整体的均值和方差import tqdmimport globimport numpy as npdef get_mean_std(image_path_list):
print('Total images size:', len(image_path_list)) # 结果向量的初始化
max_val, min_val = np.zeros(3), np.ones(3) * 255
mean, std = np.zeros(3), np.zeros(3) for image_path in tqdm.tqdm(image_path_list):
image = cv2.imread(image_path) for c in range(3): # 计算每个通道的均值和方差
mean[c] += image[:, :, c].mean()
std[c] += image[:, :, c].std()
max_val[c] = max(max_val[c], image[:, :, c].max())
min_val[c] = min(min_val[c], image[:, :, c].min()) # 图像的平均均值和方差
mean /= len(image_path_list)
std /= len(image_path_list)
mean /= max_val - min_val
std /= max_val - min_val # print(max_val - min_val)
return mean, std
image_path_list = []# image_path_list.extend(glob.glob('/home/aistudio/work/dataset-master/dataset-master/JPEGImages/*.jpg'))image_path_list.extend(glob.glob('/home/aistudio/work/dataset2-master/dataset2-master/images/*/*/*.jpeg'))
mean, std = get_mean_std(image_path_list)print('mean:', mean)print('std:', std)1%| | 82/12515 [00:00<00:30, 404.73it/s]
Total images size: 12515
1%| | 122/12515 [00:00<00:30, 401.44it/s]100%|██████████| 12515/12515 [00:30<00:00, 408.74it/s]
mean: [0.66109358 0.64167306 0.67932446] std: [0.25564928 0.25832876 0.25864613]
<br/>
# 减均值去方差,提高色彩对比度,便于神经网络提取特征import cv2import paddleimport numpy as npimport paddle.vision.transforms as Timport matplotlib.pyplot as pltimport warnings
warnings.filterwarnings('ignore')def preprocess(img):
transform = T.Compose([
T.RandomRotation(degrees=45),
T.RandomCrop(size=(240, 300)),
T.RandomHorizontalFlip(),
T.Resize(size=(240, 240)),
T.ToTensor(),
T.Normalize(mean=[0.66109358, 0.64167306, 0.67932446], std=[0.25564928, 0.25832876, 0.25864613])
])
img = transform(img).astype('float32') return img
img_bgr = cv2.imread('work/dataset2-master/dataset2-master/images/TRAIN/EOSINOPHIL/_0_6149.jpeg')
img = preprocess(img_bgr)print(img.shape, img_bgr.shape)
plt.imshow(img.T)W0322 14:55:38.966475 101 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1 W0322 14:55:38.971231 101 device_context.cc:465] device: 0, cuDNN Version: 7.6. Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
[3, 240, 240] (240, 320, 3)
<matplotlib.image.AxesImage at 0x7fec7c931410>
<Figure size 432x288 with 1 Axes>
# 定义数据集类class MyImageDataset(paddle.io.Dataset):
def __init__(self, phase = 'train'):
super(MyImageDataset, self).__init__() assert phase in ['train', 'test']
self.samples = [] if (phase == 'train'):
self.samples.extend(glob.glob('/home/aistudio/work/dataset2-master/dataset2-master/images/TRAIN/*/*.jpeg')) else:
self.samples.extend(glob.glob('/home/aistudio/work/dataset2-master/dataset2-master/images/TEST/*/*.jpeg'))
self.labels = {'EOSINOPHIL': 0, 'LYMPHOCYTE': 1, 'MONOCYTE': 2, 'NEUTROPHIL': 3} def __getitem__(self, index):
