本文介绍基于LGBM模型预测借款人还款情况的项目。用40000条训练集和15000条测试集数据,经数据加载、预处理和特征工程,构建如贷款金额与缴存额组合等特征。选择LGBM算法,通过多轮参数调优,采用分层K折交叉验证训练,最终模型AUC均值较高,可辅助银行判断借款人信用。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

利用轻量级LGBM模型学习纯数据,从中归纳出优秀的特征,能够判断一个人是否会按期还款。
1、代替人为判断是否能贷款给某人 2、减少传统人为贷款,暗箱操作 3、帮助银行找出信用更优质的人群
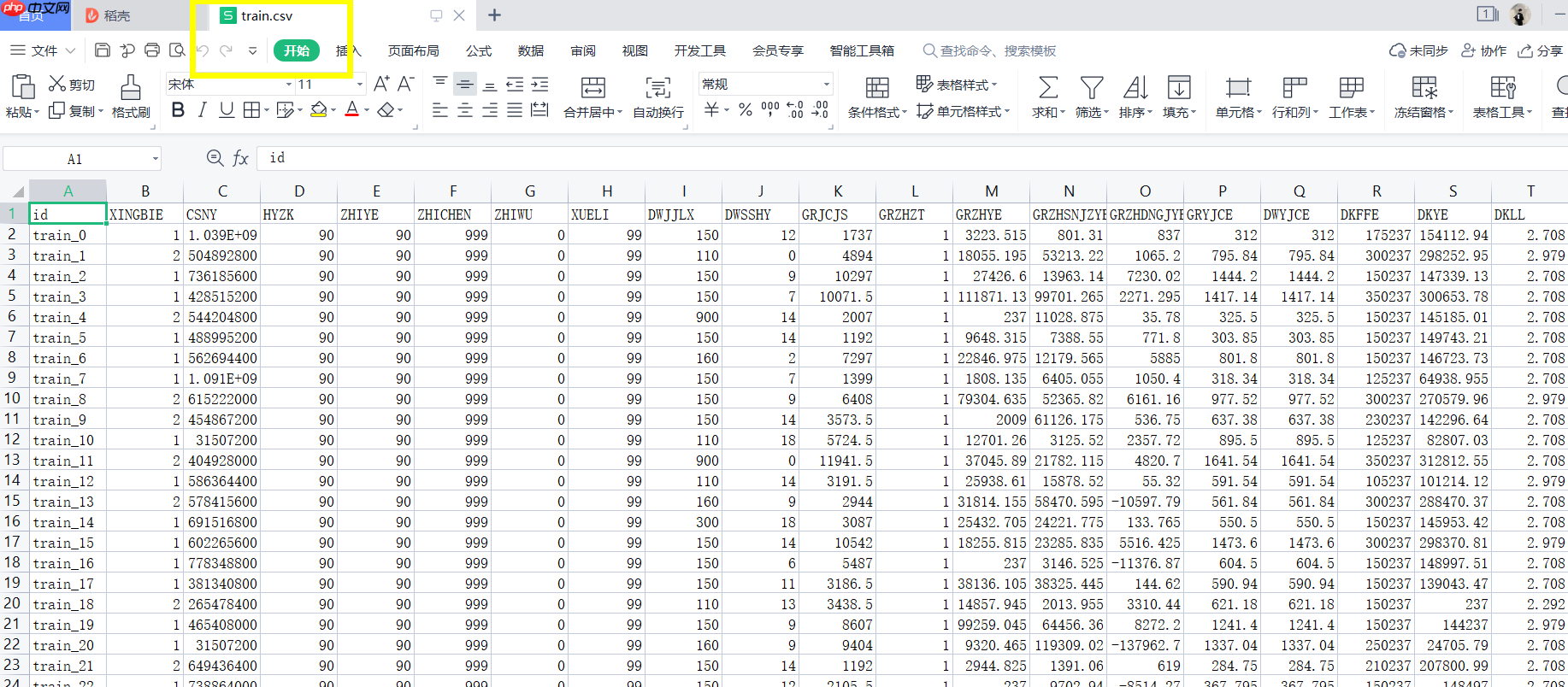
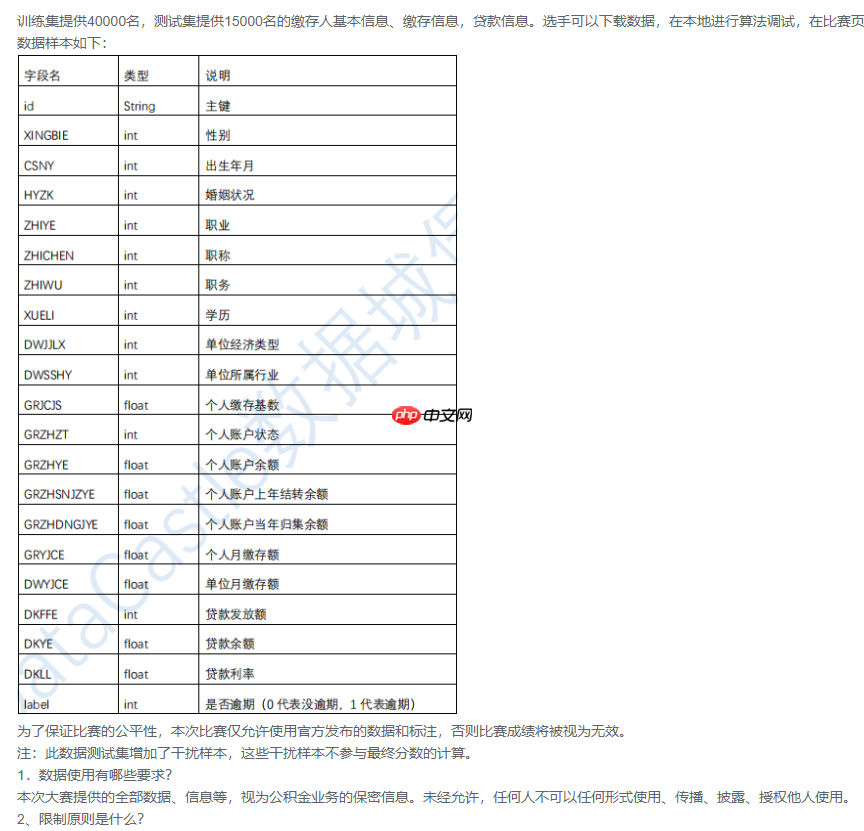
已收集的数据集数量: 训练集提供40000名,测试集提供15000名的缴存人基本信息、缴存信息,贷款信息 。
train_df = df[df['label'].isna() == False].reset_index(drop=True) test_df = df[df['label'].isna() == True].reset_index(drop=True) display(train_df.shape, test_df.shape)
训练集样本量: (40000, 1093),验证集样本量: (15000, 1093)
def get_daikuanYE(df,col):
df[col + '_genFeat1'] = (df[col] > 100000).astype(int)
df[col + '_genFeat2'] = (df[col] > 120000).astype(int)
df[col + '_genFeat3'] = (df[col] > 140000).astype(int)
df[col + '_genFeat4'] = (df[col] > 180000).astype(int)
df[col + '_genFeat5'] = (df[col] > 220000).astype(int)
df[col + '_genFeat6'] = (df[col] > 260000).astype(int)
df[col + '_genFeat7'] = (df[col] > 300000).astype(int) return df, [col + f'_genFeat{i}' for i in range(1, 8)]
df, genFeats2 = get_daikuanYE(df, col = 'DKYE')
df, genFeats3 = get_daikuanYE(df, col = 'DKFFE')
plt.figure(figsize = (8, 2))
plt.subplot(1,2,1)
sns.distplot(df['DKYE'][df['label'] == 1])
plt.subplot(1,2,2)
sns.distplot(df['DKFFE'][df['label'] == 1])
详细说明你使用的算法。此处可细分,如下所示:
# df['GRYJCE_sum_DWYJCE']= (df['GRYJCE']+df['DWYJCE'])*12*(df['DKLL']+1) #贷款每年的还款额# df['GRZHDNGJYE_GRZHSNJZYE']=(df['GRZHDNGJYE']+df['GRZHSNJZYE']+df['GRZHYE'])-df['GRYJCE_sum_DWYJCE']# df['DWJJLX_DWYSSHY']=df['DWJJLX'] *df['DWSSHY'] #单位经济体行业*单位经济体行业# df['XINGBIEDKYE'] = df['XINGBIE'] * df['DKYE']# df['m2'] = (df['DKYE'] - ((df['GRYJCE'] + df['DWYJCE'] ) * 12) + df['GRZHDNGJYE'] ) / 12# df['KDKZGED'] = df['m2'] * (df['GRYJCE'] + df['DWYJCE'] )# gen_feats = ['DKFFE_multi_DKLL','DKFFE_DKYE_DKFFE','DWYSSHY2GRYJCE','DWYSSHY2DWYJCE','ZHIYE_GRZHZT','GRZHDNGJYE_GRZHSNJZYE']df['DWYSSHY2GRYJCE']=df['DWSSHY'] * df['DWSSHY']*df['GRYJCE'] #好gen_feats = ['DWYSSHY2GRYJCE'] df.head()
概括来说,lightGBM主要有以下特点:
oof = np.zeros(train_df.shape[0])# feat_imp_df = pd.DataFrame({'feat': cols, 'imp': 0})test_df['prob'] = 0clf = LGBMClassifier( # 0.05--0.1
learning_rate=0.07, # 1030
# 1300
n_estimators=1030, # 31
# 35
# 37
# 40
# (0.523177, 0.93799) 38
#(0.519115, 0.93587) 39
num_leaves=37,
subsample=0.8, # 0.8
# 0.85
colsample_bytree=0.8,
random_state=11,
is_unbalace=True,
sample_pos_weight=13
