本文复现了基于SPP特征金字塔池化的图像分类网络,SPP可解决输入尺寸差异问题。网络含五层卷积、两层全连接及SPP层,在Cifar10数据集上实验,经20个epoch训练,训练准确率约28.97%,测试准确率约23.73%,呈现了模型的训练过程与性能。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

由于工作需要,最近整理了神经网络中的各种池化方式,对于Spatial Pyramid Pooling(SPP)特征金字塔池化在本项目中做了一个复现,并基于此模块搭建了一个图像分类网络,并在Cifar10数据库中进行了实验。
由于卷积神经网络的全连接层需要固定输入的尺寸,而Selective search所得到的候选区域存在尺寸上的差异,无法直接输入到卷积神经网络中实现区域的特征提取,因此RCNN先将候选区缩放至指定大小随后再输入到模型中进行特征提取直接对区域进行裁剪会导致区域缺失,而将区域缩放则可能导致目标过度形变而导致后续分类错误(例如筷子是细长形的,如果将其直接形变成正方形则会使其严重失真而错误分类)。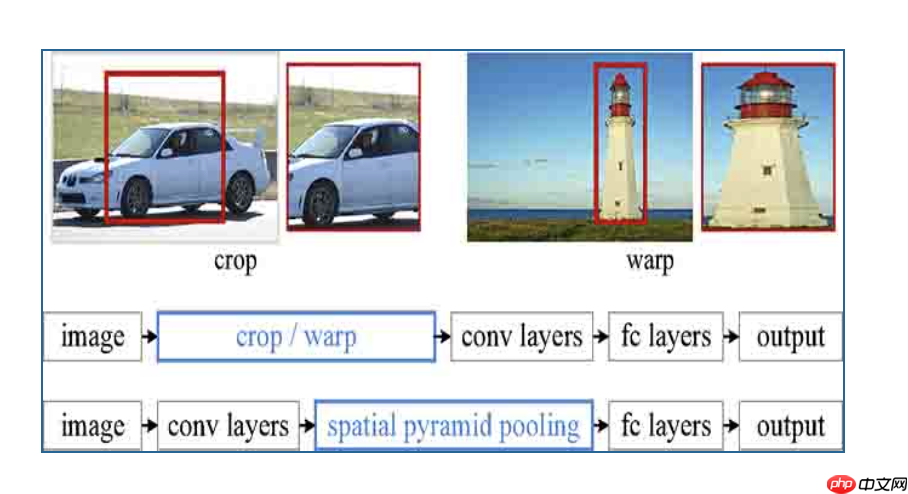
如上图所示,直接对区域进行裁剪会导致区域缺失,而将区域缩放则可能导致目标过度形变而导致后续分类错误(例如筷子是细长形的,如果将其直接形变成正方形则会使其严重失真而错误分类)。其主要结构如下图所示: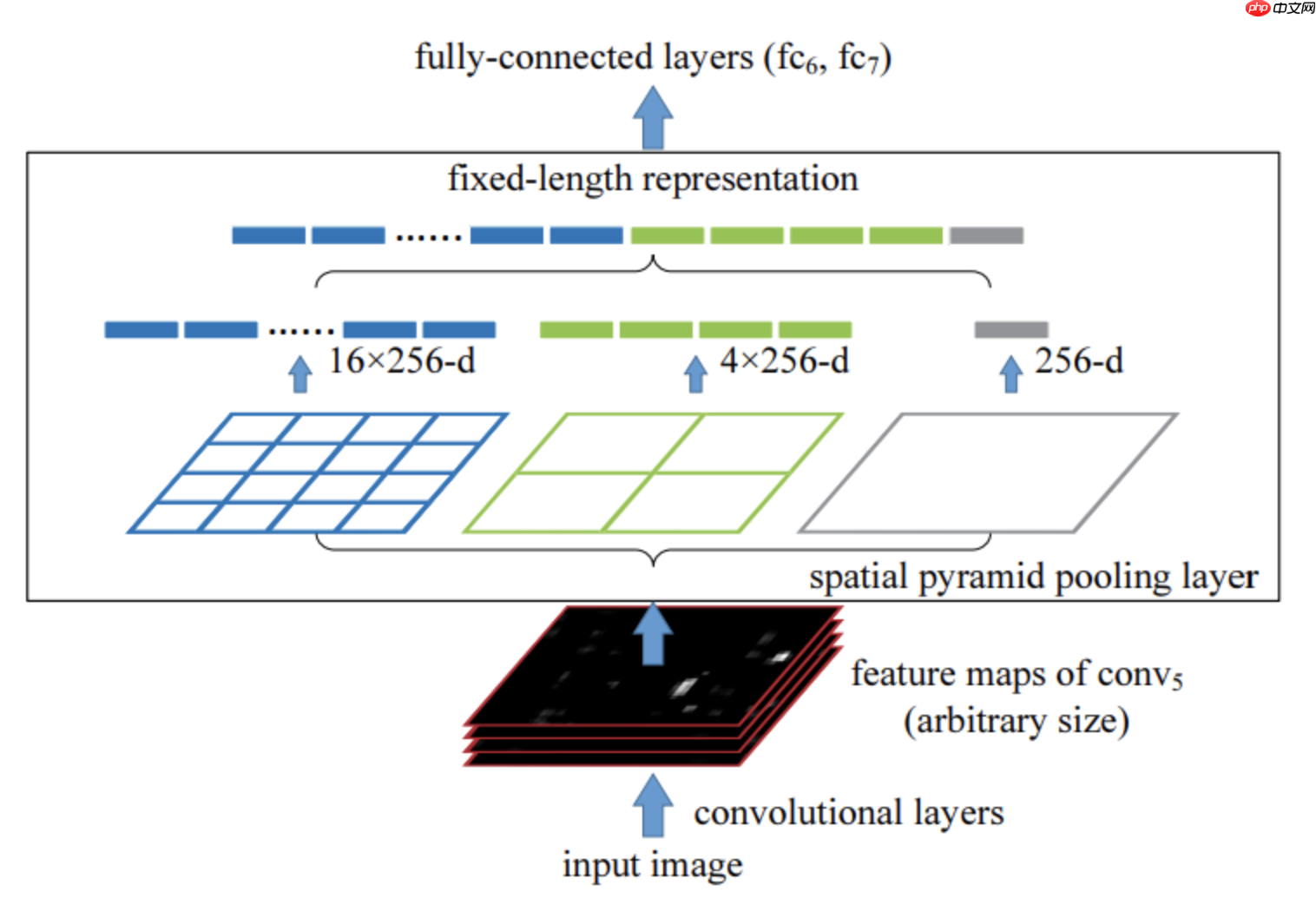
import mathimport paddleimport paddle.nn as nnimport functoolsimport numpy as npimport paddle.nn.functional as Fdef spatial_pyramid_pool(previous_conv, num_sample, previous_conv_size, out_pool_size):
'''
previous_conv: a tensor vector of previous convolution layer
num_sample: an int number of image in the batch
previous_conv_size: an int vector [height, width] of the matrix features size of previous convolution layer
out_pool_size: a int vector of expected output size of max pooling layer
returns: a tensor vector with shape [1 x n] is the concentration of multi-level pooling
'''
# print(previous_conv.size())
for i in range(len(out_pool_size)):
# print(previous_conv_size)
# out_pool_size[i]
h_wid = int(math.ceil(previous_conv_size[0] / out_pool_size[i]))
w_wid = int(math.ceil(previous_conv_size[1] / out_pool_size[i]))
h_pad = (h_wid*out_pool_size[i] - previous_conv_size[0] + 1)
w_pad = (w_wid*out_pool_size[i] - previous_conv_size[1] + 1)
maxpool = nn.MaxPool2D((h_wid, w_wid), stride=(h_wid, w_wid), padding=(h_pad, w_pad))
x = maxpool(previous_conv) if(i == 0): # spp = x.reshape(num_sample,-1)
spp = paddle.reshape(x, [num_sample,-1]) else:
spp = paddle.concat([spp,paddle.reshape(x, [num_sample,-1])], 1) return spp在搭建的CNN网络中,采用了五层卷积层,两层全连接层,在卷积层与全连接层之间添加了SPP层。其模型结构在下面的cell中已经输出

