本文介绍基于Paddle2.0搭建的Kd-Unet点云分割网络,融合Kd-Networks特征提取与Unet结构,编码器用Kd-Networks下采样5次,解码器反卷积上采样5次,含跳跃连接。使用ShapeNet的.h5数据集,训练40轮后训练集miou为0.431,还包含数据处理、网络定义、训练及评估等内容。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

训练四十轮后的miou:
| 训练集上 | |
|---|---|
| miou | 0.431 |
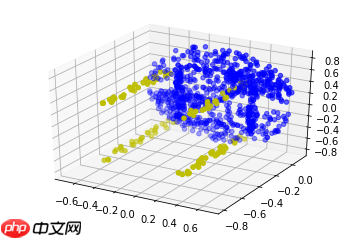
下列图均是分割后的效果图: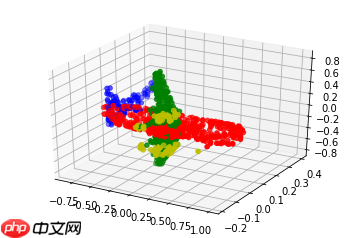
本次用到的数据集是ShapeNet,储存格式是.h5文件。
.h5储存的key值分别为:
1、data:这一份数据中所有点的xyz坐标,
2、label:这一份数据所属类别,如airplane等,
3、pid:这一份数据中所有点所属的类型,如这一份数据属airplane类,则它包含的所有点的类型有机翼、机身等类型。
Kd-Unet是本人第一次自己尝试搭建的新的网络结构,其融合了Kd-Networks中特征提取和分割以及Unet的想法,是一个点云分割网络,效果貌似还不错。
Kd-Unet通过模仿Kd-Networks和Unet,在encoder时采取Kd-Networks网络结构下采样5次,对称地,其decoder采取反卷积相应上采样5次,并在同一个stage模仿Unet使用了skip-connection。
Kd-Unet网络结构: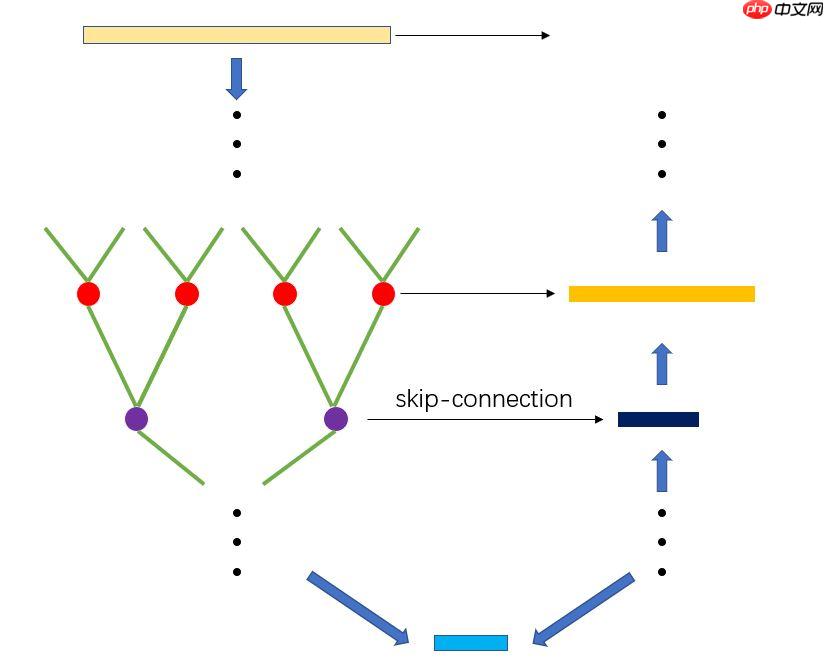
!unzip data/data67117/shapenet_part_seg_hdf5_data.zip!mv hdf5_data dataset
import osimport numpy as npimport randomimport h5pyimport paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom visualdl import LogWriterfrom tools.build_KDTree import build_KDTree
train_list = ['ply_data_train0.h5', 'ply_data_train1.h5', 'ply_data_train2.h5', 'ply_data_train3.h5', 'ply_data_train4.h5', 'ply_data_train5.h5'] test_list = ['ply_data_test0.h5', 'ply_data_test1.h5'] val_list = ['ply_data_val0.h5']
注:在数据读取这里,可以借助scipy.spatial中的cKDTree很快地生成kdTree。
def pointDataLoader(mode='train'):
path = './dataset/'
BATCHSIZE = 1
MAX_POINT = 1024
LEVELS = (np.log(MAX_POINT) / np.log(2)).astype(int)
datas = []
split_dims_v = []
points_v = []
labels = []
labels_v = [] if mode == 'train': for file_list in train_list:
f = h5py.File(os.path.join(path, file_list), 'r')
datas.extend(f['data'][:, :MAX_POINT, :])
labels.extend(f['pid'][:, :MAX_POINT])
f.close() elif mode == 'test': for file_list in test_list:
f = h5py.File(os.path.join(path, file_list), 'r')
datas.extend(f['data'][:, :MAX_POINT, :])
labels.extend(f['pid'][:, :MAX_POINT])
f.close() else: for file_list in val_list:
f = h5py.File(os.path.join(path, file_list), 'r')
datas.extend(f['data'][:, :MAX_POINT, :])
labels.extend(f['pid'][:, :MAX_POINT])
f.close()
datas = np.array(datas) for i in range(len(datas)):
split_dim, point_tree, label_tree = build_KDTree(datas[i], labels[i], LEVELS)
split_dim_v = [np.array(item).astype(np.int64) for item in split_dim]
split_dims_v.append(split_dim_v)
points_v.append(point_tree[-1].transpose(0, 2, 1))
labels_v.append(label_tree[-1].transpose(1, 0))
split_dims_v = np.array(split_dims_v)
points_v = np.array(points_v)
labels = np.array(labels_v) print('==========load over==========')
index_list = list(range(len(datas))) def pointDataGenerator():
if mode == 'train':
random.shuffle(index_list) for i in index_list:
label = np.reshape(labels[i], [-1, 1024, 1]).astype('int64')
split_dim_v = split_dims_v[i]
point_v = points_v[i].astype('float32') yield split_dim_v, point_v, label return pointDataGeneratorclass ConvBNReLU(nn.Layer):
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride,
padding='same',
**kwargs):
super().__init__()
self._conv = nn.Conv1D(
in_channels, out_channels, kernel_size, stride, padding=padding, **kwargs)