# learning_rate=0.066,#学习率
# n_estimators=1032,#拟合的树的棵树,相当于训练轮数
# num_leaves=38,#树的最大叶子数,对比xgboost一般为2^(max_depth)
# subsample=0.85,#子样本频率
# colsample_bytree=0.85, #训练特征采样率列
# random_state=17, #随机种子数
# reg_lambda=1e-1, #L2正则化系数
# # min_split_gain=0.2#最小分割增益
# learning_rate=0.07,#学习率
# n_estimators=1032,#拟合的树的棵树,相当于训练轮数
# num_leaves=37,#树的最大叶子数,对比xgboost一般为2^(max_depth)
# subsample=0.8,#子样本频率
# colsample_bytree=0.8, #训练特征采样率 列
# random_state=17, #随机种子数
# silent=True , #训练过程是否打印日志信息
# min_split_gain=0.05 ,#最小分割增益
# is_unbalace=True,
# sample_pos_weight=13)
--------------------- 0 fold ---------------------
[LightGBM] [Warning] Unknown parameter: is_unbalace
[LightGBM] [Warning] Unknown parameter: sample_pos_weight
Training until validation scores don't improve for 200 rounds
[200] valid_0's auc: 0.944549 valid_0's binary_logloss: 0.110362
Early stopping, best iteration is:
[173] valid_0's auc: 0.944278 valid_0's binary_logloss: 0.1097
--------------------- 1 fold ---------------------
[LightGBM] [Warning] Unknown parameter: is_unbalace
[LightGBM] [Warning] Unknown parameter: sample_pos_weight
Training until validation scores don't improve for 200 rounds
[200] valid_0's auc: 0.943315 valid_0's binary_logloss: 0.113508
Early stopping, best iteration is:
[161] valid_0's auc: 0.943045 valid_0's binary_logloss: 0.113012
使用model.predict接口来完成对大量数据集的批量预测。
val_aucs = []
seeds = [11,22,33]for seed in seeds:
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=seed) for i, (trn_idx, val_idx) in enumerate(skf.split(train_df, train_df['label'])): print('--------------------- {} fold ---------------------'.format(i))
t = time.time()
trn_x, trn_y = train_df[cols].iloc[trn_idx].reset_index(drop=True), train_df['label'].values[trn_idx]
val_x, val_y = train_df[cols].iloc[val_idx].reset_index(drop=True), train_df['label'].values[val_idx]
clf.fit(
trn_x, trn_y,
eval_set=[(val_x, val_y)], # categorical_feature=cate_cols,
eval_metric='auc',
early_stopping_rounds=200,
verbose=200
) # feat_imp_df['imp'] += clf.feature_importances_ / skf.n_splits
oof[val_idx] = clf.predict_proba(val_x)[:, 1]
test_df['prob'] += clf.predict_proba(test_df[cols])[:, 1] / skf.n_splits / len(seeds)
cv_auc = roc_auc_score(train_df['label'], oof)
val_aucs.append(cv_auc) print('\ncv_auc: ', cv_auc)print(val_aucs, np.mean(val_aucs))
心得:特征工程非常重要,大部分提升都是在特征工程的特征组合上,然后就是参数调优。我尝试了所有的参数,调参需要一一做对比实验,千万别同时改两个参数,然后正则化是一般是防止过拟合的,没搞清楚是否过拟合时不要用,不然大概率降低,找到关键的一些参数,能够强迫模型有提升的,比如上述min_split_gain=0.05 ,#最小分割增益,学习率由大往小了调整,多尝试不同的参数组合会有意想不到的效果。
我在AI Studio上获得钻石等级,点亮10个徽章,来互关呀~ Alchemist_W 点我互关
当数据集准备好后,就需要进行愉快的训练了,在这里 Paddle 为大家提供了很多方便的套件,大大缩短开发者的开发时间,提高了开发效率
更多的套件请访问 飞桨产品全景
import pandas as pdimport numpy as npfrom tqdm import tqdmimport osimport matplotlib.pyplot as pltimport seaborn as snsimport paddle
train = pd.read_csv('./work/train.csv')
test = pd.read_csv('./work/test.csv')
submit = pd.read_csv('./work/submit.csv')
train.shape, test.shape, submit.shapetrain.head()
