该方案针对飞桨点击反欺诈预测赛题,处理约50万点击数据。预处理含样本打乱,连续特征归一化、离散特征嵌入(处理高基数特征);构建双层双向GRU模型,含嵌入层、全连接层等;用Adam优化器,batch_size50,动态调学习率,最高得分88.992分,还做了模型对比与优化展望。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

作者:@LYX-夜光
广告欺诈是数字营销需要面临的重要挑战之一,点击会欺诈浪费广告主大量金钱,同时对点击数据会产生误导作用。本次比赛提供了约50万次点击数据。
特别注意: 该数据是模拟生成,对某些特征含义进行了隐藏,并进行了脱敏处理。请预测用户的点击行为是否为正常点击,还是作弊行为。点击欺诈预测适用于各种信息流广告投放,banner广告投放,以及百度网盟平台,帮助商家鉴别点击欺诈,锁定精准真实用户。
赛题链接:点击反欺诈预测
1. 样本分析: 点击反欺诈预测是一个二分类问题,对于分类问题,首先需要统计数据集正反例样本的占比,假如正例样本占比太大,可能会使模型更倾向于预测出正例的结果。因此,对于样本不平衡的数据集,一般采用上采样或下采样等方法。由于本赛题的数据集样本比较平均,因此不需要对数据集进行平衡处理。
2. 样本打乱: 将数据集中样本打乱,这样是为了防止模型在训练时记住了样本的某种顺序特性,以免影响模型的泛化能力。将打乱后的数据集的前90%作为训练集、后10%作为验证集。
3. 特征分析: 观察数据集特征,除“sid”(样本id)、“label”(分类结果)之外,数据集特征共有18个,其中“dev_height“,”dev_ppi“,”dev_width”,“timestamp”是连续特征,其余都是离散特征。连续特征与离散特征的区别是,前者存在特征值的某种大小关系,后者只存在特征值是否相等的关系。常见的连续特征处理方法有归一化、标准化等;离散特征的处理方法有独热编码(one-hot)、嵌入(embedding)等。考虑到“dev_xxx”等特征的不同取值较少,同时直观感觉这些特征的大小关系与是否欺诈的关联性不大,因此将“dev_xxx”等特征作为离散值处理。
4. 特征处理: 将连续特征归一化(value−min)/(max−min);对离散特征采用embedding,首先进行独热编码,即将离散特征值映射为0到n-1的整数,n为每个特征值的不同取值数。由于“android_id”、“package”、“fea_hash”、“fea1_hash”等特征的【不同取值的个数较多(如某特征在50W数据中有30W+的不同取值)】且【存在较多的相同取值计数小的样本(设某特征存在特征值"value1"、"value2"、...,对相同取值为"value1"、"value2"、...等样本统计样本数,数据集中存在有较多样本数少的样本)】,因此将这些相同特征值的样本数小于等于15的特征值转换为同一个值,这种处理一方面可以减少嵌入参数、缩短训练时间,另一方面减少相同特征值的样本数太少所带来的偶然性。
数据预处理部分代码如下:
# 特征处理方式,1:嵌入,2:归一化class DealType(Enum):
EMB = 1
NORM = 2
EMB_FILTER = 3# None为舍弃特征FEATURE_PATTERN = { # 'sid': None,
'android_id': DealType.EMB_FILTER, 'media_id': DealType.EMB, 'apptype': DealType.EMB, 'package': DealType.EMB_FILTER, 'version': DealType.EMB, 'ntt': DealType.EMB, 'carrier': DealType.EMB, 'os': DealType.EMB, 'osv': DealType.EMB, 'dev_height': DealType.EMB, 'dev_ppi': DealType.EMB, 'dev_width': DealType.EMB, 'lan': DealType.EMB, 'location': DealType.EMB, 'fea_hash': DealType.EMB_FILTER, 'fea1_hash': DealType.EMB_FILTER, 'cus_type': DealType.EMB, 'timestamp': DealType.NORM,
}
FEATURE_PATTERN_NEW = FEATURE_PATTERN.copy()
FEATURE_PATTERN_NEW.update({ 'android_id': DealType.EMB, 'package': DealType.EMB, 'fea_hash': DealType.EMB, 'fea1_hash': DealType.EMB
