本文围绕低资源神经机器翻译的领域适应方法展开研究,使用口语、专利领域的中英平行句对构建并训练中译英模型,经迁移学习后,在口语、专利、医药测试集测试。结果显示迁移训练后专利领域翻译效果提升显著,验证了领域适应方法的有效性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

机器翻译,又称为自动翻译,是利用计算机将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程。它是计算语言学的一个分支,是人工智能的终极目标之一,具有重要的科学研究价值。同时,机器翻译又具有重要的实用价值。随着经济全球化及互联网的飞速发展,机器翻译技术在促进政治、经济、文化交流等方面起到越来越重要的作用。
机器翻译,肩负着架起语言沟通桥梁的重任。百度翻译自2011年上线至今,在追梦路上已经走过十个年头。十年来,翻译质量大幅提升30个百分点,领域翻译准确率90%以上,日均翻译量超千亿字符,服务50多万企事业单位和个人开发者,实现了机器翻译技术和产业的跨越式发展。
如今机器翻译技术已经取得了很大的突破。机器翻译的性能不仅依赖于大规模的双语数据,还取决于训练和测试数据之间的领域匹配程度。具有丰富数据资源领域的机器翻译性能不断提高,但是由于数据资源获取困难等原因,某些特殊领域的翻译效果还不够理想。如何利用富资源领域的数据帮助低资源领域提升翻译质量是一个热点研究问题。
迁移学习是一种机器学习的方法,指的是一个预训练的模型被重新用在另一个任务中。 迁移学习与多任务学习以及概念飘移这些问题相关,它不是一个专门的机器学习领域。 然而,迁移学习在某些深度学习问题中是非常受欢迎的,例如在具有大量训练深度模型所需的资源或者具有大量的用来预训练模型的数据集的情况。仅在第一个任务中的深度模型特征是泛化特征的时候,迁移学习才会起作用。 深度学习中的这种迁移被称作归纳迁移。就是通过使用一个适用于不同但是相关的任务的模型,以一种有利的方式缩小可能模型的搜索范围。
本小组进行面向低资源神经机器翻译的领域适应方法研究,使用提供的口语领域的中英平行句对和专利领域的中英平行句对作为训练样本,需要基于提供的训练样本实现中译英机器翻译模型的构建与训练,并基于口语、专利、医药三个领域测试集分别提供翻译结果。
来源: 机器领域迁移
描述:数据集一共有三类,分别为口语oral、专利patent和医药medical,每个子类中有各自的训练集和测试集。18.69万口语领域中英双语句对(iswlt-2014)、10万专利领域中英双语句对(opus)和10万专利领域中文单语数据(opus)、20万医药领域英文单语数据(WMT-2016);测试集:1000条口语领域双语句对、1000条专利领域双语句对、1000条医药领域双语句对
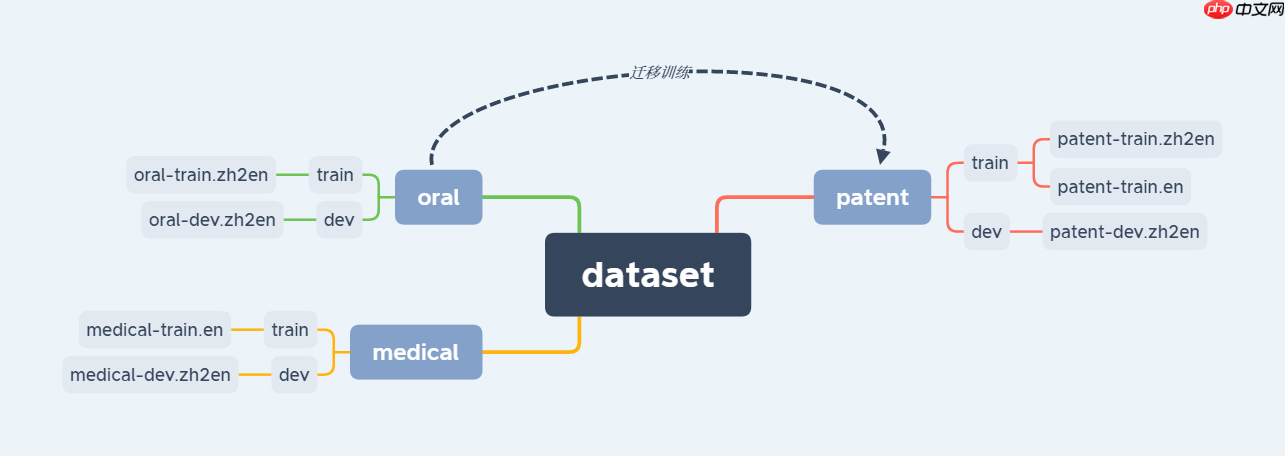
我们需要先训练口语数据集,进而迁移训练专利patent数据集。在迁移训练前后分别测试patent测试集,通过与正确翻译做对比,进而判断迁移训练模型是否达到预期效果。
数据处理:
模型建立与训练:
模型预测:
使用PaddleHub中的simnet_bow文本相似度检测模型,对比正确译句与机器译句,通过二者的相似度来评估翻译效果
结果展示
调用matplotlib中的相关函数,绘制结果对比图,便于直观查看结果。
通过比对迁移训练前后的对patent测试集的测试效果,可以通过下图看到,模型在低资源领域的翻译效果有了显著提高。
在进行任何操作前,我们需要导入一些需要的库文件。并且将我们的数据集文件解压缩。
!unzip -q data/data147459/train_dataset.zip -d dataset
! pip install paddlehub==2.2.0 -i https://mirror.baidu.com/pypi/simple !pip install paddlepaddle==2.2.0 -i https://mirror.baidu.com/pypi/simple
import paddlehub as hubimport paddleimport paddle.nn.functional as Fimport reimport numpy as npimport jieba
from nltk.translate.bleu_score import sentence_bleuprint(paddle.__version__)print(paddle.device.get_device())import matplotlib.pyplot as plt# paddle.device.set_device('gpu:0') simnet_bow = hub.Module(name="simnet_bow")2.1.2 cpu
[2022-07-21 13:29:28,166] [ WARNING]
- The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object
<br/>
在训练模型之前,我们先查看了三种数据集的数据结构,结果发现在各类数据集中存在一定不规范的情况,因此,我们先将对数据进行清洗处理
在处理口语oral训练集时,我们发现,有些数据出现了全英文的情况,此外,还有一些中文数据带有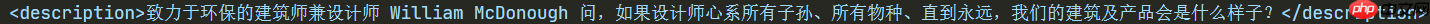
我们将处理好后的数据重新写入到新的文件中,以便于我们在下次使用时,可以直接读取。
def is_contain_chinese(check_str):
# 判断字符串中是否包含中文
for ch in check_str: if u'\u4e00' <= ch <= u'\u9fff': return True
return Falsedef is_all_chinese(string):
# 检查整个字符串是否为全中文
for chart in string: if chart < u'\u4e00' or chart > u'\u9fff': return False
return True# 数据处理oral_train_data = []with open('dataset/oral/train/oral-train.zh2en','r',encoding='utf-8') as oral:
oral_train_data = oral.read().split('\n')# 1. 处理那些全是中文或者全是英文的无用数据print(len(oral_train_data))
del_list = []for i in range(len(oral_train_data)): if is_contain_chinese(oral_train_data[i])==0 or is_all_chinese(oral_train_data[i]):
del_list.append(i)
del_list.reverse() # 对索引进行反转,使其从后往前删除for i in del_list:
temp = oral_train_data.pop(i)print(len(oral_train_data))# 2. 处理带有类似<keywords></keywords>的字样# 首先要将每行拆分为分为中文和英文zh_oral_train_data = []
en_oral_train_data = []for sentence in oral_train_data:
temp = sentence.split('\t')
zh = re.findall(r'>(.+)<',temp[0])
en = re.findall(r'>(.+)<',temp[1]) if len(zh):
zh_oral_train_data.append(zh[0]) else:
zh_oral_train_data.append(temp[0]) if len(en):
en_oral_train_data.append(en[0]) else:
en_oral_train_data.append(temp[1])186971 182676
数据处理完成后,将train训练集文件和dev测试集文件重新写入到新的文件中,以便下次可以直接使用。
with open('dataset/oral/train/oral_train.txt','w',encoding='utf-8') as zh: for i in range(len(zh_oral_train_data)):
zh.write(en_oral_train_data[i]+'\t'+zh_oral_train_data[i])
zh.write('\n')with open('dataset/oral/dev/oral-dev.zh2en','r',encoding='utf-8') as dev:
data = dev.read().split('\n')
data.pop(-1) # print(data)
en_oral_dev_data =[]
zh_oral_dev_data =[] for i in range(len(data)):
temp = data[i].split('\t') # print(temp)
# if(len(temp)!=2):
# print(i)
en_oral_dev_data.append(temp[1])
zh_oral_dev_data.append(temp[0]) # print(en_oral_dev_data)
with open('dataset/oral/dev/oral_dev.txt','w',encoding='utf-8') as txt: for i in range(len(zh_oral_dev_data)):
txt.write(en_oral_dev_data[i]+'\t'+zh_oral_dev_data[i])
txt.write('\n') print("finished")finished
在专利patent数据集中,一些数据前面有着无意义的数字,通过正则表达式将后面的,我们实际需要的数据提取出来。
# 接着处理专利训练集中双语部分# 读取数据def get_patent_data(path):
with open(path, 'r', encoding='utf-8') as patent_zh2en:
temp = patent_zh2en.read()
data = temp.split('\n')
data.pop(-1)
en_data = []
zh_data = [] for sentence in data:
zh_en = sentence.split('\t')
en_data.append(zh_en[1])
zh_data.append(zh_en[0]) return en_data,zh_data# 数据清洗def data_process_2(train_list):
for i in range(len(train_list)):
temp = re.findall('\[[0-9]+](.*)', train_list[i]) if temp == []: continue
train_list[i] = temp[0].strip()# 写入文件def write_to_file(file_path,en_data,zh_data):
with open(file_path, 'w', encoding='utf-8') as data: for i in range(len(en_data)):
data.write(en_data[i] + '\t' + zh_data[i])
data.write('\n')
patent_train_data_path = 'dataset/patent/train/patent-train.zh2en'patent_dev_data_path = 'dataset/patent/dev/patent-dev.zh2en'train_path = "dataset/patent/train/patent_train.txt"dev_path = 'dataset/patent/dev/patent_dev.txt'en_patent_train_data_1,zh_patent_train_data_1 = get_patent_data(patent_train_data_path)
en_patent_dev_data,zh_patent_dev_data = get_patent_data(patent_dev_data_path)
data_process_2(en_patent_train_data_1)
data_process_2(zh_patent_train_data_1)
data_process_2(en_patent_dev_data)
data_process_2(zh_patent_dev_data)
write_to_file(train_path,en_patent_train_data_1,zh_patent_train_data_1)
write_to_file(dev_path,en_patent_dev_data,zh_patent_dev_data)在医药medical数据集中,我们发现几乎所有的数据都是[深静脉血栓形成的门诊治疗:与历史住院患者的比较研究]的样式,句子前后的中括号对于翻译来说并没有任何作用,我们也是通过正则表达式的方式来提取出我们想要的数据。
# 最后是处理医药领域的数据集with open("dataset/medical/dev/medical-dev.zh2en",'r',encoding='utf-8') as medical_dev:
medical_dev_data = medical_dev.read().split('\n')
medical_dev_data.pop(-1)
en_medical_dev_data = []
