本文围绕RAG技术展开深度解析,介绍其基础原理,即结合信息检索与文本生成,解决大模型知识截止、深度不足等问题。还阐述核心组件,如文档加载器等,讲解文档分块策略、向量化与相似度计算,以及检索策略优化、系统集成、性能优化和实际应用案例等内容。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

RAG (Retrieval Augmented Generation) 是一种将信息检索与文本生成相结合的人工智能技术架构。它的核心思想是在生成回答之前,先从外部知识库中检索相关信息,然后基于这些检索到的信息来生成更准确、更可靠的回答。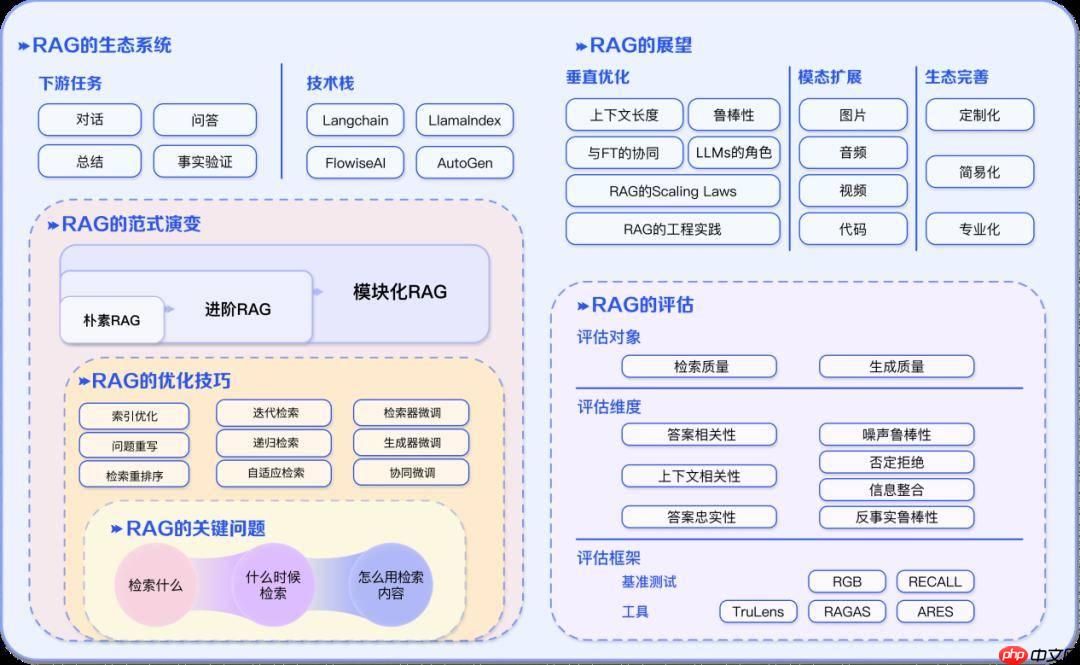
传统的大语言模型虽然具备强大的语言理解和生成能力,但存在以下几个关键问题:
知识截止时间限制:大模型的训练数据有时间边界,无法获取训练数据截止时间之后的最新信息。这意味着模型无法回答关于最新事件、技术发展或实时数据的问题。
领域知识深度不足:虽然大模型具备广泛的通用知识,但对于特定行业或专业领域的深度知识可能不够充分。例如,在医疗、法律、金融等专业领域,需要更精确和权威的信息。
知识幻觉问题:大模型有时会生成看起来合理但实际上错误的信息,这种现象被称为"幻觉"。这在需要高准确性的应用场景中是不可接受的。
无法引用来源:传统大模型无法为其回答提供具体的信息来源,这在需要验证信息准确性的场景中是一个重大缺陷。
RAG技术通过引入外部知识库,有效解决了这些问题。它将生成过程分为两个阶段:检索阶段和生成阶段。在检索阶段,系统根据用户查询从知识库中找到相关文档;在生成阶段,大模型基于检索到的文档和原始查询生成回答。
RAG系统是一个复杂的多组件系统,每个组件都发挥着关键作用:
文档加载器 (Document Loader):负责处理各种格式的原始数据源。现实世界的数据通常以多种格式存在,包括PDF文档、Word文件、网页HTML、JSON数据、CSV表格等。文档加载器需要能够解析这些不同格式,提取其中的文本内容,并保留重要的结构信息。
文本分割器 (Text Splitter):将长文档切分成适合处理的小片段。这个步骤至关重要,因为:首先,向量化模型对输入长度有限制;其次,较小的文档片段能够提供更精确的检索结果;最后,大模型的上下文窗口有限,需要提供最相关的信息片段。
向量化模型 (Embedding Model):将文本转换为高维数字向量。这些向量能够捕捉文本的语义信息,使得语义相似的文本在向量空间中距离较近。向量化是实现语义检索的基础。
向量数据库 (Vector Store):存储和管理文档向量,并提供高效的相似度搜索功能。向量数据库需要支持大规模向量的存储,并能够快速执行近似最近邻搜索。
检索器 (Retriever):根据用户查询在向量数据库中查找最相关的文档片段。检索器不仅需要考虑语义相似度,还可能需要考虑其他因素,如文档的新鲜度、权威性等。
生成模型 (Generator):基于检索到的信息和原始查询生成最终答案。生成模型需要能够综合多个信息源,产生连贯、准确的回答。
在开始实现RAG系统之前,我们需要准备开发环境并安装必要的依赖库。
import osimport reimport jsonfrom typing import List, Dict, Anyfrom openai import OpenAIimport numpy as npfrom sklearn.metrics.pairwise import cosine_similarity
