本文介绍基于ERNIE-Gram模型实现语义匹配的案例。以LCQMC数据集为例,说明文本语义匹配任务,即判断两段文本语义是否相似。还讲解了数据加载、预处理、模型搭建、训练、评估和预测的过程,以及PaddleNLP的相关数据集和数据API的使用。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

本案例介绍 NLP 最基本的任务类型之一 —— 文本语义匹配,并且基于 PaddleNLP 使用百度开源的预训练模型 ERNIE1.0 为基础训练效果优异的语义匹配模型,来判断 2 个文本语义是否相同。
文本语义匹配任务,简单来说就是给定两段文本的相,让模型来判断两段文本是不是语义相似。
在本案例中以权威的语义匹配数据集 LCQMC 为例,LCQMC 数据集是基于百度知道相似问题推荐构造的通问句语义匹配数据集。训练集中的每两段文本都会被标记为 1(语义相似) 或者 0(语义不相似)
例如百度知道场景下,用户搜索一个问题,模型会计算这个问题与候选问题是否语义相似,语义匹配模型会找出与问题语义相似的候选问题返回给用户,避免用户重复提问。例如,当某用户在搜索引擎中搜索 “深度学习的教材有哪些?”,模型就自动找到了一些语义相似的问题展现给用户: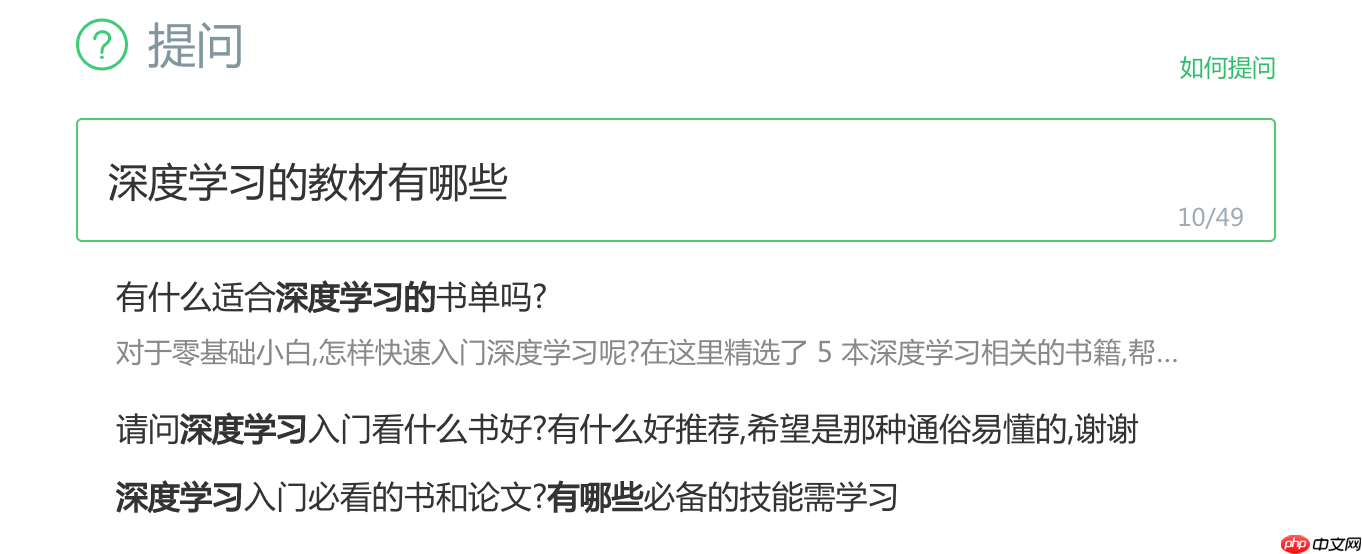
介绍如何准备数据,基于 ERNIE-Gram 模型进行匹配网络大家,然后快速进行语义匹配模型的训练、评估和预测。
为了训练匹配模型,一般需要准备三个数据集:训练集 train.tsv、验证集dev.tsv、测试集test.tsv。此案例我们使用 PaddleNLP 内置的语义数据集 LCQMC 来进行训练、评估、预测。
训练集: 用来训练模型参数的数据集,模型直接根据训练集来调整自身参数以获得更好的分类效果。
验证集: 用于在训练过程中检验模型的状态,收敛情况。验证集通常用于调整超参数,根据几组模型验证集上的表现决定哪组超参数拥有最好的性能。
测试集: 用来计算模型的各项评估指标,验证模型泛化能力。
LCQMC 数据集是公开的语义匹配权威数据集。PaddleNLP 已经内置该数据集,一键即可加载。
# 正式开始实验之前首先通过如下命令安装最新版本的 paddlenlp!python -m pip install --upgrade paddlenlp==2.0.2 -i https://pypi.org/simple
import timeimport osimport numpy as npimport paddleimport paddle.nn.functional as Ffrom paddlenlp.datasets import load_datasetimport paddlenlp# 一键加载 Lcqmc 的训练集、验证集train_ds, dev_ds = load_dataset("lcqmc", splits=["train", "dev"])# paddlenlp 会自动下载 lcqmc 数据集解压到 "${HOME}/.paddlenlp/datasets/LCQMC/lcqmc/lcqmc/" 目录下! ls ${HOME}/.paddlenlp/datasets/LCQMC/lcqmc/lcqmcprint(paddlenlp.__version__)# 输出训练集的前 20 条样本for idx, example in enumerate(train_ds): if idx <= 20: print(example)
通过 paddlenlp 加载进来的 LCQMC 数据集是原始的明文数据集,这部分我们来实现组 batch、tokenize 等预处理逻辑,将原始明文数据转换成网络训练的输入数据
# 因为是基于预训练模型 ERNIE-Gram 来进行,所以需要首先加载 ERNIE-Gram 的 tokenizer,# 后续样本转换函数基于 tokenizer 对文本进行切分tokenizer = paddlenlp.transformers.ErnieGramTokenizer.from_pretrained('ernie-gram-zh')# 将 1 条明文数据的 query、title 拼接起来,根据预训练模型的 tokenizer 将明文转换为 ID 数据# 返回 input_ids 和 token_type_idsdef convert_example(example, tokenizer, max_seq_length=512, is_test=False):
query, title = example["query"], example["title"]
encoded_inputs = tokenizer(
text=query, text_pair=title, max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"] if not is_test:
label = np.array([example["label"]], dtype="int64") return input_ids, token_type_ids, label # 在预测或者评估阶段,不返回 label 字段
else: return input_ids, token_type_ids### 对训练集的第 1 条数据进行转换input_ids, token_type_ids, label = convert_example(train_ds[0], tokenizer)
print(input_ids)
print(token_type_ids)
print(label)