img_path = self.samples[index]
img_bgr = cv2.imread(img_path)
image = preprocess(img_bgr)
label = self.labels[img_path.split('/')[-2]]
label = paddle.to_tensor([label], dtype='int64') return image, label def __len__(self):
return len(self.samples)
train_dataset = MyImageDataset('train')
test_dataset = MyImageDataset('test')print(len(train_dataset), len(test_dataset))print(train_dataset[0][0].shape, test_dataset[0][0].shape)9957 2487 [3, 240, 240] [3, 240, 240]
# 定义超参数lr = 0.0005BATCH_SIZE = 32EPOCH = 10
# 定义数据读取器train_loader = paddle.io.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = paddle.io.DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle= True)for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = data[1] print(batch_id) print(x_data.shape) print(y_data.shape) break0 [32, 3, 240, 240] [32, 1]
模型简介:
论文链接:https://openaccess.thecvf.com/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf

ResNet(Residual Neural Network)由微软研究院的Kaiming He等四名华人提出,通过使用ResNet Unit成功训练出了152层的神经网络,并在ILSVRC2015比赛中取得冠军,在top5上的错误率为3.57%,同时参数量比VGGNet低,效果非常突出。ResNet的结构可以极快的加速神经网络的训练,模型的准确率也有比较大的提升。同时ResNet的推广性非常好,甚至可以直接用到InceptionNet网络中。ResNet的主要思想是在网络中增加了直连通道,即Highway Network的思想。此前的网络结构是性能输入做一个非线性变换,而Highway Network则允许保留之前网络层的一定比例的输出。ResNet的思想和Highway Network的思想也非常类似,允许原始输入信息直接传到后面的层中,如下图所示。
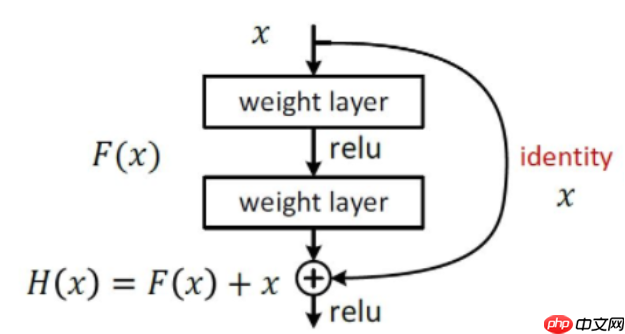
残差学习的结构如图有点类似与电路中的“短路”,所以是一种短路连接(shortcut connection)。增加一个identity mapping(恒等映射),将原始所需要学的函数H(x)转换成F(x)+x,F(x)的优化会比H(x)简单的多,相当于帮助深层网络学习浅层网络的特征,并在基础上深入探索。Residual block通过shortcut connection实现,通过shortcut将这个block的输入和输出进行一个element-wise的加叠,这个简单的加法并不会给网络增加额外的参数和计算量,同时却可以大大增加模型的训练速度、提高训练效果,并且当模型的层数加深时,这个简单的结构能够很好的解决退化问题。
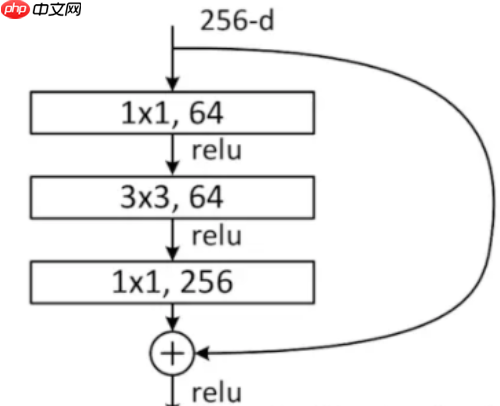
除此之外,论文中还引入bottleneck,通过减小大卷积层的通道数量来极大减小计算量,使用1x1卷积实现,如下图所示。
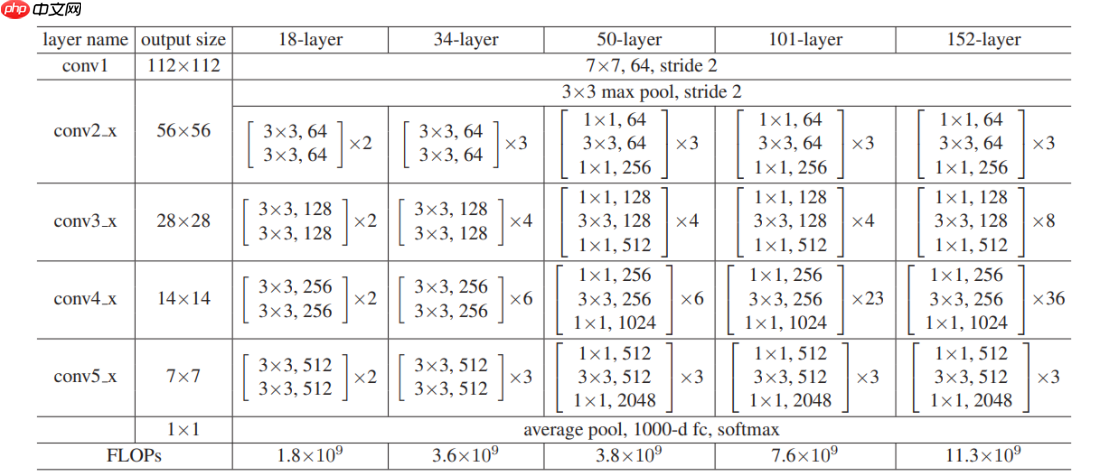
最后,附上论文中最经典、最直观的模型结构参数表,建议全表背诵。
在使用经典网络的时候,可以选择站在巨人的肩膀上,直接调用paddle.vision.models.resnet18(),然后改变最后一层的神经元个数,也可以自己尝试动手搭建,体会经典网络的精妙之处。
想要了解如何动手搭建Resnet18网络的小伙伴可以参考我的另一个项目——从零开始实现经典网络之——ResNet

本文档主要讲述的是基于VC与Matlab的混合编程实现图像的三维显示;介绍了VC++与Matlab混合编程的一般实现方法,并实现对二维影像图的三维效果显示。 MATLAB既是一种直观、高效的计算机语言,同时又是一个科学计算平台。它为数据分析和数据可视化、算法和应用程序开发提供了最核心的数学和高级图形工具。希望本文档会给有需要的朋友带来帮助;感兴趣的朋友可以过来看看
 9
9

这里直接使用了paddle提供的resnet18接口,需要注意的是要将最后一层线性层的输出改为项目需要的大小,由于本项目是进行四分类任务,因此使用Sequential容器将最后一层神经元数量修改为4
初始学习率设置为0.0005,配合batchsize为32,并且使用Adam优化器,模型的收敛效果较好
#图像格式预处理(data_fromat:'NCHW')# 定义网络import paddle.nn as nn
resnet = paddle.vision.models.resnet18()
resnet = nn.Sequential(*list(resnet.children())[:-1],
nn.Flatten(),
nn.Linear(512,4))
paddle.summary(resnet,(64, 3, 240, 240))#定义优化器和损失函数opt = paddle.optimizer.Adam(
learning_rate=lr,
parameters=resnet.parameters(),
beta1=0.9,
beta2=0.999)
loss_func = paddle.nn.CrossEntropyLoss()-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
