






【飞桨领航团】AI达人特训营:PaddleNLP实现聊天问答匹配
1. 项目背景
本项目是ai达人特训营的选题,目测该选题来自这个比赛:房产行业聊天问答匹配
背景: 贝壳找房是以技术驱动的品质居住服务平台,“有尊严的服务者、更美好的居住”,是贝壳的使命。在帮助客户实现更美好的居住过程中,客户会和服务者(房产经纪人)反复深入交流对居住的要求,这个交流发生在贝壳APP上的IM中。
IM交流是双方建立信任的必要环节,客户需要在这个场景下经常向服务者咨询许多问题,而服务者是否为客户提供了感受良好、解答专业的服务就很重要,贝壳平台对此非常关注。因此,需要准确找出服务者是否回答了客户的问题,并进一步判断回答得是否准确得体,随着贝壳平台规模扩大,需要AI参与这个过程。
任务:
赛题任务:给定IM交流片段,片段包含一个客户问题以及随后的经纪人若干IM消息,从这些随后的经纪人消息中找出一个是对客户问题的回答。
任务要点:
- 数据来自一个IM聊天交流过程;
- 选取的客户问题之前的聊天内容不会提供;
- 提供客户问题之后的经纪人发送的内容;
- 如果在这些经纪人发送内容之间原本来穿插了其他客户消息,不会提供;
- 这些经纪人发送内容中有0条或多条对客户问题的回答,把它找出来。
结果:
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
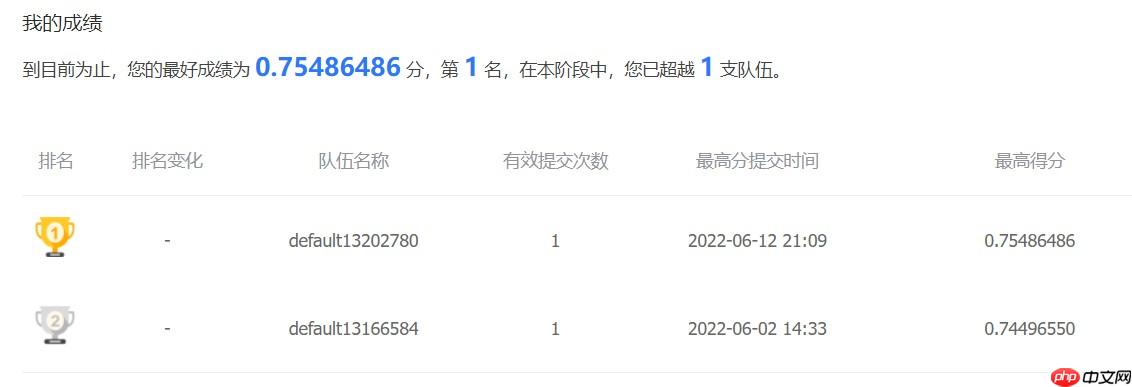
说明:比赛已经比较久了,现在只能获取长期公开赛的评分排名,而且没什么人,不过用来学习文本匹配思路还是不错的。
2. 数据集
2.1 数据说明
一共有三份数据:训练集、测试集和提交示例。
训练集包含客户问题文件和经纪人回复两个文件,涉及6000段对话(有标签答案)。
测试集包含客户问题文件和经纪人回复两个文件,涉及14000段对话(无标签答案)。
2.2 数据示例
解压训练集和测试集
!unzip data/data144231/train.zip -d ./data && unzip data/data144231/test.zip -d ./data
Archive: data/data144231/train.zip creating: ./data/train/ inflating: ./data/train/train.query.tsv inflating: ./data/train/train.reply.tsv Archive: data/data144231/test.zip creating: ./data/test/ inflating: ./data/test/test.query.tsv inflating: ./data/test/test.reply.tsv
