本文复现了Conv2Former模型,其采用Transformer风格的QKV结构,以卷积生成权重加权,平衡全局信息提取与计算开销。在CIFAR-10数据集上,用Conv2Former-N参数({64,128,256,512}维度,{2,2,8,2}深度)训练50个epoch,验证集准确率达82%,参数884万,优于Swin-T的75%准确率与2753万参数,展现出设计优越性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

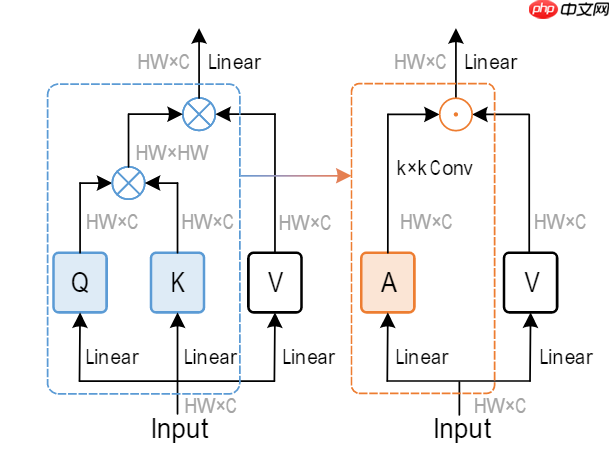
近年来,有大量的卷积模型通过堆叠不同感受野的卷积以及采用金字塔结构的网络模型提取特征,但这些模型往往忽视了全局信息的提取。直到vision transformer的提出,首次将transformer引入视觉领域,并在全局信息建模展现了更好的性能,但不可忽视的是transformer在处理高分辨率图片时会产生大量的计算开销。最近,ConvNeXt,在传统残差结构的基础上,使用了更为先进的训练技巧,使传统卷积的性能可以和ViT不相上下,这让我们重新思考能否设计一种全新的结构可以大幅减低计算开销的同时,有着transformer一样的全局特征提取的能力,Conv2Former使用了transformer一样的QKV结构,但采用卷积生成权重加权,为我们进一步设计卷积模型提供了一种思路。
 .png]
.png]
!mkdir /home/aistudio/Conv2Former-libraries !pip install paddlex -t /home/aistudio/Conv2Former-libraries
import paddleimport numpy as npfrom paddle.vision.datasets import Cifar10from paddle.vision.transforms import Transposefrom paddle.io import Dataset, DataLoaderfrom paddle import nnimport paddle.nn.functional as Fimport paddle.vision.transforms as transformsimport os#import matplotlib.pyplot as plt#from matplotlib.pyplot import figureimport sys
sys.path.append('/home/aistudio/Conv2Former-libraries')import paddlex一些训练tricks,labelsoomthing and droppath.
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss return loss.mean()def drop_path(x, drop_prob=0.0, training=False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ...
"""
if drop_prob == 0.0 or not training: return x
keep_prob = paddle.to_tensor(1 - drop_prob)
shape = (paddle.shape(x)[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
random_tensor = paddle.floor(random_tensor) # binarize
output = x.divide(keep_prob) * random_tensor return outputclass DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob def forward(self, x):
return drop_path(x, self.drop_prob, self.training)(数据集:cifar-10) 作者采用了一些常见的数据增强方式(未完全复现):MixUp、CutMix、Stochastic Depth、 Random Erasing 、Label Smoothing、RandAug 、Layer Scale
train_tfm = transforms.Compose([
transforms.Resize((32,32)),
transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2),
paddlex.transforms.MixupImage(), #transforms.Cutmix(),
transforms.RandomResizedCrop(32, scale=(0.6, 1.0)),
transforms.RandomErasing(),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
test_tfm = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
batch_size=256paddle.vision.set_image_backend('cv2')# 使用Cifar10数据集train_dataset = Cifar10(data_file='./data/cifar-10-python.tar.gz', mode='train', transform = train_tfm,)
val_dataset = Cifar10(data_file='./data/cifar-10-python.tar.gz', mode='test',transform = test_tfm)print("train_dataset: %d" % len(train_dataset))print("val_dataset: %d" % len(val_dataset))
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=2)train_dataset: 50000 val_dataset: 10000
class MLP(nn.Layer):
def __init__(self, dim, mlp_ratio=4, drop=0.,):
super().__init__()
self.norm = nn.LayerNorm(dim, epsilon=1e-6,)
self.fc1 = nn.Conv2D(dim, dim * mlp_ratio, 1)