})
FEATURE_LIST = [feat for feat in FEATURE_PATTERN_NEW if FEATURE_PATTERN_NEW[feat]]# 训练集,验证集比例TRAIN_RATIO = 0.9VAL_RATIO = 0.1# 转换大离散特征for feat in FEATURE_PATTERN: if FEATURE_PATTERN[feat] == DealType.EMB_FILTER:
trainPoint = int(len(trainData[feat]) * TRAIN_RATIO)
trainValue = trainData[feat][:trainPoint]
valueDict = {value: str(value) for value in set(trainValue) if value is not np.nan}
data = trainData.iloc[:trainPoint].groupby(feat)[feat].count()
removeValue = -1
data[data <= 15] = removeValue
valueDict.update(data.loc[data == removeValue].to_dict())
trainData[feat] = trainData[feat].map(valueDict)
trainData[feat] = trainData[feat].replace({np.nan: removeValue})
testData[feat] = testData[feat].map(valueDict)
testData[feat] = testData[feat].replace({np.nan: removeValue})
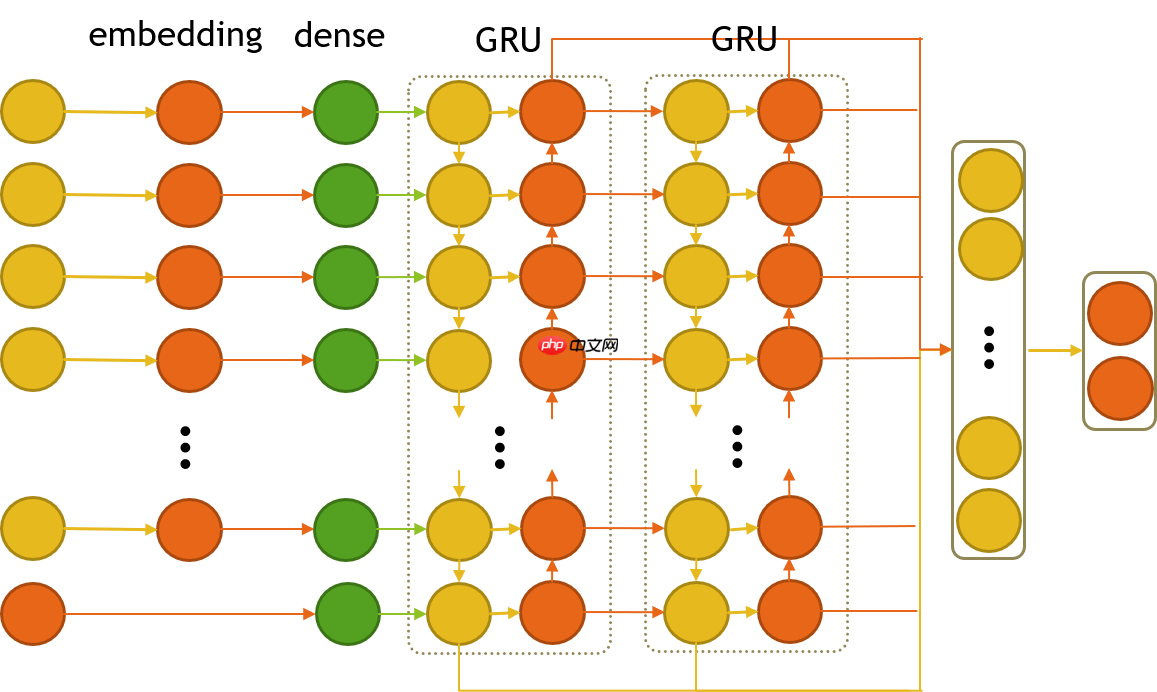
如图1,模型说明如下:
1. 嵌入层: 对离散特征采用嵌入(embedding),embedding的输出维度一般设为k⌊4size⌋(k≤16),size为某特征的不同取值数量,在这里取k=1。
2. 隐藏全连接层: 对每个连续特征和已嵌入的离散特征分别构造全连接,将全连接的输出设为同一维度n,这是为了后面可直接采用GRU网络,这里设n=1。该步骤相当于特征重建,即重新构建了与原始输入数据同一维度的特征。
3. GRU层: 考虑到特征之间存在某种关联,如有些特征同属于用户特征、有些同属于媒体特征。由于LSTM或GRU能够很好地记忆特征间关联的信息,并且GRU在很多方面比LSTM更优,同时GRU比LSTM少一个门,在运算时能节省时间,因此采用GRU。这里采用双层双向GRU,采用双向是认为特征之间前后都有关联,而不仅仅是后面的特征与前面的特征有关联,设hidden_size=18,与特征个数相同。
4. 输出全连接层: 采用两层全连接层,最后激活函数使用softmax。
组网代码:
class ConNet(paddle.nn.Layer):
def __init__(self, sizeDict: dict):
super().__init__() # 存储每个特征的隐藏层
self.hidden_layers_list = nn.LayerList([]) # 统计隐藏层输出结点
out_features = 1
for feat in FEATURE_LIST: if FEATURE_PATTERN_NEW[feat] == DealType.EMB:
embedding_dim = int(np.power(sizeDict[feat], 0.25))
hidden_layer = nn.LayerList([nn.Embedding(num_embeddings=sizeDict[feat], embedding_dim=embedding_dim),
nn.Linear(in_features=embedding_dim, out_features=out_features)]) else:
hidden_layer = nn.LayerList([nn.Linear(in_features=1, out_features=out_features)])
self.hidden_layers_list.append(hidden_layer)
feature_size, hidden_size = len(FEATURE_LIST), len(FEATURE_LIST)
self.gru = nn.GRU(input_size=out_features, hidden_size=hidden_size, time_major=True, num_layers=2, direction="bidirect", dropout=0.2)
