本文介绍基于PaddlePaddle复现STANet的过程。STANet是遥感影像变化检测算法,引入时空注意力机制与多尺度子区域方案。复现忠实原文,与官方实现存在两点差异,含特征提取器、时空注意力模块等结构,在LEVIR-CD数据集上完成训练测试,验证了复现效果。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

深度学习变化检测算法STANet的PaddlePaddle复现。已集成至PaddleRS项目。
我们生活在一个变化的世界。无论是地表生态系统还是人类社会活动,都是不断演进和动态发展的过程。实时,准确地获取地表的变化信息,对于研究自然环境、人类活动以及二者之间的相互作用具有十分重要的意义。得益于卫星传感器技术的发展,人类可以通过遥感手段对地表实施大范围、长时间的监测。而遥感影像的变化检测,正是通过对同一地区不同时间的重复观测来分析区域内地物状态变化的技术。
如下图所示,变化检测任务的输入一般是多时相遥感影像。对于二值变化检测任务而言,输出是二值变化图,标示了变化发生的位置。例如图中用白色标记发生变化的像素,黑色标记未发生变化的像素。

变化检测在实际生产生活中已经得到了十分广泛的应用,例如用于生态系统监测、城市发展规划、农业用地研究、受灾情况评估等等。
"The only thing that never changes is that everything changes." - Louis L'Amour
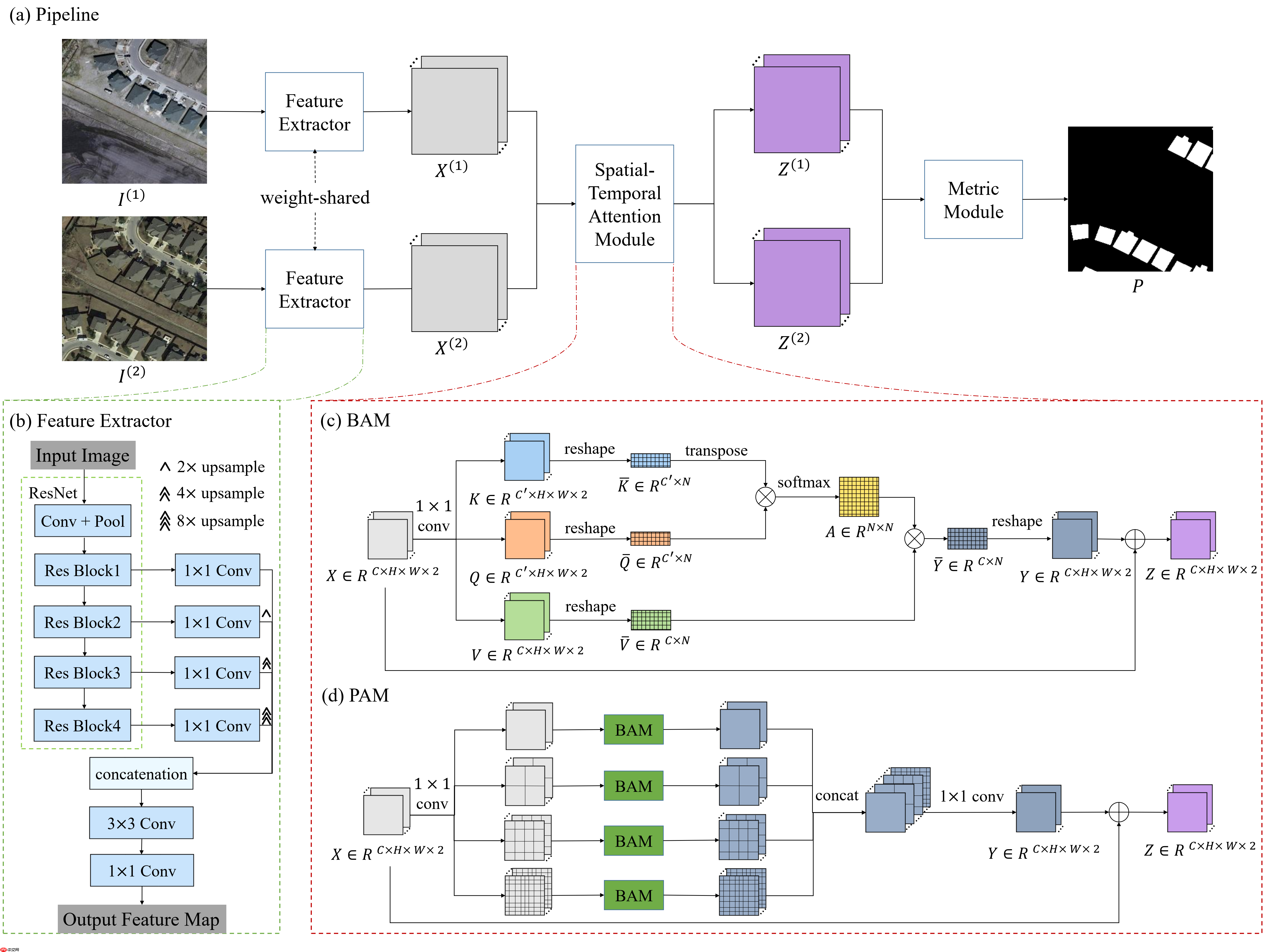
STANet是Hao Chen和Zhenwei Shi提出的一种基于深度学习的遥感影像变化检测方法,论文于2020年4月发表在《Remote Sensing》期刊。STANet创新性地将时空注意力(spatial-temporal attention)机制引入变化检测领域,通过计算两幅影像的特征图中任意两个像素间的相关关系,构建变化检测任务所需要的特征时空依赖,从而实现对变化区域更加精准的识别。另一方面,考虑到遥感影像中常见的地物多尺度问题,作者提出一种将影像分割为多尺度子区域(multi-scale subregion)、并在每个子区域内进行自注意力计算的方案,以便捕捉不同尺度的时空依赖信息。STANet的整体框架如下图所示:
Chen H, Shi Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sensing. 2020; 12(10):1662. https://doi.org/10.3390/rs12101662
本项目遵照原论文,使用PaddlePaddle框架对STANet进行复现,并在LEVIR-CD数据集上对复现算法的效果进行评估。
本节将基于PaddlePaddle框架,根据原论文实现STANet模型。复现过程总体上忠实于原文,但需要指出的是,原作者的官方实现和本项目中的实现有两点主要不同:
遵循自顶向下的设计范式,首先对STANet模型的整体结构进行规划。在此之前,出于复用性方面考虑,对PaddlePaddle的一些原生模块进行封装:
import paddleimport paddle.nn as nnimport paddle.nn.functional as Fdef get_norm_layer():
