在实际的工作中,有时候需要根据图片中的指定区域进行重命名,通过PaddleOCR和PP-OCRv3实现可自主框选识别区,实现识别内容的精确提取。本任务提供30张交付验收单,采用PP-OCRv3的文字检测、文字识别,方向检测等模型通过PaddleOCR来组合完成识别图片中的铁塔名称,并根据该字段完成对图片的重命名。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

! mkdir dataset ! unzip -d dataset -q /home/aistudio/data/data149936/Scan_0012_0004.zip
import matplotlib.pyplot as pltfrom PIL import Image
%pylab inline
img = Image.open("/home/aistudio/dataset/Scan_0012_0004/Scan_0012_0019.jpg")
figsize = (48,24)
plt.figure("preview", figsize=figsize)
plt.imshow(img)
plt.show()Populating the interactive namespace from numpy and matplotlib
<Figure size 3456x1728 with 1 Axes>
使用飞桨场景应用开发套件PaddleOCR + PP-OCRv3实现。
PP-OCRv3在PP-OCRv2的基础上进一步升级。整体的框架图保持了与PP-OCRv2相同的pipeline,针对检测模型和识别模型进行了优化。其中,检测模块仍基于DB算法优化,而识别模块不再采用CRNN,换成了IJCAI 2022最新收录的文本识别算法SVTR,并对其进行产业适配。PP-OCRv3系统框图如下所示(粉色框中为PP-OCRv3新增策略):
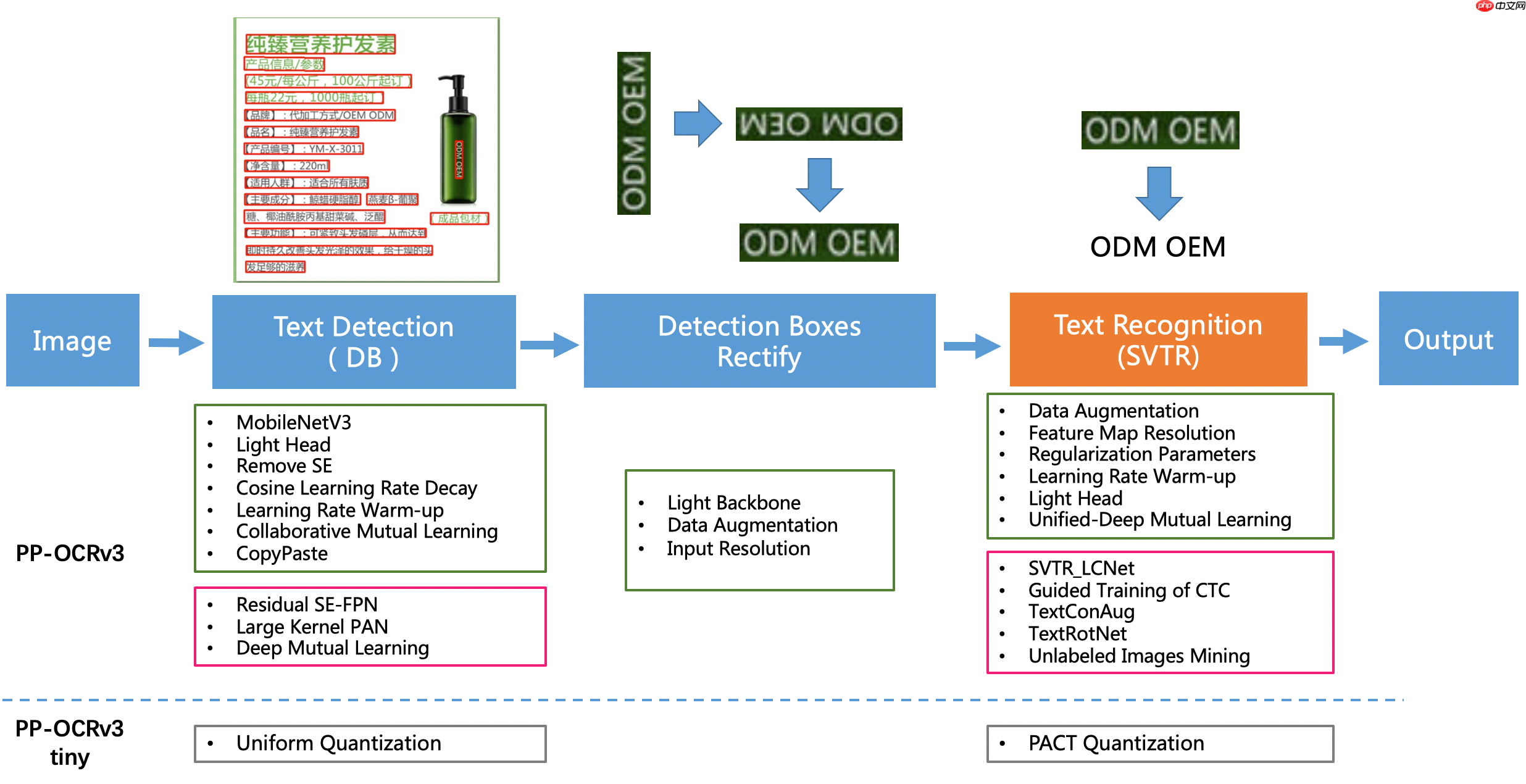
检测模块:
识别模块:
从效果上看,速度可比情况下,多种场景精度均有大幅提升:
# 如仍需安装or安装更新,可以执行以下步骤# ! git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygra# 如果访问不了,可从国内尽享下载# ! git clone https://gitee.com/PaddlePaddle/PaddleOCR# 如果限网速慢,这里提前下载了一个,解压即可.! unzip -q PaddleOCR.zip
# 安装依赖包%cd /home/aistudio/PaddleOCR ! pip install -r requirements.txt ! pip install yacs gnureadline paddlenlp==2.2.1
%cd /home/aistudio/PaddleOCR ! mkdir inference# 下载超轻量级中文OCR模型的检测模型并解压! cd inference && wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar && tar xf ch_PP-OCRv3_det_infer.tar && rm ch_PP-OCRv3_det_infer.tar# 下载超轻量级中文OCR模型的识别模型并解压! cd inference && wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar && tar xf ch_PP-OCRv3_rec_infer.tar && rm ch_PP-OCRv3_rec_infer.tar# 下载超轻量级中文OCR模型的文本方向分类器模型并解压! cd inference && wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar && tar xf ch_ppocr_mobile_v2.0_cls_infer.tar && rm ch_ppocr_mobile_v2.0_cls_infer.tar
