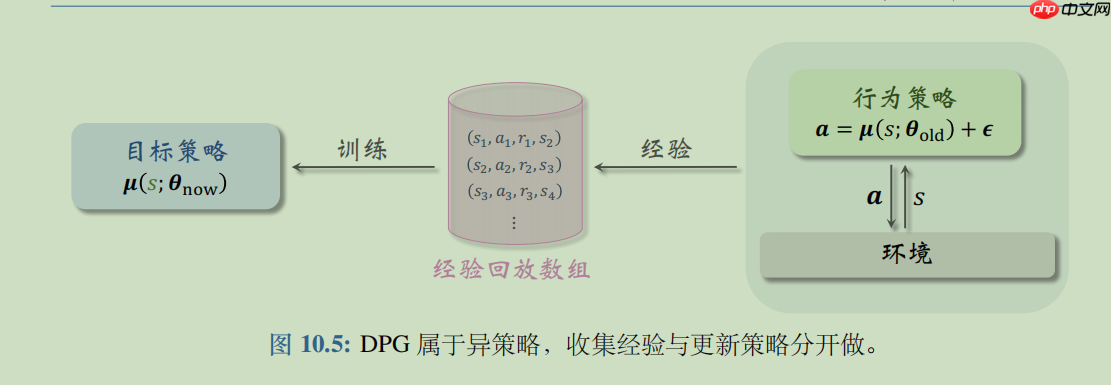
DPG是确定策略梯度 (Deterministic Policy Gradient, DPG)是最常用的连续控制方法。DPG是一种 Actor-Critic 方法,它有一个策略网络(演员),一个价值网络(评委)。策略网络控制智能体做运动,它基于状态 s 做出动作 a。价值网络不控制智能体,只是基于状态 s 给动作 a 打分,从而指导策略网络做出改进。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

DPG是确定策略梯度 (Deterministic Policy Gradient, DPG)是最常用的连续控制方法。DPG是一种 Actor-Critic 方法,它有一个策略网络(演员),一个价值网络(评委)。策略网络控制智能体做运动,它基于状态 s 做出动作 a。价值网络不控制智能体,只是基于状态 s 给动作 a 打分,从而指导策略网络做出改进。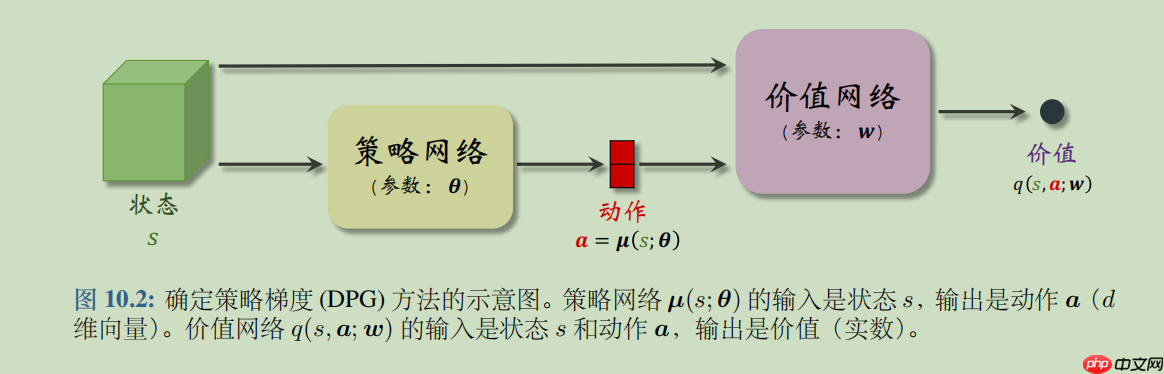
倒立摆问题的经典的连续控制问题,钟摆以随机位置开始,目标是将其向上摆动,使其保持直立。其状态空间为3,动作空间为1(因为是连续的,有范围)。具体可以参考下图:
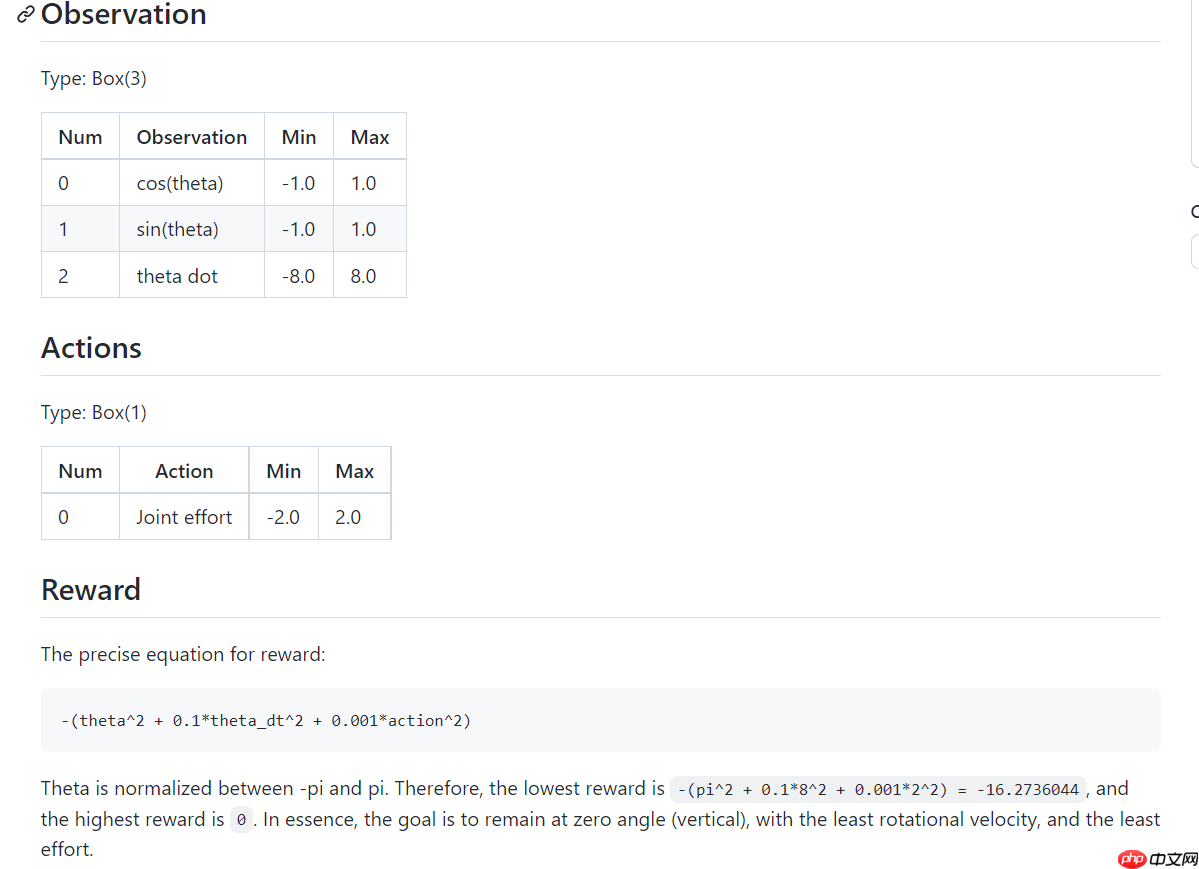
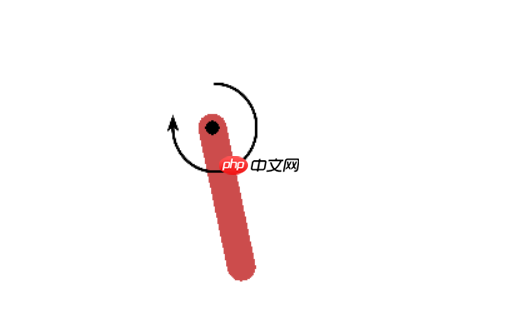
使用深度神经网络DPG训练模型,也就是DDPG方法,使其在倒立摆环境中能够获得较好的奖励。
import gymimport paddlefrom itertools import countimport numpy as npfrom collections import dequeimport randomimport timefrom visualdl import LogWriter
DDPG这种方法与Q学习紧密相关,可以看做是 【连续】动作空间的深度Q学习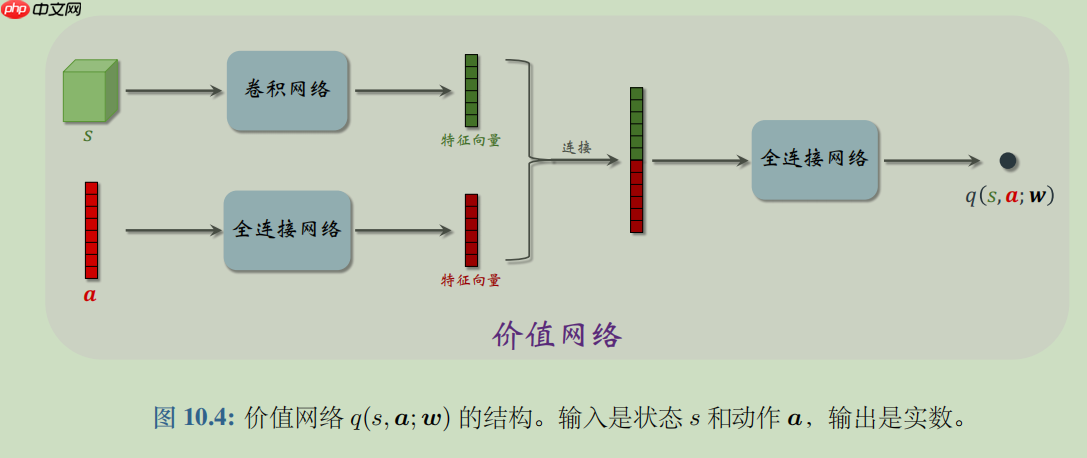
class Critic(paddle.nn.Layer):
def __init__(self):
super(Critic,self).__init__()
# 状态空间为3
self.fc1=paddle.nn.Linear(3,256)
# 连接了动作空间,所以+1
self.fc2=paddle.nn.Linear(256+1,128) #