Conv2D-177 [[64, 3, 240, 240]] [64, 64, 120, 120] 9,408
BatchNorm2D-177 [[64, 64, 120, 120]] [64, 64, 120, 120] 256
ReLU-10 [[64, 64, 120, 120]] [64, 64, 120, 120] 0
MaxPool2D-2 [[64, 64, 120, 120]] [64, 64, 60, 60] 0
Conv2D-178 [[64, 64, 60, 60]] [64, 64, 60, 60] 36,864
BatchNorm2D-178 [[64, 64, 60, 60]] [64, 64, 60, 60] 256
ReLU-11 [[64, 64, 60, 60]] [64, 64, 60, 60] 0
Conv2D-179 [[64, 64, 60, 60]] [64, 64, 60, 60] 36,864
BatchNorm2D-179 [[64, 64, 60, 60]] [64, 64, 60, 60] 256
BasicBlock-9 [[64, 64, 60, 60]] [64, 64, 60, 60] 0
Conv2D-180 [[64, 64, 60, 60]] [64, 64, 60, 60] 36,864
BatchNorm2D-180 [[64, 64, 60, 60]] [64, 64, 60, 60] 256
ReLU-12 [[64, 64, 60, 60]] [64, 64, 60, 60] 0
Conv2D-181 [[64, 64, 60, 60]] [64, 64, 60, 60] 36,864
BatchNorm2D-181 [[64, 64, 60, 60]] [64, 64, 60, 60] 256
BasicBlock-10 [[64, 64, 60, 60]] [64, 64, 60, 60] 0
Conv2D-183 [[64, 64, 60, 60]] [64, 128, 30, 30] 73,728
BatchNorm2D-183 [[64, 128, 30, 30]] [64, 128, 30, 30] 512
ReLU-13 [[64, 128, 30, 30]] [64, 128, 30, 30] 0
Conv2D-184 [[64, 128, 30, 30]] [64, 128, 30, 30] 147,456
BatchNorm2D-184 [[64, 128, 30, 30]] [64, 128, 30, 30] 512
Conv2D-182 [[64, 64, 60, 60]] [64, 128, 30, 30] 8,192
BatchNorm2D-182 [[64, 128, 30, 30]] [64, 128, 30, 30] 512
BasicBlock-11 [[64, 64, 60, 60]] [64, 128, 30, 30] 0
Conv2D-185 [[64, 128, 30, 30]] [64, 128, 30, 30] 147,456
BatchNorm2D-185 [[64, 128, 30, 30]] [64, 128, 30, 30] 512
ReLU-14 [[64, 128, 30, 30]] [64, 128, 30, 30] 0
Conv2D-186 [[64, 128, 30, 30]] [64, 128, 30, 30] 147,456
BatchNorm2D-186 [[64, 128, 30, 30]] [64, 128, 30, 30] 512
BasicBlock-12 [[64, 128, 30, 30]] [64, 128, 30, 30] 0
Conv2D-188 [[64, 128, 30, 30]] [64, 256, 15, 15] 294,912
BatchNorm2D-188 [[64, 256, 15, 15]] [64, 256, 15, 15] 1,024
ReLU-15 [[64, 256, 15, 15]] [64, 256, 15, 15] 0
Conv2D-189 [[64, 256, 15, 15]] [64, 256, 15, 15] 589,824
BatchNorm2D-189 [[64, 256, 15, 15]] [64, 256, 15, 15] 1,024
Conv2D-187 [[64, 128, 30, 30]] [64, 256, 15, 15] 32,768
BatchNorm2D-187 [[64, 256, 15, 15]] [64, 256, 15, 15] 1,024
BasicBlock-13 [[64, 128, 30, 30]] [64, 256, 15, 15] 0
Conv2D-190 [[64, 256, 15, 15]] [64, 256, 15, 15] 589,824
BatchNorm2D-190 [[64, 256, 15, 15]] [64, 256, 15, 15] 1,024
ReLU-16 [[64, 256, 15, 15]] [64, 256, 15, 15] 0
Conv2D-191 [[64, 256, 15, 15]] [64, 256, 15, 15] 589,824
BatchNorm2D-191 [[64, 256, 15, 15]] [64, 256, 15, 15] 1,024
BasicBlock-14 [[64, 256, 15, 15]] [64, 256, 15, 15] 0
Conv2D-193 [[64, 256, 15, 15]] [64, 512, 8, 8] 1,179,648
BatchNorm2D-193 [[64, 512, 8, 8]] [64, 512, 8, 8] 2,048
ReLU-17 [[64, 512, 8, 8]] [64, 512, 8, 8] 0
Conv2D-194 [[64, 512, 8, 8]] [64, 512, 8, 8] 2,359,296
BatchNorm2D-194 [[64, 512, 8, 8]] [64, 512, 8, 8] 2,048
Conv2D-192 [[64, 256, 15, 15]] [64, 512, 8, 8] 131,072