# 为了后续方便使用,我们给 convert_example 赋予一些默认参数from functools import partial# 训练集和验证集的样本转换函数trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=512)上一小节,我们完成了对单条样本的转换,本节我们需要将样本组合成 Batch 数据,对于不等长的数据还需要进行 Padding 操作,便于 GPU 训练。
PaddleNLP 提供了许多关于 NLP 任务中构建有效的数据 pipeline 的常用 API
| API | 简介 |
|---|---|
| paddlenlp.data.Stack | 堆叠N个具有相同shape的输入数据来构建一个batch |
| paddlenlp.data.Pad | 将长度不同的多个句子padding到统一长度,取N个输入数据中的最大长度 |
| paddlenlp.data.Tuple | 将多个batchify函数包装在一起 |
更多数据处理操作详见: https://github.com/PaddlePaddle/models/blob/release/2.0-beta/PaddleNLP/docs/data.md
from paddlenlp.data import Stack, Pad, Tuplea = [1, 2, 3, 4]
b = [3, 4, 5, 6]
c = [5, 6, 7, 8]
result = Stack()([a, b, c])print("Stacked Data: \n", result)print()
a = [1, 2, 3, 4]
b = [5, 6, 7]
c = [8, 9]
result = Pad(pad_val=0)([a, b, c])print("Padded Data: \n", result)print()
data = [
[[1, 2, 3, 4], [1]],
[[5, 6, 7], [0]],
[[8, 9], [1]],
]
batchify_fn = Tuple(Pad(pad_val=0), Stack())
ids, labels = batchify_fn(data)print("ids: \n", ids)print()print("labels: \n", labels)print()# 我们的训练数据会返回 input_ids, token_type_ids, labels 3 个字段# 因此针对这 3 个字段需要分别定义 3 个组 batch 操作batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack(dtype="int64") # label): [data for data in fn(samples)]下面我们基于组 batchify_fn 函数和样本转换函数 trans_func 来构造训练集的 DataLoader, 支持多卡训练
# 定义分布式 Sampler: 自动对训练数据进行切分,支持多卡并行训练batch_sampler = paddle.io.DistributedBatchSampler(train_ds, batch_size=32, shuffle=True)# 基于 train_ds 定义 train_data_loader# 因为我们使用了分布式的 DistributedBatchSampler, train_data_loader 会自动对训练数据进行切分train_data_loader = paddle.io.DataLoader(
dataset=train_ds.map(trans_func),
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)# 针对验证集数据加载,我们使用单卡进行评估,所以采用 paddle.io.BatchSampler 即可# 定义 dev_data_loaderbatch_sampler = paddle.io.BatchSampler(dev_ds, batch_size=32, shuffle=False)
dev_data_loader = paddle.io.DataLoader(
dataset=dev_ds.map(trans_func),
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)自从 2018 年 10 月以来,NLP 个领域的任务都通过 Pretrain + Finetune 的模式相比传统 DNN 方法在效果上取得了显著的提升,本节我们以百度开源的预训练模型 ERNIE-Gram 为基础模型,在此之上构建 Point-wise 语义匹配网络。
首先我们来定义网络结构:
import paddle.nn as nn# 我们基于 ERNIE-Gram 模型结构搭建 Point-wise 语义匹配网络# 所以此处先定义 ERNIE-Gram 的 pretrained_modelpretrained_model = paddlenlp.transformers.ErnieGramModel.from_pretrained('ernie-gram-zh')#pretrained_model = paddlenlp.transformers.ErnieModel.from_pretrained('ernie-1.0')class PointwiseMatching(nn.Layer):
# 此处的 pretained_model 在本例中会被 ERNIE-Gram 预训练模型初始化
def __init__(self, pretrained_model, dropout=None):
super().__init__()
self.ptm = pretrained_model