Shop7z网上购物系统是基于ASP开发的简单易用的商城建站平台,Shop7z可以满足不同企业、个人的各种网上开店需求!普及版是一套简便易用的商城系统,支持商品图片批量上传、淘宝导入、商品批量修改等实用功能,还支持手机版以及APP的整合,普及版支持4种不同的模板风格,支持支付宝、财付通、网银在线等支付接口,系统还支持新订单邮件通知、多种分类排序、商品归属多分类等功能,支持五种会员价格体系等。
 0
0

class SPP_NET(nn.Layer):
'''
A CNN model which adds spp layer so that we can input multi-size tensor
'''
def __init__(self, input_nc=3, ndf=64, gpu_ids=[0]):
super(SPP_NET, self).__init__()
self.gpu_ids = gpu_ids
self.output_num = [4,2,1]
self.conv1 = nn.Conv2D(input_nc, ndf, kernel_size=4, stride=2)
self.conv2 = nn.Conv2D(ndf, ndf * 2, kernel_size=4, stride=2)
self.BN1 = nn.BatchNorm2D(ndf * 2)
self.conv3 = nn.Conv2D(ndf * 2, ndf * 4, kernel_size=4, stride=2)
self.BN2 = nn.BatchNorm2D(ndf * 4)
self.conv4 = nn.Conv2D(ndf * 4, ndf * 8, kernel_size=4, stride=2)
self.BN3 = nn.BatchNorm2D(ndf * 8) # self.conv5 = nn.Conv2D(ndf * 8, 64, kernel_size=4, stride=2)
self.fc1 = nn.Linear(10752,4096)
self.fc2 = nn.Linear(4096,1000) def forward(self,x):
x = self.conv1(x)
x = F.leaky_relu(x)
x = self.conv2(x)
x = F.leaky_relu(self.BN1(x))
x = self.conv3(x)
x = F.leaky_relu(self.BN2(x))
x = self.conv4(x) # print(x.shape)
# x = F.leaky_relu(self.BN3(x))
# x = self.conv5(x)
spp = spatial_pyramid_pool(x,512,[int(x.shape[2]),int(x.shape[3])],self.output_num)
# print(spp.shape)
fc1 = self.fc1(spp)
fc2 = self.fc2(fc1)
s = nn.Sigmoid()
output = s(fc2) return sppspp = SPP_NET() paddle.summary(spp, (512, 3, 224, 224))
W0613 21:40:22.094002 4661 gpu_context.cc:278] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1 W0613 21:40:22.098572 4661 gpu_context.cc:306] device: 0, cuDNN Version: 7.6.
---------------------------------------------------------------------------- Layer (type) Input Shape Output Shape Param # ============================================================================ Conv2D-1 [[512, 3, 224, 224]] [512, 64, 111, 111] 3,136 Conv2D-2 [[512, 64, 111, 111]] [512, 128, 54, 54] 131,200 BatchNorm2D-1 [[512, 128, 54, 54]] [512, 128, 54, 54] 512 Conv2D-3 [[512, 128, 54, 54]] [512, 256, 26, 26] 524,544 BatchNorm2D-2 [[512, 256, 26, 26]] [512, 256, 26, 26] 1,024 Conv2D-4 [[512, 256, 26, 26]] [512, 512, 12, 12] 2,097,664 Linear-1 [[512, 10752]] [512, 4096] 44,044,288 Linear-2 [[512, 4096]] [512, 1000] 4,097,000 ============================================================================ Total params: 50,899,368 Trainable params: 50,897,832 Non-trainable params: 1,536 ---------------------------------------------------------------------------- Input size (MB): 294.00 Forward/backward pass size (MB): 7656.16 Params size (MB): 194.17 Estimated Total Size (MB): 8144.32 ----------------------------------------------------------------------------
{'total_params': 50899368, 'trainable_params': 50897832}import paddlefrom paddle.metric import Accuracyfrom paddle.vision.transforms import Compose, Normalize, Resize, Transpose, ToTensor
callback = paddle.callbacks.VisualDL(log_dir='visualdl_log_dir')
normalize = Normalize(mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5],
data_format='HWC')
transform = Compose([ToTensor(), Normalize(), Resize(size=(224,224))])
cifar10_train = paddle.vision.datasets.Cifar10(mode='train',
transform=transform)
cifar10_test = paddle.vision.datasets.Cifar10(mode='test',
transform=transform)# 构建训练集数据加载器train_loader = paddle.io.DataLoader(cifar10_train, batch_size=512, shuffle=True, drop_last=True)# 构建测试集数据加载器test_loader = paddle.io.DataLoader(cifar10_test, batch_size=512, shuffle=True, drop_last=True)
model = paddle.Model(SPP_NET())
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
model.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy()
)
model.fit(train_data=train_loader,
eval_data=test_loader,
epochs=20,
callbacks=callback,
verbose=1
)The loss value printed in the log is the current step, and the metric is the average value of previous steps. Epoch 1/20
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:654: UserWarning: When training, we now always track global mean and variance. "When training, we now always track global mean and variance.")