zh_medical_dev_data = []for sentence in medical_dev_data:
en_medical_dev_data.append(sentence.split('\t')[1])
zh_medical_dev_data.append(sentence.split('\t')[0])# 数据清洗def data_process_3(data):
for i in range(len(data)): if re.findall('\[(.*)]', data[i])!=[]:
data[i] = re.findall('\[(.*)]', data[i])[0].strip() elif re.findall('【(.*)】',data[i])!=[]:
re.findall('【(.*)】', data[i])
data[i] = re.findall('【(.*)】',data[i])[0].strip() else: continuedata_process_3(en_medical_dev_data)
data_process_3(zh_medical_dev_data)with open("dataset/medical/dev/medical_dev.txt",'w',encoding='utf-8') as medical_dev: for i in range(len(en_medical_dev_data)):
medical_dev.write(en_medical_dev_data[i]+'\t'+zh_medical_dev_data[i])
medical_dev.write('\n')接下来我们通过处理双语文件,将双语句对读入到python的数据结构中。这里做了如下的处理。
对于英文,会把全部英文都变成小写,并只保留英文的单词。
对于中文,使用jieba库函数进行分词。
为了后续的程序运行的更快,我们通过限制句子长度,和只保留部分英文单词开头的句子的方式来更新数据集。
然后我们分别创建中英文的词表,这两份词表会用来将英文和中文的句子转换为词的ID构成的序列。词表中还加入了如下三个特殊的词:
MAX_LEN = 60
#1.准备数据def read_data(path):
#用于读取数据
data=[]
lines = open(path, encoding='utf-8').read().strip().split('\n') #用open来读取数据
words_re = re.compile(r'\w+') #用于把英文句子分解成单词的正则匹配项
for each in lines:
en_sent, cn_sent= each.split('\t') # 处理中文存在的空格
cn_sent = cn_sent.replace(" ",'')
cn_sent_list = jieba.lcut(cn_sent)
data.append((words_re.findall(en_sent.lower()),cn_sent_list))
data_filtered=[] for each in data: #选取中英文句子长度均小于60的样本
if len(each[0]) < MAX_LEN and len(each[1]) < MAX_LEN:
data_filtered.append(each) return data_filtereddef build_vocab(data):
#用于构建词典
eng_vocab = {} #英文词典
chn_vocab = {} #中文词典
#分别在词典中添加:<pad>代表填充词,<bos>代表开始词,<eos>代表结束词
eng_vocab['<pad>'], eng_vocab['<bos>'], eng_vocab['<eos>'] = 0, 1, 2
chn_vocab['<pad>'], chn_vocab['<bos>'], chn_vocab['<eos>'] = 0, 1, 2
#迭代data,一旦发现新词便加进词典里
eng_idx, chn_idx = 3, 3
for eng, chn in data: for word in eng: if word not in eng_vocab:
eng_vocab[word] = eng_idx
eng_idx += 1
for word in chn: if word not in chn_vocab:
chn_vocab[word] = chn_idx
chn_idx += 1
return eng_vocab, chn_vocab
oral_train_path = 'dataset/oral/train/oral_train.txt'oral_dev_path = 'dataset/oral/dev/oral_dev.txt'patent_train_path_1 = 'dataset/patent/train/patent_train.txt'patent_dev_path = 'dataset/patent/dev/patent_dev.txt'medical_dev_path = 'dataset/medical/dev/medical_dev.txt'oral_train_data = read_data(oral_train_path)
oral_dev_data = read_data(oral_dev_path)
patent_train_data = read_data(patent_train_path_1)
patent_dev_data = read_data(patent_dev_path)
medical_dev_data = read_data(medical_dev_path)
total_data = oral_train_data+oral_dev_data+patent_train_data+patent_dev_data+medical_dev_data
eng_vocab, chn_vocab = build_vocab(total_data) #根据数据构建词典print('finished')Building prefix dict from the default dictionary ... DEBUG:jieba:Building prefix dict from the default dictionary ... Dumping model to file cache /tmp/jieba.cache DEBUG:jieba:Dumping model to file cache /tmp/jieba.cache Loading model cost 0.760 seconds. DEBUG:jieba:Loading model cost 0.760 seconds. Prefix dict has been built successfully. DEBUG:jieba:Prefix dict has been built successfully.