查看数据示例
import pandas as pd
train_query = pd.read_csv("data/train/train.query.tsv", sep='\t', header=None)
train_query.columns = ['query_id', 'sentence']# query 文件有 2 列,分别是问题 Id 和客户问题,同一对话 Id 只有一个问题,已脱敏print(train_query.head())
train_reply = pd.read_csv("data/train/train.reply.tsv", sep='\t', header=None)
train_reply.columns = ['query_id', 'reply_id', 'sentence', 'label']# reply 文件有 4 列,分别是:# 对话id,对应客户问题文件中的对话 id # 经纪人回复 Id,Id 对应真实回复顺序# 经纪人回复内容,已脱敏# 经纪人回复标签,1 表示此回复是针对客户问题的回答,0 相反print(train_reply.head())# 训练集文件结构与测试集相同,只不过 reply 文件没有回复标签test_query = pd.read_csv("data/test/test.query.tsv", sep='\t', header=None, encoding='gb18030')
test_query.columns = ['query_id', 'sentence']print(test_query.head())
test_reply = pd.read_csv("data/test/test.reply.tsv", sep='\t', header=None, encoding='gb18030')
test_reply.columns = ['query_id', 'reply_id', 'sentence']print(test_reply.head())
query_id sentence 0 0 采荷一小是分校吧 1 1 毛坯吗? 2 2 你们的佣金费大约是多少和契税是多少。 3 3 靠近川沙路嘛? 4 4 这套房源价格还有优惠空间吗? query_id reply_id sentence label 0 0 0 杭州市采荷第一小学钱江苑校区,杭州市钱江新城实验学校。 1 1 0 1 是的 0 2 0 2 这是5楼 0 3 1 0 因为公积金贷款贷的少 0 4 1 1 是呢 0 query_id sentence 0 0 东区西区?什么时候下证? 1 1 小学哪个 2 2 看哪个? 3 3 面积多少,什么户型 4 4 什么时候能够看房呢? query_id reply_id sentence 0 0 0 我在给你发套 1 0 1 您看下我发的这几套 2 0 2 这两套也是金源花园的 3 0 3 价钱低 4 0 4 便宜的房子,一般都是顶楼
3. ERNIE 系列模型
原文:
- ERNIE: Enhanced Representation through Knowledge Integration
- ERNIE 2.0: A Continual Pre-training Framework for Language Understanding
- ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
ERNIE 1.0
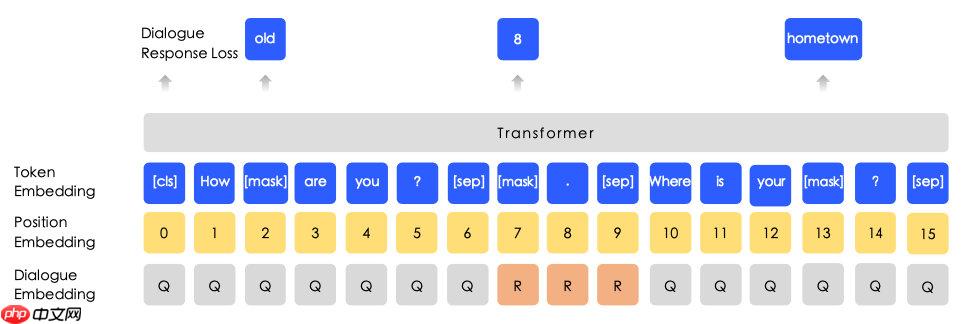
首先对原始的MLM任务进行改进,引入了Entity-level masking和Phrase-level masking,帮助模型学习更多的词汇短语知识,这个任务也成为了后续中文预训练模型的标配:

同时引入了DLM(Dialogue Language Model)对NSP任务进行了优化,在预测Mask token的同时判断输入的多轮对话(QRQ、QRR、QQR三种模式)是否真实。
ERNIE 2.0
首先是框架上的闭环化,把各种下游任务持续加入模型中提升效果:
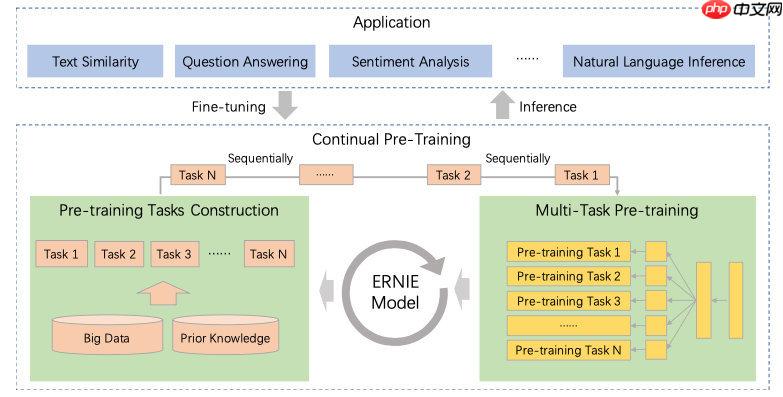
其次引入更多预训练任务,细节参见原论文。
ERNIE 3.0
3.0版本首先延续了之前有效的预训练任务。
其次3.0版本提出了海量无监督文本与大规模知识图谱的平行预训练方法 (Universal Knowledge-Text Prediction)。将5千万知识图谱三元组与4TB大规模语料中相关的文本组成pair,同时输入到预训练模型之中进行联合掩码训练:
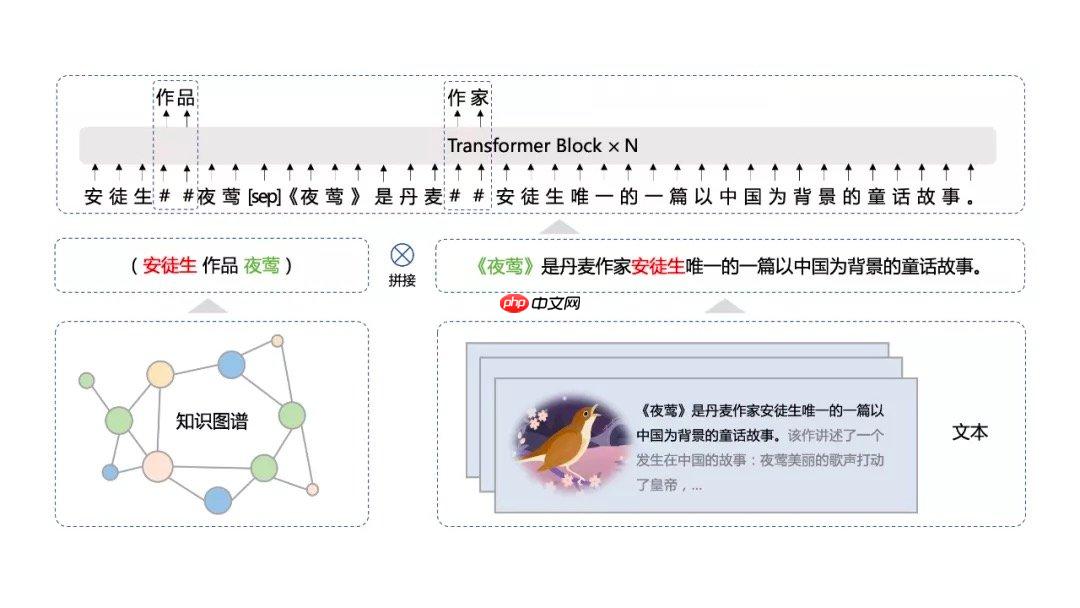
语料库 4TB,我的天!!!

