






该方案针对PALM病理性近视预测任务,曾获五月第八、六月三十第一。通过眼底照片分类区分正常与病变眼球,数据分辨率较高,需注意显存问题。思路参考相关方案,预处理采用调整亮度、大小及翻转旋转等,经网格调参确定最优组合,用对应模型训练,最后批量预测生成结果。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

常规赛:PALM病理性近视预测
比赛链接
本方案是五月份第八名&截至六月三十第一名
1.比赛介绍
使用模型对上百张眼底照片进行分类,区分出其中正常和病变的眼球。
2.数据特点
随便打开几张训练集图片,发现数据集有这些特点:
图片的分辨率较高,2124124 x 2056的分辨率是四百万像素
这个大小的图片,远远比手写数字之类的图片大,但也不是极大的医学影像数据集,像于Kaggle上肾脏坏掉的那个比赛的数据集,单张图片3GB以上
所以在Aistudio上运行时需要特别注意模型大小,图片resize大小,batch_size三者的关系,实测32G爆显存是很正常的事情
观察图片
发现所有图片都是一个色调,黑乎乎的
所有图片都差不多是个正方形
图片中亮点都在左边,或上或下
3.思路
项目的思路,主要参考自:PaddleX超简单之--【常规赛:PALM病理性近视预测】第二名方案

