






本文介绍了基于PaddlePaddle复现Stable Diffusion的过程。Stable Diffusion是开源的扩散模型,可文本生成图像。作者使用英特尔图像分类数据集,目标是输入类别生成对应图像。实现步骤包括数据处理、预处理、搭建UNet网络、构建Diffusion类、训练及推理,还提供了训练450轮的模型,生成效果初具雏形但需优化。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

【多模态地基】Stable Diffusion 从0到1
由于工作内容需要,最近自己看了一下Stable Diffusion,目前Stable Diffusion已经很成熟了,有很多开源的成型的项目,我这里也是四处借鉴(抄袭,bushi),复现了一个paddle版本Stable Diffusion。

仅供自己学习和大家学习
Stable Diffusion 是什么?
这个大家估计都知道了,我只简单的说一下吧,以防小白读者误入不明觉厉
Stable Diffusion 是一种扩散模型(Diffusion Model),属于生成模型的一种。它的工作原理是从一个纯噪声图像开始,通过一个反向扩散过程逐渐减少噪声,从而生成一个目标图像。这个过程可以理解为在模型训练阶段学习如何逐渐将一个噪声图像转化为一个清晰的图像,直到生成符合期望的输出。
Stable Diffusion 的特点
- 高质量图像生成:Stable Diffusion 能够生成高分辨率且细节丰富的图像。
- 文本到图像生成:它支持通过输入文本提示生成相应的图像,这意味着你可以通过简单的描述词语来生成你想要的图像。
- 开源和易于使用:Stable Diffusion 是一个开源项目,使用起来非常灵活,支持多种编程语言和框架,如 PaddlePaddle、PyTorch、TensorFlow 等。
结构如下:
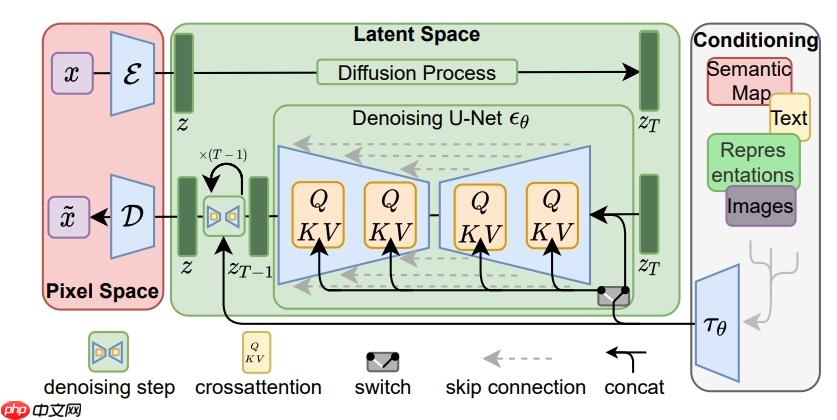
好了,上面全是废话。
浓缩为三个字就是:
文生图
数据集介绍
我这里使用的数据集是 英特尔 某年发布的一个图像分类的挑战赛的数据集
可以戳链接细看: Intel Image Classification
该数据包含约25k张150x150大小的图像,分为6类。
“建筑物”->0
“森林”->1
“冰川”->2
“山”->3
“海”->4
“街道”->5
训练、测试和预测数据在每个zip文件中都是分开的。列车中有大约14k个图像,测试中有3k个图像,预测中有7k个图像。
致谢 https://datahack.analyticsvidhya.com 挑战与英特尔数据照片
实现目标
我们的任务就是,构建一个图像生成的模型,将这几类的图片进行训练
目标:当我们输入“建筑物”时,就可以生成“建筑物图片”
可能有些同学会失望了,为什么不可以随意生成种类? 为什么不可以随意输入相关文本?