self.dropout = nn.Dropout(dropout if dropout is not None else 0.1) # 语义匹配任务: 相似、不相似 2 分类任务
self.classifier = nn.Linear(self.ptm.config["hidden_size"], 2) def forward(self,
input_ids,
token_type_ids=None,
position_ids=None,
attention_mask=None):
# 此处的 Input_ids 由两条文本的 token ids 拼接而成
# token_type_ids 表示两段文本的类型编码
# 返回的 cls_embedding 就表示这两段文本经过模型的计算之后而得到的语义表示向量
_, cls_embedding = self.ptm(input_ids, token_type_ids, position_ids,
attention_mask)
cls_embedding = self.dropout(cls_embedding) # 基于文本对的语义表示向量进行 2 分类任务
logits = self.classifier(cls_embedding)
probs = F.softmax(logits) return probs# 定义 Point-wise 语义匹配网络model = PointwiseMatching(pretrained_model)from paddlenlp.transformers import LinearDecayWithWarmup
epochs = 3num_training_steps = len(train_data_loader) * epochs# 定义 learning_rate_scheduler,负责在训练过程中对 lr 进行调度lr_scheduler = LinearDecayWithWarmup(5E-5, num_training_steps, 0.0)# Generate parameter names needed to perform weight decay.# All bias and LayerNorm parameters are excluded.decay_params = [
p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])
]# 定义 Optimizeroptimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=0.0,
apply_decay_param_fun=lambda x: x in decay_params)# 采用交叉熵 损失函数criterion = paddle.nn.loss.CrossEntropyLoss()# 评估的时候采用准确率指标metric = paddle.metric.Accuracy()# 因为训练过程中同时要在验证集进行模型评估,因此我们先定义评估函数@paddle.no_grad()def evaluate(model, criterion, metric, data_loader, phase="dev"):
model.eval()
metric.reset()
losses = [] for batch in data_loader:
input_ids, token_type_ids, labels = batch
probs = model(input_ids=input_ids, token_type_ids=token_type_ids)
loss = criterion(probs, labels)
losses.append(loss.numpy())
correct = metric.compute(probs, labels)
metric.update(correct)
accu = metric.accumulate() print("eval {} loss: {:.5}, accu: {:.5}".format(phase,
np.mean(losses), accu))
model.train()
metric.reset()# 接下来,开始正式训练模型global_step = 0tic_train = time.time()for epoch in range(1, epochs + 1): for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch
probs = model(input_ids=input_ids, token_type_ids=token_type_ids)
loss = criterion(probs, labels)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
# 每间隔 10 step 输出训练指标
if global_step % 10 == 0: print( "global step %d, epoch: %d, batch: %d, loss: %.5f, accu: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc, 10 / (time.time() - tic_train)))
tic_train = time.time()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad() # 每间隔 100 step 在验证集和测试集上进行评估
if global_step % 100 == 0:
evaluate(model, criterion, metric, dev_data_loader, "dev")
# 训练结束后,存储模型参数save_dir = os.path.join("checkpoint", "model_%d" % global_step)
os.makedirs(save_dir)
save_param_path = os.path.join(save_dir, 'model_state.pdparams')
paddle.save(model.state_dict(), save_param_path)
tokenizer.save_pretrained(save_dir)模型训练过程中会输出如下日志:
global step 5310, epoch: 3, batch: 1578, loss: 0.31671, accu: 0.95000, speed: 0.63 step/sglobal step 5320, epoch: 3, batch: 1588, loss: 0.36240, accu: 0.94063, speed: 6.98 step/sglobal step 5330, epoch: 3, batch: 1598, loss: 0.41451, accu: 0.93854, speed: 7.40 step/sglobal step 5340, epoch: 3, batch: 1608, loss: 0.31327, accu: 0.94063, speed: 7.01 step/sglobal step 5350, epoch: 3, batch: 1618, loss: 0.40664, accu: 0.93563, speed: 7.83 step/sglobal step 5360, epoch: 3, batch: 1628, loss: 0.33064, accu: 0.93958, speed: 7.34 step/sglobal step 5370, epoch: 3, batch: 1638, loss: 0.38411, accu: 0.93795, speed: 7.72 step/sglobal step 5380, epoch: 3, batch: 1648, loss: 0.35376, accu: 0.93906, speed: 7.92 step/sglobal step 5390, epoch: 3, batch: 1658, loss: 0.39706, accu: 0.93924, speed: 7.47 step/sglobal step 5400, epoch: 3, batch: 1668, loss: 0.41198, accu: 0.93781, speed: 7.41 step/seval dev loss: 0.4177, accu: 0.89082global step 5410, epoch: 3, batch: 1678, loss: 0.34453, accu: 0.93125, speed: 0.63 step/sglobal step 5420, epoch: 3, batch: 1688, loss: 0.34569, accu: 0.93906, speed: 7.75 step/sglobal step 5430, epoch: 3, batch: 1698, loss: 0.39160, accu: 0.92917, speed: 7.54 step/sglobal step 5440, epoch: 3, batch: 1708, loss: 0.46002, accu: 0.93125, speed: 7.05 step/sglobal step 5450, epoch: 3, batch: 1718, loss: 0.32302, accu: 0.93188, speed: 7.14 step/sglobal step 5460, epoch: 3, batch: 1728, loss: 0.40802, accu: 0.93281, speed: 7.22 step/sglobal step 5470, epoch: 3, batch: 1738, loss: 0.34607, accu: 0.93348, speed: 7.44 step/sglobal step 5480, epoch: 3, batch: 1748, loss: 0.34709, accu: 0.93398, speed: 7.38 step/sglobal step 5490, epoch: 3, batch: 1758, loss: 0.31814, accu: 0.93437, speed: 7.39 step/sglobal step 5500, epoch: 3, batch: 1768, loss: 0.42689, accu: 0.93125, speed: 7.74 step/seval dev loss: 0.41789, accu: 0.88968
接下来我们使用已经训练好的语义匹配模型对一些预测数据进行预测。待预测数据为每行都是文本对的 tsv 文件,我们使用 Lcqmc 数据集的测试集作为我们的预测数据,进行预测并提交预测结果到 千言文本相似度竞赛
下载我们已经训练好的语义匹配模型, 并解压
# 下载我们基于 Lcqmc 事先训练好的语义匹配模型并解压! wget https://paddlenlp.bj.bcebos.com/models/text_matching/ernie_gram_zh_pointwise_matching_model.tar ! tar -xvf ernie_gram_zh_pointwise_matching_model.tar
# 测试数据由 2 列文本构成 tab 分隔# Lcqmc 默认下载到如下路径! head -n10 "${HOME}/.paddlenlp/datasets/LCQMC/lcqmc/lcqmc/test.tsv"def predict(model, data_loader):
batch_probs = [] # 预测阶段打开 eval 模式,模型中的 dropout 等操作会关掉
