本文讲述在Jetson NX部署EfficientDet的过程。先介绍EfficientNet的复合模型扩张方法,通过平衡深度、宽度和分辨率提升性能;提及EfficientDet的BiFPN结构。接着说明将动态图转为静态图并导出,测试静态图性能,最后阐述在Jetson NX配置环境及部署流程,其期望FPS为4。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

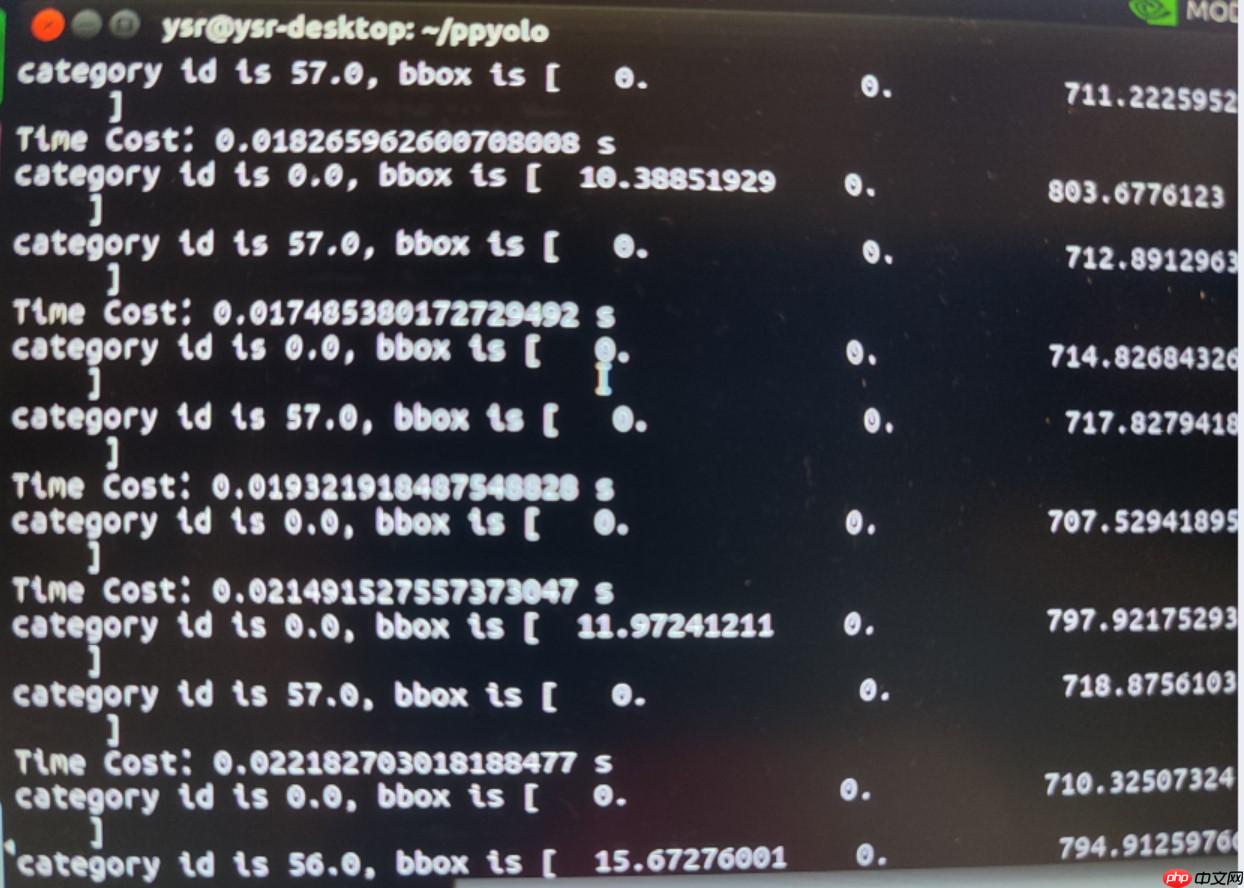
听闻jetson NX的算力很强,前几天部署了ppyolo并跑出了接近100的FPS,于是这几天尝试部署一下efficient。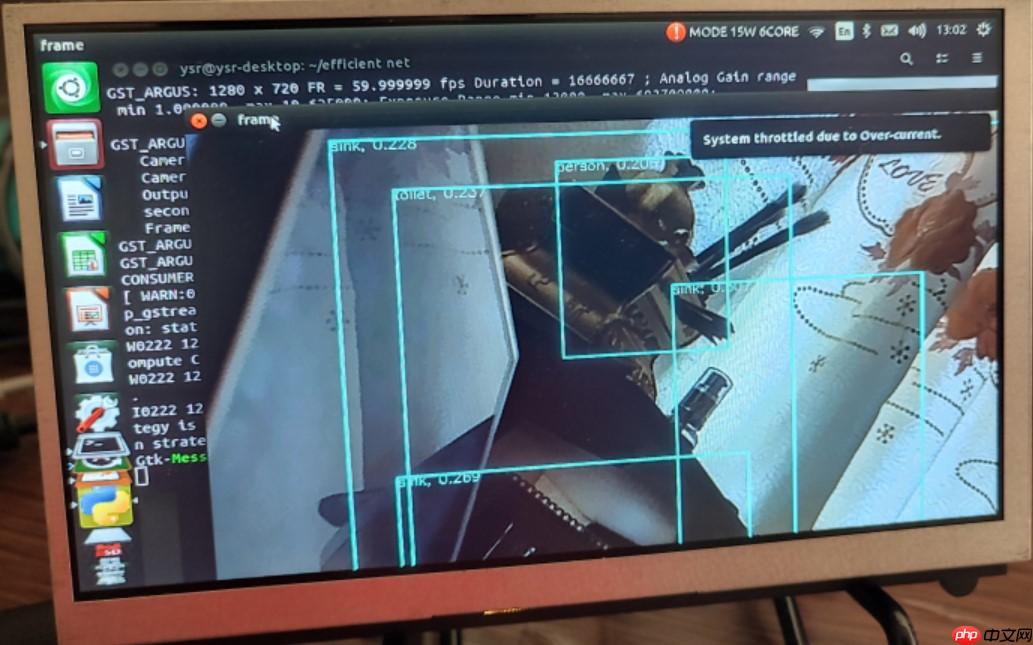
paddle在jetson NX的配置
引用了这位大佬的efficientnet
知乎
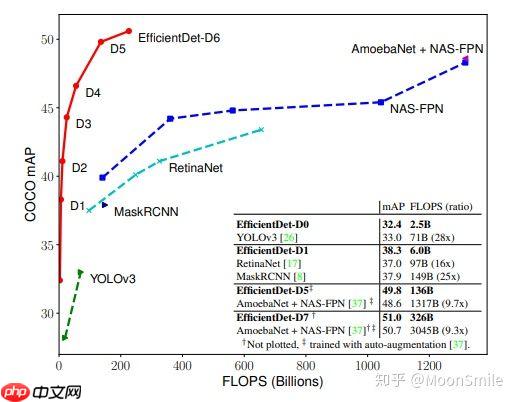
卷积神经网络扩大规模以获得更好的精度,比如可以提高网络深度(depth)、网络宽度(width)和输入图像分辨率 (resolution)大小。但是通过人工去调整 depth, width, resolution 的放大或缩小的很困难的,在计算量受限时有放大哪个缩小哪个,这些都是很难去确定的,换句话说,这样的组合空间太大,人力无法穷举。基于上述背景,该论文提出了一种新的模型缩放方法,它使用一个简单而高效的复合系数来从depth, width, resolution 三个维度放大网络,不会像传统的方法那样任意缩放网络的维度,基于神经结构搜索技术可以获得最优的一组参数(复合系数)。从下图可看出,EfficientNet不仅比别的网络快很多,而且精度也更高。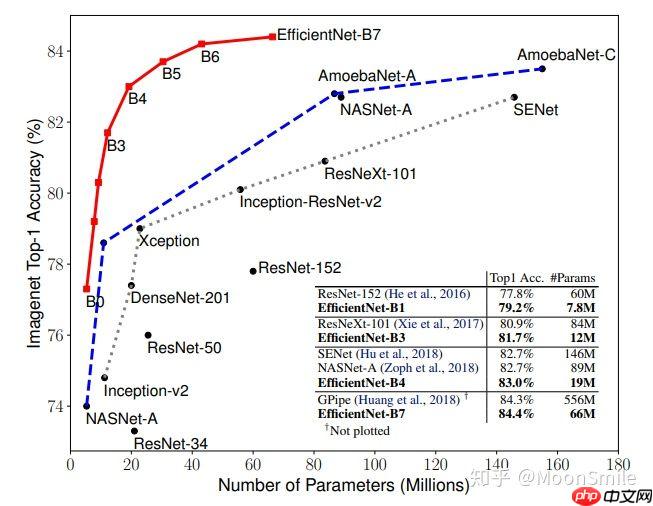
EfficientNet从三个维度均扩大了,但是扩大多少,就是通过作者提出来的复合模型扩张方法结合神经结构搜索技术获得的。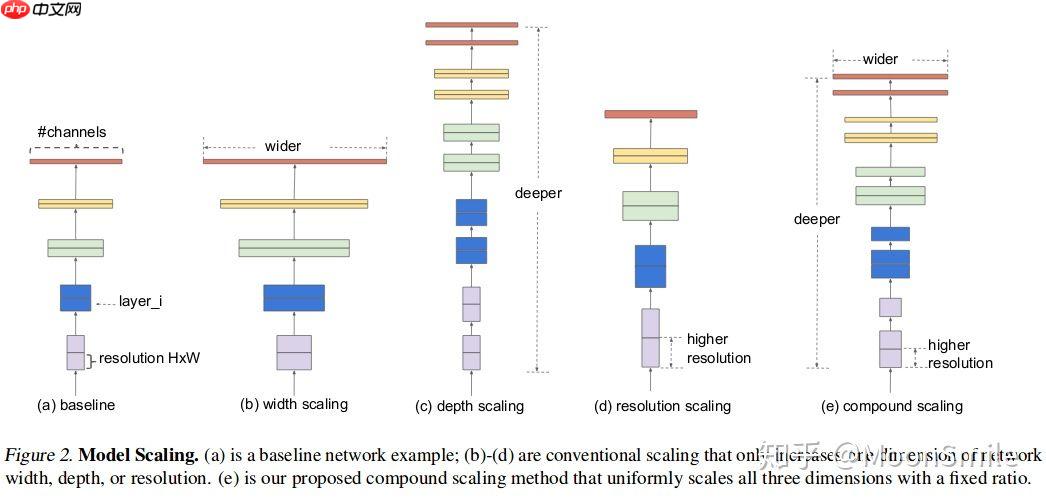
实现最优化目标。 优化目标就是在资源有限的情况下,要最大化 Accuracy, 优化目标的公式表达如下: 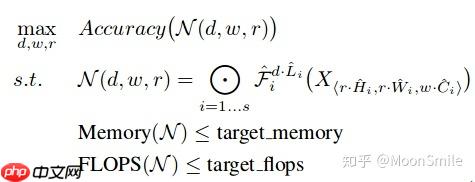 作者发现,更大的网络具有更大的宽度、深度或分辨率,往往可以获得更高的精度,但精度增益在达到80%后会迅速饱和,这表明了只对单一维度进行扩张的局限性,实验结果如下图:
作者发现,更大的网络具有更大的宽度、深度或分辨率,往往可以获得更高的精度,但精度增益在达到80%后会迅速饱和,这表明了只对单一维度进行扩张的局限性,实验结果如下图: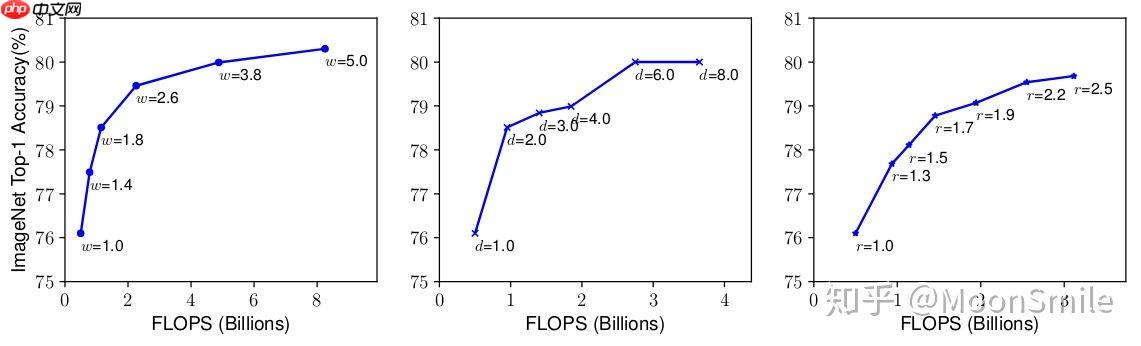
作者指出,模型扩张的各个维度之间并不是完全独立的,比如说,对于更大的分辨率图像,应该使用更深、更宽的网络,这就意味着需要平衡各个扩张维度,而不是在单一维度张扩张。
所以本文提出了复合扩张方法,这也是文章核心的地方。 
先固定公式中的一个参数,然后求别参数,从而得到基础的d0网络,然后固定其他参数,根据基础网络扩展d1以上的网络
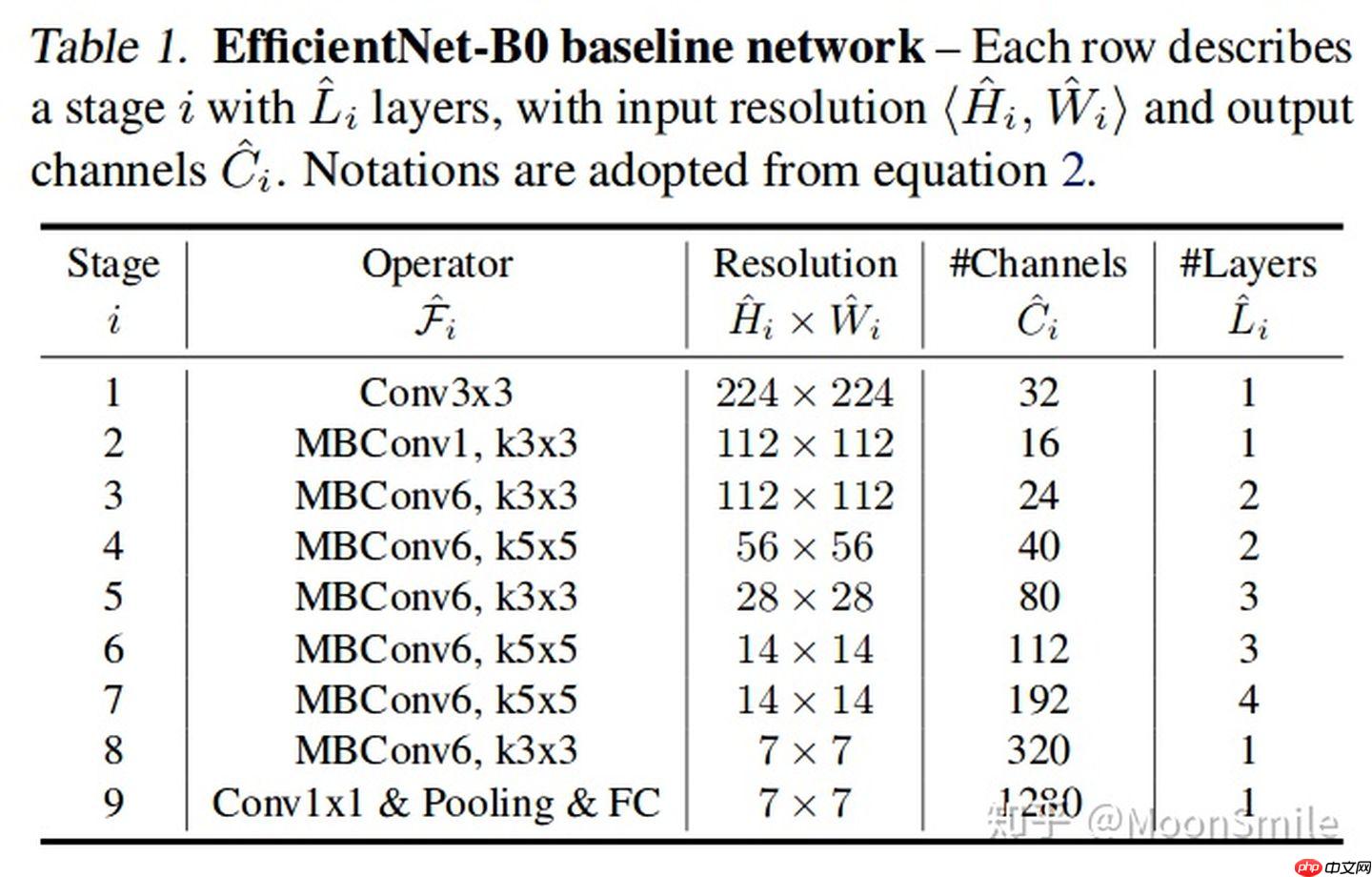