BatchNorm2D-192 [[64, 512, 8, 8]] [64, 512, 8, 8] 2,048
BasicBlock-15 [[64, 256, 15, 15]] [64, 512, 8, 8] 0
Conv2D-195 [[64, 512, 8, 8]] [64, 512, 8, 8] 2,359,296
BatchNorm2D-195 [[64, 512, 8, 8]] [64, 512, 8, 8] 2,048
ReLU-18 [[64, 512, 8, 8]] [64, 512, 8, 8] 0
Conv2D-196 [[64, 512, 8, 8]] [64, 512, 8, 8] 2,359,296
BatchNorm2D-196 [[64, 512, 8, 8]] [64, 512, 8, 8] 2,048
BasicBlock-16 [[64, 512, 8, 8]] [64, 512, 8, 8] 0
AdaptiveAvgPool2D-5 [[64, 512, 8, 8]] [64, 512, 1, 1] 0
Flatten-4 [[64, 512, 1, 1]] [64, 512] 0
Linear-11 [[64, 512]] [64, 4] 2,052
===============================================================================
Total params: 11,188,164
Trainable params: 11,168,964
Non-trainable params: 19,200
-------------------------------------------------------------------------------
Input size (MB): 42.19
Forward/backward pass size (MB): 4218.25
Params size (MB): 42.68
Estimated Total Size (MB): 4303.12
-------------------------------------------------------------------------------print(paddle.device.get_cudnn_version())print(paddle.device.get_device())
paddle.device.set_device('gpu:0')7605 gpu:0
CUDAPlace(0)
# 开始训练from tqdm import tqdm
resnet.train()for epoch in range(EPOCH): for batch_id, data in tqdm(enumerate(train_loader())):
imgs = data[0]
label = data[1]
infer_prob = resnet(imgs)
loss = loss_func(infer_prob, label)
acc = paddle.metric.accuracy(infer_prob, label)
loss.backward()
opt.step()
opt.clear_gradients() if (batch_id + 1) % 20 == 0: print('第{}个epoch:batch_id is: {},loss is: {}, acc is: {}'.format(epoch,batch_id + 1, loss.numpy(),acc.numpy()))
paddle.save(resnet.state_dict(), 'param')模型简介:
论文链接: https://arxiv.org/pdf/1704.04861.pdf
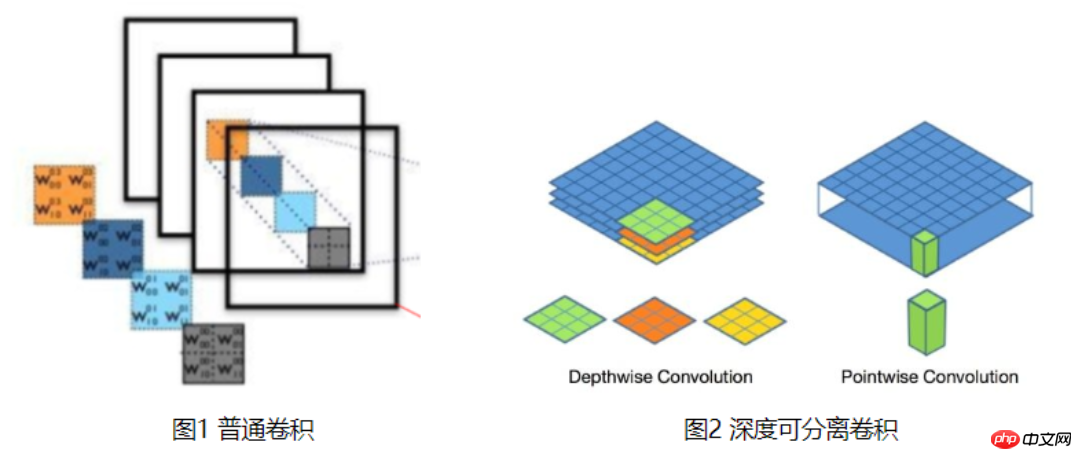
mobileNet V1是一种体积较小、计算量较少、适用于移动设备的卷积神经网络。mobileNet V1的主要创新点是用深度可分离卷积(depthwise separable convolution)代替普通的卷积,并使用宽度乘数(width multiply)减少参数量,不过减少参数的数量和操作的同时也会使特征丢失导致精度下降。 标准的卷积过程如图1,卷积核做卷积运算时得同时考虑对应图像区域中的所有通道(channel),而深度可分离卷积对不同的通道采用不同的卷积核进行卷积,如图2所示它将普通卷积分解成了深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)两个过程,这样可以将通道(channel)相关性和空间(spatial)相关性解耦。原文中给出的深度可分离卷积后面都接了一个BN和ReLU层。
mobileNetV1的网络结构如下表所示。前面的卷积层中除了第一层为标准卷积层外,其他都是深度可分离卷积(Conv dw + Conv/s1),卷积后接了一个77的平均池化层,之后通过全连接层,最后利用Softmax激活函数将全连接层输出归一化到0-1的一个概率值,根据概率值的高低可以得到图像的分类情况。
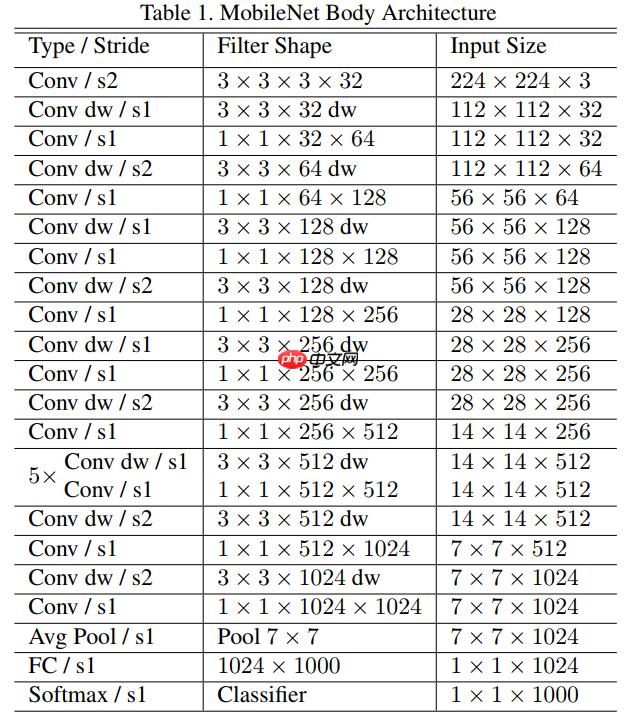
该模型还引入了两个超参数宽度因子和分辨率因子来提进一步降低模型的计算量。
该项目使用相同的学习率和batchsize,使用Adam优化器加速模型收敛
net = paddle.vision.models.MobileNetV2()
net = nn.Sequential(*list(net.children())[:-1],
nn.Flatten(),
nn.Linear(1280, 512),
nn.Linear(512, 4))
paddle.summary(net,(64, 3, 240, 240))#定义优化器和损失函数opt = paddle.optimizer.Adam(
learning_rate=lr,
parameters=net.parameters(),
beta1=0.9,
beta2=0.999)-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
Conv2D-197 [[64, 3, 240, 240]] [64, 32, 120, 120] 864