self.fc3=paddle.nn.Linear(128,1)
self.relu=paddle.nn.ReLU()
def forward(self,x,a):
x=self.relu(self.fc1(x))
x=paddle.concat((x,a),axis=1)
x=self.relu(self.fc2(x))
x=self.fc3(x) return x为了使DDPG策略更好的进行探索,在训练时对其行为增加了干扰。原始DDPG论文建议使用时间相关的OU噪声,但最近的结果表明,【不相关的均值零高斯噪声】效果更好。后者更简单,首选。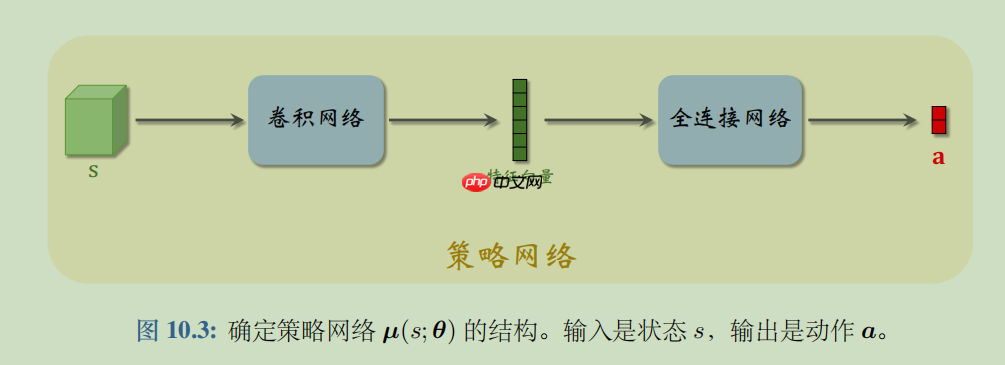
class Actor(paddle.nn.Layer):
def __init__(self,is_tranin=True):
super(Actor,self).__init__()
self.fc1=paddle.nn.Linear(3,256)
self.fc2=paddle.nn.Linear(256,128)
self.fc3=paddle.nn.Linear(128,1)
self.relu=paddle.nn.ReLU() # max(0,x)
self.tanh=paddle.nn.Tanh() # 双切正切曲线 (e^(x)-e^(-x))/(e^(x)+e^(-x))
self.noisy=paddle.distribution.Normal(0,0.2)
self.is_tranin=is_tranin
def forward(self,x):
x=self.relu(self.fc1(x))
x=self.relu(self.fc2(x))
x=self.tanh(self.fc3(x)) return x
def select_action(self,epsilon,state):
state=paddle.to_tensor(state,dtype='float32').unsqueeze(0) # 创建一个上下文来禁用动态图梯度计算。在此模式下,每次计算的结果都将具有stop_gradient=True。
with paddle.no_grad(): # squeeze():会删除输入Tensor的Shape中尺寸为1的维度
# noisy抽样结果是1维的tensor
action=self.forward(state).squeeze()+self.is_tranin*epsilon*self.noisy.sample([1]).squeeze(0)