cate_2_cols = ['XINGBIE', 'ZHIWU', 'XUELI'] cate_cols = ['HYZK', 'ZHIYE', 'ZHICHEN', 'DWJJLX', 'DWSSHY', 'GRZHZT'] train[cate_cols]
num_cols = ['GRJCJS', 'GRZHYE', 'GRZHSNJZYE', 'GRZHDNGJYE', 'GRYJCE', 'DWYJCE','DKFFE', 'DKYE', 'DKLL'] train[num_cols]
df = pd.concat([train, test], axis = 0).reset_index(drop = True) #这一块把训练集和测试集连起来 观察数据分布特征 且方便后期做处理 最终还是会分开df.head(10)
概括来说,lightGBM主要有以下特点:
# Find correlations with the target and sort correlations = df.corr()['label'].sort_values()# Display correlationsprint('Most Positive Correlations:\n', correlations.tail(15))print('\nMost Negative Correlations:\n', correlations.head(15))#Most Positive Correlations: 越大说明正相关性越强 可以用来做组合特征# Heatmap 使用热力图来分析两组特征存在的数学上的关系summary=pd.pivot_table(data=df,
index='GRZHZT',
columns='ZHIYE',
values='label',
aggfunc=np.sum)
sns.heatmap(data=summary,
cmap='rainbow',
annot=True, # fmt='.2e', #科学计数法 保留2位小数
linewidth=0.5)
plt.title('Label')
plt.show()def get_age(df,col = 'age'):
df[col+"_genFeat1"]=(df['age'] > 18).astype(int)
df[col+"_genFeat2"]=(df['age'] > 25).astype(int)
df[col+"_genFeat3"]=(df['age'] > 30).astype(int)
df[col+"_genFeat4"]=(df['age'] > 35).astype(int)
df[col+"_genFeat5"]=(df['age'] > 40).astype(int)
df[col+"_genFeat6"]=(df['age'] > 45).astype(int) return df, [col + f'_genFeat{i}' for i in range(1, 7)]
df['age'] = ((1609430399 - df['CSNY']) / (365 * 24 * 3600)).astype(int)
df, genFeats1 = get_age(df, col = 'age')
sns.distplot(df['age'][df['age'] > 0])def get_daikuanYE(df,col):
df[col + '_genFeat1'] = (df[col] > 100000).astype(int)
df[col + '_genFeat2'] = (df[col] > 120000).astype(int)
df[col + '_genFeat3'] = (df[col] > 140000).astype(int)
df[col + '_genFeat4'] = (df[col] > 180000).astype(int)
df[col + '_genFeat5'] = (df[col] > 220000).astype(int)
df[col + '_genFeat6'] = (df[col] > 260000).astype(int)
df[col + '_genFeat7'] = (df[col] > 300000).astype(int) return df, [col + f'_genFeat{i}' for i in range(1, 8)]
df, genFeats2 = get_daikuanYE(df, col = 'DKYE')
df, genFeats3 = get_daikuanYE(df, col = 'DKFFE')
plt.figure(figsize = (8, 2))
plt.subplot(1,2,1)
sns.distplot(df['DKYE'][df['label'] == 1])
plt.subplot(1,2,2)
sns.distplot(df['DKFFE'][df['label'] == 1])train_df = df[df['label'].isna() == False].reset_index(drop=True) test_df = df[df['label'].isna() == True].reset_index(drop=True) display(train_df.shape, test_df.shape) plt.figure(figsize = (8, 2)) plt.subplot(1,2,1) sns.distplot(train_df['age'][train_df['age'] > 0]) plt.subplot(1,2,2) sns.distplot(test_df['age'][test_df['age'] > 0])
Tips比较训练集与测试集中的各属性分布 发现(zhiwu)职务这个属性训练集与测试集分布不同 是不可用属性 给LGBM会使得分类效果变差