/home/aistudio/PaddleOCR --2022-06-14 19:55:17-- https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar 正在解析主机 paddleocr.bj.bcebos.com (paddleocr.bj.bcebos.com)... 182.61.200.195, 182.61.200.229, 2409:8c04:1001:1002:0:ff:b001:368a 正在连接 paddleocr.bj.bcebos.com (paddleocr.bj.bcebos.com)|182.61.200.195|:443... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度: 3829760 (3.7M) [application/x-tar] 正在保存至: “ch_PP-OCRv3_det_infer.tar” ch_PP-OCRv3_det_inf 100%[===================>] 3.65M 12.4MB/s in 0.3s 2022-06-14 19:55:17 (12.4 MB/s) - 已保存 “ch_PP-OCRv3_det_infer.tar” [3829760/3829760]) --2022-06-14 19:55:17-- https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar 正在解析主机 paddleocr.bj.bcebos.com (paddleocr.bj.bcebos.com)... 182.61.200.195, 182.61.200.229, 2409:8c04:1001:1002:0:ff:b001:368a 正在连接 paddleocr.bj.bcebos.com (paddleocr.bj.bcebos.com)|182.61.200.195|:443... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度: 11909120 (11M) [application/x-tar] 正在保存至: “ch_PP-OCRv3_rec_infer.tar” ch_PP-OCRv3_rec_inf 100%[===================>] 11.36M 9.66MB/s in 1.2s 2022-06-14 19:55:19 (9.66 MB/s) - 已保存 “ch_PP-OCRv3_rec_infer.tar” [11909120/11909120]) --2022-06-14 19:55:19-- https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar 正在解析主机 paddleocr.bj.bcebos.com (paddleocr.bj.bcebos.com)... 182.61.200.229, 182.61.200.195, 2409:8c04:1001:1002:0:ff:b001:368a 正在连接 paddleocr.bj.bcebos.com (paddleocr.bj.bcebos.com)|182.61.200.229|:443... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度: 1454080 (1.4M) [application/x-tar] 正在保存至: “ch_ppocr_mobile_v2.0_cls_infer.tar” ch_ppocr_mobile_v2. 100%[===================>] 1.39M 3.24MB/s in 0.4s 2022-06-14 19:55:20 (3.24 MB/s) - 已保存 “ch_ppocr_mobile_v2.0_cls_infer.tar” [1454080/1454080])
直接通过PaddleOCR自带的预测工具和之前解压的推理模型预测
# 直接使用预训练的推理模型预测%cd /home/aistudio/PaddleOCR
!python tools/infer/predict_system.py \
--image_dir="/home/aistudio/dataset/Scan_0012_0004/" \
--det_model_dir="./inference/ch_PP-OCRv3_det_infer/" \
--rec_model_dir="./inference/ch_PP-OCRv3_rec_infer/" \
--cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer"# 查看预测后图片%cd /home/aistudio/PaddleOCR !ls ./inference_results/