# paddle.clip:将输入的所有元素进行剪裁,使得输出元素限制在[min, max]内
# 动作空间是[-2,2]
return 2*paddle.clip(action,-1,1).numpy()这是智能体以前的经验,为了使算法具有稳定的行为,重播缓冲区应该足够大以包含广泛的经验。
class Memory(object):
def __init__(self,memory_size):
self.memory_size=memory_size
self.buffer=deque(maxlen=self.memory_size)
# 增加经验,因为经验数组是存放在deque中的,deque是双端队列,
# 我们的deque指定了大小,当deque满了之后再add元素,则会自动把队首的元素出队
def add(self,experience):
self.buffer.append(experience)
def size(self):
return len(self.buffer) # continuous=True则表示连续取batch_size个经验
def sample(self , batch_szie , continuous = True):
# 选取的经验数目是否超过缓冲区内经验的数目
if batch_szie>len(self.buffer):
batch_szie=len(self.buffer)
# 是否连续取经验
if continuous: # random.randint(a,b) 返回[a,b]之间的任意整数
rand=random.randint(0,len(self.buffer)-batch_szie) return [self.buffer[i] for i in range(rand,rand+batch_szie)] else: # numpy.random.choice(a, size=None, replace=True, p=None)
# a 如果是数组则在数组中采样;a如果是整数,则从[0,a-1]这个序列中随机采样
# size 如果是整数则表示采样的数量
# replace为True可以重复采样;为false不会重复
# p 是一个数组,表示a中每个元素采样的概率;为None则表示等概率采样
indexes=np.random.choice(np.arange(len(self.buffer)),size=batch_szie,replace=False) return [self.buffer[i] for i in indexes]