gen_feats_fest = ['age','HYZK','ZHIYE','ZHICHEN','ZHIWU','XUELI','DWJJLX','DWSSHY','GRJCJS','GRZHZT','GRZHYE','GRZHSNJZYE','GRZHDNGJYE','GRYJCE','DWYJCE','DKFFE','DKYE','DKLL']for i in range(len(gen_feats_fest)):
plt.figure(figsize = (8, 2))
plt.subplot(1,2,1)
sns.distplot(train_df[gen_feats_fest[i]])
plt.subplot(1,2,2)
sns.distplot(test_df[gen_feats_fest[i]])依据贷款公式组合特征,根据前面提到的皮尔曼系数组合特征
#df['missing_rate'] = (df.shape[1] - df.count(axis = 1)) / df.shape[1]#差#df['DKFFE_DKYE'] = df['DKFFE'] + df['DKYE'] #一般差#df['DKFFE_DKY_multi_DKLL'] = (df['DKFFE'] + df['DKYE']) * df['DKLL']#一般好#df['DKFFE_multi_DKLL'] = df['DKFFE'] * df['DKLL']#一般好#df['DKYE_multi_DKLL'] = df['DKYE'] * df['DKLL']#一般差#df['GRYJCE_DWYJCE'] = df['GRYJCE'] + df['DWYJCE']#一般#df['GRZHDNGJYE_GRZHSNJZYE'] = df['GRZHDNGJYE'] + df['GRZHSNJZYE']#一般差#df['DKFFE_multi_DKLL_ratio'] = df['DKFFE'] * df['DKLL'] / df['DKFFE_DKY_multi_DKLL']#一般差#df['DKYE_multi_DKLL_ratio'] = df['DKYE'] * df['DKLL'] / df['DKFFE_DKY_multi_DKLL']#一般差#df['DKYE_DKFFE_ratio'] = df['DKYE'] / (df['DKFFE'] + df['DKYE'])#一般#df['DKFFE_DKYE_ratio'] = df['DKFFE'] /(df['DKFFE'] + df['DKYE'])#一般差#df['GRZHYE_diff_GRZHDNGJYE'] = df['GRZHYE'] - df['GRZHDNGJYE']#一般差#df['GRZHYE_diff_GRZHSNJZYE'] = df['GRZHYE'] - df['GRZHSNJZYE']#一般差#df['GRYJCE_DWYJCE_ratio'] = df['GRYJCE'] / (df['GRYJCE'] + df['DWYJCE'])#差#df['DWYJCE_GRYJCE_ratio'] = df['DWYJCE'] / (df['GRYJCE'] + df['DWYJCE'])#一般差#df['DWYSSHY2DKLL']=df['DWSSHY'] * df['DWSSHY']*df['DKLL']# df['DWYSSHY2GRJCJS2']=df['DWSSHY'] * df['DWSSHY']*df['GRYJCE']*df['GRYJCE']# df['ZHIYE_GRZHZT']= df['GRZHZT']/(df['ZHIYE']+0.00000001)# gen_feats = ['DWYSSHY2GRYJCE','ZHIYE_GRZHZT']# df['DKFFE_multi_DKLL'] = df['DKFFE'] * df['DKLL'] #发放贷款金额*贷款利率# df['DKFFE-DKYE']=df['DKFFE']-df['DKYE'] #贷款发放额-贷款余额=剩余未还款# df['DKFFE_DKYE_DKFFE']=df['DKFFE-DKYE']*df['DKFFE'] #(贷款发放额-贷款余额)*贷款利率# df['DWYSSHY2GRYJCE']=df['DWSSHY'] * df['DWSSHY']*df['GRYJCE'] #所属行业*所属行业*个人月缴存额 ***# df['DWYSSHY2DWYJCE']=df['DWSSHY'] * df['DWSSHY']*df['DWYJCE'] #所属行业*所属行业*单位月缴存额# df['ZHIYE_GRZHZT']=df['GRZHZT']/df['ZHIYE']# df['DWYSSHY3GRYJCE']=(df['DWSSHY']*df['DWSSHY']*df['DWSSHY']*df['GRYJCE'])*(df['GRZHZT']/df['ZHIYE'])# df['GRYJCE_sum_DWYJCE']= (df['GRYJCE']+df['DWYJCE'])*12*(df['DKLL']+1) #贷款每年的还款额# df['GRZHDNGJYE_GRZHSNJZYE']=(df['GRZHDNGJYE']+df['GRZHSNJZYE']+df['GRZHYE'])-df['GRYJCE_sum_DWYJCE']# df['DWJJLX_DWYSSHY']=df['DWJJLX'] *df['DWSSHY'] #单位经济体行业*单位经济体行业# df['XINGBIEDKYE'] = df['XINGBIE'] * df['DKYE']# df['m2'] = (df['DKYE'] - ((df['GRYJCE'] + df['DWYJCE'] ) * 12) + df['GRZHDNGJYE'] ) / 12# df['KDKZGED'] = df['m2'] * (df['GRYJCE'] + df['DWYJCE'] )# gen_feats = ['DKFFE_multi_DKLL','DKFFE_DKYE_DKFFE','DWYSSHY2GRYJCE','DWYSSHY2DWYJCE','ZHIYE_GRZHZT','GRZHDNGJYE_GRZHSNJZYE']df['DWYSSHY2GRYJCE']=df['DWSSHY'] * df['DWSSHY']*df['GRYJCE'] #好gen_feats = ['DWYSSHY2GRYJCE'] df.head()