# TODO: select appropriate norm layer.
return nn.BatchNorm2Ddef make_norm(*args, **kwargs):
norm_layer = get_norm_layer() return norm_layer(*args, **kwargs)class BasicConv(nn.Layer):
def __init__(self,
in_ch,
out_ch,
kernel_size,
pad_mode='constant',
bias='auto',
norm=False,
act=False,
**kwargs):
super(BasicConv, self).__init__()
seq = [] if kernel_size >= 2:
seq.append(nn.Pad2D(kernel_size // 2, mode=pad_mode))
seq.append(
nn.Conv2D(
in_ch,
out_ch,
kernel_size,
stride=1,
padding=0,
bias_attr=(False if norm else None) if bias == 'auto' else bias,
**kwargs)) if norm: if norm is True:
norm = make_norm(out_ch)
seq.append(norm) if act: if act is True:
act = make_act()
seq.append(act)
self.seq = nn.Sequential(*seq) def forward(self, x):
return self.seq(x)class Conv1x1(BasicConv):
def __init__(self,
in_ch,
out_ch,
pad_mode='constant',
bias='auto',
norm=False,
act=False,
**kwargs):
super(Conv1x1, self).__init__(
in_ch,
out_ch, 1,
pad_mode=pad_mode,
bias=bias,
norm=norm,
act=act,
**kwargs)class Conv3x3(BasicConv):
def __init__(self,
in_ch,
out_ch,
pad_mode='constant',
bias='auto',
norm=False,
act=False,
**kwargs):
super(Conv3x3, self).__init__(
in_ch,
out_ch, 3,
pad_mode=pad_mode,
bias=bias,
norm=norm,
act=act,
**kwargs)class Identity(nn.Layer):
"""A placeholder identity operator that accepts exactly one argument."""
def __init__(self, *args, **kwargs):
super(Identity, self).__init__() def forward(self, x):
return x接着,利用封装好的组件“搭积木”,定义模型:
class STANet(nn.Layer):
"""
The STANet implementation based on PaddlePaddle.
