EfficientFormer是纯Transformer模型,经优化设计,在移动设备上表现优异。最快的L1在ImageNet-1K准确率79.2%,iPhone 12延迟1.6毫秒,与MobileNetv2×1.4速度相当,证明合理设计的Transformer能兼顾低延迟与高性能。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

视觉Transformer(ViT)在计算机视觉任务中取得了迅速的进展,在各种基准上都取得了很好的结果。 然而,由于ViT模型的参数和模型设计,例如注意力机制,其速度通常比轻量级卷积网络慢几倍。 因此,面向实时应用的ViT部署尤其具有挑战性,尤其是在资源受限的硬件上,如移动设备。 近年来的研究试图通过网络结构搜索或与MobileNet块的混合设计来降低ViT的计算复杂度,但推理速度仍不尽如人意。 这就引出了一个重要的问题:Transformer能在获得高性能的同时运行得像MobileNet一样快吗? 为了回答这个问题,我们首先回顾基于ViT的模型中使用的网络架构和运算符,并识别出低效设计。 然后我们介绍了一个维度一致的纯Transformer(没有MobileNet块)作为设计范例。 最后,我们进行延迟驱动的裁剪,得到一系列最终的模型,称为EfficientFormer。 通过大量的实验,证明了该算法在移动设备性能和速度上的优越性。 我们最快的模型EfficientFormer-L1在ImageNet-1K上的准确率达到79.2%,在iPhone 12(用CoreML编译)上的推理延迟仅为1.6毫秒,运行速度与MobileNetv2×1.4(1.6毫秒,74.7%Top-1)一样快。我们最大的模型EfficientFormer-L7在ImageNet-1K上的准确率达到83.3%,延迟仅为7.0毫秒。 我们的工作证明,适当设计的Transformer可以在移动设备上达到极低的延迟,同时保持高性能。
从图2可以得到如下轻量化视觉Transformer的观察:
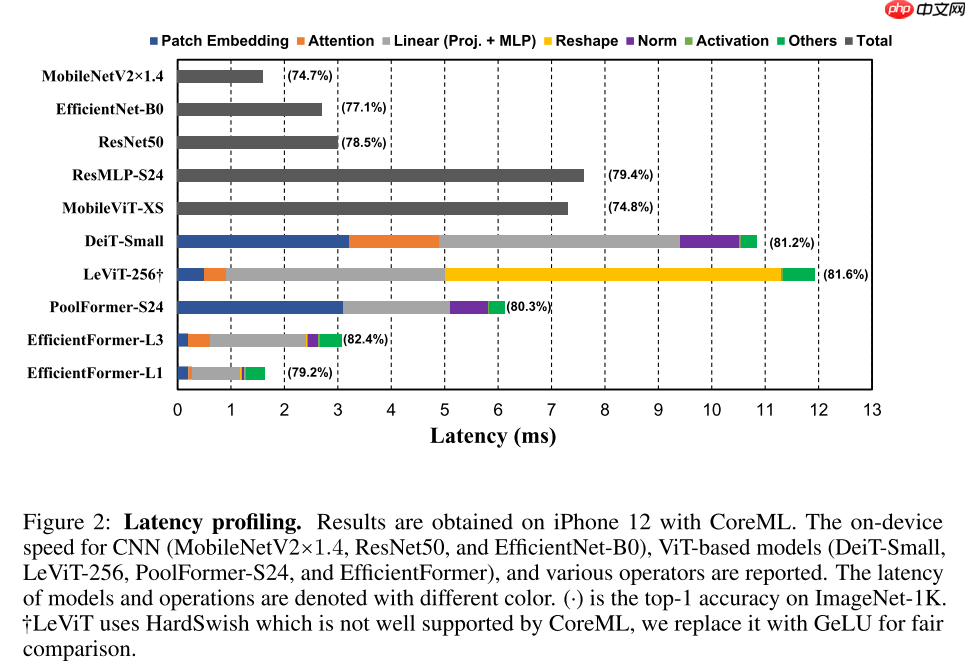
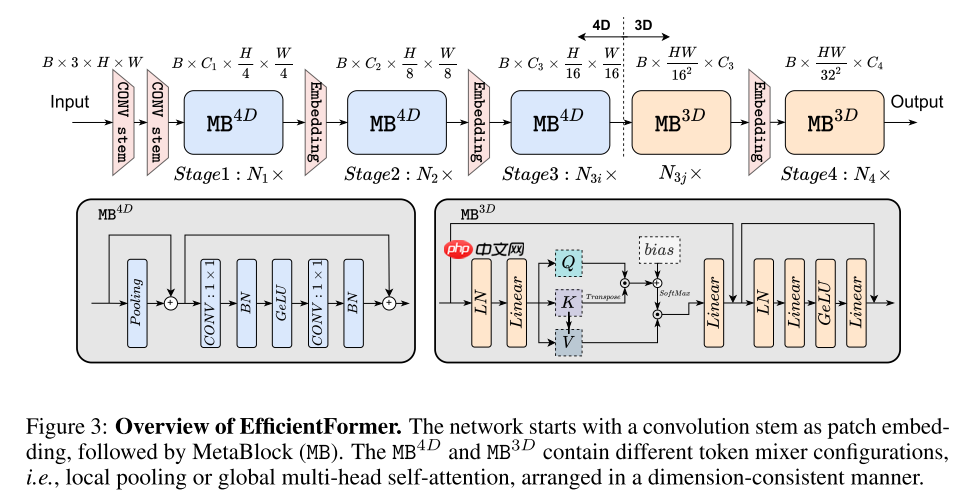
基于以上的观察,本文设计了一个新的轻量化视觉Transformer——EfficientFormer,从宏观上看,主要包含两种结构:Patch Embedding和Meta Transformer Block,用公式表示为:
Y=∏imMBi( PatchEmbed (X0B,3,H,W))Xi+1=MBi(Xi)=MLP( TokenMixer (Xi))
为了在早期捕获局部特征,本文使用类似于PoolFormer的架构(实际使用DWConv更好,但是本文想提出一个纯Transformer架构,因此没用),为了在后期捕获全局特征,本文使用原始的Transformer架构。同时,为了保证一致特征维度,早期是四维的使用卷积操作,后期是三维的使用线性层操作。
Ii=Pool(XiB,Cj,2j+1H,2j+1W)+XiB,Cj,2j+1H,2j+1W,Xi+1B,Cj,2j+1H,2j+1W=ConvB(ConvB,G(Ii))+Ii,
Ii=Linear(MHSA(Linear(LN(XiB,4j+1HW,Cj))))+XiB,4j+1HW,CjXi+1B,4j+1HW,Cj= Linear ( Linear G(LN(Ii)))+IiMHSA(Q,K,V)=Softmax(CjQ⋅KT+b)⋅V
!pip install paddlex
%matplotlib inlineimport paddleimport paddle.fluid as fluidimport numpy as npimport matplotlib.pyplot as pltfrom paddle.vision.datasets import Cifar10from paddle.vision.transforms import Transposefrom paddle.io import Dataset, DataLoaderfrom paddle import nnimport paddle.nn.functional as Fimport paddle.vision.transforms as transformsimport osimport matplotlib.pyplot as pltfrom matplotlib.pyplot import figureimport paddleximport itertools
train_tfm = transforms.Compose([
transforms.RandomResizedCrop(224, scale=(0.6, 1.0)),
transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
paddlex.transforms.MixupImage(),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
test_tfm = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])paddle.vision.set_image_backend('cv2')# 使用Cifar10数据集train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm, )