1、如何高效的进行多尺度特征融合(efficient multi-scale feature fusion):提到多尺度融合,在融合不同的输入特征时,以往的研究(FPN以及一些对FPN的改进工作)大多只是没有区别的将特征相加;然而,由于这些不同的输入特征具有不同的分辨率,我们观察到它们对融合输出特征的贡献往往是不平等的,为了解决这一问题,作者提出了一种简单而高效的加权(类似与attention)双向特征金字塔网络(BiFPN),它引入可学习的权值来学习不同输入特征的重要性,同时反复应用自顶向下和自下而上的多尺度特征融合。
2、如何对模型进行扩张(参考上文 EfficientNet ,同时考虑depth、width和resolution)
作者基于EfficientNet, 提出对检测器的backbone等网络进行模型缩放,并且结合提出的BiFPN提出了新的检测器家族,叫做EfficientDet。本文提出的检测器的主要遵循one-stage的设计思想,通过优化网络结构,可以达到更高的效率和精度。
如下图所示,BiFPN在图e的基础上增加了shortcut,这些都是在现有的一些工作的基础上添砖加瓦。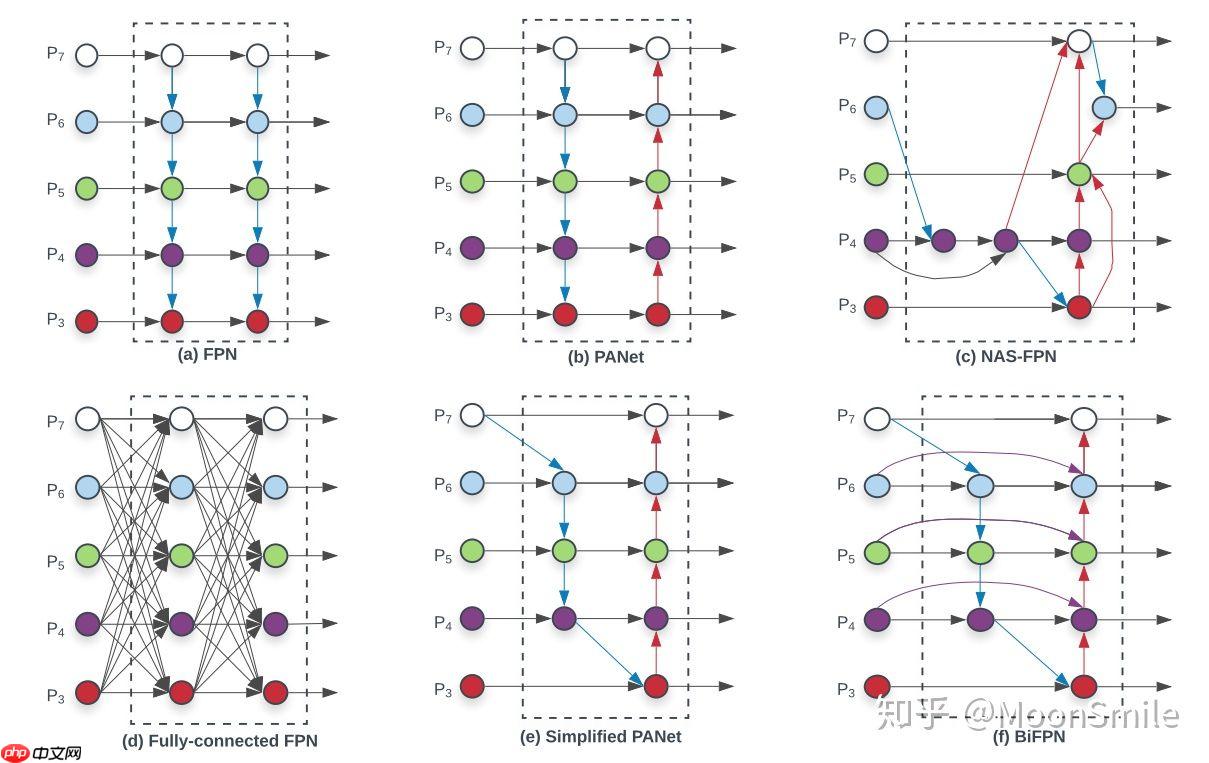
作者提出了快速的限制方法 
之前的写好的是动态图模式的复现,我们首先要将其转换成静态图模式
%cd EfficientDet/
/home/aistudio/EfficientDet
!pip install pycocotools webcolors
# 先检查动态图能不能跑通!python b.py
接下来导出静态图
注意,自定义算子的apply无法在静态图里面使用,因此如果要导出静态图,必须要先设置好自定义算子在静态静态图的运动模式
#自定义算子class SwishImplementation(PyLayer): @staticmethod
def forward(ctx, i):
result = i * F.sigmoid(i)
ctx.save_for_backward(i) return result @staticmethod
def backward(ctx, grad_output):
i = ctx.saved_tensor()[0]
sigmoid_i = F.sigmoid(i) return grad_output * (sigmoid_i * (1 + i * (1 - sigmoid_i)))# 动态图模式class MemoryEfficientSwish(nn.Layer):
def forward(self, x):
return SwishImplementation.apply(x)# 静态图的自定义算子的运用class Swish(nn.Layer):
def forward(self, x):
return x * F.sigmoid(x)# 导出静态图import paddleimport cv2import numpy as npfrom backbone import EfficientDetBackbonefrom efficientdet.utils import BBoxTransform, ClipBoxesfrom utils.utils import invert_affine, postprocess, preprocess_videoimport os