The original article refers to
H. Chen and Z. Shi, "A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection"
(https://www.mdpi.com/2072-4292/12/10/1662).
Note that this implementation differs from the original work in two aspects:
1. We do not use multiple dilation rates in layer 4 of the ResNet backbone.
2. A classification head is used in place of the original metric learning-based head to stablize the training process.
Args:
in_channels (int): The number of bands of the input images.
num_classes (int): The number of target classes.
att_type (str, optional): The attention module used in the model. Options are 'PAM' and 'BAM'. Default: 'BAM'.
ds_factor (int, optional): The downsampling factor of the attention modules. When `ds_factor` is set to values
greater than 1, the input features will first be processed by an average pooling layer with the kernel size of
`ds_factor`, before being used to calculate the attention scores. Default: 1.
Raises:
ValueError: When `att_type` has an illeagal value (unsupported attention type).
"""
def __init__(self, in_channels, num_classes, att_type='BAM', ds_factor=1):
super(STANet, self).__init__()
WIDTH = 64
self.extract = build_feat_extractor(in_ch=in_channels, width=WIDTH)
self.attend = build_sta_module(
in_ch=WIDTH, att_type=att_type, ds=ds_factor)
self.conv_out = nn.Sequential(
Conv3x3(
WIDTH, WIDTH, norm=True, act=True),
Conv3x3(WIDTH, num_classes))
self.init_weight() def forward(self, t1, t2):
f1 = self.extract(t1)
f2 = self.extract(t2)
f1, f2 = self.attend(f1, f2)
y = paddle.abs(f1 - f2)
y = F.interpolate(
y, size=paddle.shape(t1)[2:], mode='bilinear', align_corners=True)
pred = self.conv_out(y) return [pred] def init_weight(self):
# Do nothing here as the encoder and decoder weights have already been initialized.
# Note however that currently self.attend and self.conv_out use the default initilization method.
pass其中,build_feat_extractor()函数负责定义特征提取器(Feature Extractor),而build_sta_module()函数则负责定义时空注意力模块(Spatial-Temporal Attention Module)。
根据原文,将特征提取器分为骨干网络(backbone,一个修改版的ResNet-18)和解码器(decoder,将骨干网络提取到的不同层级特征上采样并融合)。编写build_feat_extractor()如下:
def build_feat_extractor(in_ch, width):
return nn.Sequential(Backbone(in_ch, 'resnet18'), Decoder(width))其中,Backbone是对骨干网络部分的封装(为了使代码更具可扩展性,不止支持ResNet-18一种结构),Decoder则是对解码器部分的封装,用nn.Sequential将二者级联。
class Backbone(nn.Layer):
def __init__(self, in_ch, arch, pretrained=True, strides=(2, 1, 2, 2, 2)):
super(Backbone, self).__init__() if arch == 'resnet18':
self.resnet = resnet18(
pretrained=pretrained,
strides=strides,
norm_layer=get_norm_layer()) elif arch == 'resnet34':
self.resnet = resnet34(
pretrained=pretrained,
strides=strides,
norm_layer=get_norm_layer()) elif arch == 'resnet50':
self.resnet = resnet50(
pretrained=pretrained,
strides=strides,
norm_layer=get_norm_layer()) else: raise ValueError
self._trim_resnet() if in_ch != 3:
self.resnet.conv1 = nn.Conv2D(
in_ch, 64,
kernel_size=7,
stride=strides[0],
padding=3,
bias_attr=False) def forward(self, x):
x = self.resnet.conv1(x)
x = self.resnet.bn1(x)
x = self.resnet.relu(x)
x = self.resnet.maxpool(x)
x1 = self.resnet.layer1(x)
x2 = self.resnet.layer2(x1)
x3 = self.resnet.layer3(x2)
x4 = self.resnet.layer4(x3) return x1, x2, x3, x4 def _trim_resnet(self):