finished
# 数据预处理# 处理训练集def data_process(data,eng_vocab, chn_vocab):
#填充句子
padded_eng_sents = []
padded_chn_sents = []
padded_chn_label_sents = [] for eng, chn in data: #给每个英文句子结尾加上<eos>,并且把不足MAX_LEN单词数量的英文句子填充<pad>
padded_eng_sent = eng + ['<eos>'] + ['<pad>'] * (MAX_LEN - len(eng))
padded_eng_sent.reverse() #给每个中文句子开头加上<bos>、结尾加上<eos>,并且把不足MAX_LEN个词数量的句子填充<pad>
padded_chn_sent = ['<bos>'] + chn + ['<eos>'] + ['<pad>'] * (MAX_LEN - len(chn))
padded_chn_label_sent = chn + ['<eos>'] + ['<pad>'] * (MAX_LEN - len(chn) + 1) #根据字典,把句子中的单词转成字典中相对应的数字
padded_eng_sents.append([eng_vocab[w] for w in padded_eng_sent])
padded_chn_sents.append([chn_vocab[w] for w in padded_chn_sent])
padded_chn_label_sents.append([chn_vocab[w] for w in padded_chn_label_sent])
train_eng_sents = np.array(padded_eng_sents).astype('int64')
train_chn_sents = np.array(padded_chn_sents).astype('int64')
train_chn_label_sents = np.array(padded_chn_label_sents).astype('int64') return train_eng_sents,train_chn_sents,train_chn_label_sentsdef dev_data_process(data):
#填充句子
padded_eng_sents = [] for eng, chn in data: #给每个英文句子结尾加上<eos>,并且把不足MAX_LEN单词数量的英文句子填充<pad>
padded_eng_sent = eng + ['<eos>'] + ['<pad>'] * (MAX_LEN - len(eng))
padded_eng_sent.reverse() #根据字典,把句子中的单词转成字典中相对应的数字
padded_eng_sents.append([eng_vocab[w] for w in padded_eng_sent])
train_eng_sents = np.array(padded_eng_sents).astype('int64') return train_eng_sents
train_eng_sents,train_chn_sents,train_chn_label_sents = data_process(oral_train_data,eng_vocab, chn_vocab)
train_eng_sents_2,train_chn_sents_2,train_chn_label_sents_2 = data_process(patent_train_data,eng_vocab,chn_vocab)
val_oral_dev_data = dev_data_process(oral_dev_data)
val_patent_dev_data = dev_data_process(patent_dev_data)
val_medical_dev_data = dev_data_process(medical_dev_data)创建一个Encoder-AttentionDecoder架构的模型结构用来完成机器翻译任务。 首先我们将设置一些必要的网络结构中用到的参数。
Encoder部分
在编码器的部分,我们通过查找完Embedding之后接一个LSTM的方式构建一个对源语言编码的网络。飞桨的RNN系列的API,除了LSTM之外,还提供了SimleRNN, GRU供使用,同时,还可以使用反向RNN,双向RNN,多层RNN等形式。也可以通过dropout参数设置是否对多层RNN的中间层进行dropout处理,来防止过拟合。
Decoder部分
在解码器部分,我们通过一个带有注意力机制的LSTM来完成解码。
单步的LSTM:在解码器的实现的部分,我们同样使用LSTM,与Encoder部分不同的是,下面的代码,每次只让LSTM往前计算一次。整体的recurrent部分,是在训练循环内完成的。
注意力机制:这里使用了一个由两个Linear组成的网络来完成注意力机制的计算,它用来计算出目标语言在每次翻译一个词的时候,需要对源语言当中的每个词需要赋予多少的权重。
# 构建模型embedding_size = 128hidden_size = 256epochs = 25batch_size = 512eng_vocab_size = len(list(eng_vocab))
chn_vocab_size = len(list(chn_vocab))#编码器class Encoder(paddle.nn.Layer):
def __init__(self):
super(Encoder, self).__init__() #词向量层
self.embed = paddle.nn.Embedding(eng_vocab_size, embedding_size) #长短期记忆网络层
self.lstm = paddle.nn.LSTM(input_size=embedding_size, hidden_size=hidden_size, num_layers=1) def forward(self, x):
#输入数据形状大小为[批量数,时间步长]
x = self.embed(x) #经过词嵌入层,输出形状大小为[批量数,时间步长,词向量维度(embedding_size)].其中,时间步长=MAX_LEN+1
x, (_, _) = self.lstm(x) #经过长短期记忆网络层,输出形状大小为:[批量数,时间步长,隐藏层维度(hidden_size)].其中,时间步长=MAX_LEN+1
return x#解码器class Decoder(paddle.nn.Layer):
def __init__(self):
super(Decoder, self).__init__() #词嵌入层
self.embed = paddle.nn.Embedding(chn_vocab_size, embedding_size) #长短期记忆网络层
self.lstm = paddle.nn.LSTM(input_size=embedding_size + hidden_size, hidden_size=hidden_size) #注意力计算函数
self.attention_linear1 = paddle.nn.Linear(hidden_size * 2, hidden_size)
self.attention_linear2 = paddle.nn.Linear(hidden_size, 1)
self.linear =paddle.nn.Linear(hidden_size, chn_vocab_size) def forward(self, x, previous_hidden, previous_cell, encoder_outputs):
#输入数据x的形状大小为[批量数, 1]
#上个时间步的隐藏层previous_hidden形状大小为[批量数, 1, 隐藏层维度(hidden_size)]
#上个时间步的单元previous_cell形状大小为[批量数, 1, 隐藏层维度(hidden_size)]
#编码器在各时间步隐藏状态encoder_outputs形状大小为[批量数,时间步长,隐藏层维度(hidden_size)]
#输入编码器的是英文句子,每句的长度为MAX_LEN+1,加了一个结束符<eos>
x = self.embed(x) #经过词嵌入层,输出形状大小为[批量数,1,词向量维度(embedding_size)]
#把编码器在各个时间部的隐藏状态与解码器的上一时间步的隐藏状态拼接起来
#编码器在各时间步隐藏状态encoder_outputs形状大小为[批量数,时间步长,隐藏层维度(hidden_size)]
#而解码器在上个时间步的隐藏层previous_hidden的形状大小为[批量数, 1, 隐藏层维度(hidden_size)]
#需要用paddle.tile方法对previous_hidden在时间步维度进行复制扩展
#之后,用paddle.concat方法把encoder_outputs和扩展后的previous_hidden在最后一个维度进行拼接