client = OpenAI(
api_key=os.environ.get("*******************************"),
base_url="https://aistudio.baidu.com/llm/lmapi/v3")文档分块是RAG系统中最关键的预处理步骤之一,它直接影响到后续检索和生成的质量。
计算资源限制:大多数向量化模型对输入序列长度有严格限制。例如,许多BERT类模型的最大输入长度为512个token。如果文档过长,就需要截断或分块处理。
检索精度要求:过长的文档片段包含的信息过于宽泛,可能包含多个不相关的主题,这会降低检索的精确度。相反,过短的片段可能缺乏足够的上下文信息,导致语义表示不完整。
生成质量考虑:大模型在生成答案时需要依赖提供的上下文信息。如果上下文信息过于分散或不完整,会影响生成质量。
语义完整性保持:理想的分块应该保持语义的完整性,避免在句子中间或关键信息点进行切分。
固定长度分块是最简单直接的分块方式,它按照预设的字符数或token数对文档进行切分。这种方法的优点是实现简单、处理速度快,缺点是可能会破坏语义的完整性。
class FixedLengthSplitter:
def __init__(self, chunk_size=500, chunk_overlap=50):
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def split_text(self, text: str) -> List[str]:
chunks = []
start = 0
while start < len(text):
end = start + self.chunk_size
chunk = text[start:end]
chunks.append(chunk)
start = end - self.chunk_overlap
return chunkssample_text = """
人工智能(Artificial Intelligence,AI)是计算机科学的一个分支,它企图了解智能的实质,
并生产出一种新的能以人类智能相似的方式做出反应的智能机器。该领域的研究包括机器人、
语言识别、图像识别、自然语言处理和专家系统等。人工智能从诞生以来,理论和技术日益成熟,
应用领域也不断扩大,可以设想,未来人工智能带来的科技产品,将会是人类智慧的"容器"。
人工智能可以对人的意识、思维的信息过程的模拟。人工智能不是人的智能,但能像人那样思考、
也可能超过人的智能。
"""splitter = FixedLengthSplitter(chunk_size=100, chunk_overlap=20)
chunks = splitter.split_text(sample_text)for i, chunk in enumerate(chunks): print(f"块 {i+1}: {chunk[:50]}...")块 1: 人工智能(Artificial Intelligence,AI)是计算机科学的一个分支,它企图了解... 块 2: 的智能机器。该领域的研究包括机器人、 语言识别、图像识别、自然语言处理和专家系统等。人工智能从诞生以... 块 3: 人工智能带来的科技产品,将会是人类智慧的"容器"。 人工智能可以对人的意识、思维的信息过程的模拟。人... 块 4: ...