self.resnet.avgpool = Identity()
self.resnet.fc = Identity()其中,_trim_resnet()方法用于去除没有用到的全局平均池化和全连接层,以避免不必要的开销和可能导致的参数量统计错误。
对于ResNet的具体实现,为了避免重复造轮子,本项目直接在PaddlePaddle内置的ResNet基础上修改。主要修改的地方是为ResNet类的构造函数添加strides和norm_layer两个参数,前者控制stem及每个stage的output stride,后者控制使用的归一化层的类型。尽管本项目中并没有涉及到对归一化层类型的改变(仍然使用nn.BatchNorm2D),但应用这一设计有利于日后进一步的功能扩展。
# Adapted from https://github.com/PaddlePaddle/Paddle/blob/release/2.2/python/paddle/vision/models/resnet.py## Original head information# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.## Licensed under the Apache License, Version 2.0 (the "License");# you may not use this file except in compliance with the License.# You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.from __future__ import divisionfrom __future__ import print_functionimport paddleimport paddle.nn as nnfrom paddle.utils.download import get_weights_path_from_url
__all__ = []
model_urls = { 'resnet18': ('https://paddle-hapi.bj.bcebos.com/models/resnet18.pdparams', 'cf548f46534aa3560945be4b95cd11c4'), 'resnet34': ('https://paddle-hapi.bj.bcebos.com/models/resnet34.pdparams', '8d2275cf8706028345f78ac0e1d31969'), 'resnet50': ('https://paddle-hapi.bj.bcebos.com/models/resnet50.pdparams', 'ca6f485ee1ab0492d38f323885b0ad80'), 'resnet101': ('https://paddle-hapi.bj.bcebos.com/models/resnet101.pdparams', '02f35f034ca3858e1e54d4036443c92d'), 'resnet152': ('https://paddle-hapi.bj.bcebos.com/models/resnet152.pdparams', '7ad16a2f1e7333859ff986138630fd7a'),
}class BasicBlock(nn.Layer):
expansion = 1
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None):
super(BasicBlock, self).__init__() if norm_layer is None:
norm_layer = nn.BatchNorm2D if dilation > 1: raise NotImplementedError( "Dilation > 1 not supported in BasicBlock")
self.conv1 = nn.Conv2D(
inplanes, planes, 3, padding=1, stride=stride, bias_attr=False)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2D(planes, planes, 3, padding=1, bias_attr=False)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out) if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out) return outclass BottleneckBlock(nn.Layer):
expansion = 4
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None):
super(BottleneckBlock, self).__init__() if norm_layer is None:
norm_layer = nn.BatchNorm2D
width = int(planes * (base_width / 64.)) * groups
self.conv1 = nn.Conv2D(inplanes, width, 1, bias_attr=False)
self.bn1 = norm_layer(width)
self.conv2 = nn.Conv2D(
width,
width, 3,
padding=dilation,
stride=stride,
groups=groups,
dilation=dilation,
bias_attr=False)
self.bn2 = norm_layer(width)
self.conv3 = nn.Conv2D(
width, planes * self.expansion, 1, bias_attr=False)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU()
self.downsample = downsample
self.stride = stride def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out) if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out) return outclass ResNet(nn.Layer):
"""ResNet model from
`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_
Args:
Block (BasicBlock|BottleneckBlock): block module of model.
depth (int): layers of resnet, default: 50.
num_classes (int): output dim of last fc layer. If num_classes <=0, last fc layer
will not be defined. Default: 1000.
with_pool (bool): use pool before the last fc layer or not. Default: True.