结构上,ERNIE 3.0框架分为两层。第一层是通用语义表示网络,该网络学习数据中的基础和通用的知识。第二层是任务语义表示网络,该网络基于通用语义表示,学习任务相关的知识。在学习过程中,任务语义表示网络只学习对应类别的预训练任务,而通用语义表示网络会学习所有的预训练任务。
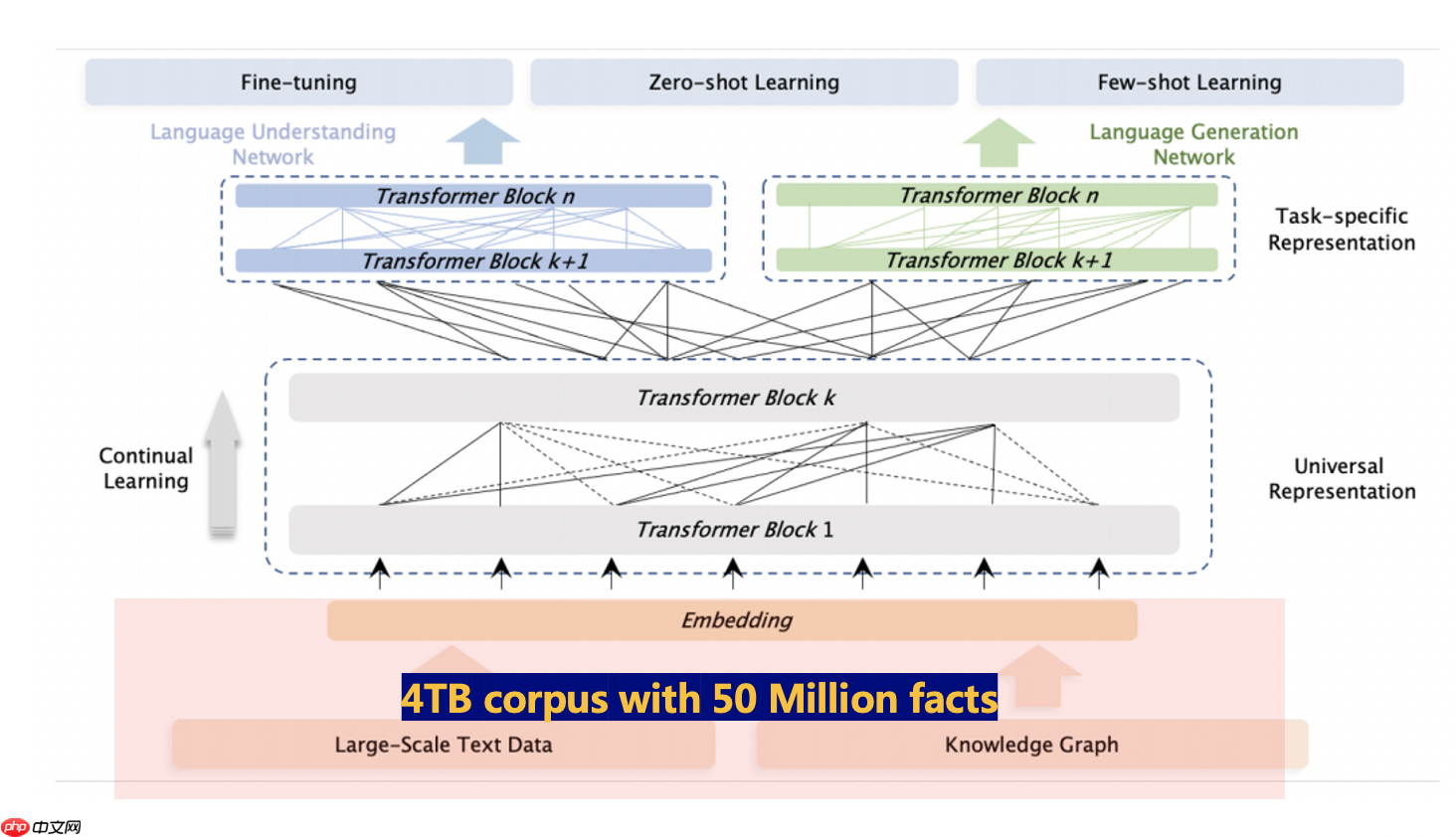
本项目使用 3.0 版本预训练模型。
4. 解题思路
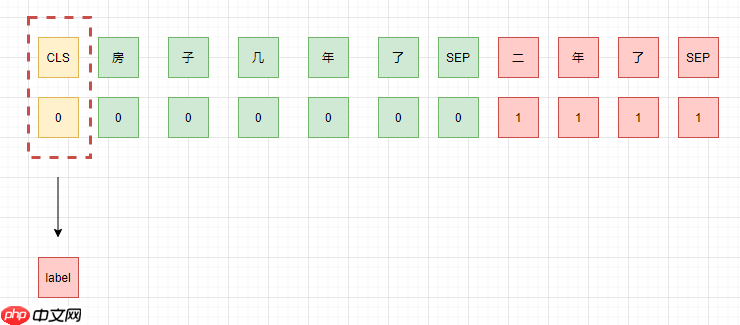
- 由于回答是不连续的,所以可以将问题和答案一一对应,组成 query-reply-pair,然后进行文本分类,分别判断是否是针对问题的回答。
- 虽然对话是不连续的,但是是同一个对话,不同的回答可能相互支撑,提供部分信息,所以,第二种思路就是将同一个问题的所有回答都拼接在当前回答后面,然后同时对每一个回答进行判断。
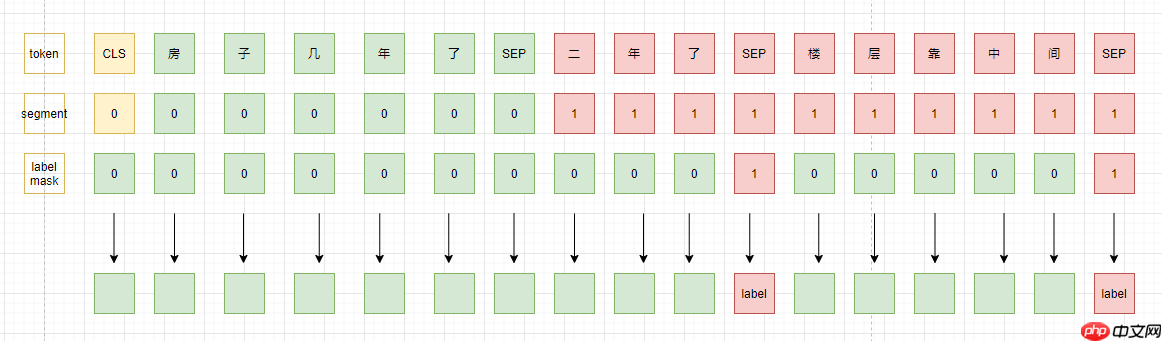
在思路 2 的基础上,还可以把 [CLS] 对应的输出拿出来,预测所有候选 reply 中是否存在可以匹配的回答。
本项目采用思路 1 作为 baseline 。
5. Talk is cheap, show me the code
首先安装最新版本的 paddlenlp
!pip install paddlenlp --upgrade
上述安装过程可能会报错,大概是parl包的版本依赖问题,对于本项目来说无伤大雅。
训练、测试代码都写在 query_reply_pair.py 文件中,有详细注释。
注意:
- 你可能需要在 main() 中的 args 列表下,修改训练参数。
- 为了便于展示结果,避免输出信息过长,下面的结果是在 num_train_epochs = 0.5 的参数下输出的,为了更好的结果,这里可能需要修改,项目开头展示的成绩是 num_train_epochs = 5.0 的结果。
运行脚本:
!python query_reply_pair.py
[2022-06-22 10:04:10,523] [ INFO] - using `logging_steps` to initialize `eval_steps` to 100[2022-06-22 10:04:10,523] [ INFO] - ============================================================[2022-06-22 10:04:10,523] [ INFO] - Model Configuration Arguments
[2022-06-22 10:04:10,523] [ INFO] - paddle commit id :590b4dbcdd989324089ce43c22ef151c746c92a3[2022-06-22 10:04:10,523] [ INFO] - export_model_dir :None[2022-06-22 10:04:10,523] [ INFO] - model_name_or_path :ernie-3.0-medium-zh[2022-06-22 10:04:10,524] [ INFO] -