compound_coef = 0# 更改compound可以选择efficientDet的版本force_input_size = None # set None to use default sizethreshold = 0.2iou_threshold = 0.2obj_list = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', '', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', '', 'backpack', 'umbrella', '', '', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', '', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', '', 'dining table', '', '', 'toilet', '', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', '', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']# tf bilinear interpolation is different from any other's, just make doinput_sizes = [512, 640, 768, 896, 1024, 1280, 1280, 1536, 1536]
input_size = input_sizes[compound_coef] if force_input_size is None else force_input_size# load modelmodel = EfficientDetBackbone(compound_coef=compound_coef, num_classes=len(obj_list)
,onnx_export=True)
model.set_state_dict(paddle.load(f'weights/efficientdet-d{compound_coef}.pdparams'))
model.eval()
input_spec = paddle.static.InputSpec([1, 3, 512, 512], 'float32', 'image')# input_spec = paddle.static.InputSpec([None, 3, 512, 512], 'float32', 'image')# 填写底下那句,到后面None会被表示成-1,这样如果动态图里面有-1就不行了model = paddle.jit.to_static(model, input_spec=[input_spec])
paddle.jit.save(model, 'inference_models/efficientDet')# paddle.onnx.export(model, "inference", input_spec=[input_spec],opset_version=11)# 打印保存的模型文件名print(os.listdir('inference_models'))注意在设置模型输入类型时,如果动态图模式里,维度大小表示时使用了-1.则输入类型可能不能有-1
点击项目右边的数据可视化,然后选择模型文件为inference_models/efficientDet.pdmodel,然后进入可视化即可
这个模型有点大!
# Core Author: Zylo117# Script's Author: winter2897 """
Simple Inference Script of EfficientDet-Pytorch for detecting objects on webcam
"""import timeimport paddleimport cv2import numpy as npfrom efficientdet.utils import BBoxTransform, ClipBoxesfrom utils.utils import invert_affine, postprocess, preprocess_video# Video's pathvideo_src = 'video.mp4' # set int to use webcam, set str to read from a video filecompound_coef = 0force_input_size = None # set None to use default sizethreshold = 0.2iou_threshold = 0.2obj_list = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', '', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', '', 'backpack', 'umbrella', '', '', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', '', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', '', 'dining table', '', '', 'toilet', '', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', '', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']# tf bilinear interpolation is different from any other's, just make doinput_sizes = [512, 640, 768, 896, 1024, 1280, 1280, 1536, 1536]
input_size = input_sizes[compound_coef] if force_input_size is None else force_input_sizedef display(preds, imgs):