Examples:
.. code-block:: python
from paddle.vision.models import ResNet
from paddle.vision.models.resnet import BottleneckBlock, BasicBlock
resnet50 = ResNet(BottleneckBlock, 50)
resnet18 = ResNet(BasicBlock, 18)
"""
def __init__(self,
block,
depth,
num_classes=1000,
with_pool=True,
strides=(1, 1, 2, 2, 2),
norm_layer=None):
super(ResNet, self).__init__()
layer_cfg = { 18: [2, 2, 2, 2], 34: [3, 4, 6, 3], 50: [3, 4, 6, 3], 101: [3, 4, 23, 3], 152: [3, 8, 36, 3]
}
layers = layer_cfg[depth]
self.num_classes = num_classes
self.with_pool = with_pool
self._norm_layer = nn.BatchNorm2D if norm_layer is None else norm_layer
self.inplanes = 64
self.dilation = 1
self.conv1 = nn.Conv2D( 3,
self.inplanes,
kernel_size=7,
stride=strides[0],
padding=3,
bias_attr=False)
self.bn1 = self._norm_layer(self.inplanes)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2D(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], stride=strides[1])
self.layer2 = self._make_layer(block, 128, layers[1], stride=strides[2])
self.layer3 = self._make_layer(block, 256, layers[2], stride=strides[3])
self.layer4 = self._make_layer(block, 512, layers[3], stride=strides[4]) if with_pool:
self.avgpool = nn.AdaptiveAvgPool2D((1, 1)) if num_classes > 0:
self.fc = nn.Linear(512 * block.expansion, num_classes) def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2D(
self.inplanes,
planes * block.expansion, 1,
stride=stride,
bias_attr=False),
norm_layer(planes * block.expansion), )
layers = []
layers.append(
block(self.inplanes, planes, stride, downsample, 1, 64,
previous_dilation, norm_layer))
self.inplanes = planes * block.expansion for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, norm_layer=norm_layer)) return nn.Sequential(*layers) def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x) if self.with_pool:
x = self.avgpool(x) if self.num_classes > 0:
x = paddle.flatten(x, 1)
x = self.fc(x) return xdef _resnet(arch, Block, depth, pretrained, **kwargs):
model = ResNet(Block, depth, **kwargs) if pretrained: assert arch in model_urls, "{} model do not have a pretrained model now, you should set pretrained=False".format(
arch)
weight_path = get_weights_path_from_url(model_urls[arch][0],
model_urls[arch][1])
param = paddle.load(weight_path)
model.set_dict(param) return modeldef resnet18(pretrained=False, **kwargs):
"""ResNet 18-layer model
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
Examples:
.. code-block:: python
from paddle.vision.models import resnet18
# build model
model = resnet18()
# build model and load imagenet pretrained weight
# model = resnet18(pretrained=True)
"""
return _resnet('resnet18', BasicBlock, 18, pretrained, **kwargs)def resnet34(pretrained=False, **kwargs):
"""ResNet 34-layer model
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
Examples:
.. code-block:: python
from paddle.vision.models import resnet34
# build model
model = resnet34()
# build model and load imagenet pretrained weight
# model = resnet34(pretrained=True)
"""
return _resnet('resnet34', BasicBlock, 34, pretrained, **kwargs)def resnet50(pretrained=False, **kwargs):
"""ResNet 50-layer model
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
Examples:
.. code-block:: python
from paddle.vision.models import resnet50
# build model
model = resnet50()
# build model and load imagenet pretrained weight
# model = resnet50(pretrained=True)
"""
return _resnet('resnet50', BottleneckBlock, 50, pretrained, **kwargs)def resnet101(pretrained=False, **kwargs):
"""ResNet 101-layer model
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
Examples:
.. code-block:: python
from paddle.vision.models import resnet101
# build model
model = resnet101()
# build model and load imagenet pretrained weight
# model = resnet101(pretrained=True)
"""
return _resnet('resnet101', BottleneckBlock, 101, pretrained, **kwargs)def resnet152(pretrained=False, **kwargs):
"""ResNet 152-layer model
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
Examples:
.. code-block:: python
from paddle.vision.models import resnet152
# build model
model = resnet152()
# build model and load imagenet pretrained weight
# model = resnet152(pretrained=True)
"""
return _resnet('resnet152', BottleneckBlock, 152, pretrained, **kwargs)接着,定义特征提取器的解码器部分:
class Decoder(nn.Layer):
def __init__(self, f_ch):
super(Decoder, self).__init__()
self.dr1 = Conv1x1(64, 96, norm=True, act=True)
self.dr2 = Conv1x1(128, 96, norm=True, act=True)
self.dr3 = Conv1x1(256, 96, norm=True, act=True)
self.dr4 = Conv1x1(512, 96, norm=True, act=True)
self.conv_out = nn.Sequential(
Conv3x3( 384, 256, norm=True, act=True),
nn.Dropout(0.5),
Conv1x1( 256, f_ch, norm=True, act=True))
self.init_weight() def forward(self, feats):
f1 = self.dr1(feats[0])
f2 = self.dr2(feats[1])
f3 = self.dr3(feats[2])
f4 = self.dr4(feats[3])
f2 = F.interpolate(
f2, size=paddle.shape(f1)[2:], mode='bilinear', align_corners=True)
f3 = F.interpolate(
f3, size=paddle.shape(f1)[2:], mode='bilinear', align_corners=True)
f4 = F.interpolate(
f4, size=paddle.shape(f1)[2:], mode='bilinear', align_corners=True)
x = paddle.concat([f1, f2, f3, f4], axis=1)
y = self.conv_out(x) return y需要指出的是,在本项目的实现中,若没有使用预训练权重参数,则整个特征提取器中的所有权重参数均使用PaddlePaddle默认的方式初始化。
原论文提出了基础时空注意力模块(Basic spatial-temporal Attention Module, BAM)和金字塔时空注意力模块(Pyramid spatial-temporal Attention Module, PAM)两种时空注意力模块。提出BAM和PAM是论文的主要贡献点之一,而二者的实现也是STANet复现过程中相对困难的部分。仍然遵照自顶向下的原则,首先编写build_sta_module()函数:
def build_sta_module(in_ch, att_type, ds):
if att_type == 'BAM': return Attention(BAM(in_ch, ds)) elif att_type == 'PAM': return Attention(PAM(in_ch, ds)) else: raise ValueError使用Attention类封装时空注意力模块的相关逻辑,作为适配器(adapter)。
class Attention(nn.Layer):
def __init__(self, att):
super(Attention, self).__init__()
self.att = att def forward(self, x1, x2):
x = paddle.stack([x1, x2], axis=-1)
y = self.att(x) return y[..., 0], y[..., 1]因为时空注意力机制涉及到两个时相的影像特征,在这里我使用一种简单的策略,即,将两个时相的输入特征图堆叠(stack)后送入具体的注意力模块实现中,然后以元组的形式返回输出特征图在堆叠维度的拆分(split)结果。
考虑到PAM是BAM的多尺度改进版本,首先实现BAM:
class BAM(nn.Layer):
def __init__(self, in_ch, ds):
super(BAM, self).__init__()
self.ds = ds
self.pool = nn.AvgPool2D(self.ds)
self.val_ch = in_ch
self.key_ch = in_ch // 8
self.conv_q = Conv1x1(in_ch, self.key_ch)
self.conv_k = Conv1x1(in_ch, self.key_ch)
self.conv_v = Conv1x1(in_ch, self.val_ch)
self.softmax = nn.Softmax(axis=-1) def forward(self, x):
x = x.flatten(-2)
x_rs = self.pool(x)
b, c, h, w = paddle.shape(x_rs)
query = self.conv_q(x_rs).reshape((b, -1, h * w)).transpose((0, 2, 1))
key = self.conv_k(x_rs).reshape((b, -1, h * w))
energy = paddle.bmm(query, key)
energy = (self.key_ch**(-0.5)) * energy
attention = self.softmax(energy)
value = self.conv_v(x_rs).reshape((b, -1, w * h))
out = paddle.bmm(value, attention.transpose((0, 2, 1)))
out = out.reshape((b, c, h, w))
out = F.interpolate(out, scale_factor=self.ds)
out = out + x return out.reshape(tuple(out.shape[:-1]) + (out.shape[-1] // 2, 2))由于BAM需要计算两个时相的特征图中所有像素的密集连接,因此其计算复杂度较高。通过设置大于1的ds参数可以对输入的特征图进行池化以减小其空间尺寸,从而达到降低计算量的目的。
相较BAM,PAM更为复杂。但通过抽象可以将其拆解为不同尺度上“子模块”结果的融合,定义如下所示:
class PAM(nn.Layer):
def __init__(self, in_ch, ds, scales=(1, 2, 4, 8)):
super(PAM, self).__init__()
self.stages = nn.LayerList(
[PAMBlock(
in_ch, scale=s, ds=ds) for s in scales])
self.conv_out = Conv1x1(in_ch * len(scales), in_ch, bias=False) def forward(self, x):
x = x.flatten(-2)
res = [stage(x) for stage in self.stages]
out = self.conv_out(paddle.concat(res, axis=1)) return out.reshape(tuple(out.shape[:-1]) + (out.shape[-1] // 2, 2))对于每种尺度,“子模块”PAMBlock的定义为:
class PAMBlock(nn.Layer):
def __init__(self, in_ch, scale=1, ds=1):
super(PAMBlock, self).__init__()
self.scale = scale
self.ds = ds
self.pool = nn.AvgPool2D(self.ds)
self.val_ch = in_ch
self.key_ch = in_ch // 8
self.conv_q = Conv1x1(in_ch, self.key_ch, norm=True)
self.conv_k = Conv1x1(in_ch, self.key_ch, norm=True)
self.conv_v = Conv1x1(in_ch, self.val_ch) def forward(self, x):
x_rs = self.pool(x) # Get query, key, and value.
