它是一个表格,用于分类问题中评估模型中的错误发生在哪里。
行代表实际结果应该有的类别。而列代表了我们所做的预测。使用这个表,我们可以很容易地看出哪些预测是错误的。
混淆矩阵可以通过逻辑回归做出的预测来创建。
现在,我们将使用 NumPy 生成实际值和预测值:
import numpy
接下来,我们需要为 "actual" 和 "predicted" 值生成数字。
actual = numpy.random.binomial(1, 0.9, size = 1000) predicted = numpy.random.binomial(1, 0.9, size = 1000)
为了创建混淆矩阵,我们需要从 sklearn 模块中导入 metrics。
from sklearn import metrics
导入 metrics 后,我们可以在实际值和预测值上使用混淆矩阵函数。
confusion_matrix = metrics.confusion_matrix(actual, predicted)
为了创建一个更易理解的可视化展示,我们需要将表格转换为混淆矩阵展示。
cm_display = metrics.ConfusionMatrixDisplay(confusion_matrix = confusion_matrix, display_labels = [0, 1])
可视化展示需要我们从 matplotlib 中导入 pyplot。
import matplotlib.pyplot as plt
最后,为了展示图表,我们可以使用 pyplot 中的 plot() 和 show() 函数。
cm_display.plot() plt.show()
查看整个实例的实际运行效果:
import matplotlib.pyplot as plt import numpy from sklearn import metrics actual = numpy.random.binomial(1,.9,size = 1000) predicted = numpy.random.binomial(1,.9,size = 1000) confusion_matrix = metrics.confusion_matrix(actual, predicted) cm_display = metrics.ConfusionMatrixDisplay(confusion_matrix = confusion_matrix, display_labels = [0, 1]) cm_display.plot() plt.show()运行实例 »
点击 "运行实例" 按钮查看在线实例
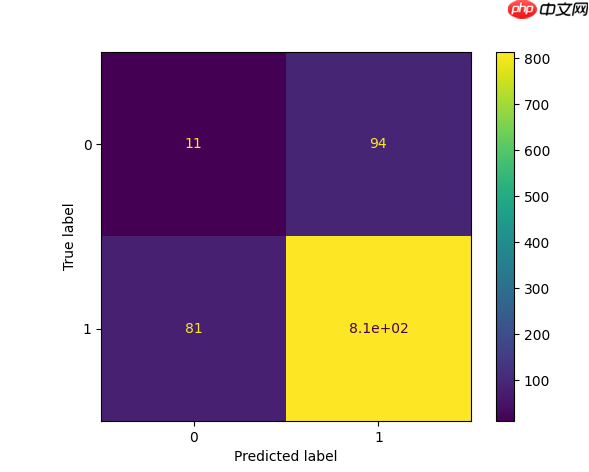
创建的混淆矩阵有四个不同的象限:
True 意味着值被准确地预测了,False 意味着存在错误或错误的预测。
现在我们已经创建了一个混淆矩阵,我们可以计算不同的度量来量化模型的质量。首先,让我们看看准确性。
矩阵为我们提供了许多有用的度量标准,帮助我们评估分类模型。
不同的度量标准包括:准确性、精确度、敏感性(召回率)、特异性和 F 分数,下面将进行解释。
准确性衡量模型正确的频率。
(True Positive + True Negative) / Total Predictions
中文译为:(真正例 + 真反例) / 总预测数
Accuracy = metrics.accuracy_score(actual, predicted)运行实例 »
点击 "运行实例" 按钮查看在线实例
在预测为正的结果中,真正为正的比例是多少?
True Positive / (True Positive + False Positive)
中文译为:真正例 / (真正例 + 假正例)
精确度不评估正确预测的反例:
Precision = metrics.precision_score(actual, predicted)运行实例 »
点击 "运行实例" 按钮查看在线实例
在所有正例中,预测为正的比例是多少?
敏感性(有时称为召回率)衡量模型在预测正例方面的表现如何。
这意味着它查看真正例和假反例(即被错误预测为反例的正例)。
True Positive / (True Positive + False Negative)
中文译为:真正例 / (真正例 + 假反例)
敏感性对于理解模型预测正例的能力很有用:
Sensitivity_recall = metrics.recall_score(actual, predicted)运行实例 »
点击 "运行实例" 按钮查看在线实例
模型在预测反例方面的表现如何?
特异性与敏感性相似,但它是从反例的角度来看的。
True Negative / (True Negative + False Positive)
中文译为:真反例 / (真反例 + 假正例)
因为它是召回率的相反概念,所以我们使用 recall_score 函数,采用相反的位置标签:
Specificity = metrics.recall_score(actual, predicted, pos_label=0)运行实例 »
点击 "运行实例" 按钮查看在线实例
F 分数是精确度和敏感性的“调和平均数”。
它同时考虑了假正例和假反例,并且对于不平衡的数据集很有用。
2 * ((Precision * Sensitivity) / (Precision + Sensitivity))
中文译为:2 * ((精确度 * 敏感性) / (精确度 + 敏感性))
这个分数没有考虑真反例的值:
F1_score = metrics.f1_score(actual, predicted)运行实例 »
点击 "运行实例" 按钮查看在线实例
所有计算合在一起:
# 度量标准
print({"准确性":Accuracy,"精确度":Precision,"敏感性_召回率":Sensitivity_recall,"特异性":Specificity,"F1分数":F1_score})
运行实例 »点击 "运行实例" 按钮查看在线实例
相关
视频
RELATED VIDEOS
科技资讯



1
2
3
4
5
6
7
8
9
精选课程

共5课时
17.3万人学习

共49课时
77.6万人学习

共29课时
62.1万人学习

共25课时
39.6万人学习

共43课时
71.4万人学习

共25课时
62万人学习

共22课时
23.1万人学习

共28课时
34.2万人学习

共89课时
126万人学习



