[2022-06-22 10:04:10,524] [ INFO] - ============================================================[2022-06-22 10:04:10,524] [ INFO] - Data Configuration Arguments
[2022-06-22 10:04:10,524] [ INFO] - paddle commit id :590b4dbcdd989324089ce43c22ef151c746c92a3[2022-06-22 10:04:10,524] [ INFO] - max_seq_length :128[2022-06-22 10:04:10,524] [ INFO] - test_query_path :data/test/test.query.tsv[2022-06-22 10:04:10,524] [ INFO] - test_reply_path :data/test/test.reply.tsv[2022-06-22 10:04:10,524] [ INFO] - train_query_path :data/train/train.query.tsv[2022-06-22 10:04:10,524] [ INFO] - train_reply_path :data/train/train.reply.tsv[2022-06-22 10:04:10,524] [ INFO] -
raw train dataset example: {'query': '东区西区?什么时候下证?', 'reply': '我在给你发套'}.[2022-06-22 10:04:11,911] [ INFO] - We are using to load 'ernie-3.0-medium-zh'.[2022-06-22 10:04:11,911] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-3.0-medium-zh/ernie_3.0_medium_zh_vocab.txt[2022-06-22 10:04:11,934] [ INFO] - We are using to load 'ernie-3.0-medium-zh'.[2022-06-22 10:04:11,934] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-3.0-medium-zh/ernie_3.0_medium_zh.pdparams
W0622 10:04:11.936193 1093 gpu_context.cc:278] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0622 10:04:11.939395 1093 gpu_context.cc:306] device: 0, cuDNN Version: 7.6.