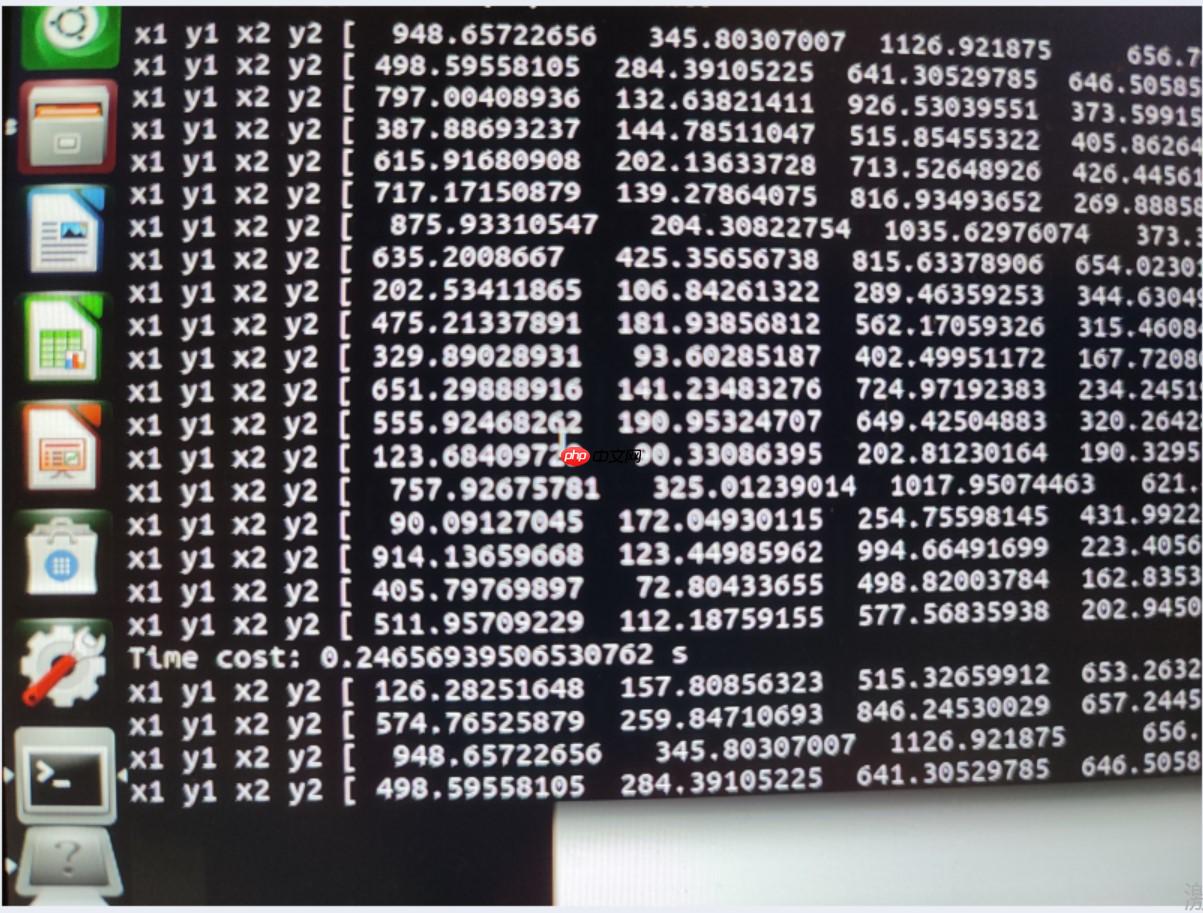
for i in range(len(imgs)): if len(preds[i]['rois']) == 0: return imgs[i] for j in range(len(preds[i]['rois'])): # print("x1 y1 x2 y2",preds[i]['rois'][j])
(x1, y1, x2, y2) = preds[i]['rois'][j].astype(np.int)
cv2.rectangle(imgs[i], (x1, y1), (x2, y2), (255, 255, 0), 2)
obj = obj_list[preds[i]['class_ids'][j]]
score = float(preds[i]['scores'][j])
cv2.putText(imgs[i], '{}, {:.3f}'.format(obj, score),
(x1, y1 + 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
(255, 255, 0), 1)
return imgs[i]# BoxregressBoxes = BBoxTransform()
clipBoxes = ClipBoxes()# Video capturecap = cv2.VideoCapture(video_src)
fourcc = cv2.VideoWriter_fourcc(*'MP4V')
fps = cap.get(cv2.CAP_PROP_FPS)
width, height = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
outvideo = cv2.VideoWriter('result.mp4', fourcc, fps, (width, height))
model = paddle.jit.load('inference_models/efficientDet')# predictor=predict_config("inference_models/u2netp.pdmodel","inference_models/u2netp.pdiparams")while True:
ret, frame = cap.read() if not ret: break
# print("frame shape is",frame.shape)
# frame preprocessing
ori_imgs, framed_imgs, framed_metas = preprocess_video(frame, max_size=input_size)
x = paddle.stack([paddle.to_tensor(fi) for fi in framed_imgs], 0)
x = x.astype(paddle.float32).transpose([0, 3, 1, 2]) # model predict
with paddle.no_grad():
