MogaNet是高效多阶门控聚合网络,属纯卷积架构。其通过SMixer和CMixer模块,在空间和通道交互中促进多阶交互并情境化,平衡复杂度与性能。在ImageNet分类等任务表现优异,轻量版MogaNet-T以1.44G FLOPs达80.0%精度,超ParC-Net-S且节省59% FLOPs。代码复现含各组件及训练过程,实验验证了其有效性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

自从Vision Transformers(ViT)取得成功以来,对Transformers架构的探索也引发了现代ConvNets的复兴。在这项工作中,通过交互复杂性的角度来探索DNN的表示能力。经验表明,交互复杂性是视觉识别的一个容易被忽视但又必不可少的指标。因此,本文作者提出了一个新的高效ConvNet系列,名为MogaNet,以在基于ConvNet的纯模型中进行信息上下文挖掘,并在复杂度和性能方面进行了更好的权衡。在MogaNet中,通过在空间和通道交互空间中利用两个专门设计的聚合模块,促进了跨多个复杂性的交互并将其情境化。本文对ImageNet分类、COCO目标检测和ADE20K语义分割任务进行了广泛的研究。实验结果表明,MogaNet在主流场景和所有模型规模中建立了比其他流行方法更先进的新SOTA。通常,轻量级的MogaNet-T通过在ImageNet-1K上进行精确的训练设置,以1.44G的FLOPs实现80.0%的top-1精度,超过ParC-Net-S 1.4%的精度,但节省了59%(2.04G)的FLOPs。
现有方法仍然存在一个表示瓶颈:自注意力或大核卷积的朴素实现阻碍了区分性上下文信息和全局交互的建模,导致DNN与人类视觉系统之间的认知差距。为此本文从特征交互复杂性的角度提出了一种纯卷积架构MogaNet。MogaNet采用类似金字塔式ViT的架构,包括两个模块:SMixer和CMixer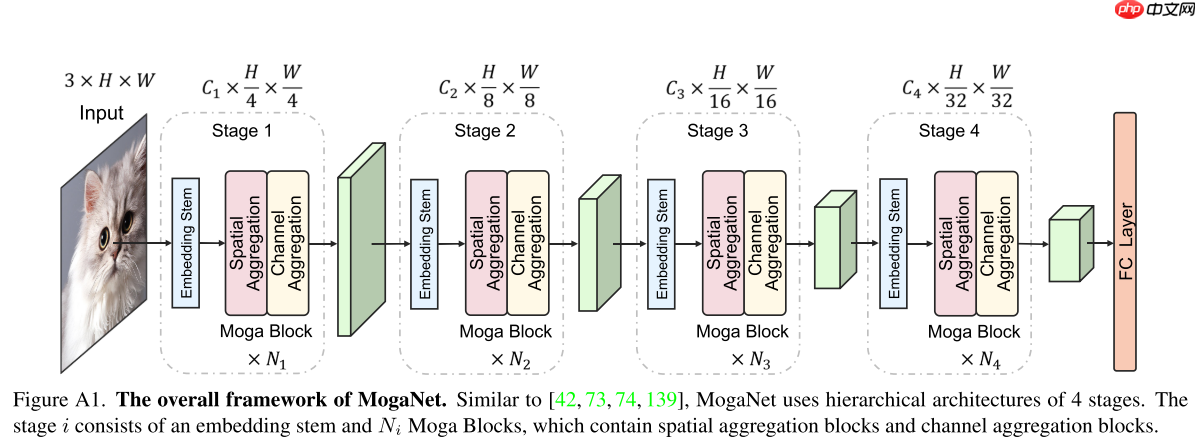
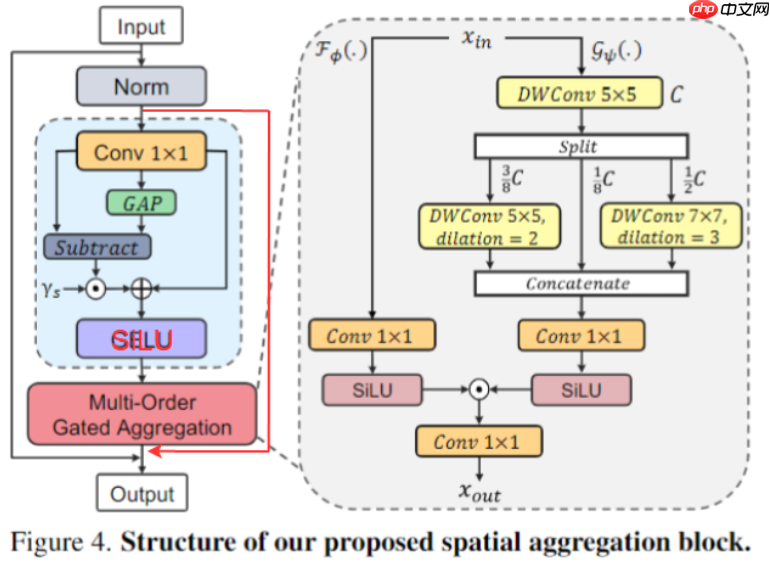
SMixer主要包括两个模块:特征分解(FD)和多阶门控聚合(Multi-Order Gated Aggregation)
为了强迫网络关注多阶交互,本文提出了FD模块,动态地排除不重要的交互(Patch自身的0阶交互【Conv2D 1 * 1】和覆盖所有Patch的n阶交互【GAP】),详细操作如下公式所示:
Y=Conv1×1(X)Z=GELU(Y+γs⊙(Y−GAP(Y)))
多阶门控聚合包含两个分支:聚合分支和上下文分支,聚合分支负责生成门控权重,上下文分支通过不同核大小和不同空洞大小的卷积进行多尺度的特征提取,从而捕获上下文多阶交互。值得注意的是,两个分支的输出使用SiLU激活函数(SILU既具有Sigmoid门控效应,又具有稳定的训练特性)。公式表示为:
Z=FϕSiLU(Conv1×1(X))⊙GψSiLU(Conv1×1(YC))