实现步骤分别是:数据读取,数据预处理,模型加载训练,预测数据
这里主要是数据预处理上使用了很多思路:
标注人员或者专业医生应该能在室内不同光环境下看出来哪张眼球有问题,所以预处理可以调整亮度和对比度
标注人员或者专业医生或许隔着老远看照片就能分辨出来哪个有问题,所以预处理调整图片小
标注人员或者专业医生应该侧着眼瞅,或者反着拿的情况下也能分辨病变与否,所以预处理多尝试几种随机的翻转和旋转变换
4.实现
4.1 安装必要的库
pip install paddlex -i https://mirror.baidu.com/pypi/simple pip install paddle2onnx -i https://mirror.baidu.com/pypi/simple
4.2划分训练集和验证集
注意:这里发布的项目并不包含数据,建议读者搜索到PALM数据集,解压到'dataset/Train/'直接使用
import pandas as pdimport random
train_excel_file = 'dataset/Train/Classification.xlsx'pd_list=pd.read_excel(train_excel_file)
pd_list_lenght=len(pd_list)# 乱序pd_list=pd_list.sample(frac=1)
offset=int(pd_list_lenght*0.9)
trian_list=pd_list[:offset]
eval_list=pd_list[offset:]
trian_list.to_csv("train_list.txt", index=None, header=None, sep=' ')
eval_list.to_csv("eval_list.txt", index=None, header=None, sep=' ')
# 设置使用0号GPU卡(如无GPU,执行此代码后仍然会使用CPU训练模型)import matplotlib
matplotlib.use('Agg')
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'import paddlex as pdx
4.3 数据预处理
类似于sklearn.GridSearchCV的方法进行网格调参找水平翻转,垂直翻转,旋转角度的最优组合
{'transforms.RandomHorizontalFlip":[0.4,0.5,0.6]}
{'transforms.RandomVerticalFlip':[0.3,0.5,0.7]}
{'transforms.RandomRotate':[rotate_range=30,45,60,75]}
各种尝试下的结果
| crop_size | RandomHorizontalFlip | RandomRotate | RandomVerticalFlip | score | backbone | model_zoo |
|---|---|---|---|---|---|---|
| 224 | 0.6 | 75 | 0.5 | 0.99643 | ResNet50_vd_ssld | 点击查看 |
| 224 | 0.6 | 60 | 0.7 | 0.99636 | ResNet50_vd_ssld | |
| 1440 | 0.6 | 45 | 0.2 | 0.9991 | MobileNetV3_large_ssld | 点击查看 |
| 1440 | 0.6 | 45 | 0.2 | 不太行 | ResNet50_vd_ssld | |
| 1440 | 0.2 | 45 | 0.2 | 0.983 | MobileNetV3_large_ssld |
from paddlex.cls import transforms
train_transforms = transforms.Compose([
transforms.RandomCrop(crop_size=1440),
transforms.RandomHorizontalFlip(0.9),
transforms.RandomRotate(rotate_range=45),
transforms.RandomVerticalFlip(0.2),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.ResizeByShort(short_size=1440),
transforms.CenterCrop(crop_size=1440),
transforms.Normalize()
])
from paddlex.cls import transforms
train_transforms = transforms.Compose([
transforms.RandomCrop(crop_size=224),
transforms.RandomHorizontalFlip(0.6),
transforms.RandomRotate(rotate_range=75),
transforms.RandomVerticalFlip(0.6),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.ResizeByShort(short_size=256),
transforms.CenterCrop(crop_size=224),
transforms.Normalize()
])
4.4读取数据集
train_dataset = pdx.datasets.ImageNet(
data_dir='dataset/Train/fundus_image',
file_list='train_list.txt',
label_list='labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='dataset/Train/fundus_image',
file_list='eval_list.txt',
label_list='labels.txt',
transforms=eval_transforms)
2021-06-20 22:11:56 [INFO] Starting to read file list from dataset... 2021-06-20 22:11:56 [INFO] 720 samples in file train_list.txt 2021-06-20 22:11:56 [INFO] Starting to read file list from dataset... 2021-06-20 22:11:56 [INFO] 80 samples in file eval_list.txt
4.5 开始训练
# model = pdx.cls.ResNet50_vd_ssld(num_classes=2)# model = pdx.cls.ResNet101_vd_ssld(num_classes=2)model = pdx.cls.MobileNetV3_large_ssld(num_classes=2)
model.train(num_epochs=25,
train_dataset=train_dataset,
train_batch_size=8,
eval_dataset=eval_dataset,
lr_decay_epochs=[10, 15, 20],
save_interval_epochs=5,
learning_rate=0.03,
save_dir='output/ResNet50_vd_ssld7',
use_vdl=True)
这里选择了use_vdl=True后,会得到训练中参数的变化
训练过程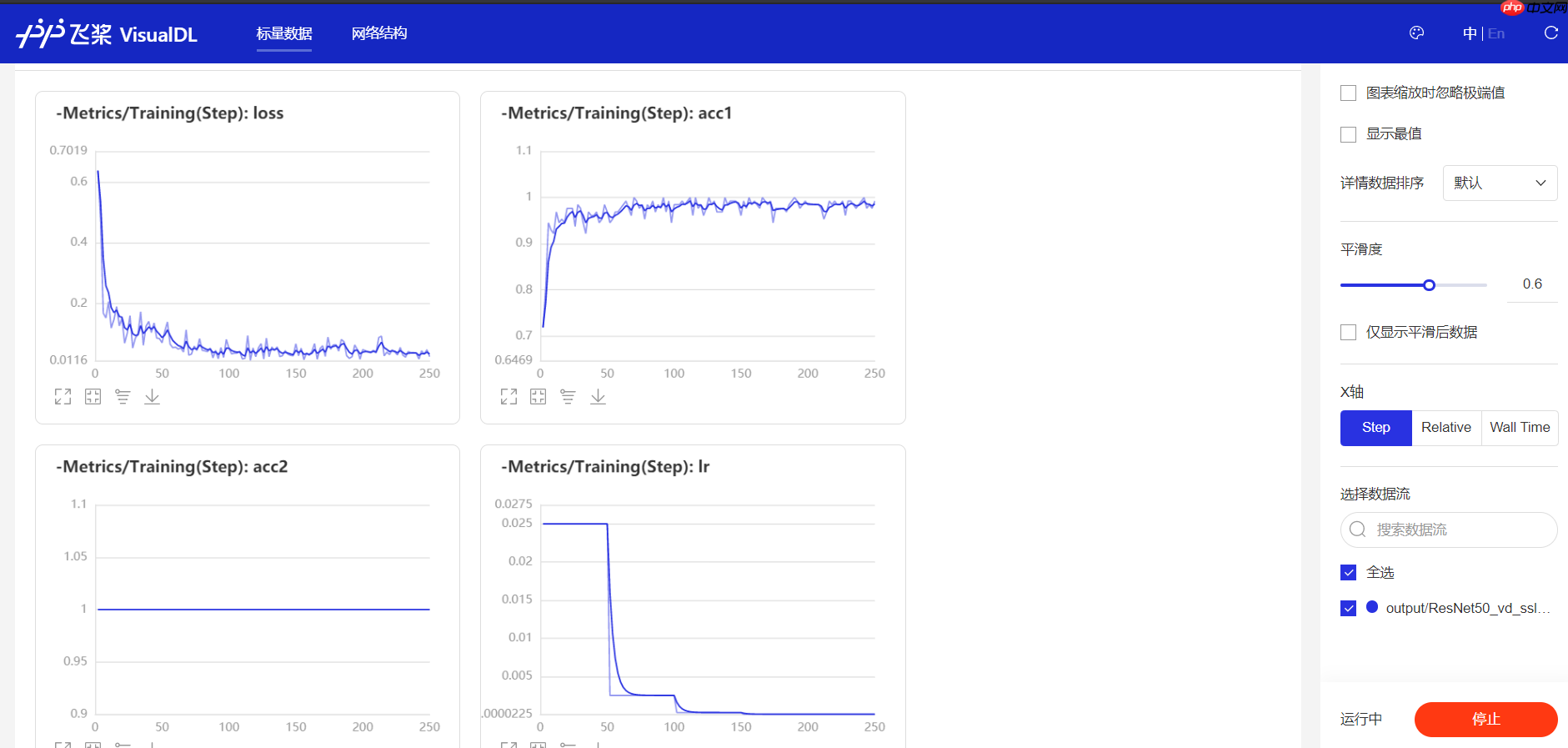
4.6开始预测
# 预测数据集val_listval_list=[]for i in range(1,401,1):
filename='T'+ str(i).zfill(4)+'.jpg'
print(filename)
val_list.append(filename+'\n')with open('val_list.txt','w') as f:
f.writelines(val_list)
val_list=[]with open('val_list.txt', 'r') as f: for line in f:
line='dataset/PALM-Testing400-Images/'+line
val_list.append(line.split('\n')[0]) # print(line.split('\n')[0])# print(val_list)
这里注意使用了小模型+小图片,是可以使用batch_predict直接预测的,否则就一个一个预测
# 批量预测import numpy as np
model = pdx.load_model('output/ResNet50_vd_ssld7/best_model')# model = pdx.load_model('best_model')results = []for file in val_list:
result = model.predict(file,topk=2)
results.append(result)# result = model.batch_predict(val_list)
print("Predict Result:", result)
# 结果列pd_B=[]for item in results: # print(item)
if item[0]['category_id']==1:
pd_B.append(item[0]['score']) else:
pd_B.append(1-item[0]['score'])
# 文件名列pd_A=[]with open('val_list.txt', 'r') as f: for line in f:
pd_A.append(line.split('\n')[0]) # print(line.split('\n')[0])
# 构造pandas的DataFrameimport pandas as pd
df= pd.DataFrame({'FileName': pd_A, 'PM Risk':pd_B})
# 保存为提交文件df.to_csv("Classification_Results062101.csv", index=None)




