# y=x.numpy().astype(np.float32)
# l=predict(predictor,[y])
time_start = time.time()
l=model(x) print('Time Cost:{}'.format(time.time()-time_start) , "s")
regression=paddle.to_tensor(l[-3]).astype(paddle.float32)
classification=paddle.to_tensor(l[-2]).astype(paddle.float32)
anchors=paddle.to_tensor(l[-1]).astype(paddle.float32) # print(l)
out = postprocess(x,
anchors, regression, classification,
regressBoxes, clipBoxes,
threshold, iou_threshold) # result
out = invert_affine(framed_metas, out)
img_show = display(out, ori_imgs) # show frame by frame
# cv2.imshow('frame',img_show)
outvideo.write(img_show) if cv2.waitKey(1) & 0xFF == ord('q'):
breakcap.release()
cv2.destroyAllWindows()import paddleimport cv2import numpy as npfrom efficientdet.utils import BBoxTransform, ClipBoxesfrom utils.utils import invert_affine, postprocess, preprocess_video# Video's pathvideo_src = 'video.mp4' # set int to use webcam, set str to read from a video filecompound_coef = 0force_input_size = None # set None to use default sizethreshold = 0.2iou_threshold = 0.2obj_list = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', '', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', '', 'backpack', 'umbrella', '', '', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', '', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', '', 'dining table', '', '', 