- 我是在本地写的Demo,搬运上来的,单单这几类图片的训练调大了分辨率之后都跑不起来,以至于只能64*64训练,更别提大模型了
- 一步步来,后续如果有时间和能力,我会继续跟进,加入Clip或者T5等文本编码器,支持随意的文本输入
开始实现
我的代码已经完全放在左侧的文件当中,可以点开查看
千博电子企业网站系统(又称企业网站系统、企业建站系统、企业网站模板)作为面向企业的CMS产品,从设计初期便建立在大量企业用户的实际需求基础上。我们结合企业用户的特点,设计了独到的功能,这些领先功能让基于“千博电子企业网站系统”的网站具有浓郁的企业味道。千博电子企业网站系统内建了大量Seo支持策略和工具,基于“千博企业网站系统”的网站本身就是Seo友好的。众多Seo策略,如:全站静态地址,静态内容,
第一步 数据处理
将项目中挂载的数据进行处理
!unzip /home/aistudio/data/data289174/datasets.zip -d /home/aistudio/datasets
# 详见data_show.pyimport osimport globimport matplotlib.pyplot as pltfrom PIL import Image# 读取图片 def read_image(root_path='./datasets', mode='train'):
img_class = {'buildings': 0,
'forest': 1,
'glacier': 2,
'mountain': 3,
'sea': 4,
'street': 5}
img_c = 'seg_' + mode
img_data = glob.glob(os.path.join(root_path, img_c) + '/*/*.jpg')
# 存入 图片路径和标签 txt 文件 每个类别一个 txt 文件
img_path = []
label_path = []
with open("data.txt", "w") as f: for img in img_data:
img_path.append(img)
label = img.split('/')[-2]
label_index = img_class[label]
f.write(img + ' '+ str(label_index) + '\n')
f.close()
return img_path, label_path
# 展示图片def show_imgs(image, col = 3):
num_sample = len(image)
i = 0
while i < num_sample:
img = Image.open(image[i])
label = image[i].split('/')[-2]
plt.subplot(int(num_sample/col+1), col, i + 1)
plt.imshow(img)
plt.title('label:' + label)
i += 1
plt.show()
if __name__ == '__main__': # 加载数据集
img_path = ['datasets/seg_train/buildings/0.jpg', 'datasets/seg_train/forest/8.jpg', 'datasets/seg_train/mountain/32.jpg']
# 展示训练集中的图片
show_imgs(img_path)
# 读取数据集 构建索引文件
read_image(mode= 'train')第二步 数据预处理
拿到数据索引文件 data.txt 之后,我们还要构建数据类用于训练
# 构建数据读取类# 返回图片与标签import paddle.vision as Vfrom PIL import Imagefrom paddle.io import Dataset, DataLoaderfrom tqdm import tqdm# 数据变换transforms = V.transforms.Compose([
V.transforms.Resize(80), # args.image_size + 1/4 *args.image_size
V.transforms.RandomResizedCrop(64, scale=(0.8, 1.0)),
V.transforms.ToTensor(),
V.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])class TrainData(Dataset):
def __init__(self, txt_path="data.txt"):
with open(txt_path, "r") as f:
data = f.readlines()
self.image_paths = data[:-1] # 最后一行是空行,舍弃
def __getitem__(self, index):
image_path, label = self.image_paths[index].strip().split(" ")
image = Image.open(image_path)
image = transforms(image)
label = int(label)
return image, label
def __len__(self):
return len(self.image_paths)
dataset = TrainData()
dataloader = DataLoader(dataset, batch_size=64, shuffle=True)第三步 UNet 网络搭建
这个不再详细讲了,UNet 已经是一个很经典的网络了
放个图片得了
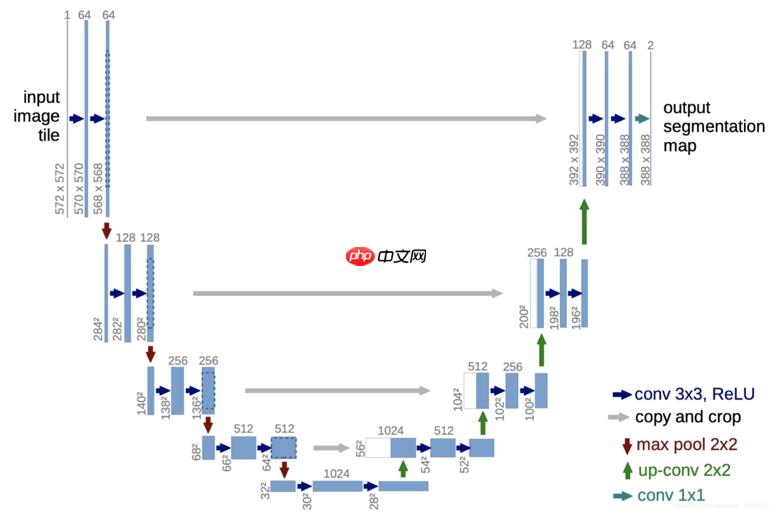
很经典,建议完全没不了解UNet的去搜一下原文和源码 学习一下
# 这里相关代码在 /home/aistudio/models/modules.pyimport paddleimport paddle.nn as nnimport paddle.nn.functional as Fclass EMA:
def __init__(self, beta):
super().__init__()
self.beta = beta
self.step = 0
def update_model_average(self, ma_model, current_model):
for current_params, ma_params in zip(current_model.parameters(), ma_model.parameters()):
old_weight, up_weight = ma_params, current_params
ma_params = self.update_average(old_weight, up_weight) def update_average(self, old, new):
if old is None: return new return old * self.beta + (1 - self.beta) * new def step_ema(self, ema_model, model, step_start_ema=1000):
if self.step < step_start_ema:
self.reset_parameters(ema_model, model)
self.step += 1
return
self.update_model_average(ema_model, model)