for f in tqdm(cate_cols):
df[f] = df[f].map(dict(zip(df[f].unique(), range(df[f].nunique()))))
df[f + '_count'] = df[f].map(df[f].value_counts())
df = pd.concat([df,pd.get_dummies(df[f],prefix=f"{f}")],axis=1)
cate_cols_combine = [[cate_cols[i], cate_cols[j]] for i in range(len(cate_cols)) \ for j in range(i + 1, len(cate_cols))]for f1, f2 in tqdm(cate_cols_combine):
df['{}_{}_count'.format(f1, f2)] = df.groupby([f1, f2])['id'].transform('count')
df['{}_in_{}_prop'.format(f1, f2)] = df['{}_{}_count'.format(f1, f2)] / df[f2 + '_count']
df['{}_in_{}_prop'.format(f2, f1)] = df['{}_{}_count'.format(f1, f2)] / df[f1 + '_count']
for f1 in tqdm(cate_cols):
g = df.groupby(f1) for f2 in num_cols + gen_feats: for stat in ['sum', 'mean', 'std', 'max', 'min', 'std']:
df['{}_{}_{}'.format(f1, f2, stat)] = g[f2].transform(stat) for f3 in genFeats2 + genFeats3: for stat in ['sum', 'mean']:
df['{}_{}_{}'.format(f1, f2, stat)] = g[f2].transform(stat)
num_cols_gen_feats = num_cols + gen_featsfor f1 in tqdm(num_cols_gen_feats):
g = df.groupby(f1) for f2 in num_cols_gen_feats: if f1 != f2: for stat in ['sum', 'mean', 'std', 'max', 'min', 'std']:
df['{}_{}_{}'.format(f1, f2, stat)] = g[f2].transform(stat)for i in tqdm(range(len(num_cols_gen_feats))): for j in range(i + 1, len(num_cols_gen_feats)):
df[f'numsOf_{num_cols_gen_feats[i]}_{num_cols_gen_feats[j]}_add'] = df[num_cols_gen_feats[i]] + df[num_cols_gen_feats[j]]
df[f'numsOf_{num_cols_gen_feats[i]}_{num_cols_gen_feats[j]}_diff'] = df[num_cols_gen_feats[i]] - df[num_cols_gen_feats[j]]
df[f'numsOf_{num_cols_gen_feats[i]}_{num_cols_gen_feats[j]}_multi'] = df[num_cols_gen_feats[i]] * df[num_cols_gen_feats[j]]
df[f'numsOf_{num_cols_gen_feats[i]}_{num_cols_gen_feats[j]}_div'] = df[num_cols_gen_feats[i]] / (df[num_cols_gen_feats[j]] + 0.0000000001)train_df = df[df['label'].isna() == False].reset_index(drop=True) test_df = df[df['label'].isna() == True].reset_index(drop=True) display(train_df.shape, test_df.shape)
(40000, 1093)
(15000, 1093)
drop_feats = [f for f in train_df.columns if train_df[f].nunique() == 1 or train_df[f].nunique() == 0]len(drop_feats), drop_feats
(4, ['DWSSHY_DKYE_min', 'GRYJCE_DWYJCE_std', 'DWYJCE_GRYJCE_std', 'numsOf_GRYJCE_DWYJCE_diff'])
cols = [col for col in train_df.columns if col not in ['id', 'label'] + drop_feats]
from sklearn.model_selection import StratifiedKFoldfrom lightgbm.sklearn import LGBMClassifierfrom sklearn.metrics import f1_score, roc_auc_scorefrom sklearn.ensemble import RandomForestClassifier,VotingClassifierfrom xgboost import XGBClassifierimport timeimport lightgbm as lgb
<IPython.core.display.HTML object>