'toilet', '', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', '', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']# tf bilinear interpolation is different from any other's, just make doinput_sizes = [512, 640, 768, 896, 1024, 1280, 1280, 1536, 1536]
input_size = input_sizes[compound_coef] if force_input_size is None else force_input_size# function for displaydef gstreamer_pipeline(
capture_width=1280,
capture_height=720,
display_width=1280,
display_height=720,
framerate=60,
flip_method=0,):
return ( "nvarguscamerasrc ! "
"video/x-raw(memory:NVMM), "
"width=(int)%d, height=(int)%d, "
"format=(string)NV12, framerate=(fraction)%d/1 ! "
"nvvidconv flip-method=%d ! "
"video/x-raw, width=(int)%d, height=(int)%d, format=(string)BGRx ! "
"videoconvert ! "
"video/x-raw, format=(string)BGR ! appsink"
% (
capture_width,
capture_height,
framerate,
flip_method,
display_width,
display_height,
)
)
def display(preds, imgs):
for i in range(len(imgs)): if len(preds[i]['rois']) == 0: return imgs[i] for j in range(len(preds[i]['rois'])): # print("x1 y1 x2 y2",preds[i]['rois'][j])
(x1, y1, x2, y2) = preds[i]['rois'][j].astype(np.int)
cv2.rectangle(imgs[i], (x1, y1), (x2, y2), (255, 255, 0), 2)
obj = obj_list[preds[i]['class_ids'][j]]
score = float(preds[i]['scores'][j])
cv2.putText(imgs[i], '{}, {:.3f}'.format(obj, score),
(x1, y1 + 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
(255, 255, 0), 1)
return imgs[i]# BoxregressBoxes = BBoxTransform()