#输出attention_inputs的形状大小变为[批量数,时间步长,隐藏层维度*2]
attention_inputs = paddle.concat((encoder_outputs, paddle.tile(previous_hidden, repeat_times=[1, MAX_LEN+1, 1])), axis=-1) #采用单隐藏层的多层感知机进行变换
attention_hidden = self.attention_linear1(attention_inputs)
attention_hidden = F.tanh(attention_hidden)
attention_logits = self.attention_linear2(attention_hidden) #此时的输出形状大小为[批量数,时间步长,1]
attention_logits = paddle.squeeze(attention_logits) #删除输入Tensor的Shape中尺寸为1的维度
#此时的输出形状大小为[批量数,时间步长]
#利用softmax运算得到注意力权重,形状大小为[批量数,时间步长],每个取值在0至1之间,它是在时间维取权重。
attention_weights = F.softmax(attention_logits) #编码器在各时间步隐藏状态encoder_outputs形状大小为[批量数,时间步长,隐藏层维度(hidden_size)]
#而注意力权重的形状大小为[批量数,时间步长],因此需要用paddle.unsqueeze方法对注意力权重增加一个维度
#接着,使用paddle.expand_as方法把注意力权重扩展成encoder_outputs的形状
attention_weights = paddle.expand_as(paddle.unsqueeze(attention_weights, -1), encoder_outputs) #逐元素相乘得到背景向量
context_vector = paddle.multiply(encoder_outputs, attention_weights) #此时的背景向量形状大小为[批量数,时间步长,隐藏层维度]
#接着对背景向量在时间步求和
context_vector = paddle.sum(context_vector, 1) #此时的背景向量形状大小为[批量数,隐藏层维度]
context_vector = paddle.unsqueeze(context_vector, 1) #在第1维插入尺寸为1的维度
#此时的背景向量形状大小为[批量数,1,隐藏层维度]
#经过词嵌入层,输出x形状大小为[批量数,1,词向量维度(embedding_size)]
#把x与背景向量在最后一个维度上拼接起来,得到形状大小为[批量数,1,词向量维度+隐藏层维度]
lstm_input = paddle.concat((x, context_vector), axis=-1) #上个时间步的隐藏层previous_hidden形状大小转变为[1,批量数, 隐藏层维度(hidden_size)]
previous_hidden = paddle.transpose(previous_hidden, [1, 0, 2]) #上个时间步的单元previous_cell形状大小转变为[1,批量数, 隐藏层维度(hidden_size)]
previous_cell = paddle.transpose(previous_cell, [1, 0, 2]) #数据输入长短期记忆网络层
x, (hidden, cell) = self.lstm(lstm_input, (previous_hidden, previous_cell))
hidden = paddle.transpose(hidden, [1, 0, 2])
cell = paddle.transpose(cell, [1, 0, 2]) #经过上述转置,当前时间步隐藏层输出形状大小为[批量数,1,隐藏层维度]
output = self.linear(hidden) #此时,输出形状大小为[批量数,1,中文词典大小]
output = paddle.squeeze(output) #删除输入Tensor的Shape中尺寸为1的维度
#此时,输出形状大小为[批量数, 中文词典大小]
return output, (hidden, cell)接下来我们开始训练模型。
在每个epoch开始之前,我们对训练数据进行了随机打乱。
我们通过多次调用atten_decoder,在这里实现了解码时的recurrent循环。
训练时并打印当前的loss值与时间。
# 训练模型import datetime
encoder = Encoder() #生成编码器实例decoder = Decoder() #生成解码器实例#优化器optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=encoder.parameters()+decoder.parameters())#进行训练for epoch in range(epochs): print("第{}轮训练开始...".format(epoch+1)) #打乱数据顺序
order = np.random.permutation(len(train_eng_sents))
train_eng_sents_shuffled = train_eng_sents[order]
train_chn_sents_shuffled = train_chn_sents[order]
train_chn_label_sents_shuffled = train_chn_label_sents[order] for iteration in range(train_eng_sents_shuffled.shape[0] // batch_size):
eng_sentence = train_eng_sents_shuffled[(batch_size*iteration):(batch_size*(iteration+1))] # 转为tensor类型
eng_sentence = paddle.to_tensor(eng_sentence)
encoder_outputs = encoder(eng_sentence)
x_chn_data = train_chn_sents_shuffled[(batch_size*iteration):(batch_size*(iteration+1))]
x_chn_label_data = train_chn_label_sents_shuffled[(batch_size*iteration):(batch_size*(iteration+1))] # shape: (batch, num_layer(=1 here) * num_of_direction(=1 here), hidden_size)
hidden = paddle.zeros([batch_size, 1, hidden_size])
cell = paddle.zeros([batch_size, 1, hidden_size])
loss = paddle.zeros([1]) #循环调用解码器,每次喂入一个时间步的批量数据
for i in range(MAX_LEN + 2):
chn_word = paddle.to_tensor(x_chn_data[:,i:i+1])
chn_word_label = paddle.to_tensor(x_chn_label_data[:,i])
logits, (hidden, cell) = decoder(chn_word, hidden, cell, encoder_outputs)
step_loss = F.cross_entropy(logits, chn_word_label)
loss += step_loss
loss = loss / (MAX_LEN + 2) if(iteration % 200 == 0):
current_time = datetime.datetime.now()
print("current_time: " + str(current_time)) print("iter {}, loss:{}".format(iteration, loss.numpy()))
loss.backward()
optimizer.step()
optimizer.clear_grad()在训练完成后,对oral和patent测试集进行测试,将预测的结果与实际翻译做比对,通过SimNet计算出相似度得分,帮助我们直观查看模型效果。
最后将oral结果写入到result_oral文件中并保存,将patent结果写入到before文件中。
注意:因为在写入文件时方式为"a",是追加的方式,所以不会覆盖掉前面的预测结果。
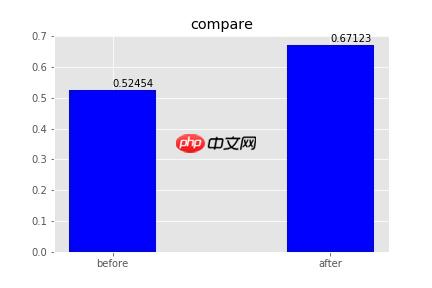
从最终的结果中可以看到:最后的oral平均得分为0.6582814999999989,patent平均得分为0.5245418511066401。
# 模型预测oral数据集encoder.eval()
decoder.eval()