BatchNorm2D-197 [[64, 32, 120, 120]] [64, 32, 120, 120] 128
ReLU6-106 [[64, 32, 120, 120]] [64, 32, 120, 120] 0
Conv2D-198 [[64, 32, 120, 120]] [64, 32, 120, 120] 288
BatchNorm2D-198 [[64, 32, 120, 120]] [64, 32, 120, 120] 128
ReLU6-107 [[64, 32, 120, 120]] [64, 32, 120, 120] 0
Conv2D-199 [[64, 32, 120, 120]] [64, 16, 120, 120] 512
BatchNorm2D-199 [[64, 16, 120, 120]] [64, 16, 120, 120] 64
InvertedResidual-52 [[64, 32, 120, 120]] [64, 16, 120, 120] 0
Conv2D-200 [[64, 16, 120, 120]] [64, 96, 120, 120] 1,536
BatchNorm2D-200 [[64, 96, 120, 120]] [64, 96, 120, 120] 384
ReLU6-108 [[64, 96, 120, 120]] [64, 96, 120, 120] 0
Conv2D-201 [[64, 96, 120, 120]] [64, 96, 60, 60] 864
BatchNorm2D-201 [[64, 96, 60, 60]] [64, 96, 60, 60] 384
ReLU6-109 [[64, 96, 60, 60]] [64, 96, 60, 60] 0
Conv2D-202 [[64, 96, 60, 60]] [64, 24, 60, 60] 2,304
BatchNorm2D-202 [[64, 24, 60, 60]] [64, 24, 60, 60] 96
InvertedResidual-53 [[64, 16, 120, 120]] [64, 24, 60, 60] 0
Conv2D-203 [[64, 24, 60, 60]] [64, 144, 60, 60] 3,456
BatchNorm2D-203 [[64, 144, 60, 60]] [64, 144, 60, 60] 576
ReLU6-110 [[64, 144, 60, 60]] [64, 144, 60, 60] 0
Conv2D-204 [[64, 144, 60, 60]] [64, 144, 60, 60] 1,296
BatchNorm2D-204 [[64, 144, 60, 60]] [64, 144, 60, 60] 576
ReLU6-111 [[64, 144, 60, 60]] [64, 144, 60, 60] 0
Conv2D-205 [[64, 144, 60, 60]] [64, 24, 60, 60] 3,456
BatchNorm2D-205 [[64, 24, 60, 60]] [64, 24, 60, 60] 96
InvertedResidual-54 [[64, 24, 60, 60]] [64, 24, 60, 60] 0
Conv2D-206 [[64, 24, 60, 60]] [64, 144, 60, 60] 3,456
BatchNorm2D-206 [[64, 144, 60, 60]] [64, 144, 60, 60] 576
ReLU6-112 [[64, 144, 60, 60]] [64, 144, 60, 60] 0
Conv2D-207 [[64, 144, 60, 60]] [64, 144, 30, 30] 1,296
BatchNorm2D-207 [[64, 144, 30, 30]] [64, 144, 30, 30] 576
ReLU6-113 [[64, 144, 30, 30]] [64, 144, 30, 30] 0
Conv2D-208 [[64, 144, 30, 30]] [64, 32, 30, 30] 4,608
BatchNorm2D-208 [[64, 32, 30, 30]] [64, 32, 30, 30] 128
InvertedResidual-55 [[64, 24, 60, 60]] [64, 32, 30, 30] 0
Conv2D-209 [[64, 32, 30, 30]] [64, 192, 30, 30] 6,144
BatchNorm2D-209 [[64, 192, 30, 30]] [64, 192, 30, 30] 768
ReLU6-114 [[64, 192, 30, 30]] [64, 192, 30, 30] 0
Conv2D-210 [[64, 192, 30, 30]] [64, 192, 30, 30] 1,728
BatchNorm2D-210 [[64, 192, 30, 30]] [64, 192, 30, 30] 768
ReLU6-115 [[64, 192, 30, 30]] [64, 192, 30, 30] 0
Conv2D-211 [[64, 192, 30, 30]] [64, 32, 30, 30] 6,144
BatchNorm2D-211 [[64, 32, 30, 30]] [64, 32, 30, 30] 128
InvertedResidual-56 [[64, 32, 30, 30]] [64, 32, 30, 30] 0
Conv2D-212 [[64, 32, 30, 30]] [64, 192, 30, 30] 6,144
BatchNorm2D-212 [[64, 192, 30, 30]] [64, 192, 30, 30] 768
ReLU6-116 [[64, 192, 30, 30]] [64, 192, 30, 30] 0
Conv2D-213 [[64, 192, 30, 30]] [64, 192, 30, 30] 1,728
BatchNorm2D-213 [[64, 192, 30, 30]] [64, 192, 30, 30] 768
ReLU6-117 [[64, 192, 30, 30]] [64, 192, 30, 30] 0