out_layer1_in_features, out_layer1_out_features = feature_size+hidden_size*4, hidden_size
self.out_layer1 = nn.Linear(in_features=out_layer1_in_features, out_features=out_layer1_out_features)
self.out_layer2 = nn.Linear(in_features=out_layer1_out_features, out_features=2)
self.softmax = nn.Softmax() def forward(self, X):
layerList = [] for x, hidden_layers in zip(X, self.hidden_layers_list): for hidden_layer in hidden_layers:
x = hidden_layer(x) # 将[batch_size, 1, out_features] 转为 [batch_size, out_features]
layerList.append(tensor.flatten(x, start_axis=1)) # 在0维扩展维度
X = tensor.stack(layerList, 0) # [time_step, batch_size, vector_size]
# 送入GRU,将每个batch的输出拼成向量
out, hc = self.gru(X)
out = out[:, :, -1].transpose((1, 0)).unsqueeze(0) # 合并
y = tensor.concat(list(out)+list(hc), axis=1) # 把特征放入用于输出层的网络
y = self.out_layer1(y)
y = self.out_layer2(y)
y = self.softmax(y) # 返回分类结果
return y
1. batch_size: 设为50,不确定设为多大最合适,尽量保证能整除训练集数量
2. 优化器: 选择Adam,确保能够快速收敛
3. 学习率lr: 先设为0.001,训练大概30个左右epoch后,选择验证集损失(val loss)最小的模型参数,再将学习率设为0.0005,再进行训练,看情况再依次递减学习率训练
采用以上的思路,模型的预测结果分数大部分时候有88.9分以上,最高能达到88.992分
1. 特征选取对比: 刚开始没有选取所有特征,因为考虑到”android_id“等特征的不同取值数量太大,不适合用于嵌入,”os“特征取值只有两个取值,而且两个取值只有首字母大小写的区别,因此舍弃了几个特征。后面通过逐个增加特征对比,发现利用所有特征的效果最好。
2. 特征处理对比: 将“dev_xxx”等特征用【归一化】和【嵌入】作对比,发现后者【嵌入】效果较好;将“fea1_hash”特征【直接嵌入】和【特征处理:将相同取值的样本数小于等于15转化为相同值】作对比,发现后者【特征处理】效果更好;比较【特征处理:将相同取值的样本数小于等于k转化为相同值】,k取5或10时,不如k=15,k取20与15差不多;将“timestamp”特征拆分为“day”、“hour”、“minute”,再进行嵌入,效果比"timestamp"直接使用归一化差。
3. 嵌入维度对比: 将【embedding输出维度统一为同一值(如统一输出为4,8,16,32等)】与【embedding输出维度k⌊4size⌋(k≤16),k=1】作对比,发现后者优于前者;将k取值为1和2做对比,发现k=1效果较好。
4. 隐藏全连接层对比: 将隐藏全连接输出维度取1和2作对比,发现取1时较好。
5. GRU层对比: 加上GRU层明显比仅使用全连接层效果好,hidden_size采用8或32时,比采用16或18效果较差。使用双层GRU比单层效果好,三层与双层效果差不多。
6. 输出全连接层对比: 使用两层全连接层比一层效果好。
7. 优化器对比: 测试了SGD、Momentum、Adam、Adadelta等优化器,发现Adam明显优于其他优化器。
注意: 以上对比如有出入的地方,可能是因为实验做得不充分,另一方面可能由于权值初始化是随机的,无法做出比较准确的对比。
本文思路和代码参考了baseline,从一开始的86.36分,再一步步调优直到88.99分,期间遇到了很多困难,主要在调参和对比方面,随机初始权值也给模型对比带来了困难。本文的模型在训练时,有时候在epoch较大时会出现loss为nan的问题,至今也不知道为什么,应该不是学习率太大造成的;训练时有时候也没法达到88.9分,这可能是随机初始权值的问题,也可能是模型本身的问题。总之,该模型还是存在着不足。