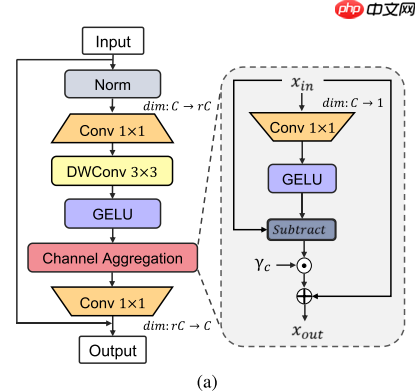
传统的FFN会导致大量的特征冗余,降低效率,本文提出了一种新的通道聚合模块以重分配多阶特征,通道聚合与FD操作类似,具体公式如下所示:
YZCA(X)=GELU(DW3×3(Conv1×1(Norm(X))))=Conv1×1(CA(Y))+X=X+γc⊙(X−GELU(XWr))
!pip install paddlex
%matplotlib inlineimport paddleimport paddle.fluid as fluidimport numpy as npimport matplotlib.pyplot as pltfrom paddle.vision.datasets import Cifar10from paddle.vision.transforms import Transposefrom paddle.io import Dataset, DataLoaderfrom paddle import nnimport paddle.nn.functional as Fimport paddle.vision.transforms as transformsimport osimport matplotlib.pyplot as pltfrom matplotlib.pyplot import figureimport paddlex
train_tfm = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
paddlex.transforms.MixupImage(),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
test_tfm = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])paddle.vision.set_image_backend('cv2')# 使用Cifar10数据集train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)print("train_dataset: %d" % len(train_dataset))print("val_dataset: %d" % len(val_dataset))train_dataset: 50000 val_dataset: 10000
batch_size=128
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss return loss.mean()def drop_path(x, drop_prob=0.0, training=False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ...