self.step += 1
def reset_parameters(self, ema_model, model):
ema_model.set_state_dict(model.state_dict())class SelfAttention(nn.Layer):
def __init__(self, channels):
super(SelfAttention, self).__init__()
self.channels = channels
self.mha = nn.MultiHeadAttention(channels, 4)
self.ln = nn.LayerNorm([channels])
self.ff_self = nn.Sequential(
nn.LayerNorm([channels]),
nn.Linear(channels, channels),
nn.GELU(),
nn.Linear(channels, channels),
) def forward(self, x):
batch_size, channels, height, width = x.shape
x = x.reshape([batch_size, channels, height*width]).transpose([0, 2, 1])
x_ln = self.ln(x)
attention_value = self.mha(x_ln, x_ln)
attention_value = attention_value + x
attention_value = self.ff_self(attention_value) + attention_value return attention_value.transpose([0, 2, 1]).reshape([batch_size, channels, height, width])class DoubleConv(nn.Layer):
def __init__(self, in_channels, out_channels, mid_channels=None, residual=False):
super().__init__()
self.residual = residual if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2D(in_channels, mid_channels, kernel_size=3, padding=1, bias_attr=False),
nn.GroupNorm(1, mid_channels),
nn.GELU(),
nn.Conv2D(mid_channels, out_channels, kernel_size=3, padding=1, bias_attr=False),
nn.GroupNorm(1, out_channels),
) def forward(self, x):
if self.residual: return F.gelu(x + self.double_conv(x)) else: return self.double_conv(x)class Down(nn.Layer):
def __init__(self, in_channels, out_channels, emb_dim=256):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2D(2),
DoubleConv(in_channels, in_channels, residual=True),
DoubleConv(in_channels, out_channels),
)
self.emb_layer = nn.Sequential(
nn.Silu(),
nn.Linear(
emb_dim,
out_channels
),
) def forward(self, x, t):
x = self.maxpool_conv(x)
emb = self.emb_layer(t)[:, :, None, None].tile([1, 1, x.shape[-2], x.shape[-1]]) return x + embclass Up(nn.Layer):
def __init__(self, in_channels, out_channels, emb_dim=256):
super().__init__()
self.up = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
self.conv = nn.Sequential(
DoubleConv(in_channels, in_channels, residual=True),
DoubleConv(in_channels, out_channels, in_channels // 2),
)
self.emb_layer = nn.Sequential(
nn.Silu(),
nn.Linear(
emb_dim,
out_channels
),
) def forward(self, x, skip_x, t):
x = self.up(x)
x = paddle.concat([skip_x, x], axis=1)
x = self.conv(x)
emb = self.emb_layer(t)[:, :, None, None].tile([1, 1, x.shape[-2], x.shape[-1]]) return x + embclass UNet(nn.Layer):
def __init__(self, c_in=3, c_out=3, time_dim=256, device="cuda"):
super().__init__()
self.device = device
self.time_dim = time_dim
self.inc = DoubleConv(c_in, 64)
self.down1 = Down(64, 128)
self.sa1 = SelfAttention(128)
self.down2 = Down(128, 256)
self.sa2 = SelfAttention(256)
self.down3 = Down(256, 256)
self.sa3 = SelfAttention(256)
self.bot1 = DoubleConv(256, 512)
self.bot2 = DoubleConv(512, 512)
self.bot3 = DoubleConv(512, 256)
self.up1 = Up(512, 128)
self.sa4 = SelfAttention(128)
self.up2 = Up(256, 64)
self.sa5 = SelfAttention(64)
self.up3 = Up(128, 64)
self.sa6 = SelfAttention(64)
self.outc = nn.Conv2D(64, c_out, kernel_size=1) def pos_encoding(self, t, channels):
inv_freq = 1.0 / ( 10000
** (paddle.arange(0, channels, 2).astype(paddle.float32) / channels)
)
pos_enc_a = paddle.sin(t.tile([1, channels // 2]) * inv_freq)