self._batch_norm = nn.BatchNorm(out_channels) def forward(self, x):
x = self._conv(x)
x = self._batch_norm(x)
x = F.relu(x) return xclass Downsample(nn.Layer):
def __init__(self):
super(Downsample, self).__init__()
self.convbnrelu1 = ConvBNReLU(3, 32 * 3, 1, 1)
self.convbnrelu2 = ConvBNReLU(32, 64 * 3, 1, 1)
self.convbnrelu3 = ConvBNReLU(64, 256 * 3, 1, 1)
self.convbnrelu4 = ConvBNReLU(256, 512 * 3, 1, 1)
self.convbnrelu5 = ConvBNReLU(512, 1024 * 3, 1, 1) def forward(self, x, split_dims_v):
def kdconv(x, shortcut, dim, featdim, select, convbnrelu):
shortcut.append(x)
x = convbnrelu(x)
x = paddle.reshape(x, (-1, featdim, 3, dim))
x = paddle.reshape(x, (-1, featdim, 3 * dim))
select = paddle.to_tensor(select) + (paddle.arange(0, dim) * 3)
x = paddle.index_select(x, axis=2, index=select)
x = paddle.reshape(x, (-1, featdim, int(dim / 2), 2))
x = paddle.max(x, axis=-1) return x, shortcut
shortcut = []
x, shortcut = kdconv(x, shortcut, 1024, 32, split_dims_v[0], self.convbnrelu1)
x, shortcut = kdconv(x, shortcut, 512, 64, split_dims_v[1], self.convbnrelu2)
x, shortcut = kdconv(x, shortcut, 256, 256, split_dims_v[2], self.convbnrelu3)
x, shortcut = kdconv(x, shortcut, 128, 512, split_dims_v[3], self.convbnrelu4)
x, shortcut = kdconv(x, shortcut, 64, 1024, split_dims_v[4], self.convbnrelu5) return x, shortcutclass Upsample(nn.Layer):
def __init__(self, k=50):
super(Upsample, self).__init__()
self.deconv1 = nn.Conv1DTranspose(1024, 512, 2, 2)
self.doubleconv1 = nn.Sequential(
ConvBNReLU(1024, 512, 1, 1),
ConvBNReLU(512, 512, 1, 1))
self.deconv2 = nn.Conv1DTranspose(512, 512, 2, 2)
self.doubleconv2 = nn.Sequential(
ConvBNReLU(768, 512, 1, 1),
ConvBNReLU(512, 512, 1, 1))
self.deconv3 = nn.Conv1DTranspose(512, 256, 2, 2)
self.doubleconv3 = nn.Sequential(
ConvBNReLU(320, 256, 1, 1),
ConvBNReLU(256, 256, 1, 1))
self.deconv4 = nn.Conv1DTranspose(256, 256, 2, 2)
self.doubleconv4 = nn.Sequential(
ConvBNReLU(288, 128, 1, 1),
ConvBNReLU(128, 128, 1, 1))
self.deconv5 = nn.Conv1DTranspose(128, 128, 2, 2)
self.doubleconv5 = nn.Sequential(
ConvBNReLU(131, 128, 1, 1),
nn.Conv1D(128, k, 1, 1))
def forward(self, x, shortcut):
x = self.deconv1(x)
x = paddle.concat([x, shortcut[-1]], axis=1)
x = self.doubleconv1(x)
x = self.deconv2(x)
x = paddle.concat([x, shortcut[-2]], axis=1)
x = self.doubleconv2(x)
x = self.deconv3(x)
x = paddle.concat([x, shortcut[-3]], axis=1)
x = self.doubleconv3(x)
x = self.deconv4(x)
x = paddle.concat([x, shortcut[-4]], axis=1)
x = self.doubleconv4(x)
x = self.deconv5(x)
x = paddle.concat([x, shortcut[-5]], axis=1)
x = self.doubleconv5(x)
x = x.transpose((0, 2, 1))
x = F.softmax(x, axis=-1) return xclass KDNet(nn.Layer):
def __init__(self, k=16):
super(KDNet, self).__init__()
self.downsample = Downsample()
self.upsample = Upsample(k=50) def forward(self, x, split_dims_v):
x, shortcut = self.downsample(x, split_dims_v)
x = self.upsample(x, shortcut) return x 注:由于训练数据预处理比较慢,所以先创建训练数据读取器(创建同时会对数据进行预处理),这样在训练时候直接导入就显得训练过程快很多(实际上并没有节省时间,只不过是为了调试方便和读者尝试,把训练数据读取器单独拿出来创建)。
train_loader = pointDataLoader(mode='train')