"""
if drop_prob == 0.0 or not training: return x
keep_prob = paddle.to_tensor(1 - drop_prob)
shape = (paddle.shape(x)[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
random_tensor = paddle.floor(random_tensor) # binarize
output = x.divide(keep_prob) * random_tensor return outputclass DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob def forward(self, x):
return drop_path(x, self.drop_prob, self.training)class ElementScale(nn.Layer):
"""A learnable element-wise scaler."""
def __init__(self, embed_dims, init_value=0.):
super().__init__()
self.scale =self.create_parameter((1, embed_dims, 1, 1),
default_initializer=nn.initializer.Constant(init_value)) def forward(self, x):
return x * self.scaleclass ChannelAggregationFFN(nn.Layer):
def __init__(self, embed_dims, feedforward_channels, kernel_size=3, act_fuc=nn.GELU, ffn_drop=0.):
super().__init__()
self.fc1 = nn.Conv2D(embed_dims, feedforward_channels, 1)
self.dwconv = nn.Conv2D(feedforward_channels, feedforward_channels, kernel_size, padding=kernel_size // 2, groups= feedforward_channels)
self.fc2 = nn.Conv2D(feedforward_channels, embed_dims, 1)
self.act = act_fuc()
self.drop = nn.Dropout(ffn_drop)
self.decompose = nn.Conv2D(feedforward_channels, 1, 1)
self.sigma = ElementScale(feedforward_channels, init_value=1e-5) def forward(self, x):
x = self.fc1(x)
x = self.dwconv(x)
x = self.act(x)
x = self.drop(x)
decompose = self.decompose(x)
decompose = self.act(x)
x = x + self.sigma(x - decompose)
x = self.fc2(x)
x = self.drop(x) return xclass MultiOrderDWConv(nn.Layer):
def __init__(self, embed_dims, dw_dilation=[1, 2, 3], channel_split=[1, 3, 4]):
super().__init__()
self.split_ratio = [i / sum(channel_split) for i in channel_split]
self.embed_dims = embed_dims
self.embed_dims_1 = int(embed_dims * self.split_ratio[1])
self.embed_dims_2 = int(embed_dims * self.split_ratio[2])
self.embed_dims_0 = embed_dims - self.embed_dims_1 - self.embed_dims_2 assert len(dw_dilation) == len(channel_split) == 3
assert 1 <= min(dw_dilation) and max(dw_dilation) <= 3
assert embed_dims % sum(channel_split) == 0
self.dwconv0 = nn.Conv2D(embed_dims, embed_dims, 5, padding=(1 + 4 * dw_dilation[0]) // 2,
groups=embed_dims, dilation=dw_dilation[0])
self.dwconv1 = nn.Conv2D(self.embed_dims_1, self.embed_dims_1, 5, padding=(1 + 4 * dw_dilation[1]) // 2,
groups=self.embed_dims_1, dilation=dw_dilation[1])
self.dwconv2 = nn.Conv2D(self.embed_dims_2, self.embed_dims_2, 7, padding=(1 + 6 * dw_dilation[2]) // 2,
groups=self.embed_dims_2, dilation=dw_dilation[2])
self.pwconv = nn.Conv2D(embed_dims, embed_dims, 1) def forward(self, x):
x = self.dwconv0(x)
x_1 = self.dwconv1(x[:, self.embed_dims_0:self.embed_dims_0 + self.embed_dims_1, ...])
x_2 = self.dwconv2(x[:, self.embed_dims - self.embed_dims_2:, ...])
x_0 = x[:, :self.embed_dims_0, ...]