pos_enc_b = paddle.cos(t.tile([1, channels // 2]) * inv_freq)
pos_enc = paddle.concat([pos_enc_a, pos_enc_b], axis=-1) return pos_enc def unet_forward(self, x, t):
x1 = self.inc(x)
x2 = self.down1(x1, t)
x2 = self.sa1(x2)
x3 = self.down2(x2, t)
x3 = self.sa2(x3)
x4 = self.down3(x3, t)
x4 = self.sa3(x4)
x4 = self.bot1(x4)
x4 = self.bot2(x4)
x4 = self.bot3(x4)
x = self.up1(x4, x3, t)
x = self.sa4(x)
x = self.up2(x, x2, t)
x = self.sa5(x)
x = self.up3(x, x1, t)
x = self.sa6(x)
output = self.outc(x) return output def forward(self, x, t):
t = t.unsqueeze(-1).astype(paddle.float32)
t = self.pos_encoding(t, self.time_dim) return self.unet_forward(x, t)class UNet_conditional(UNet):
def __init__(self, c_in=3, c_out=3, time_dim=256, num_classes=None, device="cuda"):
super().__init__(c_in=c_in, c_out=c_out, time_dim=time_dim,device=device)
if num_classes is not None:
self.label_emb = nn.Embedding(num_classes, time_dim) def forward(self, x, t, y):
t = t.unsqueeze(-1).astype(paddle.float32)
t = self.pos_encoding(t, self.time_dim) if y is not None:
t += self.label_emb(y)
return self.unet_forward(x, t)第四步 Stable Diffusion 部分
这里给小白讲解一个误区,可能只接触过深度的同学会认为 Stable Diffusion 是个网络去用于训练
但实际上,他只是针对训练中的加噪声以及推理时,根据加的噪声进行去噪
# /home/aistudio/models/diffusion.pyimport paddlefrom tqdm import tqdmfrom tools import *class Diffusion:
def __init__(self, noise_steps=500, beta_start=1e-4, beta_end=0.02, img_size=256, device="cuda"):
self.noise_steps = noise_steps
self.beta_start = beta_start
self.beta_end = beta_end
self.beta = self.prepare_noise_schedule()
self.alpha = 1. - self.beta
self.alpha_hat = paddle.cumprod(self.alpha, dim=0)
self.img_size = img_size
self.device = device def prepare_noise_schedule(self):
return paddle.linspace(self.beta_start, self.beta_end, self.noise_steps) def noise_images(self, x, t):
sqrt_alpha_hat = paddle.sqrt(self.alpha_hat[t])[:, None, None, None]
sqrt_one_minus_alpha_hat = paddle.sqrt(1 - self.alpha_hat[t])[:, None, None, None]
Ɛ = paddle.randn(shape=x.shape) return sqrt_alpha_hat * x + sqrt_one_minus_alpha_hat * Ɛ, Ɛ def sample_timesteps(self, n):
return paddle.randint(low=1, high=self.noise_steps, shape=(n,)) def sample(self, model, n, labels, cfg_scale=3):
model.eval() with paddle.no_grad():
x = paddle.randn((n, 3, self.img_size, self.img_size)) for i in tqdm(reversed(range(1, self.noise_steps)), position=0, desc=f"denoising, wait for {self.noise_steps} steps ", unit=' steps',ncols=80):
t = paddle.to_tensor([i] * x.shape[0]).astype("int64")
predicted_noise = model(x, t, labels) if cfg_scale > 0:
uncond_predicted_noise = model(x, t, None)
cfg_scale = paddle.to_tensor(cfg_scale).astype("float32")
predicted_noise = paddle.lerp(uncond_predicted_noise, predicted_noise, cfg_scale)
alpha = self.alpha[t][:, None, None, None]
alpha_hat = self.alpha_hat[t][:, None, None, None]
beta = self.beta[t][:, None, None, None] if i > 1:
noise = paddle.randn(shape=x.shape) else:
noise = paddle.zeros_like(x)
x = 1 / paddle.sqrt(alpha) * (x - ((1 - alpha) / (paddle.sqrt(1 - alpha_hat))) * predicted_noise) + paddle.sqrt(beta) * noise
model.train()
x = (x.clip(-1, 1) + 1) / 2
x = (x * 255) return x# /home/aistudio/train.pyimport paddleimport paddle.nn as nnimport paddle.optimizer as optimizerfrom paddle.io import DataLoaderfrom models import *from dataset import TrainDataimport numpy as npimport matplotlib.pyplot as pltfrom tqdm import tqdmimport copyfrom tools import *
