
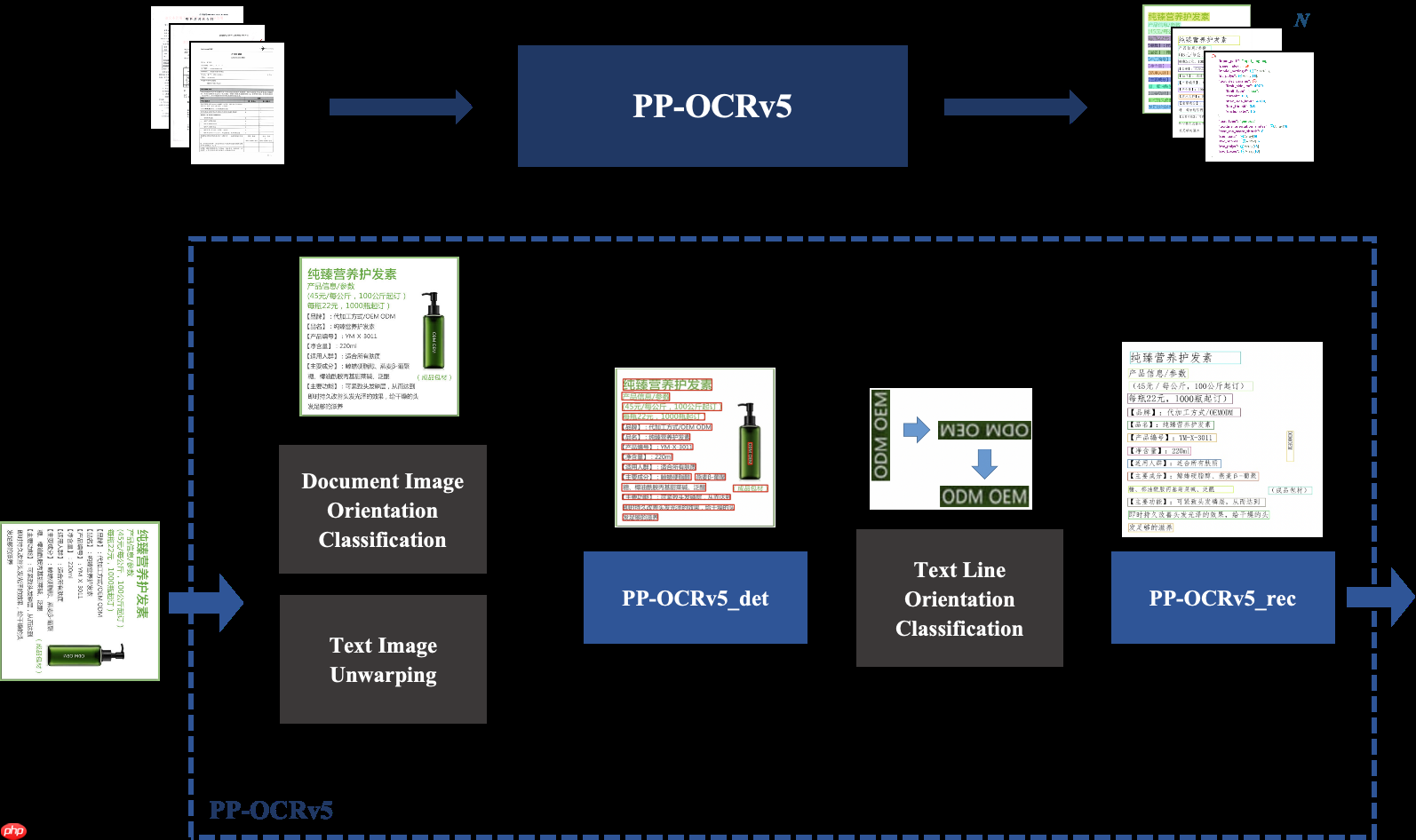
百度近日推出全新 OCR 模型 PP-OCRv5,致力于突破通用视觉语言模型(VLMs)在文字识别领域的应用瓶颈。作为 PP-OCR 系列的最新一代解决方案,PP-OCRv5 专注于应对多样场景与多种文字类型的识别挑战。
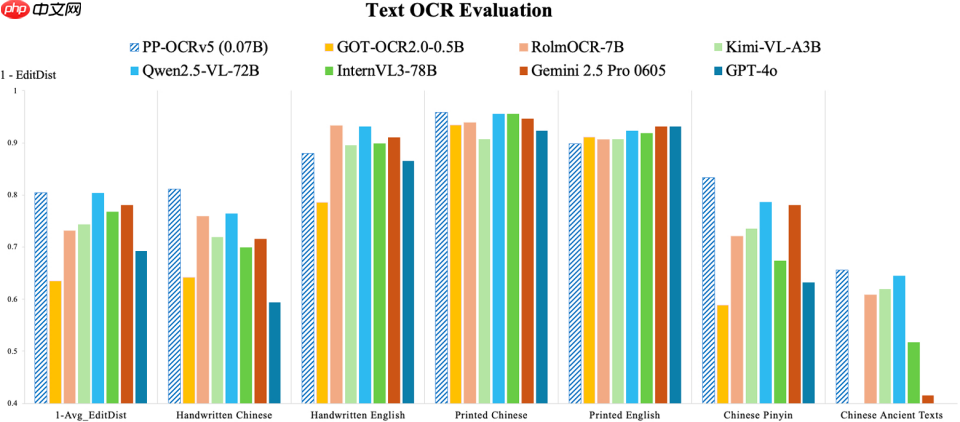
该模型全面支持简体中文、中文拼音、繁体中文、英文以及日文五大主流语言类型。在应用场景上,进一步优化了对中英文复杂手写体、竖排文本和生僻字等高难度情况的识别表现。在百度内部构建的多场景综合测试集上,PP-OCRv5 相比前代 PP-OCRv4 实现了端到端识别准确率提升达 13%。
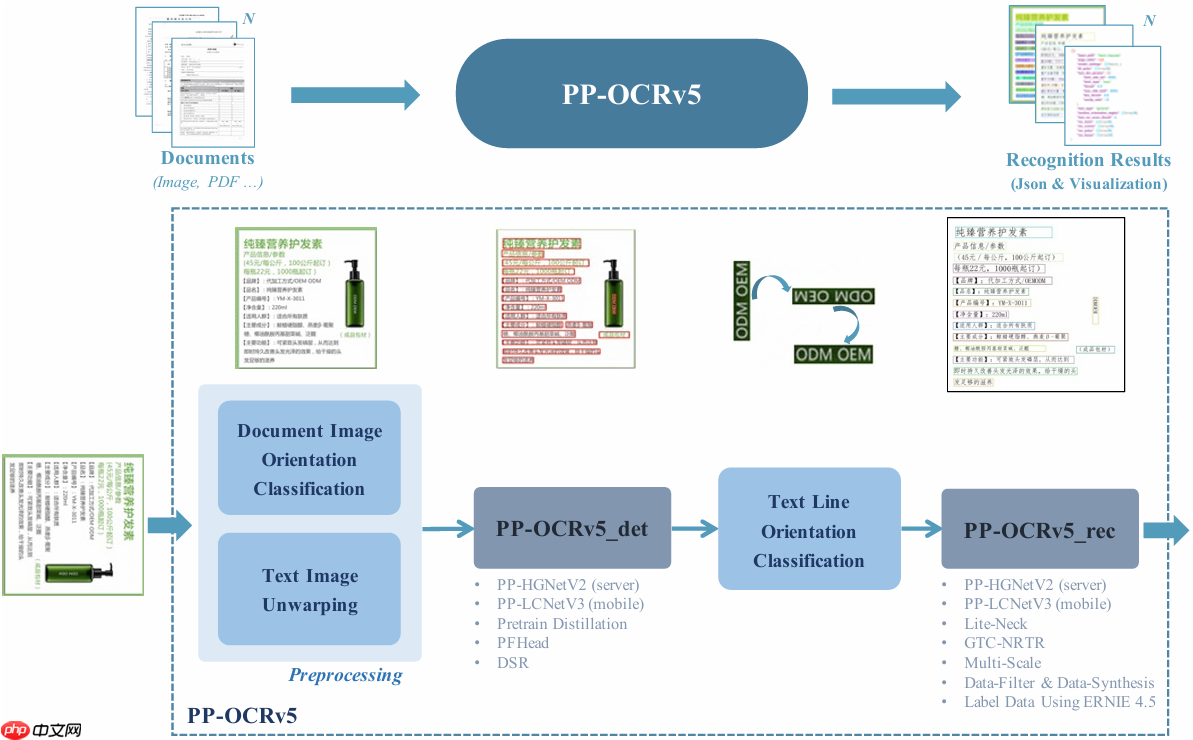
PP-OCRv5 采用高效的两阶段模块化架构,专为实现快速且精准的文本检测与识别而设计。整体模型更加轻量化,在保证高性能的同时显著降低资源消耗,特别适用于计算资源有限的设备部署。
其整体流程由四大核心模块构成:图像预处理、文本检测、文本行方向分类以及文本识别,形成完整的端到端识别流水线。
目前,PP-OCRv5 已正式发布于 Hugging Face 平台,用户可通过在线 Demo 实时体验其在多语言文档、手写内容及低质量扫描图像上的出色识别能力。开发者可从 Hugging Face Models 页面下载模型权重,并结合 PaddlePaddle 与 PaddleOCR 开源库在本地环境中进行部署和二次开发。
https://www.php.cn/link/89a82bfdadb7b2ee56416a986b0376ae
以上就是百度发布新一代文字识别解决方案:PP-OCRv5的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 221
221

