/home/aistudio/PaddleOCR Scan_0012_0001.jpg Scan_0012_0009.jpg Scan_0012_0017.jpg Scan_0012_0025.jpg Scan_0012_0002.jpg Scan_0012_0010.jpg Scan_0012_0018.jpg Scan_0012_0026.jpg Scan_0012_0003.jpg Scan_0012_0011.jpg Scan_0012_0019.jpg Scan_0012_0027.jpg Scan_0012_0004.jpg Scan_0012_0012.jpg Scan_0012_0020.jpg Scan_0012_0028.jpg Scan_0012_0005.jpg Scan_0012_0013.jpg Scan_0012_0021.jpg Scan_0012_0029.jpg Scan_0012_0006.jpg Scan_0012_0014.jpg Scan_0012_0022.jpg Scan_0012_0030.jpg Scan_0012_0007.jpg Scan_0012_0015.jpg Scan_0012_0023.jpg system_results.txt Scan_0012_0008.jpg Scan_0012_0016.jpg Scan_0012_0024.jpg
%cd /home/aistudio/PaddleOCRimport matplotlib.pyplot as pltfrom PIL import Image
%matplotlib inline
img = Image.open("./inference_results/Scan_0012_0019.jpg")
plt.figure("preview", figsize=(48,24))
plt.imshow(img)
plt.show()/home/aistudio/PaddleOCR
<Figure size 3456x1728 with 1 Axes>
import jsonfrom PIL import Imageimport re"""
解析OCR预测结果,找出“铁塔名称”对应值
"""def parse_ocr_result(dataset_path,question_label_name="铁塔名称"):
file = open(dataset_path+'/system_results.txt')
newinfo = {}
i = 0
lines = ""
while True:
line = file.readline() if not line: break
image_path,ocr_info = line.split("\t");
ocr_infos = json.loads(ocr_info)
question_label_points = []; # 1.定位“铁塔名称”文字的位置
for ocr_info in ocr_infos: if ocr_info['transcription'] == question_label_name:
question_label_points = ocr_info['points'] # 【左上,右上,右下,左下】
if question_label_points == []: continue
# 2.找到“铁塔名称”文字右边的有效标签,可能分多行,多行文本按标签排序
valid_labels=[]; for ocr_info in ocr_infos:
label_points = ocr_info['points'] if ocr_info['transcription'] == question_label_name: continue
if label_points[0][0] < question_label_points[1][0]: continue
if label_points[3][1] < question_label_points[1][1]: continue
if label_points[0][1] > question_label_points[3][1]: continue
# lines += image_path +"\t" + ocr_info['transcription'] + "\n"
#按Y轴从小到大的顺序添加
if valid_labels == []:
valid_labels.append(ocr_info)
else: if valid_labels[-1]['points'][0][1] < label_points[0][1]:
valid_labels.append(ocr_info)
elif valid_labels[0]['points'][0][1] > label_points[0][1]:
valid_labels.insert(ocr_info)
answer_text = ''
for valid_label in valid_labels:
answer_text += valid_label['transcription'] # lines += image_path +"\t" + answer_text + "\n"
lines += "mv "+image_path+" "+answer_text+".jpg \n"
print(lines) with open(dataset_path+'/rename_info.txt','w+',encoding='utf-8') as f2:
f2.writelines(lines)
parse_ocr_result('/home/aistudio/PaddleOCR/inference_results', "铁塔名称")mv Scan_0012_0001.jpg 名嘉广场置业有限公司前绿化带.jpg mv Scan_0012_0002.jpg 泰山区凤凰小区南侧.jpg mv Scan_0012_0003.jpg 泰山区华城丽景湾北.jpg mv Scan_0012_0004.jpg 中国山东泰安主城区国棉北机房无线.jpg mv Scan_0012_0005.jpg 老王府村北十字路口绿化带.jpg mv Scan_0012_0006.jpg 时代大厦西区.jpg mv Scan_0012_0007.jpg 高新区龙腾路青年特车西.jpg mv Scan_0012_0008.jpg 泰山区上峪环山路卧龙大观北.jpg mv Scan_0012_0009.jpg 泰山区上峪环山路卧龙大观北.jpg mv Scan_0012_0010.jpg 泰山区白马石东一体化基站.jpg mv Scan_0012_0011.jpg 泰山区徐家楼栗家庄南快装.jpg mv Scan_0012_0012.jpg 泰山区建行于部学校.jpg mv Scan_0012_0013.jpg 宁阳磁窑力博集团办公楼-3G.jpg mv Scan_0012_0014.jpg 宁阳县东庄王家庄.jpg mv Scan_0012_0015.jpg 宁阳华丰机电高庄山坡.jpg mv Scan_0012_0016.jpg 杨家集-2.jpg mv Scan_0012_0017.jpg 新泰市放城涝坡村.jpg mv Scan_0012_0018.jpg 新泰市宫里镇桃园村中间.jpg mv Scan_0012_0019.jpg 中国山东泰安新泰宫里西南佐机房无线.jpg mv Scan_0012_0020.jpg 新泰市龙廷胡家庄新建.jpg mv Scan_0012_0021.jpg 中国山东泰安新泰赵家峪机房无线.jpg mv Scan_0012_0022.jpg 泉沟庙子牌村.jpg mv Scan_0012_0023.jpg 新泰龙庭刘家石山子机房无线.jpg mv Scan_0012_0024.jpg 新泰西韩.jpg mv Scan_0012_0025.jpg 新泰星泰晶光电.jpg mv Scan_0012_0026.jpg 新泰泉沟高崖头.jpg mv Scan_0012_0027.jpg 新泰楼德镇封家庄.jpg mv Scan_0012_0029.jpg 新泰市西张庄湖西社区.jpg mv Scan_0012_0030.jpg 岱岳区惠普西区西新建.jpg
正确率为: 28 / 30 = 93.33% 达到任务要求
| 图片名称 | 识别的文字 | 是否正确 | 说明 |
|---|---|---|---|
| Scan_0012_0014.jpg | 宁阳县东庄王家庄 | 错误 | 【未识别修改的手写文字】 |
| Scan_0012_0028.jpg | 错误 | 【把铁塔名称 识别成了 伙塔名称】 |
查看错误及原因分析:
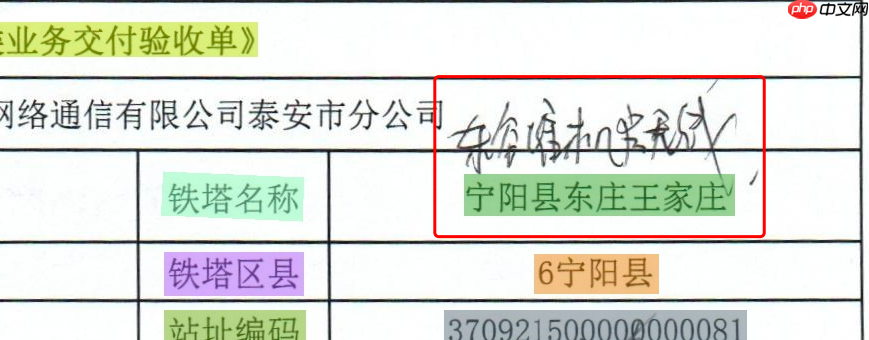
未能检测出手写体,可尝试训练文字检测模型
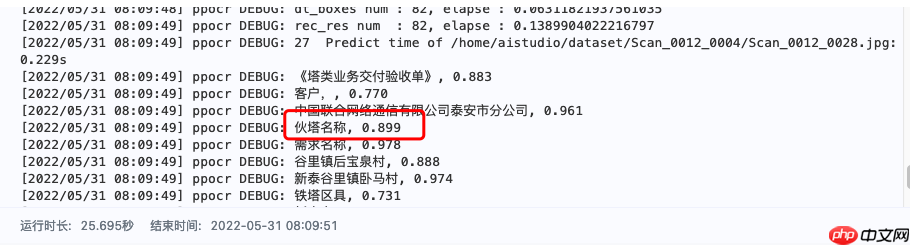
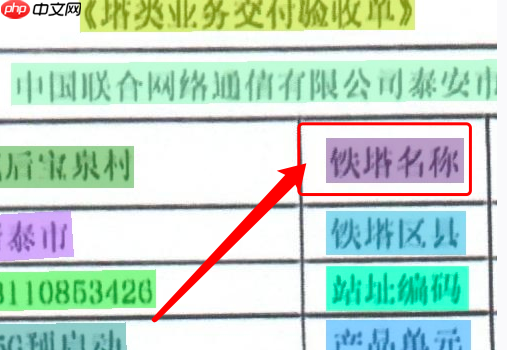
由于图片模糊,图上的“铁” 也很像 “伙” 字,可尝试训练文字识别模型。
由于把“铁塔名称” 错误的识别为了“伙塔名称”,可以通过训练的方法来提高识别率的。
在这里提供一种不用训练的方法,由于是相同的文档,标注的位置也是相对固定的,也就是可以通过其他的图片的标签位置来定位(图片尺寸差不多大和相近的倾斜度),那么就可以在识别失败的情况下,找到相近的图片上“铁塔名称”位置。
import osimport jsonfrom PIL import Imageimport reimport mathdef get_images_question(dataset_path,question_label_name):
file = open(dataset_path+'/system_results.txt')
newinfo = {}
i = 0
lines = ""
question_labels = []; while True:
line = file.readline() if not line: break
image_path,ocr_info = line.split("\t");
ocr_infos = json.loads(ocr_info) # 1.定位“铁塔名称”文字的位置
for ocr_info in ocr_infos: if ocr_info['transcription'] == question_label_name:
img = Image.open(dataset_path+'/'+image_path)
ocr_info['width'] = img.width
question_labels.append(ocr_info) return question_labelsdef get_nearly_point(dataset_path,image_path,valid_questions):
img = Image.open(dataset_path+'/'+image_path)
width_nearly=[] #保存图片宽度
for question in valid_questions:
width_nearly.append([question['transcription'],abs(question['width'] - img.width),question['points']])
min_diff = width_nearly[0][1]
min_points = width_nearly[0][2] for item in width_nearly: if item[0] == image_path: #排除自身
continue
if int(item[1]) < int(min_diff):
min_diff = int(item[1])
min_points = item[2]
return min_points"""
解析OCR预测结果,找出“铁塔名称”对应值
"""def parse_ocr_result2(dataset_path,valid_questions,question_label_name="铁塔名称"):
file = open(dataset_path+'/system_results.txt')
newinfo = {}
i = 0
lines = ""
rename_info = [] while True:
line = file.readline() if not line: break
image_path,ocr_info = line.split("\t");
ocr_infos = json.loads(ocr_info)
question_label_points = []; # 1.定位“铁塔名称”文字的位置
for ocr_info in ocr_infos: if ocr_info['transcription'] == question_label_name:
question_label_points = ocr_info['points'] # 【左上,右上,右下,左下】
if question_label_points == []:
question_label_points = get_nearly_point(dataset_path,image_path,valid_questions) # continue
# 2.找到“铁塔名称”文字右边的有效标签,可能分多行,多行文本按标签排序
valid_labels=[]; for ocr_info in ocr_infos:
label_points = ocr_info['points'] if ocr_info['transcription'] == question_label_name: continue
if label_points[0][0] < question_label_points[1][0]: continue
if label_points[3][1] < question_label_points[1][1]: continue
if label_points[0][1] > question_label_points[3][1]: continue
# lines += image_path +"\t" + ocr_info['transcription'] + "\n"
#按Y轴从小到大的顺序添加
if valid_labels == []:
valid_labels.append(ocr_info)
else: if valid_labels[-1]['points'][0][1] < label_points[0][1]:
valid_labels.append(ocr_info)
elif valid_labels[0]['points'][0][1] > label_points[0][1]:
valid_labels.insert(ocr_info) # # 没识别出标签
# if valid_labels == []:
# print(image_path,"图中未识别到 ",question_label_name," 标签对应的答案")
answer_text = ''
for valid_label in valid_labels:
answer_text += valid_label['transcription'] #防止重名