clipBoxes = ClipBoxes()# Video capturecap = cv2.VideoCapture(gstreamer_pipeline(flip_method=0), cv2.CAP_GSTREAMER)# cap = cv2.VideoCapture(video_src)fps = cap.get(cv2.CAP_PROP_FPS)
width, height = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
model = paddle.jit.load('inference_models/efficientDet')while True:
ret, frame = cap.read() if not ret: break
# print("frame shape is",frame.shape)
# frame preprocessing
ori_imgs, framed_imgs, framed_metas = preprocess_video(frame, max_size=input_size)
x = paddle.stack([paddle.to_tensor(fi) for fi in framed_imgs], 0)
x = x.astype(paddle.float32).transpose([0, 3, 1, 2]) # model predict
with paddle.no_grad():
# y=x.numpy().astype(np.float32)
# l=predict(predictor,[y])
l=model(x)
regression=paddle.to_tensor(l[-3]).astype(paddle.float32)
classification=paddle.to_tensor(l[-2]).astype(paddle.float32)
anchors=paddle.to_tensor(l[-1]).astype(paddle.float32) # print(l)
out = postprocess(x,
anchors, regression, classification,
regressBoxes, clipBoxes,
threshold, iou_threshold) # result
out = invert_affine(framed_metas, out)
img_show = display(out, ori_imgs) # show frame by frame
cv2.imshow('frame',img_show)
if cv2.waitKey(1) & 0xFF == ord('q'):
breakcap.release()
cv2.destroyAllWindows()期望FPS为4(很慢) YOLOv4在NX上的FPS也差不多
以上就是基于efficientDet在jetson NX上实现目标检测的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 269
269