Conv2D-214 [[64, 192, 30, 30]] [64, 32, 30, 30] 6,144
BatchNorm2D-214 [[64, 32, 30, 30]] [64, 32, 30, 30] 128
InvertedResidual-57 [[64, 32, 30, 30]] [64, 32, 30, 30] 0
Conv2D-215 [[64, 32, 30, 30]] [64, 192, 30, 30] 6,144
BatchNorm2D-215 [[64, 192, 30, 30]] [64, 192, 30, 30] 768
ReLU6-118 [[64, 192, 30, 30]] [64, 192, 30, 30] 0
Conv2D-216 [[64, 192, 30, 30]] [64, 192, 15, 15] 1,728
BatchNorm2D-216 [[64, 192, 15, 15]] [64, 192, 15, 15] 768
ReLU6-119 [[64, 192, 15, 15]] [64, 192, 15, 15] 0
Conv2D-217 [[64, 192, 15, 15]] [64, 64, 15, 15] 12,288
BatchNorm2D-217 [[64, 64, 15, 15]] [64, 64, 15, 15] 256
InvertedResidual-58 [[64, 32, 30, 30]] [64, 64, 15, 15] 0
Conv2D-218 [[64, 64, 15, 15]] [64, 384, 15, 15] 24,576
BatchNorm2D-218 [[64, 384, 15, 15]] [64, 384, 15, 15] 1,536
ReLU6-120 [[64, 384, 15, 15]] [64, 384, 15, 15] 0
Conv2D-219 [[64, 384, 15, 15]] [64, 384, 15, 15] 3,456
BatchNorm2D-219 [[64, 384, 15, 15]] [64, 384, 15, 15] 1,536
ReLU6-121 [[64, 384, 15, 15]] [64, 384, 15, 15] 0
Conv2D-220 [[64, 384, 15, 15]] [64, 64, 15, 15] 24,576
BatchNorm2D-220 [[64, 64, 15, 15]] [64, 64, 15, 15] 256
InvertedResidual-59 [[64, 64, 15, 15]] [64, 64, 15, 15] 0
Conv2D-221 [[64, 64, 15, 15]] [64, 384, 15, 15] 24,576
BatchNorm2D-221 [[64, 384, 15, 15]] [64, 384, 15, 15] 1,536
ReLU6-122 [[64, 384, 15, 15]] [64, 384, 15, 15] 0
Conv2D-222 [[64, 384, 15, 15]] [64, 384, 15, 15] 3,456
BatchNorm2D-222 [[64, 384, 15, 15]] [64, 384, 15, 15] 1,536
ReLU6-123 [[64, 384, 15, 15]] [64, 384, 15, 15] 0
Conv2D-223 [[64, 384, 15, 15]] [64, 64, 15, 15] 24,576
BatchNorm2D-223 [[64, 64, 15, 15]] [64, 64, 15, 15] 256
InvertedResidual-60 [[64, 64, 15, 15]] [64, 64, 15, 15] 0
Conv2D-224 [[64, 64, 15, 15]] [64, 384, 15, 15] 24,576
BatchNorm2D-224 [[64, 384, 15, 15]] [64, 384, 15, 15] 1,536
ReLU6-124124 [[64, 384, 15, 15]] [64, 384, 15, 15] 0
Conv2D-225 [[64, 384, 15, 15]] [64, 384, 15, 15] 3,456
BatchNorm2D-225 [[64, 384, 15, 15]] [64, 384, 15, 15] 1,536
ReLU6-125 [[64, 384, 15, 15]] [64, 384, 15, 15] 0
Conv2D-226 [[64, 384, 15, 15]] [64, 64, 15, 15] 24,576
BatchNorm2D-226 [[64, 64, 15, 15]] [64, 64, 15, 15] 256
InvertedResidual-61 [[64, 64, 15, 15]] [64, 64, 15, 15] 0
Conv2D-227 [[64, 64, 15, 15]] [64, 384, 15, 15] 24,576
BatchNorm2D-227 [[64, 384, 15, 15]] [64, 384, 15, 15] 1,536
ReLU6-126 [[64, 384, 15, 15]] [64, 384, 15, 15] 0
Conv2D-228 [[64, 384, 15, 15]] [64, 384, 15, 15] 3,456
BatchNorm2D-228 [[64, 384, 15, 15]] [64, 384, 15, 15] 1,536
ReLU6-127 [[64, 384, 15, 15]] [64, 384, 15, 15] 0
Conv2D-229 [[64, 384, 15, 15]] [64, 96, 15, 15] 36,864
BatchNorm2D-229 [[64, 96, 15, 15]] [64, 96, 15, 15] 384
InvertedResidual-62 [[64, 64, 15, 15]] [64, 96, 15, 15] 0
Conv2D-230 [[64, 96, 15, 15]] [64, 576, 15, 15] 55,296
BatchNorm2D-230 [[64, 576, 15, 15]] [64, 576, 15, 15] 2,304