num_of_exampels_to_evaluate = len(val_oral_dev_data)
x_data = val_oral_dev_data# print(oral_dev_data)sent = paddle.to_tensor(x_data)
en_repr = encoder(sent)
word = np.array([[eng_vocab['<bos>']]] * num_of_exampels_to_evaluate)
word = paddle.to_tensor(word)
hidden = paddle.zeros([num_of_exampels_to_evaluate, 1, hidden_size])
cell = paddle.zeros([num_of_exampels_to_evaluate, 1, hidden_size])
decoded_sent = []for i in range(MAX_LEN + 2):
logits, (hidden, cell) = decoder(word, hidden, cell, en_repr)
word = paddle.argmax(logits, axis=1)
decoded_sent.append(word.numpy())
word = paddle.unsqueeze(word, axis=-1)
oral_scores = []
results = np.stack(decoded_sent, axis=1)for i in range(num_of_exampels_to_evaluate):
en_input = " ".join(oral_dev_data[i][0])
ground_truth_translate = "".join(oral_dev_data[i][1])
model_translate = ""
for k in results[i]:
w = list(chn_vocab)[k] if w != '<pad>' and w != '<eos>':
model_translate += w
true_sentence = "true: {}".format(ground_truth_translate)
pred_sentence = "pred: {}".format(model_translate)
inputs = {"text_1":[ground_truth_translate],'text_2':[model_translate]}
result = simnet_bow.similarity(data=inputs, batch_size=1)
oral_score = "score: {}".format(result[0]['similarity'])
oral_scores.append(result[0]['similarity']) # 在写入文件时方式为"a",是追加的方式,所以不会覆盖掉前面的预测结果。
with open('result_oral.txt','a',encoding = 'utf-8') as result_txt:
result_txt.write(en_input+'\n'+true_sentence+'\n'+pred_sentence+'\n'+oral_score+'\n')print(f"oral测试集全部测试完毕,累计{num_of_exampels_to_evaluate}条数据,已经全部写入result_oral.txt文件中")
total_oral_score = sum(oral_scores)print(f"平均得分为: {total_oral_score/len(oral_scores)}")oral测试集全部测试完毕,累计1000条数据,已经全部写入result_oral.txt文件中 平均得分为: 0.6582814999999989
为了体现迁移学习的效果,因此在迁移学习前,对patent测试集进行测试,得到的平均得分与之后迁移训练后的模型测试出来的得分相比对,可以体现出迁移学习的效果。
# 模型预测patent测试集,用于迁移训练模型效果比对encoder.eval()
decoder.eval()
num_of_exampels_to_evaluate = len(val_patent_dev_data)
x_data = val_patent_dev_data
sent = paddle.to_tensor(x_data)
en_repr = encoder(sent)
word = np.array([[chn_vocab['<bos>']]] * num_of_exampels_to_evaluate)
word = paddle.to_tensor(word)
hidden = paddle.zeros([num_of_exampels_to_evaluate, 1, hidden_size])
cell = paddle.zeros([num_of_exampels_to_evaluate, 1, hidden_size])
decoded_sent = []for i in range(MAX_LEN + 2):
logits, (hidden, cell) = decoder(word, hidden, cell, en_repr)
word = paddle.argmax(logits, axis=1)
decoded_sent.append(word.numpy())
word = paddle.unsqueeze(word, axis=-1)
patent_scores_before = []
results = np.stack(decoded_sent, axis=1)for i in range(num_of_exampels_to_evaluate):
en_input = " ".join(patent_dev_data[i][0])
ground_truth_translate = "".join(patent_dev_data[i][1])
model_translate = ""
for k in results[i]:
w = list(chn_vocab)[k] if w != '<pad>' and w != '<eos>':
model_translate += w
true_sentence = "true: {}".format(ground_truth_translate)
pred_sentence = "pred: {}".format(model_translate)
inputs = {"text_1":[ground_truth_translate],'text_2':[model_translate]}
result = simnet_bow.similarity(data=inputs, batch_size=1)
patent_score_before = "score: {}".format(result[0]['similarity'])
patent_scores_before.append(result[0]['similarity']) # 将数据结果写入before文件中,方便后续与迁移训练后的结果做对比
# 在写入文件时方式为"a",是追加的方式,所以不会覆盖掉前面的预测结果。
with open('before.txt','a',encoding = 'utf-8') as result_txt:
result_txt.write(en_input+'\n'+true_sentence+'\n'+pred_sentence+'\n'+patent_score_before+'\n')print(f"patent测试集全部测试完毕,累计{num_of_exampels_to_evaluate}条数据,已经全部写入before.txt文件中")
total_patent_score_before = sum(patent_scores_before)print(f"平均得分为: {total_patent_score_before/len(patent_scores_before)}")patent测试集全部测试完毕,累计994条数据,已经全部写入before.txt文件中 平均得分为: 0.5245418511066401
模型保存与加载
将我们训练好的模型保存到output文件夹中,在下一次使用时,可以不用经过训练便可以进行预测。
通过加载模型,我们可以直接使用上次训练好的模型。
paddle.save(encoder.state_dict(),'./output/encoder.pdparams') paddle.save(decoder.state_dict(),'./output/decoder.pdparams') paddle.save(optimizer.state_dict(),'./output/decoder.pdopt')
load_encoder = Encoder()
load_decoder = Decoder()
dict_load_encoder = paddle.load('./output/encoder.pdparams')