model.eval() with paddle.no_grad(): for batch_data in data_loader:
input_ids, token_type_ids = batch_data
input_ids = paddle.to_tensor(input_ids)
token_type_ids = paddle.to_tensor(token_type_ids)
# 获取每个样本的预测概率: [batch_size, 2] 的矩阵
batch_prob = model(
input_ids=input_ids, token_type_ids=token_type_ids).numpy()
batch_probs.append(batch_prob)
batch_probs = np.concatenate(batch_probs, axis=0) return batch_probs# 预测数据的转换函数# predict 数据没有 label, 因此 convert_exmaple 的 is_test 参数设为 Truetrans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=512,
is_test=True)# 预测数据的组 batch 操作# predict 数据只返回 input_ids 和 token_type_ids,因此只需要 2 个 Pad 对象作为 batchify_fnbatchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment_ids): [data for data in fn(samples)]# 加载预测数据test_ds = load_dataset("lcqmc", splits=["test"])batch_sampler = paddle.io.BatchSampler(test_ds, batch_size=32, shuffle=False)# 生成预测数据 data_loaderpredict_data_loader =paddle.io.DataLoader(
dataset=test_ds.map(trans_func),
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)pretrained_model = paddlenlp.transformers.ErnieGramModel.from_pretrained('ernie-gram-zh')
model = PointwiseMatching(pretrained_model)# 刚才下载的模型解压之后存储路径为 ./ernie_gram_zh_pointwise_matching_model/model_state.pdparamsstate_dict = paddle.load("./ernie_gram_zh_pointwise_matching_model/model_state.pdparams")# 刚才下载的模型解压之后存储路径为 ./pointwise_matching_model/ernie1.0_base_pointwise_matching.pdparams# state_dict = paddle.load("pointwise_matching_model/ernie1.0_base_pointwise_matching.pdparams")model.set_dict(state_dict)for idx, batch in enumerate(predict_data_loader): if idx < 1: print(batch)
# 执行预测函数y_probs = predict(model, predict_data_loader)# 根据预测概率获取预测 labely_preds = np.argmax(y_probs, axis=1)
# 我们按照千言文本相似度竞赛的提交格式将预测结果存储在 lcqmc.tsv 中,用来后续提交# 同时将预测结果输出到终端,便于大家直观感受模型预测效果test_ds = load_dataset("lcqmc", splits=["test"])with open("lcqmc.tsv", 'w', encoding="utf-8") as f:
f.write("index\tprediction\n")
for idx, y_pred in enumerate(y_preds):
f.write("{}\t{}\n".format(idx, y_pred))
text_pair = test_ds[idx]
text_pair["label"] = y_pred print(text_pair)千言文本相似度竞赛一共有 3 个数据集: lcqmc、bq_corpus、paws-x, 我们刚才生成了 lcqmc 的预测结果 lcqmc.tsv, 同时我们在项目内提供了 bq_corpus、paw-x 数据集的空预测结果,我们将这 3 个文件打包提交到千言文本相似度竞赛,即可看到自己的模型在 Lcqmc 数据集上的竞赛成绩。
# 打包预测结果!zip submit.zip lcqmc.tsv paws-x.tsv bq_corpus.tsv
PaddleNLP提供了以下数据集的快速读取API,实际使用时请根据需要添加splits信息:
| 数据集名称 | 简介 | 调用方法 |
|---|---|---|
| SQuAD | 斯坦福问答数据集,包括SQuAD1.1和SQuAD2.0 | paddlenlp.datasets.load_dataset('squad') |
| DuReader-yesno | 千言数据集:阅读理解,判断答案极性 | paddlenlp.datasets.load_dataset('dureader_yesno') |
| DuReader-robust | 千言数据集:阅读理解,答案原文抽取 | paddlenlp.datasets.load_dataset('dureader_robust') |
| CMRC2018 | 第二届“讯飞杯”中文机器阅读理解评测数据集 | paddlenlp.datasets.load_dataset('cmrc2018') |
| DRCD | 台達閱讀理解資料集 | paddlenlp.datasets.load_dataset('drcd') |
| 数据集名称 | 简介 | 调用方法 |
|---|---|---|
| CoLA | 单句分类任务,二分类,判断句子是否合法 | paddlenlp.datasets.load_dataset('glue','cola') |
| SST-2 | 单句分类任务,二分类,判断句子情感极性 | paddlenlp.datasets.load_dataset('glue','sst-2') |
| MRPC | 句对匹配任务,二分类,判断句子对是否是相同意思 | paddlenlp.datasets.load_dataset('glue','mrpc') |
| STSB | 计算句子对相似性,分数为1~5 | paddlenlp.datasets.load_dataset('glue','sts-b') |
| QQP | 判定句子对是否等效,等效、不等效两种情况,二分类任务 | paddlenlp.datasets.load_dataset('glue','qqp') |
| MNLI | 句子对,一个前提,一个是假设。前提和假设的关系有三种情况:蕴含(entailment),矛盾(contradiction),中立(neutral)。句子对三分类问题 | paddlenlp.datasets.load_dataset('glue','mnli') |
| QNLI | 判断问题(question)和句子(sentence)是否蕴含,蕴含和不蕴含,二分类 | paddlenlp.datasets.load_dataset('glue','qnli') |
| RTE | 判断句对是否蕴含,句子1和句子2是否互为蕴含,二分类任务 | paddlenlp.datasets.load_dataset('glue','rte') |
| WNLI | 判断句子对是否相关,相关或不相关,二分类任务 | paddlenlp.datasets.load_dataset('glue','wnli') |
| LCQMC | A Large-scale Chinese Question Matching Corpus 语义匹配数据集 | paddlenlp.datasets.load_dataset('lcqmc') |
| ChnSentiCorp | 中文评论情感分析语料 | paddlenlp.datasets.load_dataset('chnsenticorp') |
| 数据集名称 | 简介 | 调用方法 |
|---|---|---|
| MSRA_NER | MSRA 命名实体识别数据集 | paddlenlp.datasets.load_dataset('msra_ner') |
| People's Daily | 人民日报命名实体识别数据集 | paddlenlp.datasets.load_dataset('peoples_daily_ner') |
| 数据集名称 | 简介 | 调用方法 |
|---|---|---|
| IWSLT15 | IWSLT'15 English-Vietnamese data 英语-越南语翻译数据集 | paddlenlp.datasets.load_dataset('iwslt15') |
| WMT14ENDE | WMT14 EN-DE 经过BPE分词的英语-德语翻译数据集 | paddlenlp.datasets.load_dataset('wmt14ende') |
| 数据集名称 | 简介 | 调用方法 |
|---|---|---|
| BSTC | 千言数据集:机器同传,包括transcription_translation和asr | paddlenlp.datasets.load_dataset('bstc', 'asr') |
| 数据集名称 | 简介 | 调用方法 |
|---|---|---|
| Poetry | 中文诗歌古典文集数据 | paddlenlp.datasets.load_dataset('poetry') |
| Couplet | 中文对联数据集 | paddlenlp.datasets.load_dataset('couplet') |
| 数据集名称 | 简介 | 调用方法 |
|---|---|---|
| PTB | Penn Treebank Dataset | paddlenlp.datasets.load_dataset('ptb') |
| Yahoo Answer 100k | 从Yahoo Answer采样100K | paddlenlp.datasets.load_dataset('yahoo_answer_100k') |
| API | 简介 |
|---|---|