ReLU6-128 [[64, 576, 15, 15]] [64, 576, 15, 15] 0
Conv2D-231 [[64, 576, 15, 15]] [64, 576, 15, 15] 5,184
BatchNorm2D-231 [[64, 576, 15, 15]] [64, 576, 15, 15] 2,304
ReLU6-129 [[64, 576, 15, 15]] [64, 576, 15, 15] 0
Conv2D-232 [[64, 576, 15, 15]] [64, 96, 15, 15] 55,296
BatchNorm2D-232 [[64, 96, 15, 15]] [64, 96, 15, 15] 384
InvertedResidual-63 [[64, 96, 15, 15]] [64, 96, 15, 15] 0
Conv2D-233 [[64, 96, 15, 15]] [64, 576, 15, 15] 55,296
BatchNorm2D-233 [[64, 576, 15, 15]] [64, 576, 15, 15] 2,304
ReLU6-130 [[64, 576, 15, 15]] [64, 576, 15, 15] 0
Conv2D-234 [[64, 576, 15, 15]] [64, 576, 15, 15] 5,184
BatchNorm2D-234 [[64, 576, 15, 15]] [64, 576, 15, 15] 2,304
ReLU6-131 [[64, 576, 15, 15]] [64, 576, 15, 15] 0
Conv2D-235 [[64, 576, 15, 15]] [64, 96, 15, 15] 55,296
BatchNorm2D-235 [[64, 96, 15, 15]] [64, 96, 15, 15] 384
InvertedResidual-64 [[64, 96, 15, 15]] [64, 96, 15, 15] 0
Conv2D-236 [[64, 96, 15, 15]] [64, 576, 15, 15] 55,296
BatchNorm2D-236 [[64, 576, 15, 15]] [64, 576, 15, 15] 2,304
ReLU6-132 [[64, 576, 15, 15]] [64, 576, 15, 15] 0
Conv2D-237 [[64, 576, 15, 15]] [64, 576, 8, 8] 5,184
BatchNorm2D-237 [[64, 576, 8, 8]] [64, 576, 8, 8] 2,304
ReLU6-133 [[64, 576, 8, 8]] [64, 576, 8, 8] 0
Conv2D-238 [[64, 576, 8, 8]] [64, 160, 8, 8] 92,160
BatchNorm2D-238 [[64, 160, 8, 8]] [64, 160, 8, 8] 640
InvertedResidual-65 [[64, 96, 15, 15]] [64, 160, 8, 8] 0
Conv2D-239 [[64, 160, 8, 8]] [64, 960, 8, 8] 153,600
BatchNorm2D-239 [[64, 960, 8, 8]] [64, 960, 8, 8] 3,840
ReLU6-134 [[64, 960, 8, 8]] [64, 960, 8, 8] 0
Conv2D-240 [[64, 960, 8, 8]] [64, 960, 8, 8] 8,640
BatchNorm2D-240 [[64, 960, 8, 8]] [64, 960, 8, 8] 3,840
ReLU6-135 [[64, 960, 8, 8]] [64, 960, 8, 8] 0
Conv2D-241 [[64, 960, 8, 8]] [64, 160, 8, 8] 153,600
BatchNorm2D-241 [[64, 160, 8, 8]] [64, 160, 8, 8] 640
InvertedResidual-66 [[64, 160, 8, 8]] [64, 160, 8, 8] 0
Conv2D-242 [[64, 160, 8, 8]] [64, 960, 8, 8] 153,600
BatchNorm2D-242 [[64, 960, 8, 8]] [64, 960, 8, 8] 3,840
ReLU6-136 [[64, 960, 8, 8]] [64, 960, 8, 8] 0
Conv2D-243 [[64, 960, 8, 8]] [64, 960, 8, 8] 8,640
BatchNorm2D-243 [[64, 960, 8, 8]] [64, 960, 8, 8] 3,840
ReLU6-137 [[64, 960, 8, 8]] [64, 960, 8, 8] 0
Conv2D-244 [[64, 960, 8, 8]] [64, 160, 8, 8] 153,600
BatchNorm2D-244 [[64, 160, 8, 8]] [64, 160, 8, 8] 640
InvertedResidual-67 [[64, 160, 8, 8]] [64, 160, 8, 8] 0
Conv2D-245 [[64, 160, 8, 8]] [64, 960, 8, 8] 153,600
BatchNorm2D-245 [[64, 960, 8, 8]] [64, 960, 8, 8] 3,840
ReLU6-138 [[64, 960, 8, 8]] [64, 960, 8, 8] 0
Conv2D-246 [[64, 960, 8, 8]] [64, 960, 8, 8] 8,640
BatchNorm2D-246 [[64, 960, 8, 8]] [64, 960, 8, 8] 3,840
ReLU6-139 [[64, 960, 8, 8]] [64, 960, 8, 8] 0
Conv2D-247 [[64, 960, 8, 8]] [64, 320, 8, 8] 307,200
BatchNorm2D-247 [[64, 320, 8, 8]] [64, 320, 8, 8] 1,280