def clear(self):
self.buffer.clear()env=gym.make('Pendulum-v0')
actor=Actor()
critic=Critic()W1225 22:38:55.283380 289 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W1225 22:38:55.287163 289 device_context.cc:465] device: 0, cuDNN Version: 7.6.
critic_optim=paddle.optimizer.Adam(parameters=critic.parameters(),learning_rate=3e-5) actor_optim=paddle.optimizer.Adam(parameters=actor.parameters(),learning_rate=1e-5)
explore=50000epsilon=1 # 控制动作的抽样gamma=0.99tau=0.001memory_replay=Memory(50000)
begin_train=Falsebatch_szie=32learn_steps=0epochs=100writer=LogWriter('./logs')
s_time=time.time()for epoch in range(0,epochs):
start_time=time.time()
state=env.reset()
episode_reward=0 # 记录一个epoch的奖励综合
# 一个epoch进行2000的时间步
for time_step in range(2000): # 步骤1,策略网络根据初始状态做预测
action=actor.select_action(epsilon,state)
next_state,reward,done,_=env.step([action])
episode_reward+=reward # 这一步在做什么? reward [-1,1]
reward=(reward+8.2)/8.2
memory_replay.add((state,next_state,action,reward)) # 当经验回放数组中的存放一定量的经验才开始利用
if memory_replay.size()>1280:
learn_steps+=1
if not begin_train: print('train begin!')