语义分块考虑文本的自然结构,在句子或段落边界处进行切分,从而更好地保持语义的完整性。这种方法虽然实现稍微复杂,但通常能产生更好的检索效果。
class SemanticSplitter:
def __init__(self, max_chunk_size=500):
self.max_chunk_size = max_chunk_size
def split_by_sentences(self, text: str) -> List[str]:
sentences = re.split(r'[。!?]', text)
sentences = [s.strip() for s in sentences if s.strip()]
chunks = []
current_chunk = ""
for sentence in sentences: if len(current_chunk) + len(sentence) <= self.max_chunk_size:
current_chunk += sentence + "。"
else: if current_chunk:
chunks.append(current_chunk.strip())
current_chunk = sentence + "。"
if current_chunk:
chunks.append(current_chunk.strip())
return chunkssemantic_splitter = SemanticSplitter(max_chunk_size=150)
semantic_chunks = semantic_splitter.split_by_sentences(sample_text)for i, chunk in enumerate(semantic_chunks): print(f"语义块 {i+1}: {chunk}")语义块 1: 人工智能(Artificial Intelligence,AI)是计算机科学的一个分支,它企图了解智能的实质, 并生产出一种新的能以人类智能相似的方式做出反应的智能机器。该领域的研究包括机器人、 语言识别、图像识别、自然语言处理和专家系统等。 语义块 2: 人工智能从诞生以来,理论和技术日益成熟, 应用领域也不断扩大,可以设想,未来人工智能带来的科技产品,将会是人类智慧的"容器"。人工智能可以对人的意识、思维的信息过程的模拟。人工智能不是人的智能,但能像人那样思考、 也可能超过人的智能。
递归分块是一种更加智能的分块方法,它尝试在不同层级的分隔符上进行切分,优先保持文档结构的完整性。这种方法首先尝试在段落级别分割,如果段落仍然过长,则尝试在句子级别分割,以此类推。
class RecursiveSplitter:
def __init__(self, chunk_size=500, chunk_overlap=50):
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
self.separators = ["\n\n", "\n", "。", ",", " "]
def split_text(self, text: str) -> List[str]:
return self._split_text_recursive(text, self.separators)
def _split_text_recursive(self, text: str, separators: List[str]) -> List[str]:
if len(text) <= self.chunk_size: return [text]
if not separators: return self._split_by_length(text)
separator = separators[0]
remaining_separators = separators[1:]
splits = text.split(separator)
chunks = []
current_chunk = ""
for split in splits: if len(current_chunk) + len(split) + len(separator) <= self.chunk_size:
current_chunk += split + separator else: if current_chunk:
chunks.extend(self._split_text_recursive(current_chunk, remaining_separators))
current_chunk = split + separator
if current_chunk:
chunks.extend(self._split_text_recursive(current_chunk, remaining_separators))
return chunks
def _split_by_length(self, text: str) -> List[str]:
chunks = []
start = 0
while start < len(text):
end = start + self.chunk_size
chunks.append(text[start:end])
start = end - self.chunk_overlap return chunks递归分块的分隔符优先级设计非常重要:
段落分隔符(\n\n):最高优先级,保持段落完整性
行分隔符(\n):次高优先级,保持行的完整性
句号(。):保持句子完整性
逗号(,):保持短语完整性
空格( ):最后选择,避免切断单词
文本向量化是将自然语言文本转换为计算机可以处理的数字向量的过程。这个过程是RAG系统的核心,因为它使得我们能够在数学意义上比较和检索文本的语义相似性。
词袋模型的局限性:早期的文本表示方法如词袋模型(Bag of Words)只能捕捉词汇的统计信息,无法理解词汇之间的语义关系。例如,"汽车"和"车辆"在语义上相近,但在词袋模型中被视为完全不同的词汇。
分布式语义表示:现代的向量化方法基于分布式假设,即语义相似的词汇在上下文中的出现模式相似。通过大规模语料的训练,这些方法能够学习到词汇和句子的语义表示。
上下文敏感性:先进的向量化模型(如BERT、RoBERTa等)能够根据上下文动态调整词汇的向量表示,同一个词在不同上下文中可能有不同的向量表示。
AI Studio提供了高质量的文本向量化服务,我们可以通过API调用来获取文本的向量表示。
class TextEmbedding:
def __init__(self, client):
self.client = client
self.model = "embedding-v1"
def get_embedding(self, text: str) -> List[float]:
response = self.client.embeddings.create(
model=self.model, input=[text]
) return response.data[0].embedding
def get_embeddings_batch(self, texts: List[str]) -> List[List[float]]:
response = self.client.embeddings.create(
model=self.model, input=texts
) return [item.embedding for item in response.data]embedder = TextEmbedding(client)
test_texts = [ "人工智能是计算机科学的分支", "机器学习是AI的重要组成部分", "今天天气很好"]
embeddings = embedder.get_embeddings_batch(test_texts)print(f"向量维度: {len(embeddings[0])}")print(f"第一个文本的向量前10个元素: {embeddings[0][:10]}")向量维度: 384 第一个文本的向量前10个元素: [0.11059163510799408, 0.053346846252679825, 0.027788685634732246, 0.09877453744411469, -0.013270330615341663, -0.09219077974557877, 0.03588913008570671, -0.05313871055841446, -0.07635512202978134, 0.019693773239850998]
余弦相似度是向量空间中最常用的相似度度量方法之一。它计算两个向量之间夹角的余弦值,值域为[-1,1],其中1表示完全相同,-1表示完全相反,0表示正交(无关)。
余弦相似度的优势:
长度无关性:只考虑向量的方向,不受向量长度影响
计算效率高:计算相对简单,适合大规模应用
语义解释性好:值越接近1表示语义越相似
def cosine_similarity_manual(vec1: List[float], vec2: List[float]) -> float:
vec1 = np.array(vec1)
vec2 = np.array(vec2)
dot_product = np.dot(vec1, vec2)
norm1 = np.linalg.norm(vec1)
norm2 = np.linalg.norm(vec2)
return dot_product / (norm1 * norm2)similarity_01 = cosine_similarity_manual(embeddings[0], embeddings[1])
similarity_02 = cosine_similarity_manual(embeddings[0], embeddings[2])print(f"'人工智能是计算机科学的分支' 与 '机器学习是AI的重要组成部分' 的相似度: {similarity_01:.4f}")print(f"'人工智能是计算机科学的分支' 与 '今天天气很好' 的相似度: {similarity_02:.4f}")'人工智能是计算机科学的分支' 与 '机器学习是AI的重要组成部分' 的相似度: 0.6245 '人工智能是计算机科学的分支' 与 '今天天气很好' 的相似度: 0.1879
class SimpleVectorStore:
def __init__(self, embedder):
self.embedder = embedder
self.documents = []
self.embeddings = []
def add_documents(self, texts: List[str]):
embeddings = self.embedder.get_embeddings_batch(texts)
self.documents.extend(texts)
self.embeddings.extend(embeddings)
def similarity_search(self, query: str, k: int = 3) -> List[Dict]:
query_embedding = self.embedder.get_embedding(query)
similarities = [] for i, doc_embedding in enumerate(self.embeddings):
similarity = cosine_similarity_manual(query_embedding, doc_embedding)
similarities.append({ 'index': i, 'document': self.documents[i], 'similarity': similarity
})
similarities.sort(key=lambda x: x['similarity'], reverse=True) return similarities[:k]这个简单的向量存储实现了以下核心功能:
文档添加:将新文档向量化并存储
相似度搜索:根据查询找到最相似的k个文档
结果排序:按相似度从高到低排序
虽然这个实现简单,但它展示了向量检索的基本原理。在生产环境中,我们会使用专业的向量数据库来处理大规模数据和复杂查询。
现在让我们构建一个完整的知识库,并测试基础检索功能。我们将使用一个关于人工智能技术的知识库作为示例。
knowledge_base = [ "人工智能(AI)是计算机科学的一个分支,致力于创建能够执行通常需要人类智能的任务的系统。", "机器学习是人工智能的一个子集,它使计算机能够从数据中学习而无需明确编程。", "深度学习是机器学习的一个分支,使用多层神经网络来模拟人脑的学习过程。", "自然语言处理(NLP)是AI的一个领域,专注于计算机与人类语言之间的交互。", "计算机视觉是AI的一个分支,旨在让计算机能够识别和理解视觉信息。", "强化学习是机器学习的一种类型,智能体通过与环境交互来学习最优行为。", "神经网络是受生物神经系统启发的计算模型,是深度学习的基础。", "大语言模型(LLM)是基于Transformer架构的深度学习模型,能够理解和生成人类语言。"] vector_store = SimpleVectorStore(embedder) vector_store.add_documents(knowledge_base)
知识库设计原则:
覆盖性:包含查询可能涉及的各个方面
粒度适中:每个条目包含完整但不冗余的信息
权威性:确保信息的准确性和可靠性
让我们测试检索效果:
query = "什么是深度学习?"search_results = vector_store.similarity_search(query, k=3)print(f"查询: {query}\n")for i, result in enumerate(search_results): print(f"结果 {i+1} (相似度: {result['similarity']:.4f}):") print(f" {result['document']}\n")查询: 什么是深度学习? 结果 1 (相似度: 0.7514): 深度学习是机器学习的一个分支,使用多层神经网络来模拟人脑的学习过程。 结果 2 (相似度: 0.6262): 神经网络是受生物神经系统启发的计算模型,是深度学习的基础。 结果 3 (相似度: 0.4829): 强化学习是机器学习的一种类型,智能体通过与环境交互来学习最优行为。