x = paddle.concat([x_0, x_1, x_2], axis=1)
x = self.pwconv(x) return xclass MultiOrderGatedAggregation(nn.Layer):
def __init__(self, embed_dims, attn_dw_dilation=[1, 2, 3], attn_channel_split=[1, 3, 4], attn_act_fuc=nn.Silu):
super().__init__()
self.proj1 = nn.Conv2D(embed_dims, embed_dims, 1)
self.gate = nn.Conv2D(embed_dims, embed_dims, 1)
self.value = MultiOrderDWConv(embed_dims, attn_dw_dilation, attn_channel_split)
self.proj2 = nn.Conv2D(embed_dims, embed_dims, 1)
self.gate_act = attn_act_fuc()
self.value_act = attn_act_fuc()
self.act = attn_act_fuc()
self.sigma = ElementScale(embed_dims, 1e-5) def forward(self, x):
shortcut = x
x = self.proj1(x)
x = self.sigma(x - paddle.mean(x, axis=[-1, -2], keepdim=True)) + x
x = self.act(x)
x = self.gate_act(self.gate(x)) * self.value_act(self.value(x))
x = self.proj2(x)
x = x + shortcut return xclass MogaBlock(nn.Layer):
def __init__(self, embed_dims, ffn_ratio=4., drop_rate=0., drop_path_rate=0., act_fuc=nn.GELU, norm=nn.BatchNorm2D,
init_value=1e-5, attn_dw_dilation=[1, 2, 3], attn_channel_split=[1, 3, 4], attn_act_fuc=nn.Silu):
super().__init__()
self.norm1 = norm(embed_dims)
self.attn = MultiOrderGatedAggregation(embed_dims, attn_dw_dilation, attn_channel_split, attn_act_fuc)
self.norm2 = norm(embed_dims)
self.ffn = ChannelAggregationFFN(embed_dims, int(embed_dims * ffn_ratio), act_fuc=act_fuc, ffn_drop=drop_rate)
self.drop_path = DropPath(drop_path_rate) if drop_path_rate > 0. else nn.Identity()
self.layer_scales1 = self.create_parameter((1, embed_dims, 1, 1), default_initializer=nn.initializer.Constant(init_value))
self.layer_scales2 = self.create_parameter((1, embed_dims, 1, 1), default_initializer=nn.initializer.Constant(init_value)) def forward(self, x):
x = x + self.drop_path(self.layer_scales1 * self.attn(self.norm1(x)))
x = x + self.drop_path(self.layer_scales2 * self.ffn(self.norm2(x))) return xclass ConvPatchEmbed(nn.Layer):
def __init__(self, in_channels, embed_dims, kernel_size=3, stride=2, norm=nn.BatchNorm2D):
super().__init__()
self.proj = nn.Conv2D(in_channels, embed_dims, kernel_size, padding=kernel_size // 2, stride=stride)
self.norm = norm(embed_dims) def forward(self, x):
x = self.proj(x)
x = self.norm(x) return x, (x.shape[-2], x.shape[-1])class StackConvPatchEmbed(nn.Layer): # Stem
def __init__(self, in_channels, embed_dims, kernel_size=3, stride=2, act_fuc=nn.GELU, norm=nn.BatchNorm2D):
super().__init__()
self.proj = nn.Sequential(
nn.Conv2D(in_channels, embed_dims // 2, kernel_size, padding=kernel_size // 2, stride=stride),
norm(embed_dims // 2),
act_fuc(),
nn.Conv2D(embed_dims // 2, embed_dims, kernel_size, padding=kernel_size // 2, stride=stride),
)
self.norm = norm(embed_dims) def forward(self, x):
x = self.proj(x)
x = self.norm(x) return x, (x.shape[-2], x.shape[-1])class MogaNet(nn.Layer):
arch_zoo = {
**dict.fromkeys(['xt', 'x-tiny', 'xtiny'],
{'embed_dims': [32, 64, 96, 192], 'depths': [3, 3, 10, 2], 'ffn_ratios': [8, 8, 4, 4]}),
**dict.fromkeys(['t', 'tiny'],
{'embed_dims': [32, 64, 128, 256], 'depths': [3, 3, 12, 2], 'ffn_ratios': [8, 8, 4, 4]}),