query = self.conv_q(x_rs)
key = self.conv_k(x_rs)
value = self.conv_v(x_rs) # Split the whole image into subregions.
b, c, h, w = x_rs.shape
query = self._split_subregions(query)
key = self._split_subregions(key)
value = self._split_subregions(value) # Perform subregion-wise attention.
out = self._attend(query, key, value) # Stack subregions to reconstruct the whole image.
out = self._recons_whole(out, b, c, h, w)
out = F.interpolate(out, scale_factor=self.ds) return out def _attend(self, query, key, value):
energy = paddle.bmm(query.transpose((0, 2, 1)),
key) # batch matrix multiplication
energy = (self.key_ch**(-0.5)) * energy
attention = F.softmax(energy, axis=-1)
out = paddle.bmm(value, attention.transpose((0, 2, 1))) return out def _split_subregions(self, x):
b, c, h, w = x.shape assert h % self.scale == 0 and w % self.scale == 0
x = x.reshape(
(b, c, self.scale, h // self.scale, self.scale, w // self.scale))
x = x.transpose((0, 2, 4, 1, 3, 5))
x = x.reshape((b * self.scale * self.scale, c, -1)) return x def _recons_whole(self, x, b, c, h, w):
x = x.reshape(
(b, self.scale, self.scale, c, h // self.scale, w // self.scale))
x = x.transpose((0, 3, 1, 4, 2, 5)).reshape((b, c, h, w)) return xPAMBlock首先将输入特征在空间维度上划分为一系列子区域,然后在每个子区域执行和BAM相同的操作,最后将得到的结果重建为和输入具有相同形状的张量。在具体代码编写方面,本项目使用向量化的方式实现上述操作,具有较高的并行度。
本节将对上节中实现的STANet模型进行训练与测试,以验证复现效果。
# 下载安装PaddleRS(个人创建的Gitee镜像版本)!git clone https://gitee.com/bobholamovic/PaddleRS
!pip install -r PaddleRS/requirements.txt
!pip install -e PaddleRS/import sys
sys.path.append("/home/aistudio/PaddleRS")# 解压数据集!unzip -oq data/data136610/LEVIR-CD.zip -d data/data136610/
# 将每幅影像切成256x256的不重叠小块,这一做法与STANet原论文一致# 关于该步骤的具体说明可以参看crop_images.py脚本中的注释!python crop_images.py 'data/data136610/LEVIR-CD/' 'data/data136610/LEVIR-CD_crop/' 256 256
# 生成PaddleRS训练所需的file_list!IN_DIR='data/data136610/LEVIR-CD_crop/train' && paste <(ls ${IN_DIR}/A/*/*.png) <(ls ${IN_DIR}/B/*/*.png) <(ls ${IN_DIR}/label/*/*.png) -d ' ' > data/data136610/train_list.txt
!IN_DIR='data/data136610/LEVIR-CD_crop/val' && paste <(ls ${IN_DIR}/A/*/*.png) <(ls ${IN_DIR}/B/*/*.png) <(ls ${IN_DIR}/label/*/*.png) -d ' ' > data/data136610/val_list.txt
!IN_DIR='data/data136610/LEVIR-CD_crop/test' && paste <(ls ${IN_DIR}/A/*/*.png) <(ls ${IN_DIR}/B/*/*.png) <(ls ${IN_DIR}/label/*/*.png) -d ' ' > data/data136610/test_list.txtimport paddlers as pdrsimport paddlers.transforms as T# 定义训练和验证时的transformstrain_transforms = T.Compose([
T.Resize(target_size=256),
T.RandomHorizontalFlip(),
T.Normalize(
mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])
eval_transforms = T.Compose([