# callback=paddle.callbacks.VisualDL(log_dir='visualdl_log_dir')# 本地oof = np.zeros(train_df.shape[0])# feat_imp_df = pd.DataFrame({'feat': cols, 'imp': 0})test_df['prob'] = 0clf = LGBMClassifier( # 0.05--0.1
learning_rate=0.07, # 1030
# 1300
n_estimators=1030, # 31
# 35
# 37
# 40
# (0.523177, 0.93799) 38
#(0.519115, 0.93587) 39
num_leaves=37,
subsample=0.8, # 0.8
# 0.85
colsample_bytree=0.8,
random_state=11,
is_unbalace=True,
sample_pos_weight=13
# learning_rate=0.066,#学习率
# n_estimators=1032,#拟合的树的棵树,相当于训练轮数
# num_leaves=38,#树的最大叶子数,对比xgboost一般为2^(max_depth)
# subsample=0.85,#子样本频率
# colsample_bytree=0.85, #训练特征采样率列
# random_state=17, #随机种子数
# reg_lambda=1e-1, #L2正则化系数
# # min_split_gain=0.2#最小分割增益
# learning_rate=0.07,#学习率
# n_estimators=1032,#拟合的树的棵树,相当于训练轮数
# num_leaves=37,#树的最大叶子数,对比xgboost一般为2^(max_depth)
# subsample=0.8,#子样本频率
# colsample_bytree=0.8, #训练特征采样率 列
# random_state=17, #随机种子数
# silent=True , #训练过程是否打印日志信息
# min_split_gain=0.05 ,#最小分割增益
# is_unbalace=True,
# sample_pos_weight=13)
val_aucs = []
seeds = [11,22,33]for seed in seeds:
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=seed) for i, (trn_idx, val_idx) in enumerate(skf.split(train_df, train_df['label'])): print('--------------------- {} fold ---------------------'.format(i))
t = time.time()
trn_x, trn_y = train_df[cols].iloc[trn_idx].reset_index(drop=True), train_df['label'].values[trn_idx]
val_x, val_y = train_df[cols].iloc[val_idx].reset_index(drop=True), train_df['label'].values[val_idx]
clf.fit(
trn_x, trn_y,
eval_set=[(val_x, val_y)], # categorical_feature=cate_cols,
eval_metric='auc',
early_stopping_rounds=200,
verbose=200
) # feat_imp_df['imp'] += clf.feature_importances_ / skf.n_splits
oof[val_idx] = clf.predict_proba(val_x)[:, 1]
test_df['prob'] += clf.predict_proba(test_df[cols])[:, 1] / skf.n_splits / len(seeds)
cv_auc = roc_auc_score(train_df['label'], oof)
val_aucs.append(cv_auc) print('\ncv_auc: ', cv_auc)print(val_aucs, np.mean(val_aucs))--------------------- 0 fold --------------------- [LightGBM] [Warning] Unknown parameter: is_unbalace [LightGBM] [Warning] Unknown parameter: sample_pos_weight Training until validation scores don't improve for 200 rounds [200] valid_0's auc: 0.944549 valid_0's binary_logloss: 0.110362 Early stopping, best iteration is: [173] valid_0's auc: 0.944278 valid_0's binary_logloss: 0.1097 --------------------- 1 fold --------------------- [LightGBM] [Warning] Unknown parameter: is_unbalace [LightGBM] [Warning] Unknown parameter: sample_pos_weight Training until validation scores don't improve for 200 rounds [200] valid_0's auc: 0.943315 valid_0's binary_logloss: 0.113508 Early stopping, best iteration is: [161] valid_0's auc: 0.943045 valid_0's binary_logloss: 