dict_load_decoder = paddle.load('./output/decoder.pdparams')
load_encoder.set_dict(dict_load_encoder)
load_decoder.set_dict(dict_load_decoder)重新加载已保存的模型,对新的patent数据进行训练。
# 迁移训练模型import datetime# 优化器epochs = 10optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=load_encoder.parameters()+load_decoder.parameters())# 进行训练for epoch in range(epochs): print("第{}轮训练开始...".format(epoch+1)) # 打乱数据顺序
order = np.random.permutation(len(train_eng_sents_2))
train_eng_sents_shuffled = train_eng_sents_2[order]
train_chn_sents_shuffled = train_chn_sents_2[order]
train_chn_label_sents_shuffled = train_chn_label_sents_2[order] for iteration in range(train_eng_sents_shuffled.shape[0] // batch_size):
eng_sentence = train_eng_sents_shuffled[(batch_size*iteration):(batch_size*(iteration+1))] # 转为tensor类型
eng_sentence = paddle.to_tensor(eng_sentence)
encoder_outputs = load_encoder(eng_sentence)
x_chn_data = train_chn_sents_shuffled[(batch_size*iteration):(batch_size*(iteration+1))]
x_chn_label_data = train_chn_label_sents_shuffled[(batch_size*iteration):(batch_size*(iteration+1))] # shape: (batch, num_layer(=1 here) * num_of_direction(=1 here), hidden_size)
hidden = paddle.zeros([batch_size, 1, hidden_size])
cell = paddle.zeros([batch_size, 1, hidden_size])
loss = paddle.zeros([1]) # 循环调用解码器,每次喂入一个时间步的批量数据
for i in range(MAX_LEN + 2):
chn_word = paddle.to_tensor(x_chn_data[:,i:i+1])
chn_word_label = paddle.to_tensor(x_chn_label_data[:,i])
logits, (hidden, cell) = load_decoder(chn_word, hidden, cell, encoder_outputs)
step_loss = F.cross_entropy(logits, chn_word_label) # print(step_loss)
loss += step_loss
loss = loss / (MAX_LEN + 2) if(iteration % 200 == 0):
current_time = datetime.datetime.now() print("current_time: " + str(current_time)) print("iter {}, loss:{}".format(iteration, loss.numpy()))
loss.backward()
optimizer.step()
optimizer.clear_grad()对patent测试集和medical测试集数据进行测试,并将结果写入到result_patent和result_medical文件中。
注意:在写入文件时方式为"a",是追加的方式,所以不会覆盖掉前面的预测结果。
最后的patent平均得分为:0.671227364185111,medical平均得分为:0.40783529999999996。
可以通过比对两次patent的得分,第一次是0.5245418511066401,第二次是0.671227364185111,可以看到迁移学习确实使得模型预测的准确率提升。
# 迁移训练后的模型预测patent测试集,用于迁移训练模型效果比对load_encoder.eval()
load_decoder.eval()
num_of_exampels_to_evaluate = len(val_patent_dev_data)
x_data = val_patent_dev_data
sent = paddle.to_tensor(x_data)
en_repr = load_encoder(sent)
word = np.array([[chn_vocab['<bos>']]] * num_of_exampels_to_evaluate)
word = paddle.to_tensor(word)
hidden = paddle.zeros([num_of_exampels_to_evaluate, 1, hidden_size])
cell = paddle.zeros([num_of_exampels_to_evaluate, 1, hidden_size])
decoded_sent = []for i in range(MAX_LEN + 2):
logits, (hidden, cell) = load_decoder(word, hidden, cell, en_repr)
word = paddle.argmax(logits, axis=1)
decoded_sent.append(word.numpy())
word = paddle.unsqueeze(word, axis=-1)
patent_scores_after = []
results = np.stack(decoded_sent, axis=1)for i in range(num_of_exampels_to_evaluate):
en_input = " ".join(patent_dev_data[i][0])
ground_truth_translate = "".join(patent_dev_data[i][1])
model_translate = ""
for k in results[i]:
w = list(chn_vocab)[k] if w != '<pad>' and w != '<eos>':
model_translate += w
true_sentence = "true: {}".format(ground_truth_translate)
pred_sentence = "pred: {}".format(model_translate)
inputs = {"text_1":[ground_truth_translate],'text_2':[model_translate]}
result = simnet_bow.similarity(data=inputs, batch_size=1)
patent_score_after = "score: {}".format(result[0]['similarity'])
patent_scores_after.append(result[0]['similarity']) # 将数据结果写入after文件中,方便后续与迁移训练后的结果做对比
# 在写入文件时方式为"a",是追加的方式,所以不会覆盖掉前面的预测结果。
with open('after.txt','a',encoding = 'utf-8') as result_txt:
result_txt.write(en_input+'\n'+true_sentence+'\n'+pred_sentence+'\n'+patent_score_after+'\n') # 将数据结果写入result文件中,因为这是作为最后的结果查看
# 在写入文件时方式为"a",是追加的方式,所以不会覆盖掉前面的预测结果。
with open('result_patent.txt','a',encoding = 'utf-8') as result_txt:
result_txt.write(en_input+'\n'+true_sentence+'\n'+pred_sentence+'\n'+patent_score_after+'\n')print(f"patent测试集全部测试完毕,累计{num_of_exampels_to_evaluate}条数据,已经全部写入after.txt和result_patent.txt文件中")