step 97/97 [==============================] - loss: 3.0664 - acc: 0.0645 - 963ms/step Eval begin... step 19/19 [==============================] - loss: 3.0703 - acc: 0.0659 - 693ms/step Eval samples: 9728 Epoch 2/20 step 97/97 [==============================] - loss: 3.0675 - acc: 0.0742 - 972ms/step Eval begin... step 19/19 [==============================] - loss: 3.0606 - acc: 0.0702 - 677ms/step Eval samples: 9728 Epoch 3/20 step 97/97 [==============================] - loss: 3.0885 - acc: 0.0756 - 962ms/step Eval begin... step 19/19 [==============================] - loss: 3.0654 - acc: 0.0738 - 682ms/step Eval samples: 9728 Epoch 4/20 step 97/97 [==============================] - loss: 3.0523 - acc: 0.0772 - 963ms/step Eval begin... step 19/19 [==============================] - loss: 3.0613 - acc: 0.0730 - 688ms/step Eval samples: 9728 Epoch 5/20 step 97/97 [==============================] - loss: 3.0516 - acc: 0.0836 - 970ms/step Eval begin... step 19/19 [==============================] - loss: 3.0512 - acc: 0.0791 - 701ms/step Eval samples: 9728 Epoch 6/20 step 97/97 [==============================] - loss: 3.0462 - acc: 0.0899 - 962ms/step Eval begin... step 19/19 [==============================] - loss: 3.0617 - acc: 0.0816 - 690ms/step Eval samples: 9728 Epoch 7/20 step 97/97 [==============================] - loss: 3.0466 - acc: 0.0957 - 981ms/step Eval begin... step 19/19 [==============================] - loss: 3.0432 - acc: 0.0847 - 693ms/step Eval samples: 9728 Epoch 8/20 step 97/97 [==============================] - loss: 2.9990 - acc: 0.1179 - 968ms/step Eval begin... step 19/19 [==============================] - loss: 2.9948 - acc: 0.1276 - 691ms/step Eval samples: 9728 Epoch 9/20 step 97/97 [==============================] - loss: 2.8898 - acc: 0.1448 - 984ms/step Eval begin... step 19/19 [==============================] - loss: 2.9805 - acc: 0.1280 - 700ms/step Eval samples: 9728 Epoch 10/20 step 97/97 [==============================] - loss: 2.8020 - acc: 0.1579 - 968ms/step Eval begin... step 19/19 [==============================] - loss: 2.8480 - acc: 0.1619 - 685ms/step Eval samples: 9728 Epoch 11/20 step 97/97 [==============================] - loss: 2.8151 - acc: 0.1733 - 973ms/step Eval begin... step 19/19 [==============================] - loss: 2.8623 - acc: 0.1589 - 680ms/step Eval samples: 9728 Epoch 12/20 step 97/97 [==============================] - loss: 2.8155 - acc: 0.1836 - 968ms/step Eval begin... step 19/19 [==============================] - loss: 2.8546 - acc: 0.1651 - 689ms/step Eval samples: 9728 Epoch 13/20 step 97/97 [==============================] - loss: 2.7447 - acc: 0.1943 - 971ms/step Eval begin... step 19/19 [==============================] - loss: 2.8033 - acc: 0.1772 - 712ms/step Eval samples: 9728 Epoch 14/20 step 97/97 [==============================] - loss: 2.7725 - acc: 0.2043 - 968ms/step Eval begin... step 19/19 [==============================] - loss: 2.8072 - acc: 0.1818 - 695ms/step Eval samples: 9728 Epoch 15/20 step 97/97 [==============================] - loss: 2.6786 - acc: 0.2165 - 965ms/step Eval begin... step 19/19 [==============================] - loss: 2.7682 - acc: 0.1875 - 703ms/step Eval samples: 9728 Epoch 16/20 step 97/97 [==============================] - loss: 2.6975 - acc: 0.2253 - 966ms/step Eval begin... step 19/19 [==============================] - loss: 2.7896 - acc: 0.1958 - 723ms/step Eval samples: 9728 Epoch 17/20 step 97/97 [==============================] - loss: 2.6766 - acc: 0.2398 - 993ms/step Eval begin... step 19/19 [==============================] - loss: 2.7029 - acc: 0.2032 - 685ms/step Eval samples: 9728 Epoch 18/20 step 97/97 [==============================] - loss: 2.6638 - acc: 0.2562 - 971ms/step Eval begin... step 19/19 [==============================] - loss: 2.7321 - acc: 0.2071 - 692ms/step Eval samples: 9728 Epoch 19/20 step 97/97 [==============================] - loss: 2.6738 - acc: 0.2702 - 984ms/step Eval begin... step 19/19 [==============================] - loss: 2.7565 - acc: 0.2154 - 685ms/step Eval samples: 9728 Epoch 20/20 step 97/97 [==============================] - loss: 2.6295 - acc: 0.2897 - 984ms/step Eval begin... step 19/19 [==============================] - loss: 2.6954 - acc: 0.2373 - 695ms/step Eval samples: 9728
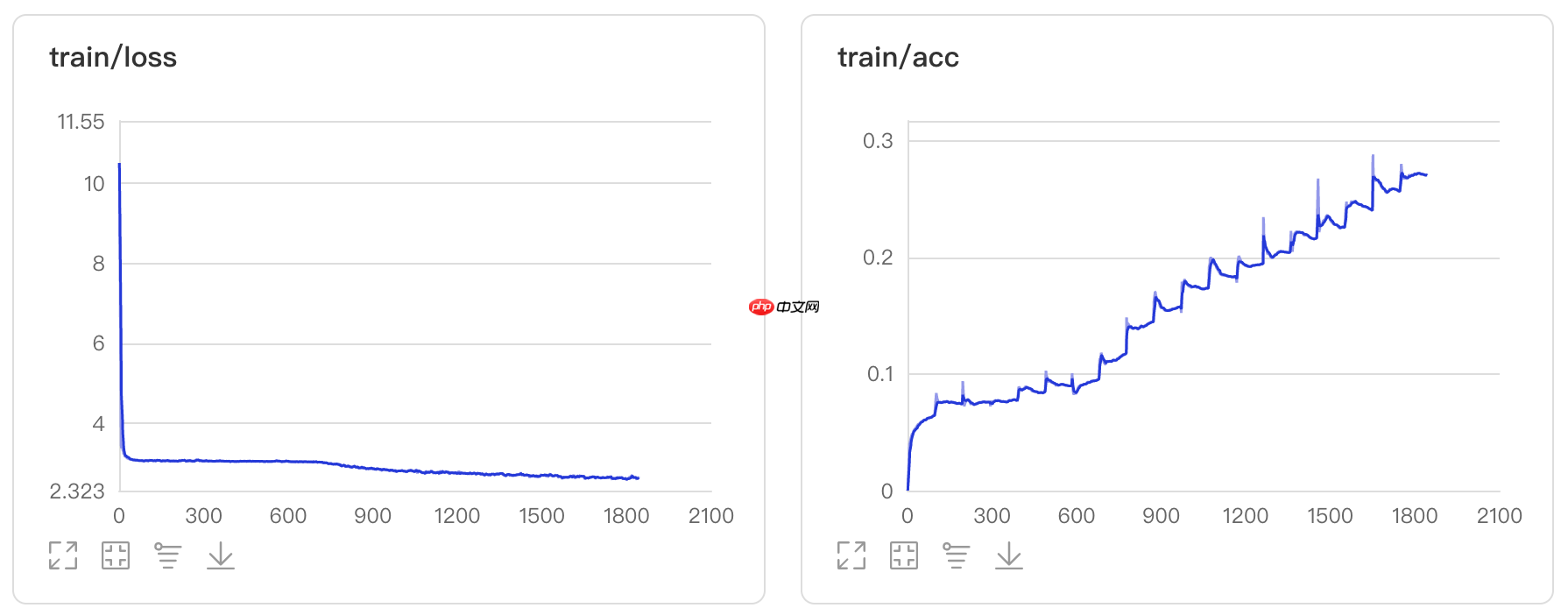
以上就是基于SPPNET的图像分类网络的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 165
165