| paddlenlp.data.Stack | 堆叠N个具有相同shape的输入数据来构建一个batch |
| paddlenlp.data.Pad | 堆叠N个输入数据来构建一个batch,每个输入数据将会被padding到N个输入数据中最大的长度 |
| paddlenlp.data.Tuple | 将多个batchify函数包装在一起,组成tuple |
| paddlenlp.data.Dict | 将多个batchify函数包装在一起,组成dict |
| paddlenlp.data.SamplerHelper | 构建用于Dataloader的可迭代sampler |
| paddlenlp.data.Vocab | 用于文本token和ID之间的映射 |
| paddlenlp.data.JiebaTokenizer | Jieba分词 |
以上API都是用来辅助构建DataLoader,DataLoader比较重要的三个初始化参数是dataset、batch_sampler和collate_fn。
paddlenlp.data.Vocab和paddlenlp.data.JiebaTokenizer用在构建dataset时处理文本token到ID的映射。
paddlenlp.data.SamplerHelper用于构建可迭代的batch_sampler。
paddlenlp.data.Stack、paddlenlp.data.Pad、paddlenlp.data.Tuple和paddlenlp.data.Dict用于构建生成mini-batch的collate_fn函数。
paddlenlp.data.Vocab词表类,集合了一系列文本token与ids之间映射的一系列方法,支持从文件、字典、json等一系方式构建词表。
from paddlenlp.data import Vocab# 从文件构建vocab1 = Vocab.load_vocabulary(vocab_file_path)# 从字典构建# dic = {'unk':0, 'pad':1, 'bos':2, 'eos':3, ...}vocab2 = Vocab.from_dict(dic)# 从json构建,一般是已构建好的Vocab对象先保存为json_str或json文件后再进行恢复# json_str方式json_str = vocab1.to_json()
vocab3 = Vocab.from_json(json_str)# json文件方式vocab1.to_json(json_file_path)
vocab4 = Vocab.from_json(json_file_path)paddlenlp.data.JiebaTokenizer初始化需传入paddlenlp.data.Vocab类,包含cut分词方法和将句子明文转换为ids的encode方法。
from paddlenlp.data import Vocab, JiebaTokenizer# 词表文件路径,运行示例程序可先下载词表文件# wget https://paddlenlp.bj.bcebos.com/data/senta_word_dict.txtvocab_file_path = './senta_word_dict.txt'# 构建词表vocab = Vocab.load_vocabulary(
vocab_file_path,
unk_token='[UNK]',
pad_token='[PAD]')
tokenizer = JiebaTokenizer(vocab)
tokens = tokenizer.cut('我爱你中国') # ['我爱你', '中国']ids = tokenizer.encode('我爱你中国') # [1170578, 575565]paddlenlp.data.SamplerHelper的作用是构建用于DataLoader的可迭代采样器,它包含shuffle、sort、batch、shard等一系列方法,方便用户灵活使用。
from paddlenlp.data import SamplerHelperfrom paddle.io import Datasetclass MyDataset(Dataset):
def __init__(self):
super(MyDataset, self).__init__()
self.data = [
[[1, 2, 3, 4], [1]],
[[5, 6, 7], [0]],
[[8, 9], [1]],
] def __getitem__(self, index):
data = self.data[index][0]
label = self.data[index][1] return data, label def __len__(self):
return len(self.data)
dataset = MyDataset()# SamplerHelper返回的是数据索引的可迭代对象,产生的迭代的索引为:[0, 1, 2]sampler = SamplerHelper(dataset)# `shuffle()`的作用是随机打乱索引顺序,产生的迭代的索引为:[0, 2, 1]sampler = sampler.shuffle()# sort()的作用是按照指定key为排序方式并在buffer_size大小个样本中排序# 示例中以样本第一个字段的长度进行升序排序,产生的迭代的索引为:[2, 0, 1]key = (lambda x, data_source: len(data_source[x][0]))