评估检索质量是优化RAG系统的关键步骤。我们需要建立量化指标来衡量检索结果的好坏。
精确率(Precision):检索到的相关文档占所有检索文档的比例
召回率(Recall):检索到的相关文档占所有相关文档的比例
F1分数:精确率和召回率的调和平均数
class RetrievalEvaluator:
def __init__(self, vector_store):
self.vector_store = vector_store
def evaluate_retrieval(self, test_cases: List[Dict]) -> Dict:
total_precision = 0
total_recall = 0
total_cases = len(test_cases)
for case in test_cases:
query = case['query']
relevant_docs = set(case['relevant_docs'])
retrieved_results = self.vector_store.similarity_search(query, k=5)
retrieved_docs = set(result['index'] for result in retrieved_results)
if retrieved_docs:
precision = len(relevant_docs & retrieved_docs) / len(retrieved_docs)
recall = len(relevant_docs & retrieved_docs) / len(relevant_docs) else:
precision = recall = 0
total_precision += precision
total_recall += recall
avg_precision = total_precision / total_cases
avg_recall = total_recall / total_cases
f1_score = 2 * (avg_precision * avg_recall) / (avg_precision + avg_recall) if (avg_precision + avg_recall) > 0 else 0
return { 'precision': avg_precision, 'recall': avg_recall, 'f1_score': f1_score
}**评估数据集的重要性:**构建高质量的评估数据集需要领域专家的参与,确保标注的准确性和完整性。评估数据集应该覆盖各种查询类型和难度级别。
初始检索通常基于单一的相似度计算,但实际应用中可能需要考虑多个因素。重排序(Re-ranking)机制在初始检索结果的基础上,使用更复杂的评分函数重新排序,以提高结果质量。
class SimpleReranker:
def __init__(self, embedder):
self.embedder = embedder
def rerank(self, query: str, documents: List[str], top_k: int = 3) -> List[Dict]:
query_embedding = self.embedder.get_embedding(query)
scored_docs = [] for i, doc in enumerate(documents):
doc_embedding = self.embedder.get_embedding(doc)
similarity = cosine_similarity_manual(query_embedding, doc_embedding)
keyword_score = self._keyword_overlap_score(query, doc)
combined_score = 0.7 * similarity + 0.3 * keyword_score
scored_docs.append({ 'index': i, 'document': doc, 'similarity': similarity, 'keyword_score': keyword_score, 'combined_score': combined_score
})
scored_docs.sort(key=lambda x: x['combined_score'], reverse=True) return scored_docs[:top_k]
def _keyword_overlap_score(self, query: str, document: str) -> float:
query_words = set(query.split())
doc_words = set(document.split())
if not query_words: return 0
overlap = len(query_words & doc_words) return overlap / len(query_words)多因子评分的优势:
语义相似度:捕捉深层语义关系
关键词匹配:确保重要术语的精确匹配
文档质量:可以加入文档的权威性、新鲜度等因素
用户偏好:可以结合用户的历史行为和偏好
让我们测试重排序的效果:
reranker = SimpleReranker(embedder)
query = "机器学习和深度学习的关系"candidates = [ "机器学习是人工智能的一个子集,它使计算机能够从数据中学习而无需明确编程。", "深度学习是机器学习的一个分支,使用多层神经网络来模拟人脑的学习过程。", "自然语言处理(NLP)是AI的一个领域,专注于计算机与人类语言之间的交互。",
]
reranked_results = reranker.rerank(query, candidates)print(f"查询: {query}\n")for i, result in enumerate(reranked_results): print(f"排名 {i+1}:") print(f" 文档: {result['document']}") print(f" 语义相似度: {result['similarity']:.4f}") print(f" 关键词匹配度: {result['keyword_score']:.4f}") print(f" 综合得分: {result['combined_score']:.4f}\n")一个完整的RAG系统需要将检索和生成无缝集成。系统的核心是在检索到相关信息后,如何有效地将这些信息与用户查询结合,生成高质量的答案。
Prompt工程的重要性:如何构造发送给大模型的prompt直接影响生成质量。一个好的prompt应该:
清晰地描述任务
提供充分的上下文信息
给出明确的格式要求
包含必要的约束条件
class RAGSystem:
def __init__(self, client, embedder, vector_store):
self.client = client
self.embedder = embedder