本文思路还有几个可以优化的点:
1. 特征工程: 可以构造新的特征,或者用其他方法对特征缺失值进行填充;
2. 模型构建: 如给GRU加入注意力机制,修改模型以及对应的输出等;
3. 训练调参: 测试batch_size等参数。
最后,要感谢百度飞桨给我们免费提供算力,在AI Studio中运行项目可以同时运行3个,只要网页不关闭可以一直运行下去,在我模型调参时节约了很多时间。而且,飞桨深度学习框架用起来也很方便,能很快上手,用其他学习框架实现的代码能够很容易地用飞桨框架迁移。
总之,飞桨很不错,值得大家体验。
执行数据预处理命令:run initData.py
run initData.py
新训练集创建完成! 新测试集创建完成! =================构建特征字典================= 特征[android_id]嵌入完毕,value共13个 特征[media_id]嵌入完毕,value共292个 特征[apptype]嵌入完毕,value共89个 特征[package]嵌入完毕,value共364个 特征[version]嵌入完毕,value共23个 特征[ntt]嵌入完毕,value共8个 特征[carrier]嵌入完毕,value共5个 特征[os]嵌入完毕,value共2个 特征[osv]嵌入完毕,value共165个 特征[dev_height]嵌入完毕,value共864个 特征[dev_ppi]嵌入完毕,value共105个 特征[dev_width]嵌入完毕,value共382个 特征[lan]嵌入完毕,value共25个 特征[location]嵌入完毕,value共332个 特征[fea_hash]嵌入完毕,value共60个 特征[fea1_hash]嵌入完毕,value共627个 特征[cus_type]嵌入完毕,value共58个 特征[timestamp]统计最大最小值完毕 =================字典构建完毕=================
执行训练命令:run train.py
温馨提示:训练时间需要较久,用CPU每轮约300s-400s,最优模型参数已存储,想直接推理结果可跳过此步,若要训练需要取消如下命令的注释。
# run train.py
执行推理命令:run test.py
温馨提示:执行该命令前必须先执行run initData.py
run test.py
mode: pred - batch: 100/3000 mode: pred - batch: 200/3000 mode: pred - batch: 300/3000 mode: pred - batch: 400/3000 mode: pred - batch: 500/3000 mode: pred - batch: 600/3000 mode: pred - batch: 700/3000 mode: pred - batch: 800/3000 mode: pred - batch: 900/3000 mode: pred - batch: 1000/3000 mode: pred - batch: 1100/3000 mode: pred - batch: 1200/3000 mode: pred - batch: 1300/3000 mode: pred - batch: 1400/3000 mode: pred - batch: 1500/3000 mode: pred - batch: 1600/3000 mode: pred - batch: 1700/3000 mode: pred - batch: 1800/3000 mode: pred - batch: 1900/3000 mode: pred - batch: 2000/3000 mode: pred - batch: 2100/3000 mode: pred - batch: 2200/3000 mode: pred - batch: 2300/3000 mode: pred - batch: 2400/3000 mode: pred - batch: 2500/3000 mode: pred - batch: 2600/3000 mode: pred - batch: 2700/3000 mode: pred - batch: 2800/3000 mode: pred - batch: 2900/3000 mode: pred - batch: 3000/3000 结果文件保存至: ./results/results_0.0005_06.csv
以上就是飞桨常规赛:点击反欺诈预测 - 4月第8名方案的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 676
676

