InvertedResidual-68 [[64, 160, 8, 8]] [64, 320, 8, 8] 0
Conv2D-248 [[64, 320, 8, 8]] [64, 1280, 8, 8] 409,600
BatchNorm2D-248 [[64, 1280, 8, 8]] [64, 1280, 8, 8] 5,120
ReLU6-140 [[64, 1280, 8, 8]] [64, 1280, 8, 8] 0
AdaptiveAvgPool2D-6 [[64, 1280, 8, 8]] [64, 1280, 1, 1] 0
Flatten-5 [[64, 1280, 1, 1]] [64, 1280] 0
Linear-13 [[64, 1280]] [64, 512] 655,872
Linear-14 [[64, 512]] [64, 4] 2,052
===============================================================================
Total params: 2,915,908
Trainable params: 2,847,684
Non-trainable params: 68,224
-------------------------------------------------------------------------------
Input size (MB): 42.19
Forward/backward pass size (MB): 11326.83
Params size (MB): 11.12
Estimated Total Size (MB): 11380.14
-------------------------------------------------------------------------------# 开始训练net.train()for epoch in range(EPOCH): for batch_id, data in tqdm(enumerate(train_loader())):
imgs = data[0]
label = data[1]
infer_prob = net(imgs)
loss = loss_func(infer_prob, label)
acc = paddle.metric.accuracy(infer_prob, label)
loss.backward()
opt.step()
opt.clear_gradients() if (batch_id + 1) % 20 == 0: print('第{}个epoch:batch_id is: {},loss is: {}, acc is: {}'.format(epoch,batch_id + 1, loss.numpy(),acc.numpy()))
paddle.save(resnet.state_dict(), 'mobile_param')这里我们在测试集上分别测试两个网络的平均精度,展示如下,ResNet18凭借更高的模型复杂度和更强大的特征提取能力得到了更高的准确率
# resnet18效果展示resnet.set_state_dict(paddle.load("param"))
resnet.eval()
global_acc = 0idx = 0for batch_id, testdata in enumerate(test_loader()):
imgs = testdata[0]
label = testdata[1]
predicts = resnet(imgs) # 计算损失与精度
loss = loss_func(predicts, label)
global_acc += paddle.metric.accuracy(predicts, label).numpy()[0]
idx += 1
# 打印信息
if (batch_id+1) % 20 == 0: print("batch_id: {}, loss is: {}".format(batch_id+1, loss.numpy()))print("全局准确率为:{}".format(global_acc / idx))batch_id: 20, loss is: [0.24643926] batch_id: 40, loss is: [0.4239157] batch_id: 60, loss is: [0.04833409] 全局准确率为:0.8782225472804828
# mobilenet效果展示net.set_state_dict(paddle.load("mobile_param"))
net.eval()
global_acc = 0idx = 0for batch_id, testdata in enumerate(test_loader()):
imgs = testdata[0]
label = testdata[1]
predicts = net(imgs) # 计算损失与精度
loss = loss_func(predicts, label)
global_acc += paddle.metric.accuracy(predicts, label).numpy()[0]
idx += 1
# 打印信息
if (batch_id+1) % 20 == 0: print("batch_id: {}, loss is: {}".format(batch_id+1, loss.numpy()))print("全局准确率为:{}".format(global_acc / idx))batch_id: 20, loss is: [0.9668553] 全局准确率为:0.785875583306337
该项目分别使用Resnet18和Mobilenetv1上对血细胞图像数据集进行分类任务的训练,目的是通过计算机视觉的方法利用人工智能技术来检测和分类血细胞亚型,从而提高血细胞分类精度并降低检测成本,有利于更加精确的分析血液样本的各项指标,最终实现为病人提供更加精准的检测报告。
以上就是基于计算机视觉的全细胞计数自动化分析方法的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 897
897

