feature train dataset example: {'input_ids': [1, 481, 1535, 7, 96, 10, 59, 225, 940, 2, 1852, 404, 99, 481, 1535, 131, 7, 96, 18, 958, 409, 2485, 225, 121, 4, 1852, 404, 99, 958, 409, 102, 257, 79, 412, 18, 225, 12043, 2], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'label': 1}.[2022-06-22 10:04:16,960] [ INFO] - ============================================================[2022-06-22 10:04:16,960] [ INFO] - Training Configuration Arguments
[2022-06-22 10:04:16,960] [ INFO] - paddle commit id :590b4dbcdd989324089ce43c22ef151c746c92a3[2022-06-22 10:04:16,961] [ INFO] - _no_sync_in_gradient_accumulation:True[2022-06-22 10:04:16,961] [ INFO] - adam_beta1 :0.9[2022-06-22 10:04:16,961] [ INFO] - adam_beta2 :0.999[2022-06-22 10:04:16,961] [ INFO] - adam_epsilon :1e-08[2022-06-22 10:04:16,961] [ INFO] - current_device :gpu:0[2022-06-22 10:04:16,961] [ INFO] - dataloader_drop_last :False[2022-06-22 10:04:16,961] [ INFO] - dataloader_num_workers :4[2022-06-22 10:04:16,961] [ INFO] - device :gpu[2022-06-22 10:04:16,961] [ INFO] - disable_tqdm :False[2022-06-22 10:04:16,961] [ INFO] - do_eval :True[2022-06-22 10:04:16,961] [ INFO] - do_export :False[2022-06-22 10:04:16,961] [ INFO] - do_predict :True[2022-06-22 10:04:16,961] [ INFO] - do_train :True[2022-06-22 10:04:16,961] [ INFO] - eval_batch_size :128[2022-06-22 10:04:16,961] [ INFO] - eval_steps :100[2022-06-22 10:04:16,961] [ INFO] - evaluation_strategy :IntervalStrategy.STEPS[2022-06-22 10:04:16,961] [ INFO] - fp16 :False[2022-06-22 10:04:16,961] [ INFO] - fp16_opt_level :O1[2022-06-22 10:04:16,961] [ INFO] - gradient_accumulation_steps :1[2022-06-22 10:04:16,961] [ INFO] - greater_is_better :True[2022-06-22 10:04:16,962] [ INFO] - ignore_data_skip :False[2022-06-22 10:04:16,962] [ INFO] - label_names :None[2022-06-22 10:04:16,962] [ INFO] - learning_rate :5e-05[2022-06-22 10:04:16,962] [ INFO] - load_best_model_at_end :True[2022-06-22 10:04:16,962] [ INFO] - local_process_index :0[2022-06-22 10:04:16,962] [ INFO] - local_rank :-1[2022-06-22 10:04:16,962] [ INFO] - log_level :-1[2022-06-22 10:04:16,962] [ INFO] - log_level_replica :-1[2022-06-22 10:04:16,962] [ INFO] - log_on_each_node :True[2022-06-22 10:04:16,962] [ INFO] - logging_dir :work/query_reply_pair/runs/Jun22_10-04-10_jupyter-532817-4195533[2022-06-22 10:04:16,962] [ INFO] - logging_first_step :False[2022-06-22 10:04:16,962] [ INFO] - logging_steps :100[2022-06-22 10:04:16,962] [ INFO] - logging_strategy :IntervalStrategy.STEPS[2022-06-22 10:04:16,962] [ INFO] - lr_scheduler_type :SchedulerType.LINEAR[2022-06-22 10:04:16,962] [ INFO] - max_grad_norm :1.0[2022-06-22 10:04:16,962] [ INFO] - max_steps :-1[2022-06-22 10:04:16,962] [ INFO] - metric_for_best_model :accuracy[2022-06-22 10:04:16,962] [ INFO] - minimum_eval_times :None[2022-06-22 10:04:16,962] [ INFO] - no_cuda :False[2022-06-22 10:04:16,962] [ INFO] - num_train_epochs :0.5[2022-06-22 10:04:16,962] [ INFO] - optim :OptimizerNames.ADAMW[2022-06-22 10:04:16,962] [ INFO] - output_dir :work/query_reply_pair/test[2022-06-22 10:04:16,962] [ INFO] - overwrite_output_dir :False[2022-06-22 10:04:16,962] [ INFO] - past_index :-1[2022-06-22 10:04:16,962] [ INFO] - per_device_eval_batch_size :128[2022-06-22 10:04:16,962] [ INFO] - per_device_train_batch_size :128[2022-06-22 10:04:16,963] [ INFO] - prediction_loss_only :False[2022-06-22 10:04:16,963] [ INFO] - process_index :0[2022-06-22 10:04:16,963] [ INFO] - remove_unused_columns :True[2022-06-22 10:04:16,963] [ INFO] - report_to :['visualdl'][2022-06-22 10:04:16,963] [ INFO] - resume_from_checkpoint :None[2022-06-22 10:04:16,963] [ INFO] - run_name :test[2022-06-22 10:04:16,963] [ INFO] - save_on_each_node :False[2022-06-22 10:04:16,963] [ INFO] - save_steps :100[2022-06-22 10:04:16,963] [ INFO] - save_strategy :IntervalStrategy.STEPS[2022-06-22 10:04:16,963] [ INFO] - save_total_limit :2[2022-06-22 10:04:16,963] [ INFO] - scale_loss :32768[2022-06-22 10:04:16,963] [ INFO] - seed :42[2022-06-22 10:04:16,963] [ INFO] - should_log :True[2022-06-22 10:04:16,963] [ INFO] - should_save :True[2022-06-22 10:04:16,963] [ INFO] - train_batch_size :128[2022-06-22 10:04:16,963] [ INFO] - warmup_ratio :0.0[2022-06-22 10:04:16,963] [ INFO] - warmup_steps :0[2022-06-22 10:04:16,963] [ INFO] - weight_decay :0.0[2022-06-22 10:04:16,963] [ INFO] - world_size :1[2022-06-22 10:04:16,963] [ INFO] -
[2022-06-22 10:04:16,964] [ INFO] - ***** Running training *****[2022-06-22 10:04:16,965] [ INFO] - Num examples = 17268[2022-06-22 10:04:16,965] [ INFO] - Num Epochs = 1[2022-06-22 10:04:16,965] [ INFO] - Instantaneous batch size per device = 128[2022-06-22 10:04:16,965] [ INFO] - Total train batch size (w. parallel, distributed & accumulation) = 128[2022-06-22 10:04:16,965] [ INFO] - Gradient Accumulation steps = 1[2022-06-22 10:04:16,965] [ INFO] - Total optimization steps = 67.5[2022-06-22 10:04:16,965] [ INFO] - Total num train samples = 8634.0
100%|███████████████████████████████████████████| 67/67 [00:17<00:00, 4.40it/s][2022-06-22 10:04:34,326] [ INFO] -
Training completed.