**dict.fromkeys(['s', 'small'],
{'embed_dims': [64, 128, 320, 512], 'depths': [2, 3, 12, 2], 'ffn_ratios': [8, 8, 4, 4]}),
**dict.fromkeys(['b', 'base'],
{'embed_dims': [64, 160, 320, 512], 'depths': [4, 6, 22, 3], 'ffn_ratios': [8, 8, 4, 4]}),
**dict.fromkeys(['l', 'large'],
{'embed_dims': [64, 160, 320, 640], 'depths': [4, 6, 44, 4], 'ffn_ratios': [8, 8, 4, 4]}),
**dict.fromkeys(['xl', 'x-large', 'xlarge'],
{'embed_dims': [96, 192, 480, 960], 'depths': [6, 6, 44, 4], 'ffn_ratios': [8, 8, 4, 4]}),
} def __init__(self, arch='tiny', in_channels=3, num_classes=1000, drop_rate=0., drop_path_rate=0., init_value=1e-5,
patch_sizes=[3, 3, 3, 3], stem_norm=nn.BatchNorm2D, conv_norm=nn.BatchNorm2D,
patchembed_types=['ConvEmbed', 'Conv', 'Conv', 'Conv',], attn_dw_dilation=[1, 2, 3],
attn_channel_split=[1, 3, 4], attn_act_fuc=nn.Silu, attn_final_dilation=True):
super().__init__() if isinstance(arch, str):
arch = arch.lower() assert arch in set(self.arch_zoo), \ f'Arch {arch} is not in default archs {set(self.arch_zoo)}'
self.arch_settings = self.arch_zoo[arch] else:
essential_keys = {'embed_dims', 'depths', 'ffn_ratios'} assert isinstance(arch, dict) and set(arch) == essential_keys, \ f'Custom arch needs a dict with keys {essential_keys}'
self.arch_settings = arch
self.embed_dims = self.arch_settings['embed_dims']
self.depths = self.arch_settings['depths']
self.ffn_ratios = self.arch_settings['ffn_ratios']
self.num_stages = len(self.depths)
self.use_layer_norm = isinstance(stem_norm, nn.LayerNorm) assert len(patchembed_types) == self.num_stages
total_depth = sum(self.depths)
dpr = [
x.item() for x in paddle.linspace(0, drop_path_rate, total_depth)
] # stochastic depth decay rule
cur_block_idx = 0
for i, depth in enumerate(self.depths): if i == 0 and patchembed_types[i] == "ConvEmbed": assert patch_sizes[i] <= 3
patch_embed = StackConvPatchEmbed(
in_channels=in_channels,
embed_dims=self.embed_dims[i],
kernel_size=patch_sizes[i],
stride=patch_sizes[i] // 2 + 1,
act_fuc=nn.GELU,
norm=conv_norm,
) else:
patch_embed = ConvPatchEmbed(
in_channels=in_channels if i == 0 else self.embed_dims[i - 1],
embed_dims=self.embed_dims[i],
kernel_size=patch_sizes[i],
stride=patch_sizes[i] // 2 + 1,
norm=conv_norm) if i == self.num_stages - 1 and not attn_final_dilation:
attn_dw_dilation = [1, 2, 1]
blocks = nn.LayerList([
MogaBlock(
embed_dims=self.embed_dims[i],
ffn_ratio=self.ffn_ratios[i],
drop_rate=drop_rate,
drop_path_rate=dpr[cur_block_idx + j],
norm=conv_norm,
init_value=init_value,
attn_dw_dilation=attn_dw_dilation,
attn_channel_split=attn_channel_split,
attn_act_fuc=attn_act_fuc
) for j in range(depth)
])
cur_block_idx += depth
norm = stem_norm(self.embed_dims[i])
self.add_sublayer(f'patch_embed{i + 1}', patch_embed)
self.add_sublayer(f'blocks{i + 1}', blocks)
self.add_sublayer(f'norm{i + 1}', norm) # Classifier head
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dims[-1], num_classes) \ if num_classes > 0 else nn.Identity() # init for classification
self.apply(self._init_weights) def _init_weights(self, m):
tn = nn.initializer.TruncatedNormal(std=.02)
kaiming = nn.initializer.KaimingNormal()
zeros = nn.initializer.Constant(0.)