i=1
if answer_text in rename_info:
answer_text = answer_text+"("+ str(i) +")"
i=i+1
rename_info.append(answer_text)
ext = os.path.splitext(image_path)[-1]
lines += "mv "+image_path+" "+answer_text+ ext+" \n"
print(lines) with open(dataset_path+'/rename_info.sh','w+',encoding='utf-8') as f2:
f2.writelines(lines)
valid_questions = get_images_question('/home/aistudio/PaddleOCR/inference_results',"铁塔名称")# print(valid_questions)parse_ocr_result2('/home/aistudio/PaddleOCR/inference_results',valid_questions, "铁塔名称")mv Scan_0012_0001.jpg 名嘉广场置业有限公司前绿化带.jpg mv Scan_0012_0002.jpg 泰山区凤凰小区南侧.jpg mv Scan_0012_0003.jpg 泰山区华城丽景湾北.jpg mv Scan_0012_0004.jpg 中国山东泰安主城区国棉北机房无线.jpg mv Scan_0012_0005.jpg 老王府村北十字路口绿化带.jpg mv Scan_0012_0006.jpg 时代大厦西区.jpg mv Scan_0012_0007.jpg 高新区龙腾路青年特车西.jpg mv Scan_0012_0008.jpg 泰山区上峪环山路卧龙大观北.jpg mv Scan_0012_0009.jpg 泰山区上峪环山路卧龙大观北(1).jpg mv Scan_0012_0010.jpg 泰山区白马石东一体化基站.jpg mv Scan_0012_0011.jpg 泰山区徐家楼栗家庄南快装.jpg mv Scan_0012_0012.jpg 泰山区建行于部学校.jpg mv Scan_0012_0013.jpg 宁阳磁窑力博集团办公楼-3G.jpg mv Scan_0012_0014.jpg 宁阳县东庄王家庄.jpg mv Scan_0012_0015.jpg 宁阳华丰机电高庄山坡.jpg mv Scan_0012_0016.jpg 杨家集-2.jpg mv Scan_0012_0017.jpg 新泰市放城涝坡村.jpg mv Scan_0012_0018.jpg 新泰市宫里镇桃园村中间.jpg mv Scan_0012_0019.jpg 中国山东泰安新泰宫里西南佐机房无线.jpg mv Scan_0012_0020.jpg 新泰市龙廷胡家庄新建.jpg mv Scan_0012_0021.jpg 中国山东泰安新泰赵家峪机房无线.jpg mv Scan_0012_0022.jpg 泉沟庙子牌村.jpg mv Scan_0012_0023.jpg 新泰龙庭刘家石山子机房无线.jpg mv Scan_0012_0024.jpg 新泰西韩.jpg mv Scan_0012_0025.jpg 新泰星泰晶光电.jpg mv Scan_0012_0026.jpg 新泰泉沟高崖头.jpg mv Scan_0012_0027.jpg 新泰楼德镇封家庄.jpg mv Scan_0012_0028.jpg 新泰谷里镇卧马村.jpg mv Scan_0012_0029.jpg 新泰市西张庄湖西社区.jpg mv Scan_0012_0030.jpg 岱岳区惠普西区西新建.jpg
可以看到图片 Scan_0012_0028.jpg 能正确的识别出来,准确率达到了:29/30 = 96.66%。
# 重命名图片%cd /home/aistudio/dataset/Scan_0012_0004 ! cp /home/aistudio/PaddleOCR/inference_results/rename_info.sh ./rename_info.sh ! chmod +x ./rename_info.sh ! ./rename_info.sh ! ls -l
/home/aistudio/dataset/Scan_0012_0004 总用量 10412 -rw-r--r-- 1 aistudio aistudio 273453 5月 27 23:48 Cache.cach -rw-r--r-- 1 aistudio aistudio 1830 5月 28 02:29 fileState.txt -rw-r--r-- 1 aistudio aistudio 282102 5月 28 02:29 Label.txt -rwxr-xr-x 1 aistudio