sampler = sampler.sort(key=key, buffer_size=2)# batch()的作用是按照batch_size组建mini-batch,产生的迭代的索引为:[[2, 0], [1]]sampler = sampler.batch(batch_size=2)# shard()的作用是为多卡训练切分数据集,当前卡产生的迭代的索引为:[[2, 0]]sampler = sampler.shard(num_replicas=2)paddlenlp.data.Stack用来组建batch,其输入必须具有相同的shape,输出便是这些输入的堆叠组成的batch数据。
from paddlenlp.data import Stack a = [1, 2, 3, 4] b = [3, 4, 5, 6] c = [5, 6, 7, 8] result = Stack()([a, b, c])""" [[1, 2, 3, 4], [3, 4, 5, 6], [5, 6, 7, 8]] """
paddlenlp.data.Pad用来组建batch,它的输入长度不同,它首先会将输入数据全部padding到最大长度,然后再堆叠组成batch数据输出。
from paddlenlp.data import Pad a = [1, 2, 3, 4] b = [5, 6, 7] c = [8, 9] result = Pad(pad_val=0)([a, b, c])""" [[1, 2, 3, 4], [5, 6, 7, 0], [8, 9, 0, 0]] """
paddlenlp.data.Tuple会将多个组batch的函数包装在一起,组成tuple。
from paddlenlp.data import Stack, Pad, Tupledata = [
[[1, 2, 3, 4], [1]],
[[5, 6, 7], [0]],
[[8, 9], [1]],
]
batchify_fn = Tuple(Pad(pad_val=0), Stack())
ids, label = batchify_fn(data)"""
ids:
[[1, 2, 3, 4],
[5, 6, 7, 0],
[8, 9, 0, 0]]
label: [[1], [0], [1]]
"""paddlenlp.data.Dict会将多个组batch的函数包装在一起,组成dict。
from paddlenlp.data import Stack, Pad, Dictdata = [
{'labels':[1], 'token_ids':[1, 2, 3, 4]},
{'labels':[0], 'token_ids':[5, 6, 7]},
{'labels':[1], 'token_ids':[8, 9]},
]
batchify_fn = Dict({'token_ids':Pad(pad_val=0), 'labels':Stack()})
ids, label = batchify_fn(data)"""
ids:
[[1, 2, 3, 4],
[5, 6, 7, 0],
[8, 9, 0, 0]]
label: [[1], [0], [1]]
"""from paddlenlp.data import Vocab, JiebaTokenizer, Stack, Pad, Tuple, SamplerHelperfrom paddlenlp.datasets import load_datasetfrom paddle.io import DataLoader# 词表文件路径,运行示例程序可先下载词表文件# wget https://paddlenlp.bj.bcebos.com/data/senta_word_dict.txtvocab_file_path = './senta_word_dict.txt'# 构建词表vocab = Vocab.load_vocabulary(
vocab_file_path,
unk_token='[UNK]',
pad_token='[PAD]')# 初始化分词器tokenizer = JiebaTokenizer(vocab)def convert_example(example):
text, label = example['text'], example['label']
ids = tokenizer.encode(text)
label = [label] return ids, label
dataset = load_dataset('chnsenticorp', splits='train')
dataset = dataset.map(convert_example, lazy=True)
pad_id = vocab.token_to_idx[vocab.pad_token]
batchify_fn = Tuple(
Pad(axis=0, pad_val=pad_id), # ids
Stack(dtype='int64') # label)
batch_sampler = SamplerHelper(dataset).shuffle().batch(batch_size=16)
data_loader = DataLoader(
dataset,
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)# 测试数据集for batch in data_loader:
ids, label = batch print(ids.shape, label.shape) print(ids) print(label) break<br/>
以上就是『NLP打卡营学习笔记』实践课2:文本语义相似度计算的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 457
457