self.pos = nn.Conv2D(dim * mlp_ratio, dim * mlp_ratio, 3, padding=1, groups=dim * mlp_ratio)
self.fc2 = nn.Conv2D(dim * mlp_ratio, dim, 1)
self.act = nn.GELU()
self.drop = nn.Dropout(drop) def forward(self, x):
B, C, H, W = x.shape
x = self.norm(x.transpose([0, 2, 3, 1])).transpose([0, 3, 1, 2])
x = self.fc1(x)
x = self.act(x)
x = x + self.act(self.pos(x))
x = self.fc2(x) return xclass ConvMod(nn.Layer):
def __init__(self, dim):
super().__init__()
self.norm = nn.LayerNorm(dim, epsilon=1e-6,)
self.a = nn.Sequential(
nn.Conv2D(dim, dim, 1),
nn.GELU(),
nn.Conv2D(dim, dim, 11, padding=5, groups=dim)
)
self.v = nn.Conv2D(dim, dim, 1)
self.proj = nn.Conv2D(dim, dim, 1) def forward(self, x):
B, C, H, W = x.shape
x = self.norm(x.transpose([0, 2, 3, 1])).transpose([0, 3, 1, 2])
a = self.a(x)
x = a * self.v(x)
x = self.proj(x) return x3.2Convolutional modulation 作者在此处采用了11乘11的大卷积核,作者通过实验,发现Conv2Former在卷积核大小进一步增大时,性能可以进一步加强,故最终将卷积核大小设置为11乘11。也许是因为这么大的感受野最后赋予了模型更强的全局信息获取能力。
class Block(nn.Layer):
def __init__(self, dim, mlp_ratio=4, drop=0., drop_path=0.,):
super().__init__()
self.attn = ConvMod(dim)
self.mlp = MLP(dim, mlp_ratio, drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity() def forward(self, x):
x = x + self.drop_path(self.attn(x))
x = x + self.drop_path(self.mlp(x)) return xclass BasicLayer(nn.Layer):
def __init__(self, dim, depth, mlp_ratio=4., drop=0., drop_path=0.,downsample=True):
super(BasicLayer, self).__init__()
self.dim = dim
self.drop_path = drop_path # build blocks
self.blocks = nn.LayerList([
Block(dim=dim, mlp_ratio=mlp_ratio, drop=drop, drop_path=drop_path[i],) for i in range(depth)
]) # patch merging layer
if downsample:
self.downsample = nn.Sequential(
nn.GroupNorm(num_groups=1, num_channels=dim),
nn.Conv2D(dim, dim * 2, kernel_size=2, stride=2,bias_attr=False)
) else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
x = blk(x) if self.downsample is not None:
x = self.downsample(x) return xclass Conv2Former(nn.Layer):
def __init__(self, num_classes=10, depths=(2,2,8,2), dim=(64,128,256,512), mlp_ratio=2.,drop_rate=0.,
drop_path_rate=0.15, **kwargs):
super().__init__()
norm_layer = nn.LayerNorm
self.num_classes = num_classes
self.num_layers = len(depths)
self.dim = dim
self.mlp_ratio = mlp_ratio
self.pos_drop = nn.Dropout(p=drop_rate) # stochastic depth decay rule
dpr = [x.item() for x in paddle.linspace(0, drop_path_rate, sum(depths))] # build layers
self.layers = nn.LayerList() for i_layer in range(self.num_layers):
layer = BasicLayer(dim[i_layer],
depth=depths[i_layer],
mlp_ratio=self.mlp_ratio,
drop=drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
downsample=(i_layer < self.num_layers - 1),
)
self.layers.append(layer)
self.fc1 = nn.Conv2D(3, 64, 1)
self.norm = norm_layer(512, epsilon=1e-6,)
self.avgpool = nn.AdaptiveAvgPool2D(1)
self.head = nn.Linear(512, num_classes) \ if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
tn = nn.initializer.TruncatedNormal(std=.02)
zeros = nn.initializer.Constant(0.)