total_patent_score_after = sum(patent_scores_after)print(f"平均得分为: {total_patent_score_after/len(patent_scores_after)}")patent测试集全部测试完毕,累计994条数据,已经全部写入after.txt和result_patent.txt文件中 平均得分为: 0.671227364185111
# 模型预测medical测试集load_encoder.eval()
load_decoder.eval()
num_of_exampels_to_evaluate = len(val_medical_dev_data)
x_data = val_medical_dev_data
sent = paddle.to_tensor(x_data)
en_repr = load_encoder(sent)
word = np.array([[chn_vocab['<bos>']]] * num_of_exampels_to_evaluate)
word = paddle.to_tensor(word)
hidden = paddle.zeros([num_of_exampels_to_evaluate, 1, hidden_size])
cell = paddle.zeros([num_of_exampels_to_evaluate, 1, hidden_size])
decoded_sent = []for i in range(MAX_LEN + 2):
logits, (hidden, cell) = load_decoder(word, hidden, cell, en_repr)
word = paddle.argmax(logits, axis=1)
decoded_sent.append(word.numpy())
word = paddle.unsqueeze(word, axis=-1)
medical_scores = []
results = np.stack(decoded_sent, axis=1)for i in range(num_of_exampels_to_evaluate):
en_input = " ".join(medical_dev_data[i][0])
ground_truth_translate = "".join(medical_dev_data[i][1])
model_translate = ""
for k in results[i]:
w = list(chn_vocab)[k] if w != '<pad>' and w != '<eos>':
model_translate += w
true_sentence = "true: {}".format(ground_truth_translate)
pred_sentence = "pred: {}".format(model_translate)
inputs = {"text_1":[ground_truth_translate],'text_2':[model_translate]}
result = simnet_bow.similarity(data=inputs, batch_size=1)
medical_score = "score: {}".format(result[0]['similarity'])
medical_scores.append(result[0]['similarity']) # 在写入文件时方式为"a",是追加的方式,所以不会覆盖掉前面的预测结果。
with open('result_medical.txt','a',encoding = 'utf-8') as result_txt:
result_txt.write(en_input+'\n'+true_sentence+'\n'+pred_sentence+'\n'+medical_score+'\n')print(f"medical测试集全部测试完毕,累计{num_of_exampels_to_evaluate}条数据,已经全部写入result_medical.txt文件中")
total_medical_score = sum(medical_scores)print(f"平均得分为: {total_medical_score/len(medical_scores)}")medical测试集全部测试完毕,累计1000条数据,已经全部写入result_medical.txt文件中 平均得分为: 0.40783529999999996
最后将迁移学习后的模型保存在output_2文件夹中。
由于生成版本时体积首受限,在包含output_2文件夹后,体积超过了1GB,无法保存,故在生成版本时,没有保存output_2文件夹。
paddle.save(load_encoder.state_dict(),'./output_2/encoder.pdparams') paddle.save(load_decoder.state_dict(),'./output_2/decoder.pdparams')
在此处,我们将展示在迁移训练前后的对patent测试集预测的效果对比图,以及最后三种测试集的平均得分图。
# 此处比较的迁移训练前后的对patent测试集预测的效果对比图def show_1(before_score,after_score):
plt.rcParams['font.family'] = ['Arial Unicode MS','Microsoft YaHei','SimHei','sans-serif']
plt.rcParams['axes.unicode_minus'] = False
X = ['before', 'after'] #X轴数据
Y = [round(before_score,5),round(after_score,5)] #Y轴数据
plt.style.use('ggplot') #添加网格线
plt.title("compare") #柱状图标题
plt.colors()
plt.bar(X, Y, 0.4, color="blue") #绘制柱状图
for i in range(len(Y)):
plt.text(i, Y[i]+0.02, "%s" % Y[i], va='center') #显示y轴数据
plt.savefig('compare.jpg') # 保存到本地文件夹,当前路径下
plt.show() # 显示柱状图show_1(total_patent_score_before/len(patent_scores_before),total_patent_score_after/len(patent_scores_after))/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:9: MatplotlibDeprecationWarning: The colors function was deprecated in version 2.1. if __name__ == '__main__':
<Figure size 432x288 with 1 Axes>
# 此处比较的迁移训练前后的对patent测试集预测的效果对比图def show_2(oral,patent,medical):
plt.rcParams['font.family'] = ['Arial Unicode MS','Microsoft YaHei','SimHei','sans-serif']
plt.rcParams['axes.unicode_minus'] = False
X = ['oral', 'patent','medical'] #X轴数据
Y = [round(oral,5),round(patent,5),round(medical,5)] #Y轴数据
plt.style.use('ggplot') #添加网格线
plt.title("compare") #柱状图标题
plt.colors()
plt.bar(X, Y, 0.4, color="blue") #绘制柱状图
for i in range(len(Y)):
plt.text(i, Y[i]+0.02, "%s" % Y[i], va='center') #显示y轴数据
plt.savefig('result.jpg') # 保存到本地文件夹,当前路径下
plt.show() # 显示柱状图show_2(total_oral_score/len(oral_scores),total_patent_score_after/len(patent_scores_after),total_medical_score/len(medical_scores))<Figure size 432x288 with 1 Axes>
以上就是机械翻译领域适应的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 582
582