begin_train=True
# false : 不连续抽样
experiences=memory_replay.sample(batch_szie,False)
batch_state,batch_next_state,batch_action,batch_reward=zip(*experiences)
batch_state=paddle.to_tensor(batch_state,dtype='float32')
batch_next_state=paddle.to_tensor(batch_next_state,dtype='float32')
batch_action=paddle.to_tensor(batch_action,dtype='float32').unsqueeze(1)
batch_reward=paddle.to_tensor(batch_reward,dtype='float32').unsqueeze(1)
with paddle.no_grad():
# 策略网络做预测
at,at1=actor(batch_state),actor(batch_next_state) # 价值网络做预测
qt,qt1=critic(batch_state,batch_action),critic(batch_next_state,at1) # 计算TD目标
Q_traget=batch_reward+gamma*qt1
# TD误差函数
# 该OP用于计算预测值和目标值的均方差误差。(预测值,目标值)
# reduction='mean',默认值,计算均值
critic_loss=paddle.nn.functional.mse_loss(qt,Q_traget) # 更新价值网络
critic_optim.clear_grad()
critic_loss.backward()
critic_optim.step()
writer.add_scalar('critic loss',critic_loss.numpy(),learn_steps) # 更新策略网络
critic.eval()
actor_loss=-critic(batch_state,at)
actor_loss=actor_loss.mean()
actor_optim.clear_grad()
actor_loss.backward()
actor_optim.step()
critic.train()
writer.add_scalar('actor loss',actor_loss.numpy(),learn_steps) # epsilon 逐渐减小
if epsilon>0:
epsilon-=1/explore
state=next_state
writer.add_scalar('episode reward',episode_reward/2000,epoch)
if epoch%10==0: print("Epoch:{}, episode reward is {:.3f}, use time is {:.3f}s ".format(epoch,episode_reward/2000,time.time()-start_time))
print("************ all time is {:.3f} h:".format((time.time()-s_time)/3600))train begin!
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:130: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations if data.dtype == np.object:
Epoch:0, episode reward is -6.058, use time is 4.891s Epoch:10, episode reward is -6.146, use time is 11.346s Epoch:20, episode reward is -6.144, use time is 11.830s Epoch:30, episode reward is -7.270, use time is 11.998s Epoch:40, episode reward is -6.148, use time is 11.932s Epoch:50, episode reward is -7.335, use time is 12.149s Epoch:60, episode reward is -6.411, use time is 12.301s Epoch:70, episode reward is -6.135, use time is 12.365s Epoch:80, episode reward is -6.768, use time is 12.136s Epoch:90, episode reward is -6.219, use time is 12.191s ************ all time is 0.329 h:
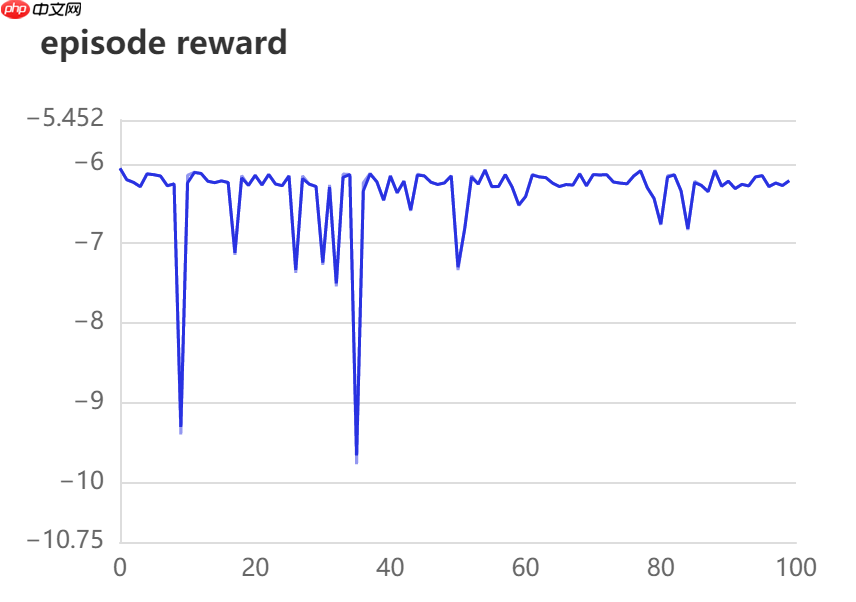
奖励在-6左右徘徊,说明网络效果不好(奖励越靠近0越好)。下面加入目标网络进行实验。
加入目标网络的作用是缓解高估问题,DPG中的高估来自两个方面:

一套自助创建网上商店的软件系统,具有界面变幻多彩、功能强大,使用傻瓜化、运行自动化的特点,任何人基本上不用学习,都能快速创建自己的网上商店,用这套系统做一个购物网站,就象做填空题一样容易。采用「巨蟹星云」可以建立诸如:网上花店、网上化妆品店、网上服装店、网上书店、网上点卡店、网上成人用品店、网上玩具店、网上书店、网上手机店、网上数码产品销售店、网上保健品店、网上玩具店、网上车模店、网上音像制品店等
 0
0

自举与最大化的分析可参考王书的10.3.3节,分析的挺不错,但是推理比较复杂,这里就不再描述了,主要把结论记住就好。(陶渊明说读书要不求甚解,嘿嘿)
这里我们重新定义了所有参数,即使前面定义过,因为有的参数是不断更新的(值变了),所有我们在这里统一重新定义一下。
actor=Actor()
critic=Critic()
critic_optim=paddle.optimizer.Adam(parameters=critic.parameters(),learning_rate=3e-5)
actor_optim=paddle.optimizer.Adam(parameters=actor.parameters(),learning_rate=1e-5)# 目标网络,缓解自举造成的高估问题actor_target=Actor()
critic_target=Critic()
explore=50000epsilon=1 # 控制动作的抽样gamma=0.99tau=0.001memory_replay=Memory(50000)
begin_train=Falsebatch_szie=32learn_steps=0epochs=100twriter=LogWriter('./newlogs')更新目标网络参数,公式如下:
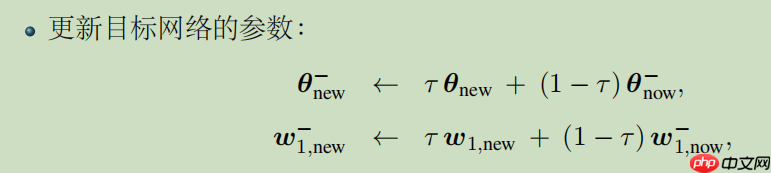
def soft_update(target,source,tau):
# zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
for target_param,param in zip(target.parameters(),source.parameters()):
target_param.set_value(target_param*(1.0-tau)+param*tau)
s_time=time.time()
k=0for epoch in range(0,epochs):
start_time=time.time()
state=env.reset()
episode_reward=0 # 记录一个epoch的奖励综合
# 一个epoch进行2000的时间步
for time_step in range(2000): # 步骤1,策略网络根据初始状态做预测
action=actor.select_action(epsilon,state)
next_state,reward,done,_=env.step([action])
episode_reward+=reward # reward缩放到 [-1,1]
reward=(reward+8.2)/8.2
memory_replay.add((state,next_state,action,reward)) # 当经验回放数组中的存放一定量的经验才开始利用
if memory_replay.size()>1280:
learn_steps+=1
if not begin_train: print('train begin!')