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)print("train_dataset: %d" % len(train_dataset))print("val_dataset: %d" % len(val_dataset))train_dataset: 50000 val_dataset: 10000
batch_size=256
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss return loss.mean()def drop_path(x, drop_prob=0.0, training=False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ...
"""
if drop_prob == 0.0 or not training: return x
keep_prob = paddle.to_tensor(1 - drop_prob)
shape = (paddle.shape(x)[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
random_tensor = paddle.floor(random_tensor) # binarize
output = x.divide(keep_prob) * random_tensor return outputclass DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob def forward(self, x):
return drop_path(x, self.drop_prob, self.training)class Attention(nn.Layer):
def __init__(self, dim=384, key_dim=32, num_heads=8,
attn_ratio=4,
resolution=7):
super().__init__()
self.resolution = resolution
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
h = self.dh + nh_kd * 2
self.N = resolution ** 2
self.N2 = self.N
self.qkv = nn.Linear(dim, h)
self.proj = nn.Linear(self.dh, dim)
points = list(itertools.product(range(self.resolution), range(self.resolution)))
N = len(points)
self.N = N
attention_offsets = {}
idxs = [] for p1 in points: for p2 in points:
offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1])) if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)
idxs.append(attention_offsets[offset])
self.attention_biases = self.create_parameter((len(attention_offsets), num_heads), default_initializer=nn.initializer.Constant(0.0))
self.attention_bias_idxs = idxs def forward(self, x): # x (B,N,C)
B, N, C = x.shape
qkv = self.qkv(x)
q, k, v = qkv.reshape((B, N, self.num_heads, -1)).split([self.key_dim, self.key_dim, self.d], axis=3)
q = q.transpose((0, 2, 1, 3))
k = k.transpose((0, 2, 1, 3))
v = v.transpose((0, 2, 1, 3))
attn = (q @ k.transpose((0, 1, 3, 2))) * self.scale
attn = attn + self.attention_biases[self.attention_bias_idxs].transpose((1, 0)).reshape((1, self.num_heads, self.N, self.N))
attn = F.softmax(attn, axis=-1)
x = (attn @ v).transpose((0, 2, 1, 3)).reshape((B, N, self.dh))
x = self.proj(x) return x# Conv Stemdef stem(in_chs, out_chs):
return nn.Sequential(
nn.Conv2D(in_chs, out_chs // 2, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2D(out_chs // 2),
nn.ReLU(),
nn.Conv2D(out_chs // 2, out_chs, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2D(out_chs),
nn.ReLU())class Embedding(nn.Layer):
"""
Patch Embedding that is implemented by a layer of conv.