0.113012 --------------------- 2 fold --------------------- [LightGBM] [Warning] Unknown parameter: is_unbalace [LightGBM] [Warning] Unknown parameter: sample_pos_weight Training until validation scores don't improve for 200 rounds [200] valid_0's auc: 0.942585 valid_0's binary_logloss: 0.119059 Early stopping, best iteration is: [148] valid_0's auc: 0.942207 valid_0's binary_logloss: 0.117848 --------------------- 3 fold --------------------- [LightGBM] [Warning] Unknown parameter: is_unbalace [LightGBM] [Warning] Unknown parameter: sample_pos_weight Training until validation scores don't improve for 200 rounds [200] valid_0's auc: 0.942192 valid_0's binary_logloss: 0.115931 Early stopping, best iteration is: [123] valid_0's auc: 0.942244 valid_0's binary_logloss: 0.114857 --------------------- 4 fold --------------------- [LightGBM] [Warning] Unknown parameter: is_unbalace [LightGBM] [Warning] Unknown parameter: sample_pos_weight Training until validation scores don't improve for 200 rounds [200] valid_0's auc: 0.939505 valid_0's binary_logloss: 0.113455 Early stopping, best iteration is: [164] valid_0's auc: 0.939654 valid_0's binary_logloss: 0.112933 cv_auc: 0.9420797160267054 --------------------- 0 fold --------------------- [LightGBM] [Warning] Unknown parameter: is_unbalace [LightGBM] [Warning] Unknown parameter: sample_pos_weight Training until validation scores don't improve for 200 rounds [200] valid_0's auc: 0.937373 valid_0's binary_logloss: 0.119639 Early stopping, best iteration is: [140] valid_0's auc: 0.938125 valid_0's binary_logloss: 0.117851 --------------------- 1 fold --------------------- [LightGBM] [Warning] Unknown parameter: is_unbalace [LightGBM] [Warning] Unknown parameter: sample_pos_weight Training until validation scores don't improve for 200 rounds [200] valid_0's auc: 0.942087 valid_0's binary_logloss: 0.113331 Early stopping, best iteration is: [182] valid_0's auc: 0.942311 valid_0's binary_logloss: 0.112912 --------------------- 2 fold --------------------- [LightGBM] [Warning] Unknown parameter: is_unbalace [LightGBM] [Warning] Unknown parameter: sample_pos_weight Training until validation scores don't improve for 200 rounds [200] valid_0's auc: 0.93272 valid_0's binary_logloss: 0.120388 Early stopping, best iteration is: [138] valid_0's auc: 0.933033 valid_0's binary_logloss: 0.118682 --------------------- 3 fold --------------------- [LightGBM] [Warning] Unknown parameter: is_unbalace [LightGBM] [Warning] Unknown parameter: sample_pos_weight Training until validation scores don't improve for 200 rounds [200] valid_0's auc: 0.951504 valid_0's binary_logloss: 0.10742 Early stopping, best iteration is: [178] valid_0's auc: 0.951198 valid_0's binary_logloss: 0.107208 --------------------- 4 fold --------------------- [LightGBM] [Warning] Unknown parameter: is_unbalace [LightGBM] [Warning] Unknown parameter: sample_pos_weight Training until validation scores don't improve for 200 rounds