ones = nn.initializer.Constant(1.) if isinstance(m, nn.Linear):
tn(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros(m.bias) elif isinstance(m, (nn.Conv1D, nn.Conv2D)):
kaiming(m.weight) if m.bias is not None:
zeros(m.bias) elif isinstance(m, (nn.LayerNorm, nn.BatchNorm2D)):
zeros(m.bias)
ones(m.weight) def forward(self, x):
for i in range(self.num_stages):
patch_embed = getattr(self, f'patch_embed{i + 1}')
blocks = getattr(self, f'blocks{i + 1}')
norm = getattr(self, f'norm{i + 1}')
x, hw_shape = patch_embed(x) for block in blocks:
x = block(x) if self.use_layer_norm:
x = x.flatten(2).transpose([0, 2, 1])
x = norm(x)
x = x.reshape(-1, *hw_shape,
block.out_channels).transpose([0, 3, 1, 2]) else:
x = norm(x)
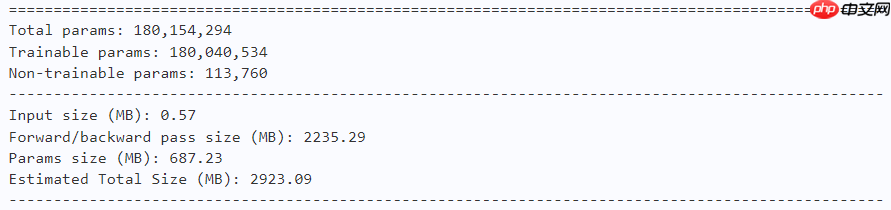
x = self.head(x.mean(axis=[2, 3])) return xmodel = MogaNet(arch='xt', num_classes=10) paddle.summary(model, (1, 3, 224, 224))
model = MogaNet(arch='t', num_classes=10) paddle.summary(model, (1, 3, 224, 224))
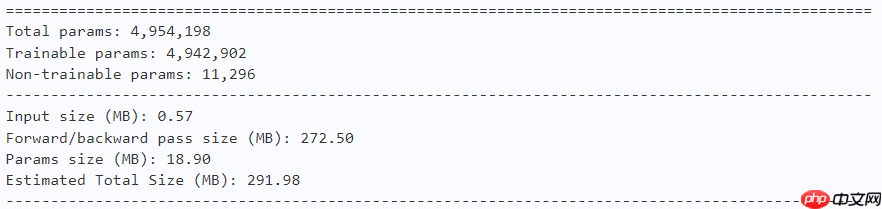
model = MogaNet(arch='s', num_classes=10) paddle.summary(model, (1, 3, 224, 224))
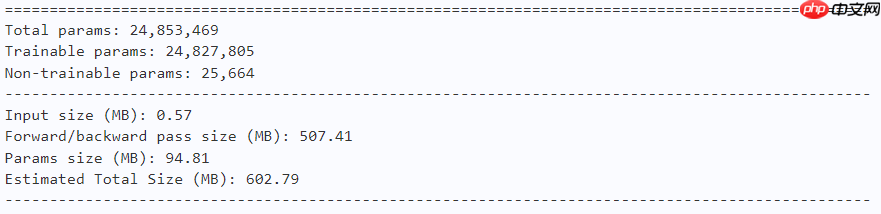
model = MogaNet(arch='b', num_classes=10) paddle.summary(model, (1, 3, 224, 224))
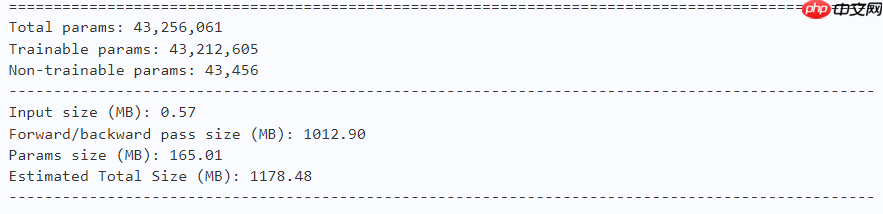
model = MogaNet(arch='l', num_classes=10) paddle.summary(model, (1, 3, 224, 224))
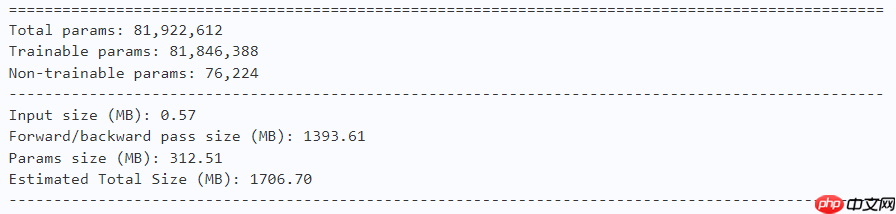
model = MogaNet(arch='xl', num_classes=10) paddle.summary(model, (1, 3, 224, 224))
learning_rate = 0.001n_epochs = 100paddle.seed(42) np.random.seed(42)
work_path = 'work/model'# MogaNet-xtmodel = MogaNet(arch='xt', num_classes=10)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0threshold = 0.0best_acc = 0.0val_acc = 0.0loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording lossacc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracyloss_iter = 0acc_iter = 0for epoch in range(n_epochs): # ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy() print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr())) for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
accuracy_manager.update(acc) if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100)) # ---------- Validation ----------