Input: tensor in shape [B, C, H, W]
Output: tensor in shape [B, C, H/stride, W/stride]
"""
def __init__(self, patch_size=16, stride=16, padding=0,
in_chans=3, embed_dim=768, norm_layer=nn.BatchNorm2D):
super().__init__()
self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size,
stride=stride, padding=padding)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity() def forward(self, x):
x = self.proj(x)
x = self.norm(x) return xclass Flat(nn.Layer):
def __init__(self, ):
super().__init__() def forward(self, x):
x = x.flatten(2).transpose((0, 2, 1)) return xclass Pooling(nn.Layer):
"""
Implementation of pooling for PoolFormer
--pool_size: pooling size
"""
def __init__(self, pool_size=3):
super().__init__()
self.pool = nn.AvgPool2D(
pool_size, stride=1, padding=pool_size // 2) def forward(self, x):
return self.pool(x) - xclass LinearMlp(nn.Layer):
""" MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.drop1 = nn.Dropout(drop)
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop2 = nn.Dropout(drop) def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x) return xclass Mlp(nn.Layer):
"""
Implementation of MLP with 1*1 convolutions.
Input: tensor with shape [B, C, H, W]
"""
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2D(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2D(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
self.norm1 = nn.BatchNorm2D(hidden_features)
self.norm2 = nn.BatchNorm2D(out_features) def forward(self, x):
x = self.fc1(x)
x = self.norm1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.norm2(x)
x = self.drop(x) return xclass Meta3D(nn.Layer):
def __init__(self, dim, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
self.norm1 = norm_layer(dim)
self.token_mixer = Attention(dim)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = LinearMlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. \ else nn.Identity()
self.use_layer_scale = use_layer_scale if use_layer_scale:
self.layer_scale_1 = self.create_parameter([dim], default_initializer=nn.initializer.Constant(layer_scale_init_value))
self.layer_scale_2 = self.create_parameter([dim], default_initializer=nn.initializer.Constant(layer_scale_init_value)) def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(self.layer_scale_1 * self.token_mixer(self.norm1(x)))
x = x + self.drop_path(self.layer_scale_2 * self.mlp(self.norm2(x))) else:
x = x + self.drop_path(self.token_mixer(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x))) return xclass Meta4D(nn.Layer):
def __init__(self, dim, pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
self.token_mixer = Pooling(pool_size=pool_size)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. \ else nn.Identity()
self.use_layer_scale = use_layer_scale if use_layer_scale:
self.layer_scale_1 = self.create_parameter([1, dim, 1, 1],
default_initializer=nn.initializer.Constant(layer_scale_init_value))
self.layer_scale_2 = self.create_parameter([1, dim, 1, 1],
default_initializer=nn.initializer.Constant(layer_scale_init_value)) def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(self.layer_scale_1 * self.token_mixer(x))
x = x + self.drop_path(self.layer_scale_2 * self.mlp(x)) else:
x = x + self.drop_path(self.token_mixer(x))
x = x + self.drop_path(self.mlp(x)) return xdef meta_blocks(dim, index, layers,
pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm,
drop_rate=.0, drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5, vit_num=1):
blocks = [] if index == 3 and vit_num == layers[index]:
blocks.append(Flat()) for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (
block_idx + sum(layers[:index])) / (sum(layers) - 1) if index == 3 and layers[index] - block_idx <= vit_num:
blocks.append(Meta3D(
dim, mlp_ratio=mlp_ratio,
act_layer=act_layer, norm_layer=norm_layer,
drop=drop_rate, drop_path=block_dpr,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
)) else:
blocks.append(Meta4D(
dim, pool_size=pool_size, mlp_ratio=mlp_ratio,
act_layer=act_layer,
drop=drop_rate, drop_path=block_dpr,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
)) if index == 3 and layers[index] - block_idx - 1 == vit_num:
blocks.append(Flat())
blocks = nn.Sequential(*blocks) return blocksclass EfficientFormer(nn.Layer):
def __init__(self, layers, embed_dims=None,
mlp_ratios=4, downsamples=None,
pool_size=3,
norm_layer=nn.LayerNorm, act_layer=nn.GELU,
num_classes=1000,
down_patch_size=3, down_stride=2, down_pad=1,
drop_rate=0., drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5,
vit_num=0,
distillation=False):
super().__init__()
self.num_classes = num_classes
self.patch_embed = stem(3, embed_dims[0])
network = [] for i in range(len(layers)):
stage = meta_blocks(embed_dims[i], i, layers,
pool_size=pool_size, mlp_ratio=mlp_ratios,
act_layer=act_layer, norm_layer=norm_layer,
drop_rate=drop_rate,
drop_path_rate=drop_path_rate,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
vit_num=vit_num)
network.append(stage) if i >= len(layers) - 1: break
if downsamples[i] or embed_dims[i] != embed_dims[i + 1]: # downsampling between two stages
network.append(
Embedding(
patch_size=down_patch_size, stride=down_stride,
padding=down_pad,
in_chans=embed_dims[i], embed_dim=embed_dims[i + 1]
)
)
self.network = nn.LayerList(network) # Classifier head
self.norm = norm_layer(embed_dims[-1])
self.head = nn.Linear(
embed_dims[-1], num_classes) if num_classes > 0 \ else nn.Identity()
self.dist = distillation if self.dist:
self.dist_head = nn.Linear(
embed_dims[-1], num_classes) if num_classes > 0 \ else nn.Identity()
self.apply(self.cls_init_weights) # init for classification
def cls_init_weights(self, m):
tn = nn.initializer.TruncatedNormal(std=.02)
kaiming = nn.initializer.KaimingNormal()
zero = nn.initializer.Constant(0.)
one = nn.initializer.Constant(1.) if isinstance(m, nn.Linear):
tn(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zero(m.bias)
if isinstance(m, nn.Conv2D):
kaiming(m.weight) if isinstance(m, nn.Conv2D) and m.bias is not None:
zero(m.bias)
if isinstance(m, (nn.BatchNorm2D, nn.LayerNorm)):
one(m.weight)
zero(m.bias) def forward_tokens(self, x):
outs = [] for idx, block in enumerate(self.network):
x = block(x) return x def forward(self, x):
x = self.patch_embed(x)
x = self.forward_tokens(x)
x = self.norm(x) if self.dist:
cls_out = self.head(x.mean(-2)), self.dist_head(x.mean(-2)) if not self.training:
cls_out = (cls_out[0] + cls_out[1]) / 2
else:
cls_out = self.head(x.mean(-2)) # for image classification
return cls_outEfficientFormer_width = { 'l1': [48, 96, 224, 448], 'l3': [64, 128, 320, 512], 'l7': [96, 192, 384, 768],
}
EfficientFormer_depth = { 'l1': [3, 2, 6, 4], 'l3': [4, 4, 12, 6], 'l7': [6, 6, 18, 8],
}def efficientformer_l1(pretrained=False, **kwargs):
model = EfficientFormer(
layers=EfficientFormer_depth['l1'],
embed_dims=EfficientFormer_width['l1'],
downsamples=[True, True, True, True],
num_classes=10,
vit_num=1) return modeldef efficientformer_l3(pretrained=False, **kwargs):
model = EfficientFormer(
layers=EfficientFormer_depth['l3'],
embed_dims=EfficientFormer_width['l3'],
downsamples=[True, True, True, True],
num_classes=10,