{'train_runtime': 17.4487, 'train_samples_per_second': 494.821, 'train_steps_per_second': 3.84, 'train_loss': 0.352832708785783, 'epoch': 0.4963}
100%|███████████████████████████████████████████| 67/67 [00:17<00:00, 3.84it/s][2022-06-22 10:04:34,416] [ INFO] - Saving model checkpoint to work/query_reply_pair/test[2022-06-22 10:04:36,894] [ INFO] - tokenizer config file saved in work/query_reply_pair/test/tokenizer_config.json[2022-06-22 10:04:36,895] [ INFO] - Special tokens file saved in work/query_reply_pair/test/special_tokens_map.json
***** train metrics *****
epoch = 0.4963
train_loss = 0.3528
train_runtime = 0:00:17.44
train_samples_per_second = 494.821
train_steps_per_second = 3.84[2022-06-22 10:04:36,898] [ INFO] - ***** Running Evaluation *****[2022-06-22 10:04:36,898] [ INFO] - Num examples = 4317[2022-06-22 10:04:36,898] [ INFO] - Pre device batch size = 128[2022-06-22 10:04:36,898] [ INFO] - Total Batch size = 128[2022-06-22 10:04:36,898] [ INFO] - Total prediction steps = 34
100%|███████████████████████████████████████████| 34/34 [00:02<00:00, 12.31it/s]
***** eval metrics *****
epoch = 0.4963
eval_accuracy = 0.8826
eval_loss = 0.283
eval_runtime = 0:00:03.21
eval_samples_per_second = 1344.038
eval_steps_per_second = 10.585[2022-06-22 10:04:40,112] [ INFO] - ***** Running Prediction *****[2022-06-22 10:04:40,112] [ INFO] - Num examples = 53757[2022-06-22 10:04:40,112] [ INFO] - Pre device batch size = 128[2022-06-22 10:04:40,112] [ INFO] - Total Batch size = 128[2022-06-22 10:04:40,112] [ INFO] - Total prediction steps = 420
100%|█████████████████████████████████████████| 420/420 [00:51<00:00, 11.37it/s]***** test metrics *****
test_runtime = 0:00:52.06
test_samples_per_second = 1032.496
test_steps_per_second = 8.067
100%|█████████████████████████████████████████| 420/420 [00:52<00:00, 7.95it/s]
训练结果可视化:
点击页面最左侧一列菜单栏中的 数据模型可视化 ,添加 logdir 然后启动服务,就可以看到训练过程的 loss 曲线等信息。
log 文件会保存在类似 work/query_reply_pair/runs/Jun22_10-01-49_jupyter-532817-4195533 这样的路径下面。
由于上面训练过程只跑了 0.5 个 epoch,曲线基本只有一个点,这里就不进行展示了。
测试集预测结果保存在 work/query_reply_pair/test/test_labels.tsv 文件中,你可以直接点开看一下结果。
import pandas as pd file_path = "work/query_reply_pair/test/test_labels.tsv"df = pd.read_csv(file_path, sep='\t') df.head()
query reply label 0 东区西区?什么时候下证? 我在给你发套 0 1 东区西区?什么时候下证? 您看下我发的这几套 0 2 东区西区?什么时候下证? 这两套也是金源花园的 0 3 东区西区?什么时候下证? 价钱低 0 4 东区西区?什么时候下证? 便宜的房子,一般都是顶楼 0
生成竞赛提交文件:
import pandas as pd sample_submit_path = "data/data144231/sample_submission.tsv"submit_path = "submit.tsv"submit = pd.read_csv(sample_submit_path, sep='\t', header=None) submit.columns = ['query_id', 'reply_id', 'label'] test_labels = pd.read_csv(file_path, sep='\t') label = test_labels['label'] submit['label'] = label submit.to_csv(submit_path, sep='\t', header=None, index=None)
根目录下 submit.tsv 文件就可以拿去提交啦,提交大概 0.75+ 的分数 (num_train_epochs = 5.0 的情况下)。



