self.vector_store = vector_store
self.reranker = SimpleReranker(embedder)
def query(self, question: str, model: str = "ernie-4.5-turbo-128k-preview", top_k: int = 3) -> Dict:
retrieved_docs = self.vector_store.similarity_search(question, k=top_k)
if not retrieved_docs: return { 'answer': '抱歉,我没有找到相关信息来回答您的问题。', 'sources': []
}
context = "\n".join([doc['document'] for doc in retrieved_docs])
prompt = f"""基于以下背景信息回答问题:
背景信息:{context}问题:{question}请基于上述背景信息回答问题。如果背景信息不足以回答问题,请说明。"""
response = self.client.chat.completions.create(
model=model,
messages=[
{"role": "user", "content": prompt}
],
temperature=0.1
)
return { 'answer': response.choices[0].message.content, 'sources': retrieved_docs, 'context': context
}rag_system = RAGSystem(client, embedder, vector_store)
test_questions = [ "什么是深度学习?", "机器学习和人工智能有什么区别?", "强化学习是如何工作的?"]for question in test_questions: print(f"问题: {question}") print("-" * 50)
result = rag_system.query(question)
print("回答:") print(result['answer']) print("\n参考来源:") for i, source in enumerate(result['sources']): print(f"{i+1}. {source['document']} (相似度: {source['similarity']:.4f})") print("\n" + "="*80 + "\n")在实际应用中,用户往往需要进行多轮对话。系统需要维护对话历史,理解上下文引用,并生成连贯的回答。
class ConversationalRAG(RAGSystem):
def __init__(self, client, embedder, vector_store):
super().__init__(client, embedder, vector_store)
self.conversation_history = []
def chat(self, question: str, model: str = "ernie-4.5-turbo-128k-preview") -> Dict:
retrieved_docs = self.vector_store.similarity_search(question, k=3)
context = "\n".join([doc['document'] for doc in retrieved_docs])
messages = [
{"role": "system", "content": "你是一个AI助手,请基于提供的背景信息回答问题。"}
]
for history in self.conversation_history[-5:]:
messages.append({"role": "user", "content": history['question']})
messages.append({"role": "assistant", "content": history['answer']})
current_prompt = f"""背景信息:{context}问题:{question}"""
messages.append({"role": "user", "content": current_prompt})
response = self.client.chat.completions.create(
model=model,
messages=messages,
temperature=0.1
)
answer = response.choices[0].message.content
self.conversation_history.append({ 'question': question, 'answer': answer, 'context': context
})
return { 'answer': answer, 'sources': retrieved_docs, 'context': context
}
def clear_history(self):
self.conversation_history = []对话历史管理策略:
长度限制:只保留最近的N轮对话,避免上下文过长
相关性过滤:只保留与当前查询相关的历史对话
摘要压缩:对较长的对话历史进行摘要压缩
用户的查询可能不够清晰或完整,查询扩展可以生成更多相关的查询变体,提高检索的召回率。
class QueryExpander:
def __init__(self, client):
self.client = client
def expand_query(self, original_query: str) -> List[str]:
prompt = f"""请为以下查询生成3个相关的扩展查询,用于信息检索:
原始查询:{original_query}扩展查询应该:
1. 保持与原始查询的语义相关性
2. 使用不同的关键词和表达方式
3. 可能涵盖更具体或更一般的方面
请以JSON格式返回扩展查询列表:
{{"expanded_queries": ["查询1", "查询2", "查询3"]}}"""
response = self.client.chat.completions.create(
model="ernie-4.5-turbo-128k",
messages=[{"role": "user", "content": prompt}],
temperature=0.3,
response_format={"type": "json_object"}
)
try:
result = json.loads(response.choices[0].message.content) return result.get("expanded_queries", [original_query]) except: return [original_query]query_expander = QueryExpander(client)