T.Resize(target_size=256),
T.Normalize(
mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])# 定义训练和验证所用的数据集train_dataset = pdrs.datasets.CDDataset(
data_dir='', # 由于file_list中存储的是完整的绝对路径,此处只需要给定空字符串即可
file_list='/home/aistudio/data/data136610/train_list.txt',
transforms=train_transforms,
num_workers=2,
binarize_labels=True,
shuffle=True)
val_dataset = pdrs.datasets.CDDataset(
data_dir='',
file_list='/home/aistudio/data/data136610/val_list.txt',
transforms=eval_transforms,
num_workers=2,
binarize_labels=True,
shuffle=False)# 构造STANet模型,使用PAM作为时空注意力模块model = pdrs.tasks.STANet(in_channels=3, num_classes=2, att_type='PAM')# 制定定步长学习率衰减策略lr_scheduler = paddle.optimizer.lr.StepDecay( 0.001,
step_size=5000, # 学习率衰减系数,这里指定每次减半
gamma=0.5)# 构造AdamW优化器optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.net.parameters()
)# 执行模型训练model.train(
num_epochs=100,
train_dataset=train_dataset,
train_batch_size=8,
eval_dataset=val_dataset,
optimizer=optimizer,
save_interval_epochs=10, # 每多少次迭代记录一次日志
log_interval_steps=200,
save_dir='exp/', # 是否使用early stopping策略,当精度不再改善时提前终止训练
early_stop=False, # 是否启用VisualDL日志功能
use_vdl=True, # 指定从某个检查点继续训练
resume_checkpoint=None)# 计算测试集上的定量指标test_dataset = pdrs.datasets.CDDataset(
data_dir='',
file_list='/home/aistudio/data/data136610/test_list.txt',
transforms=eval_transforms,
num_workers=2,
binarize_labels=True,
shuffle=False)
model = pdrs.tasks.load_model('exp/best_model')
res = model.evaluate(test_dataset)print(f"IoU={res['iou']:.4f}, F1-score={res['f1']:.4f}, OA={res['oacc']:.4f}, Kappa={res['kappa']:.4f}")# 可视化预测结果%matplotlib inlineimport numpy as npfrom PIL import Imagefrom matplotlib import pyplot as plt
T1_PATH = "data/data136610/LEVIR-CD_crop/test/A/test_1/test_1_3.png"T2_PATH = "data/data136610/LEVIR-CD_crop/test/B/test_1/test_1_3.png"GT_PATH = "data/data136610/LEVIR-CD_crop/test/label/test_1/test_1_3.png"pred = model.predict(
(T1_PATH, T2_PATH),
transforms=eval_transforms
)# 从左到右依次显示:第一时相影像、第二时相影像、STANet预测结果以及真值标签plt.figure(constrained_layout=True)
plt.subplot(141)
plt.imshow(Image.open(T1_PATH))
plt.gca().set_axis_off()
plt.title("Image1")
plt.subplot(142)
plt.imshow(Image.open(T2_PATH))
plt.gca().set_axis_off()
plt.title("Image2")
plt.subplot(143)
plt.imshow((pred['label_map']*255).astype('uint8'))
plt.gca().set_axis_off()
plt.title("Pred")
plt.subplot(144)
plt.imshow((np.asarray(Image.open(GT_PATH))*255).astype('uint8'))
plt.gca().set_axis_off()
plt.title("GT")
plt.show()<Figure size 432x288 with 4 Axes>
以上就是【PPSIG】基于PaddlePaddle复现STANet的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 787
787






