vit_num=4) return modeldef efficientformer_l7(pretrained=False, **kwargs):
model = EfficientFormer(
layers=EfficientFormer_depth['l7'],
embed_dims=EfficientFormer_width['l7'],
downsamples=[True, True, True, True],
num_classes=10,
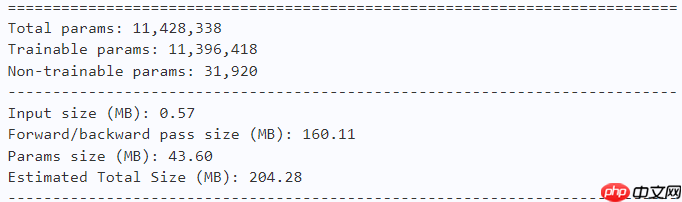
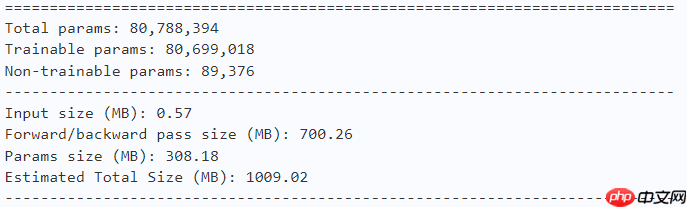
vit_num=8) return model# EfficientFormer-L1model = efficientformer_l1() paddle.summary(model, (1, 3, 224, 224))
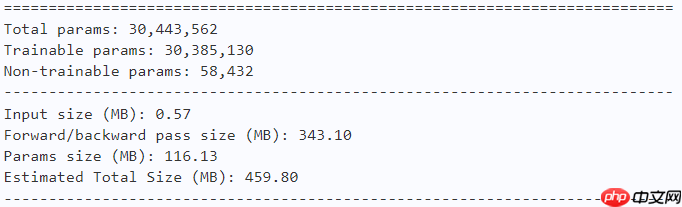
# EfficientFormer-L3model = efficientformer_l3() paddle.summary(model, (1, 3, 224, 224))
# EfficientFormer-L7model = efficientformer_l7() paddle.summary(model, (1, 3, 224, 224))
learning_rate = 0.001n_epochs = 100paddle.seed(42) np.random.seed(42)
work_path = 'work/model'# EfficientFormer-L1model = efficientformer_l1()
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0threshold = 0.0best_acc = 0.0val_acc = 0.0loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording lossacc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracyloss_iter = 0acc_iter = 0for epoch in range(n_epochs): # ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy() print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr())) for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
accuracy_manager.update(acc) if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100)) # ---------- Validation ----------
model.eval() for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100)) # ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))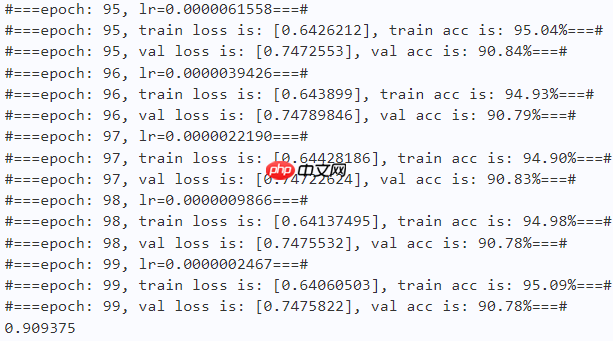
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
<Figure size 1000x600 with 1 Axes>
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
<Figure size 1000x600 with 1 Axes>
import time
work_path = 'work/model'model = efficientformer_l1()
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
bb = time.time()print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))Throughout:856
def get_cifar10_labels(labels):
"""返回CIFAR10数据集的文本标签。"""
text_labels = [ 'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] return [text_labels[int(i)] for i in labels]def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten() for i, (ax, img) in enumerate(zip(axes, imgs)): if paddle.is_tensor(img):
ax.imshow(img.numpy()) else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False) if pred or gt:
ax.set_title("pt: " + pred[i] + "\ngt: " + gt[i]) return axeswork_path = 'work/model'X, y = next(iter(DataLoader(val_dataset, batch_size=18))) model = efficientformer_l1() model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams')) model.set_state_dict(model_state_dict) model.eval() logits = model(X) y_pred = paddle.argmax(logits, -1) X = paddle.transpose(X, [0, 2, 3, 1]) axes = show_images(X.reshape((18, 224, 224, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y)) plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
<Figure size 2700x150 with 18 Axes>
!pip install interpretdl
import interpretdl as it
work_path = 'work/model'model = efficientformer_l1() model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams')) model.set_state_dict(model_state_dict)
X, y = next(iter(DataLoader(val_dataset, batch_size=18))) lime = it.LIMECVInterpreter(model)
lime_weights = lime.interpret(X.numpy()[3], interpret_class=y.numpy()[3], batch_size=100, num_samples=10000, visual=True)
100%|██████████| 10000/10000 [00:50<00:00, 196.29it/s]
<Figure size 640x480 with 1 Axes>
以上就是EfficientFormer: 速度上可以与MobileNet媲美的ViT的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 346
346























