






该内容围绕文档扫描比赛展开,介绍任务为识别文档边缘并输出扫描结果。用户曾对四角点定义存疑,后明确为左上、左下、右上、右下。解题先按生成边缘heatmap处理,用SegFormer3模型分割,经二值化、去噪、提取轮廓,后将模型转为ONNX以适配提交,最终生成提交文件。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

比赛简易介绍
赛题任务
生活中人们使用手机进行文档扫描逐渐成为一件普遍的事情,为了提高人们的使用体验,我们期望通过算法技术去除杂乱的拍摄背景并精准框取文档边缘,选手需要通过深度学习技术训练模型,对给定的真实场景下采集得到的带有拍摄背景的文件图片进行边缘智能识别,并最终输出处理后的扫描结果图片。
本次比赛希望选手结合当下前沿的图像处理技术与计算机视觉技术,提升模型的训练性能和泛化能力,在保证效果精准的同时,注意模型在实际应用中的性能问题,做到尽可能的小而快。
赛题数据介绍
- images 为文档图像数据,edges 为预生成的边缘heatmap图,segments 为预生成的文档区域分割图,根据图片名称一一对应;
- data_info.txt 文件中的每一行对应一个图像样本,其数据格式如下: 图片名称,x1,y1,x2,y2,x3,y3,…,xn,yn
如下图:

评测方式说明
由于本次比赛任务的特殊性,也希望所有的参赛者能快速融入比赛,因此本次比赛设计了两种测试的方式:
- 参赛选手提交的代码和模型只预测文档边缘的heatmap图,由后台评测脚本中预置的算法回归出文档区域的四个角的坐标点,并生成规则的四边形,与GT计算IoU值;
- 参赛选手提交的代码和模型直接回归文档区域的四个角的坐标点,并生成规则的四边形,与GT计算IoU值。
注:两种评测方式的结果会放在一个排行榜内,评测脚本中预置的角点回归算法会存在一定的局限性,如果各位参赛选手希望获得更高的分数,建议采用第二种评测方式。
这里个人还是比较迷茫的,任务是回归文档区域四个角点坐标,感觉有两种理解:
- 纸张四个角点的坐标
- 包含所有文档区域区域的最小四边形
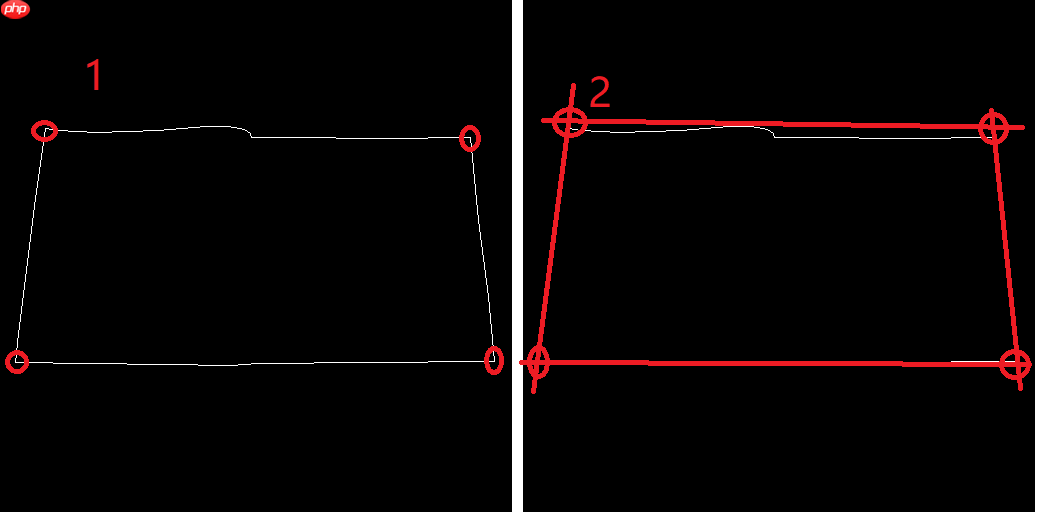
但很多图像中目标区域是凸多边形,角点顺时针相连的封闭多边形可能并不会完全包含所有区域
希望百度运营同学给出部分示例的GT,或者请明白的同学答疑解惑。
解题思路
由于定义不太明确,暂时按照预测文档边缘的heatmap图来处理,分为以下几步:
- 语义分割,生成分割结果
- 二值化
- 去噪
- 提取轮廓
下面,抛砖引玉,流程走一遍,若有错漏,还请各位多多包涵
测试数据集A第一张,原图如下:
采用segformer3模型做分割,效果如下:

二值化后去噪:

提取轮廓:

至此结束,心里还在想着这个圆角怎么处理,哪里是角点?手动狗头。
关于疑问的填坑
咨询官方群中百度的同学,关于四个角点的坐标给定的定义是:

物体左上,左下,右上,右下四个点。
按照这个思路,坐标点是边缘上的点,用相对位置来计算
根据我的实验,不同的方法可能会影响百分之零点一左右的精度,一点点,不影响大局。
下一步提升(分割部分)
- 语义分割并不是最优解,虽然看着iou高,但是边界比较粗糙,要想办法提取更精确的边界
- 更精细化的去噪
PaddleSeg语义分割实现
代码都在下面,一键运行
语义分割用了PaddleSeg套件,图形学操作在./work/predict.py中,详细注释
最后的提交结果在根目录下,submit.zip文件
希望同学们喜欢,fork
祝大家比赛顺利,取得好成绩
# clone PaddleSeg的项目!git clone https://gitee.com/paddlepaddle/PaddleSeg# 安装依赖!pip install -r PaddleSeg/requirements.txt !pip install -r ./work/requirements.txt
#解压数据集!mkdir dataset !unzip -oq data/data140391/train_datasets_document_detection_0411.zip -d dataset/ !unzip -oq data/data140389/testA_datasets_document_detection.zip -d dataset/# 数据处理,将255变为1(PaddleSeg默认255为忽略数据)!python work/data_process.py# 数据处理,生成数据列表,tarin.txt,val.txt,test.txt,labels.txt!python PaddleSeg/tools/split_dataset_list.py dataset/train_datasets_document_detection_0411 images label --split 0.9 0.1 0 --format jpg png
# # 复制segformer_b3配置文件%cp ./work/segformer_b3_doc.yml ./PaddleSeg/configs/
# 开始训练,如果想自己训练权重,去掉下面的注释即可# !python PaddleSeg/train.py \# --config PaddleSeg/configs/segformer_b3_doc.yml \# --do_eval \# --use_vdl \# --save_interval 500 \# --save_dir output_segformer_b3_train
# 如果你只想看看结果,运行这段代码!python PaddleSeg/predict.py \
--config PaddleSeg/configs/segformer_b3_doc.yml \
--model_path work/model.pdparams \
--image_path dataset/testA_datasets_document_detection/images# 输出效果图在output/result/added_prediction下
# 如果你训练更多的epoch,把下面代码的注释去掉,用自己训练的权重预测# !python PaddleSeg/predict.py \# --config PaddleSeg/configs/segformer_b3_doc.yml \# --model_path output_segformer_b3_train/best_model/model.pdparams \# --image_path dataset/testA_datasets_document_detection/images
为什么要ONNX
本以为到这就结束了,但生活吧,总是充满惊喜。
开放上传已经差不多一周了,排行榜暂无结果,本以为自己是宇宙中最快的男人,然而现实又一次给我一个暴击。
我,不快~乐
回头看,发现要求提交可执行的python文件与模型,给出了环境,给出了predict.py的输入与输出,这些都是还好,重写python文件最多是有点小麻烦
但问题是,我的依赖包怎么整,难道要我用 numpy==1.21.1 onnx==1.10.1 onnxruntime-gpu==1.10 opencv-python==4.5.3.56 paddlepaddle-gpu==2.1.2 Pillow==8.3.1 scikit-image==0.18.2 scikit-learn==0.24.2 scipy==1.7.1 shapely==1.8.1.post1从零开始撸一个框架么~

当然了,我是不会放弃治疗的,于是尝试各种方法,感觉肝疼
与笠雨聆月大佬沟通,得知可以上传分割结果,边缘结果和json结构都可以,
转念一想,( 这个念转了半个月 )不依赖PaddleSeg进行实例化,不就行了,paddle2onnx搞起来
ONNX模型转换与推理实现
开整,上代码
!pip install paddleseg !pip install paddle2onnx !pip install pillow==7.1.2
# 划重点,这里是转换代码,PaddleSeg转换简单,太香了!!!!!!!!!!!from paddleseg.models import SegFormerfrom paddleseg.cvlibs import managerimport paddle
model = SegFormer(num_classes=2,
backbone=manager.BACKBONES['MixVisionTransformer_B3'](),
embedding_dim=768,
pretrained=None)# 加载预训练模型参数model.set_dict(paddle.load('work/model.pdparams'))# 将模型设置为评估状态model.eval()# 定义输入数据input_spec = paddle.static.InputSpec(shape=[None, 3, 512, 512], dtype='float32', name='image')# ONNX模型导出paddle.onnx.export(model, './work/SegFormerB3', input_spec=[input_spec], opset_version=12)
%cp ./work/SegFormerB3.onnx ./SegFormerB3.onnx !python ./work/predict.py dataset/testA_datasets_document_detection/images results
# 输出结果在resulrs文件夹中,可视化一下import osimport numpy as npimport matplotlib.pyplot as plt
%matplotlib inlinefrom PIL import Imageimport globimport warnings
warnings.filterwarnings("ignore")
DATADIR = 'results' lst=glob.glob(DATADIR+"/*.**g")
file0 = lst[0]
file1 = lst[1]
file2 = lst[2]# 读取图片img0 = Image.open(file0)
img0 = np.array(img0)
img1 = Image.open(file1)
img1 = np.array(img1)
img2 = Image.open(file2)
img2 = np.array(img2)# 画出读取的图片plt.figure(figsize=(16, 8))
f = plt.subplot(131)
f.set_title('0', fontsize=20)
plt.imshow(img0)
f = plt.subplot(132)
f.set_title('1', fontsize=20)
plt.imshow(img1)
f = plt.subplot(133)
f.set_title('2', fontsize=20)
plt.imshow(img2)
plt.show()
# 压缩可提交文件%cp ./work/predict.py ./predict.py ! zip submit.zip SegFormerB3.onnx predict.py# 下载上传即可





