print(val_aucs, np.mean(val_aucs))def tpr_weight_funtion(y_true,y_predict):
d = pd.DataFrame()
d['prob'] = list(y_predict) #训练集
d['y'] = list(y_true) #训练之后的label
d = d.sort_values(['prob'], ascending=[0]) #对第一列排序
y = d.y #训练之后的label
PosAll = pd.Series(y).value_counts()[1] #测试集所有为1结果相加
NegAll = pd.Series(y).value_counts()[0] #测试集所有为0结果相加
pCumsum = d['y'].cumsum() #真实的1的总数
nCumsum = np.arange(len(y)) - pCumsum + 1 #真实的0的总数
pCumsumPer = pCumsum / PosAll #覆盖率
nCumsumPer = nCumsum / NegAll #打扰率
TR1 = pCumsumPer[abs(nCumsumPer-0.001).idxmin()] #TPR:TPR1:FPR = 0.001
TR2 = pCumsumPer[abs(nCumsumPer-0.005).idxmin()] #TPR TPR2:FPR = 0.005
TR3 = pCumsumPer[abs(nCumsumPer-0.01).idxmin()] #TPR TPR3:FPR = 0.01
return 0.4 * TR1 + 0.3 * TR2 + 0.3 * TR3
tpr = round(tpr_weight_funtion(train_df['label'], oof), 6)
tpr, round(np.mean(val_aucs), 5)submit.head()
submit['id'] = test_df['id']
submit['label'] = test_df['prob']
submit.to_csv('./work/Sub62 {}_{}.csv'.format(tpr, round(np.mean(val_aucs), 6)), index = False)
submit.head()训练完感觉精度不是很满意,可以对配置文件进行调参,常见的调参是针对优化器和学习率
打开PaddleDetection/configs/yolov3/yolov3_mobilenet_v1_roadsign.yml文件
LearningRate:
base_lr: 0.0001
schedulers:
- !PiecewiseDecay
gamma: 0.1
milestones: [32, 36] - !LinearWarmup
start_factor: 0.3333333333333333
steps: 100OptimizerBuilder:
optimizer:
momentum: 0.9
type: Momentum
regularizer:
factor: 0.0005
type: L2我们可以根据数据集以及选择的模型来适当调整我们的参数
更多详细可见 配置文件改动和说明
PaddleHub 各种项目
Jetson Nano上部署PaddleDection
使用SSD-MobileNetv1完成一个项目--准备数据集到完成树莓派部署
PaddleClas 源码解析
PaddleSeg 2.0动态图:车道线图像分割任务简介
PaddleGAN 大合集
如果没有你感兴趣的,可以去寻找相应的项目作为参考,注意项目 paddle 版本最好是 2.0.2 及其以上

写出完整的训练代码,并说明使用的套件,使用的优化器,在训练过程调整了那些参数,以及简短的心得
Note :如果您打算新建项目完成本作业,可以在提交的作业附上链接
使用的套件:使用了 PaddlePaddle
使用了什么模型:使用了LGBM模型
调整了那些参数: learning_rate=0.066,#学习率
n_estimators=1032,#拟合的树的棵树,相当于训练轮数 num_leaves=38,#树的最大叶子数,对比xgboost一般为2^(max_depth) subsample=0.85,#子样本频率 colsample_bytree=0.85, #训练特征采样率列 random_state=17, #随机种子数 reg_lambda=1e-1, #L2正则化系数 # min_split_gain=0.2#最小分割增益 learning_rate=0.07,#学习率 n_estimators=1032,#拟合的树的棵树,相当于训练轮数 num_leaves=37,#树的最大叶子数,对比xgboost一般为2^(max_depth) subsample=0.8,#子样本频率 colsample_bytree=0.8, #训练特征采样率 列 random_state=17, #随机种子数 silent=True , #训练过程是否打印日志信息 min_split_gain=0.05 ,#最小分割增益 is_unbalace=True, sample_pos_weight=13
以上就是『飞桨领航团AI达人创造营』基于LGBM的模型预测借款人是否能按期还款的详细内容,更多请关注php中文网其它相关文章!

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 654
654