ones = nn.initializer.Constant(1.) if isinstance(m, nn.Linear):
tn(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros(m.bias) elif isinstance(m, (nn.Conv1D, nn.Conv2D)):
tn(m.weight) if m.bias is not None:
zeros(m.bias) elif isinstance(m, (nn.LayerNorm, nn.GroupNorm)):
zeros(m.bias)
ones(m.weight) def forward_features(self, x):
x = self.fc1(x)
x = self.pos_drop(x) for layer in self.layers:
x = layer(x)
x = self.norm(x.transpose([0, 2, 3, 1]))
x = x.transpose([0, 3, 1, 2])
x = self.avgpool(x)
x = paddle.flatten(x, 1) return x def forward(self, x):
x = self.forward_features(x)
x = self.head(x) return x#参数设置learning_rate = 0.001n_epochs = 50paddle.seed(42) np.random.seed(42) batch_size = 256work_path = './work/model'
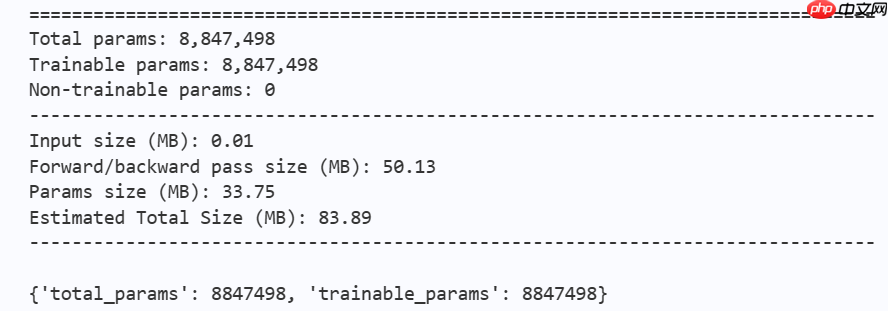
# conv2Former模型打印model = Conv2Former(num_classes=10, depths=(2,2,8,2),dim=(64,128,256,512), mlp_ratio=2,drop_path_rate=0.1) params_info=paddle.summary(model,input_size=(1, 3, 32, 32))print(params_info)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs,
verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0threshold = 0.0best_acc = 0.0val_acc = 0.0loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording lossacc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracyloss_iter = 0acc_iter = 0for epoch in range(n_epochs): # ---------- Training set----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy() print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr())) for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
accuracy_manager.update(acc) if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(),
train_acc * 100)) # ---------- Validation ----------
model.eval() for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter) print( "#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc * 100)) # ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))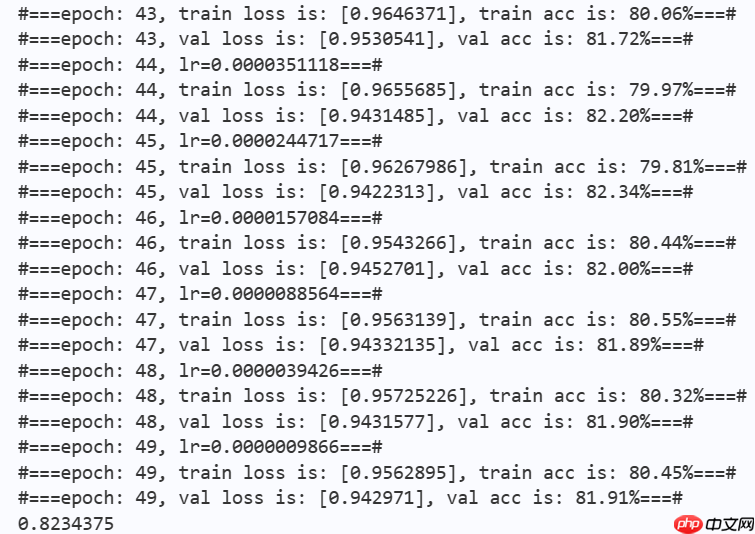
## 4.结论与讨论
4.1结论
本项目通过展现Conv2Former论文中的网络结构,对Conv2Former-N在飞桨框架下完成复现并进行初步训练,在没有预训练的基础上,对在50个epoch训练以后,模型在验证集上的准确率显著提升,在Cifar-10数据集上产生了有一定竞争力的结果,这证明了Conv2Former的模块设计具有一定的优越性,能够在大幅减少计算负担的同时,提升模型性能,同时,也为transformer的可解释性以及卷积模块的重新设计提供了新的思路。
| Model | Parameter | Val Acc |
|---|---|---|
| Conv2Former-N | 8,847,978 | 0.82 |
| Swin-T | 27,527,044 | 0.75 |
注:Swin-T实验结果来自浅析 Swin Transformer,模型为swin_tiny。
以上就是【AI达人特训营第三期】Conv2Former:一种ViT风格的卷积模块的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 249
249