original_query = "深度学习的应用"expanded_queries = query_expander.expand_query(original_query)print(f"原始查询: {original_query}")print("扩展查询:")for i, query in enumerate(expanded_queries, 1): print(f" {i}. {query}")在生产环境中,缓存是提高RAG系统性能的重要手段。合理的缓存策略可以显著减少重复计算和API调用。
class CachedRAGSystem(RAGSystem):
def __init__(self, client, embedder, vector_store, cache_size=100):
super().__init__(client, embedder, vector_store)
self.query_cache = {}
self.cache_size = cache_size
def query(self, question: str, model: str = "ernie-4.5-turbo-128k-preview", top_k: int = 3) -> Dict:
cache_key = f"{question}_{model}_{top_k}"
if cache_key in self.query_cache: print("从缓存中获取结果") return self.query_cache[cache_key]
result = super().query(question, model, top_k)
if len(self.query_cache) >= self.cache_size:
oldest_key = next(iter(self.query_cache)) del self.query_cache[oldest_key]
self.query_cache[cache_key] = result return resultclass BatchRAGProcessor:
def __init__(self, rag_system):
self.rag_system = rag_system
def process_batch(self, questions: List[str], batch_size: int = 5) -> List[Dict]:
results = []
for i in range(0, len(questions), batch_size):
batch = questions[i:i + batch_size] print(f"处理批次 {i//batch_size + 1}: {len(batch)} 个问题")
batch_results = [] for question in batch:
result = self.rag_system.query(question)
batch_results.append(result)
results.extend(batch_results)
return results让我们构建一个专门针对技术文档的问答系统,这是RAG技术的典型应用场景。
tech_docs = [ "Python是一种高级编程语言,以其简洁的语法和强大的库生态系统而闻名。", "Django是一个高级Python Web框架,鼓励快速开发和干净、实用的设计。", "Flask是一个微型Web框架,用Python编写,设计简单易用。", "NumPy是Python中科学计算的基础包,提供了强大的N维数组对象。", "Pandas是一个数据分析和操作库,提供了数据结构和数据分析工具。", "Scikit-learn是一个机器学习库,提供了简单高效的数据挖掘和数据分析工具。", "TensorFlow是一个开源机器学习框架,由Google开发。", "PyTorch是一个开源机器学习库,基于Torch库开发。"] tech_vector_store = SimpleVectorStore(embedder) tech_vector_store.add_documents(tech_docs) tech_rag = RAGSystem(client, embedder, tech_vector_store)
tech_questions = [ "Python有哪些特点?", "Django和Flask有什么区别?",
"推荐一些Python机器学习库"]print("=== 技术文档问答系统演示 ===\n")for question in tech_questions:
result = tech_rag.query(question) print(f"Q: {question}") print(f"A: {result['answer']}\n")虽然当前示例主要处理文本,但我们可以为将来的多模态扩展做准备:
class MultiModalRAGSystem:
def __init__(self, client, text_embedder):
self.client = client
self.text_embedder = text_embedder
self.text_store = SimpleVectorStore(text_embedder)
def add_text_documents(self, texts: List[str]):
self.text_store.add_documents(texts)
def query_with_context(self, question: str, context_type: str = "text") -> Dict:
if context_type == "text": return self._query_text(question) else: return {"answer": "暂不支持此类型的查询", "sources": []}
def _query_text(self, question: str) -> Dict:
retrieved_docs = self.text_store.similarity_search(question, k=3)
context = "\n".join([doc['document'] for doc in retrieved_docs])
prompt = f"""基于以下信息回答问题:
信息:{context}问题:{question}请提供准确、有用的回答。"""
response = self.client.chat.completions.create(
model="ernie-4.5-turbo-vl-preview",
messages=[{"role": "user", "content": prompt}]
)
return { 'answer': response.choices[0].message.content, 'sources': retrieved_docs
}以上就是【新手入门】检索篇 - RAG技术深度实战与优化的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 571
571