begin_train=True
# false : 不连续抽样
# 从经验数组中随机抽取四元组(s_t,a_t,r_t,s_t+1)
experiences=memory_replay.sample(batch_szie,False)
batch_state,batch_next_state,batch_action,batch_reward=zip(*experiences)
batch_state=paddle.to_tensor(batch_state,dtype='float32')
batch_next_state=paddle.to_tensor(batch_next_state,dtype='float32')
batch_action=paddle.to_tensor(batch_action,dtype='float32').unsqueeze(1)
batch_reward=paddle.to_tensor(batch_reward,dtype='float32').unsqueeze(1) # 目标策略网络做预测,输入是 s_t+1 预测出下一个动作a_t+1
# 目标价值网络做预测,输入是s_t+1和a_t+1,输出是q_tt
# 计算TD目标,y= r_t+gamma*q_tt
with paddle.no_grad(): # Q_next traget是TD目标
Q_next=critic_target(batch_next_state,actor_target(batch_next_state))
Q_traget=batch_reward+gamma*Q_next
# 价值网络做预测,输入是s_t,a_t,输出是q_t
# 计算TD误差,error=q_t-y
# 误差函数
# 该OP用于计算预测值和目标值的均方差误差。(预测值,目标值)
# reduction='mean',默认值,计算均值
critic_loss=paddle.nn.functional.mse_loss(critic(batch_state,batch_action),Q_traget)
# 更新价值网络
critic_optim.clear_grad()
critic_loss.backward()
critic_optim.step()
twriter.add_scalar('critic loss',critic_loss.numpy(),learn_steps) if k==5: #更新策略网络
# 使用Critic网络给定值的平均值来评价Actor网络采取的行动。最大化该值。
# 更新Actor()网络,对于一个给定状态,它产生的动作尽量让Critic网络给出高的评分
critic.eval()
actor_loss=-critic(batch_state,actor(batch_state))
actor_loss=actor_loss.mean()
actor_optim.clear_grad()
actor_loss.backward()
actor_optim.step()
critic.train()
twriter.add_scalar('actor loss',actor_loss.numpy(),learn_steps) # 更新目标网络
soft_update(actor_target,actor,tau)
soft_update(critic_target,critic,tau)
k=0
else:
k+=1
# epsilon 逐渐减小
if epsilon>0:
epsilon-=1/explore
state=next_state
twriter.add_scalar('episode reward',episode_reward/2000,epoch)
if epoch%10==0: print("Epoch:{}, episode reward is {:.3f}, use time is {:.3f}s ".format(epoch,episode_reward/2000,time.time()-start_time))
print("************ all time is {:.3f} h:".format((time.time()-s_time)/3600))train begin! Epoch:0, episode reward is -8.726, use time is 4.682s Epoch:10, episode reward is -7.607, use time is 10.381s Epoch:20, episode reward is -7.419, use time is 11.115s Epoch:30, episode reward is -6.317, use time is 11.464s Epoch:40, episode reward is -8.340, use time is 11.308s Epoch:50, episode reward is -8.306, use time is 11.535s Epoch:60, episode reward is -8.276, use time is 11.356s Epoch:70, episode reward is -1.401, use time is 11.539s Epoch:80, episode reward is -8.145, use time is 11.346s Epoch:90, episode reward is -0.076, use time is 11.321s ************ all time is 0.308 h:
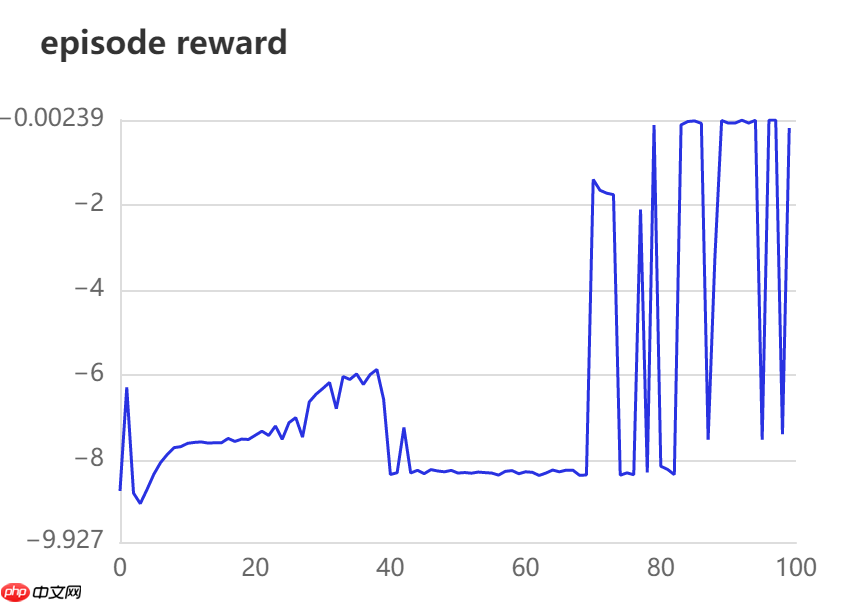
奖励在训练的后期可以达到较好的奖励值,但是波动较大。但是与没有加入目标网络的模型相比较结果有所进步。后续有时间继续优化。
以上就是【强化学习】DDPG : 强化学习之倒立摆的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 279
279