aistudio 1758 6月 14 20:04 rename_info.sh -rw-rw-r-- 1 aistudio aistudio 84741 3月 14 16:18 岱岳区惠普西区西新建.jpg -rw-rw-r-- 1 aistudio aistudio 338730 4月 14 15:08 高新区龙腾路青年特车西.jpg -rw-rw-r-- 1 aistudio aistudio 340501 4月 14 15:08 老王府村北十字路口绿化带.jpg -rw-rw-r-- 1 aistudio aistudio 347492 4月 14 15:08 名嘉广场置业有限公司前绿化带.jpg -rw-rw-r-- 1 aistudio aistudio 353122 4月 14 15:08 宁阳磁窑力博集团办公楼-3G.jpg -rw-rw-r-- 1 aistudio aistudio 353207 4月 14 15:08 宁阳华丰机电高庄山坡.jpg -rw-rw-r-- 1 aistudio aistudio 353197 4月 14 15:08 宁阳县东庄王家庄.jpg -rw-rw-r-- 1 aistudio aistudio 342838 4月 14 15:08 泉沟庙子牌村.jpg -rw-rw-r-- 1 aistudio aistudio 326687 4月 14 15:08 时代大厦西区.jpg -rw-rw-r-- 1 aistudio aistudio 322228 4月 14 15:08 泰山区白马石东一体化基站.jpg -rw-rw-r-- 1 aistudio aistudio 336812 4月 14 15:08 泰山区凤凰小区南侧.jpg -rw-rw-r-- 1 aistudio aistudio 345223 4月 14 15:08 泰山区华城丽景湾北.jpg -rw-rw-r-- 1 aistudio aistudio 331096 4月 14 15:08 泰山区建行于部学校.jpg -rw-rw-r-- 1 aistudio aistudio 332820 4月 14 15:08 泰山区上峪环山路卧龙大观北(1).jpg -rw-rw-r-- 1 aistudio aistudio 334887 4月 14 15:08 泰山区上峪环山路卧龙大观北.jpg -rw-rw-r-- 1 aistudio aistudio 336941 4月 14 15:08 泰山区徐家楼栗家庄南快装.jpg -rw-rw-r-- 1 aistudio aistudio 344522 4月 14 15:08 新泰谷里镇卧马村.jpg -rw-rw-r-- 1 aistudio aistudio 340358 4月 14 15:08 新泰龙庭刘家石山子机房无线.jpg -rw-rw-r-- 1 aistudio aistudio 349802 4月 14 15:08 新泰楼德镇封家庄.jpg -rw-rw-r-- 1 aistudio aistudio 349315 4月 14 15:08 新泰泉沟高崖头.jpg -rw-rw-r-- 1 aistudio aistudio 349701 4月 14 15:08 新泰市放城涝坡村.jpg -rw-rw-r-- 1 aistudio aistudio 337822 4月 14 15:08 新泰市宫里镇桃园村中间.jpg -rw-rw-r-- 1 aistudio aistudio 341103 4月 14 15:08 新泰市龙廷胡家庄新建.jpg -rw-rw-r-- 1 aistudio aistudio 349320 4月 14 15:08 新泰市西张庄湖西社区.jpg -rw-rw-r-- 1 aistudio aistudio 346595 4月 14 15:08 新泰西韩.jpg -rw-rw-r-- 1 aistudio aistudio 344734 4月 14 15:08 新泰星泰晶光电.jpg -rw-rw-r-- 1 aistudio aistudio 351311 4月 14 15:08 杨家集-2.jpg -rw-rw-r-- 1 aistudio aistudio 344050 4月 14 15:08 中国山东泰安新泰宫里西南佐机房无线.jpg -rw-rw-r-- 1 aistudio aistudio 360440 4月 14 15:08 中国山东泰安新泰赵家峪机房无线.jpg -rw-rw-r-- 1 aistudio aistudio 341617 4月 14 15:08 中国山东泰安主城区国棉北机房无线.jpg
以上就是【校园AI Day-AI workshop】快速用PP-OCRv3识别并重命名的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 490
490