==========load over==========
def train():
model = KDNet()
model.train()
optim = paddle.optimizer.Adam(parameters=model.parameters(), weight_decay=0.001)
epoch_num = 100
all_iou = 0
for epoch in range(epoch_num): for batch_id, data in enumerate(train_loader()):
split_dims_v = data[0]
points_v = data[1]
labels = data[2]
inputs = paddle.to_tensor(points_v)
labels = paddle.to_tensor(labels)
predict = model(inputs, split_dims_v)
loss = F.cross_entropy(predict, labels)
iou, _, _ = paddle.fluid.layers.mean_iou(paddle.unsqueeze(paddle.argmax(predict, axis=-1), axis=-1), labels, 50)
all_iou += iou if batch_id % 100 == 0:
miou = all_iou / 100
all_iou = 0
print("epoch: {}, batch_id: {}, loss is: {}, miou is: {}".format(epoch, batch_id, loss.numpy(), miou.numpy()))
loss.backward()
optim.step()
optim.clear_grad() if epoch % 4 == 0:
paddle.save(model.state_dict(), './model/KDNet.pdparams')
paddle.save(optim.state_dict(), './model/KDNet.pdopt')if __name__ == '__main__':
train()test_loader = pointDataLoader(mode='val')
==========load over==========
def test():
model = KDNet()
model_state_dict = paddle.load('./model/KDNet.pdparams')
model.load_dict(model_state_dict) for batch_id, data in enumerate(test_loader()):
split_dims_v = data[0]
points_v = data[1]
labels = data[2]
inputs = paddle.to_tensor(points_v)
predict = model(inputs, split_dims_v)
labels = paddle.to_tensor(labels) break;
zdata = []
xdata = []
ydata = []
pre_label = [] for i in points_v[0].T:
xdata.append(i[0])
ydata.append(i[1])
zdata.append(i[2]) for i in labels[0].numpy():
pre_label.append(i[0]) print(np.argmax(np.array(pre_label)))
map_color = {0:'r', 1:'g', 2:'b', 3:'y'}
Color = list(map(lambda x: map_color[x], pre_label))
xdata = np.array(xdata)
ydata = np.array(ydata)
zdata = np.array(zdata) from mpl_toolkits import mplot3d import matplotlib.pyplot as plt
ax = plt.axes(projection='3d')
ax.scatter3D(xdata, ydata, zdata, c=Color)
plt.show()if __name__ == '__main__':
test()208
<Figure size 432x288 with 1 Axes>
def test():
model = KDNet()
model_state_dict = paddle.load('./model/KDNet.pdparams')
model.load_dict(model_state_dict) for batch_id, data in enumerate(test_loader()):
split_dims_v = data[0]
points_v = data[1]
labels = data[2]
inputs = paddle.to_tensor(points_v)
predict = model(inputs, split_dims_v)
labels = paddle.to_tensor(labels) break;
zdata = []
xdata = []
ydata = []
pre_label = [] for i in points_v[0].T:
xdata.append(i[0])
ydata.append(i[1])
zdata.append(i[2]) for i in np.argmax(predict[0].numpy(), 1):
pre_label.append(i) print(np.argmax(np.array(pre_label)))
map_color = {0:'r', 1:'g', 2:'b', 3:'y'}
Color = list(map(lambda x: map_color[x], pre_label))
xdata = np.array(xdata)
ydata = np.array(ydata)
zdata = np.array(zdata) from mpl_toolkits import mplot3d import matplotlib.pyplot as plt
ax = plt.axes(projection='3d')
ax.scatter3D(xdata, ydata, zdata, c=Color)
plt.show()if __name__ == '__main__':
test()208
<Figure size 432x288 with 1 Axes>
以上就是点云处理:基于Paddle2.0尝试提出Kd-Unet对点云进行分割处理的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 489
489

