epochs = 1000batch_size = 16num_classes = 6lr = 1.5e-4image_size = 64load_checkpoints = Trueload_checkpoints_path = "weight/sd_unet_450.pdparams"dataset = TrainData()
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)def train():
device = "cuda" if paddle.device.is_compiled_with_cuda() else "cpu"
start_epoch = 0
if load_checkpoints:
start_epoch = get_checkponit_epoch(load_checkpoints_path)
model = UNet_conditional(num_classes=num_classes, device=device)
my_logger.info(f"Loading model from {load_checkpoints_path}")
params = paddle.load(load_checkpoints_path)
model.set_state_dict(params)
my_logger.info(f"Model loaded successfully!") else:
my_logger.info("Training from scratch")
model = UNet_conditional(num_classes=num_classes, device=device)
opt = optimizer.Adam(learning_rate=lr, parameters=model.parameters())
mse = nn.MSELoss()
diffusion = Diffusion(img_size=image_size, device=device)
l = len(dataloader)
ema = EMA(0.995)
ema_model = copy.deepcopy(model)
ema_model.eval()
for epoch in range(start_epoch,epochs):
cache_loss = 0
pbar = tqdm(dataloader, desc=f"[{my_time.get_time()}] Epoch {epoch}", position=0, leave=True) for i, (images, labels) in enumerate(pbar):
B = images.shape[0] # [B, C, H, W]
t = diffusion.sample_timesteps(B)
x_t, noise = diffusion.noise_images(images, t) if np.random.random() < 0.1:
labels = None
predicted_noise = model(x_t, t, labels)
loss = mse(noise, predicted_noise) # 损失函数
cache_loss += loss.item()
opt.clear_grad()
loss.backward()
opt.step()
ema.step_ema(ema_model, model)
pbar.set_postfix(MSE=loss.item())
my_logger.info(f"[{my_time.get_time()}] Epoch {epoch} loss: {cache_loss / l}")
if epoch % 10 == 0:
paddle.save(model.state_dict(), f"weight/sd_unet_{epoch}.pdparams")
if __name__ == '__main__': # 训练
train()第六步 推理
# 设置 字体 防止乱码 小方框import matplotlib.pyplot as pltfrom matplotlib.font_manager import FontProperties font = FontProperties(fname="/home/aistudio/msyh.ttc")
# /home/aistudio/eval.pyimport paddlefrom models import *import numpy as npimport matplotlib.pyplot as pltfrom PIL import Image
plt.rcParams['figure.figsize'] = (10, 5)
plt.rcParams['font.size'] = 15plt.rcParams['axes.unicode_minus'] = Falsemodel = UNet_conditional(num_classes=6)
model.set_state_dict(paddle.load("weight/sd_unet_450.pdparams")) # 加载模型文件diffusion = Diffusion(img_size=64, device="cuda")# 分别对应标签 0, 1, 2, 3, 4, 5 # 建筑物 森林 冰川 山峰 大海 街道name = ["建筑物", "森林", "冰川", "山峰", "大海", "街道"]
labels = paddle.to_tensor([0, 1, 2, 3, 4, 5]).astype("int64")# 标签引导强度cfg_scale = [7,10]# 假设我们想要将图像大小调整为256x256fixed_size = (256, 256)# 展示在不同标签引导强度下,生成的六类图像的效果for i in range(len(cfg_scale)):
sampled_images = diffusion.sample(model, n=len(labels), labels=labels, cfg_scale=cfg_scale[i]) for j in range(6):
img = sampled_images[j].transpose([1, 2, 0])
img = np.array(img).astype("uint8")
img = Image.fromarray(img).resize(fixed_size) # 调整图像大小
plt.subplot(len(cfg_scale), 6, i * 6 + j + 1)
plt.imshow(img)
plt.title(name[labels[j]],fontproperties=font)
plt.axis('off')
plt.tight_layout()
plt.show()denoising, wait for 500 steps : 499 steps [00:26, 19.00 steps/s] denoising, wait for 500 steps : 499 steps [00:26, 19.16 steps/s]
可以看到,生成的多少是个样子了,但是还需要调节参数和增加数据量来更进一步




