model.eval() for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter) print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100)) # ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))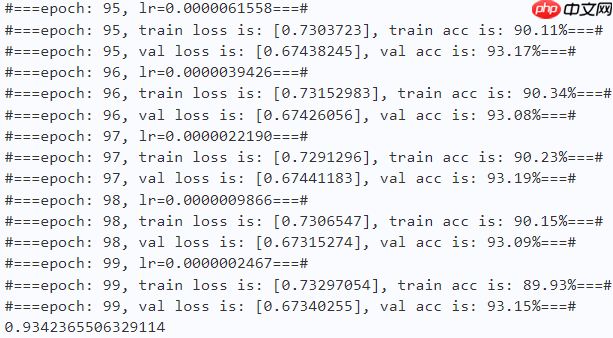
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
<Figure size 1000x600 with 1 Axes>
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
<Figure size 1000x600 with 1 Axes>
import time
work_path = 'work/model'model = MogaNet(arch='xt', num_classes=10)
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
bb = time.time()print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))Throughout:707
def get_cifar10_labels(labels):
"""返回CIFAR10数据集的文本标签。"""
text_labels = [ 'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] return [text_labels[int(i)] for i in labels]def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten() for i, (ax, img) in enumerate(zip(axes, imgs)): if paddle.is_tensor(img):
ax.imshow(img.numpy()) else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False) if pred or gt:
ax.set_title("pt: " + pred[i] + "\ngt: " + gt[i]) return axeswork_path = 'work/model'X, y = next(iter(DataLoader(val_dataset, batch_size=18))) model = MogaNet(arch='xt', num_classes=10) model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams')) model.set_state_dict(model_state_dict) model.eval() logits = model(X) y_pred = paddle.argmax(logits, -1) X = paddle.transpose(X, [0, 2, 3, 1]) axes = show_images(X.reshape((18, 224, 224, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y)) plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
<Figure size 2700x150 with 18 Axes>
!pip install interpretdl
import interpretdl as it
work_path = 'work/model'model = MogaNet(arch='xt', num_classes=10) model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams')) model.set_state_dict(model_state_dict)
X, y = next(iter(DataLoader(val_dataset, batch_size=18))) lime = it.LIMECVInterpreter(model)
lime_weights = lime.interpret(X.numpy()[3], interpret_class=y.numpy()[3], batch_size=100, num_samples=10000, visual=True)
100%|██████████| 10000/10000 [00:56<00:00, 176.50it/s]
<Figure size 640x480 with 1 Axes>
以上就是【ICLR 2024】MogaNet: 高效多阶门控聚合网络的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 317
317























