第五期论文复现赛DMNet,DMNet适用于语义分割任务,本次复现的目标是Cityscapes 验证集miou 79.64%,复现的miou79.76%,该算法已被PaddleSeg合入。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

本文提出了动态卷积模块(Dynamic Convolutional Modules),该模块可以利用上下文信息生成不同大小的卷积核,自适应地学习图片的语义信息。该模型在Cityscapes验证集上mIOU为79.64%,本次复现的mIOU为79.76%,该算法已被PaddleSeg收录。
代码参考:https://github.com/open-mmlab/mmsegmentation/tree/master/configs/dmnet
本项目地址:https://github.com/justld/DMNet_paddle
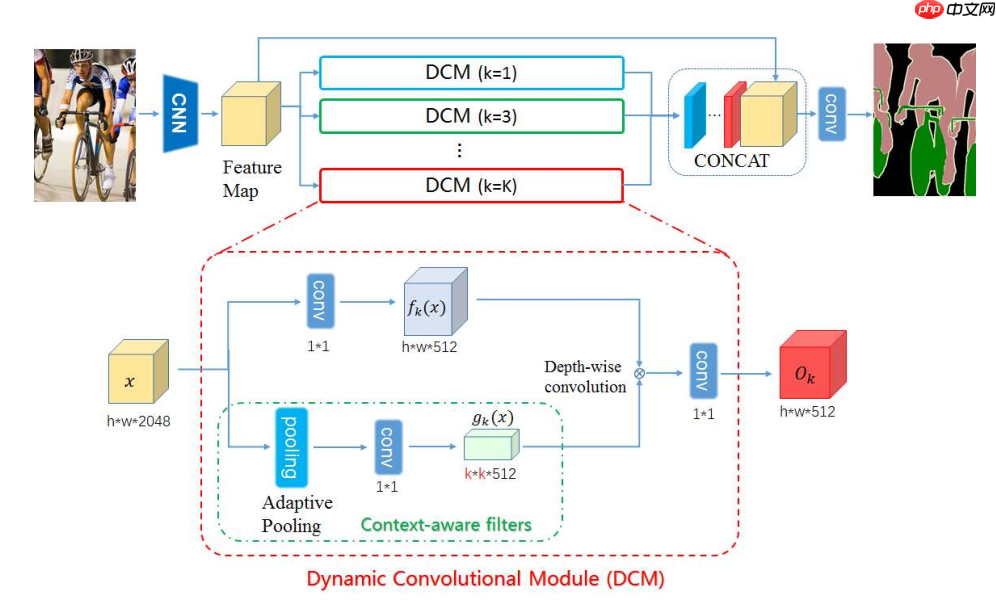
如上图所示,输入图片经过CNN(backbone网络)后,得到Feature Map,接着将Feature Map送入DCM模块,不同的DCM模块有着不同大小的卷积核,对应的感受野也不同,将特征图concat后送入语义分割head进行像素级分割。
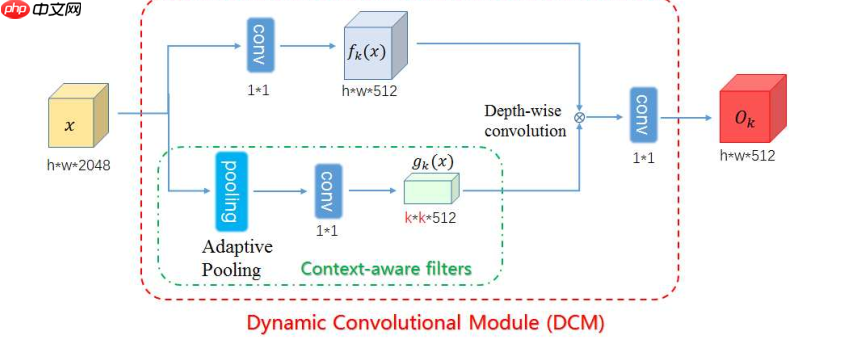
上图为DCM模块,该模块有2个分支:
分支一:使用1x1的卷积核压缩特征图的通道,得到fk(x);
分支二(Context-aware filters):对特征图进行平均池化,得到不同大小的特征图;
得到2个分支的特征图后,把分支二的特征图作为卷积核,和分支一的特征图进行深度可分离卷积运算,再经过1x1的卷积得到DCM的输出。(该模块的核心在于通过Adaptive Pooling得到不同大小的卷积核)
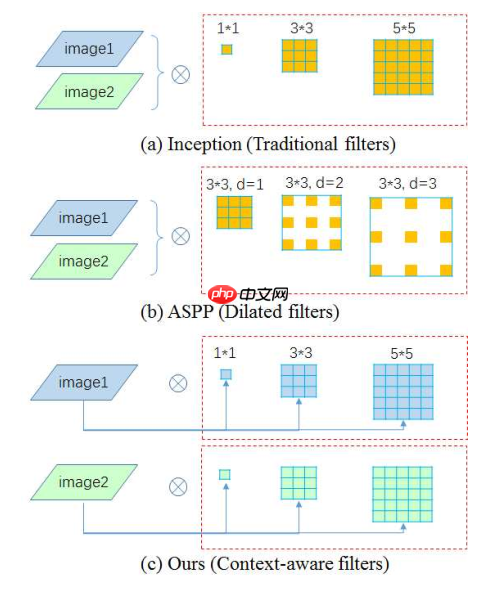
上图为不同的滤波器对比,为了使模型自适应学习适合的卷积核,Inception采用了多卷积通道(每个通道卷积核大小不同)融合的方法,ASPP采用了多空洞卷积通道(每个通道卷积核的Dilation不同)融合的方法,而DCM利用AdaptivePooling来生成卷积核,该方法能够更好的利用上下文信息。
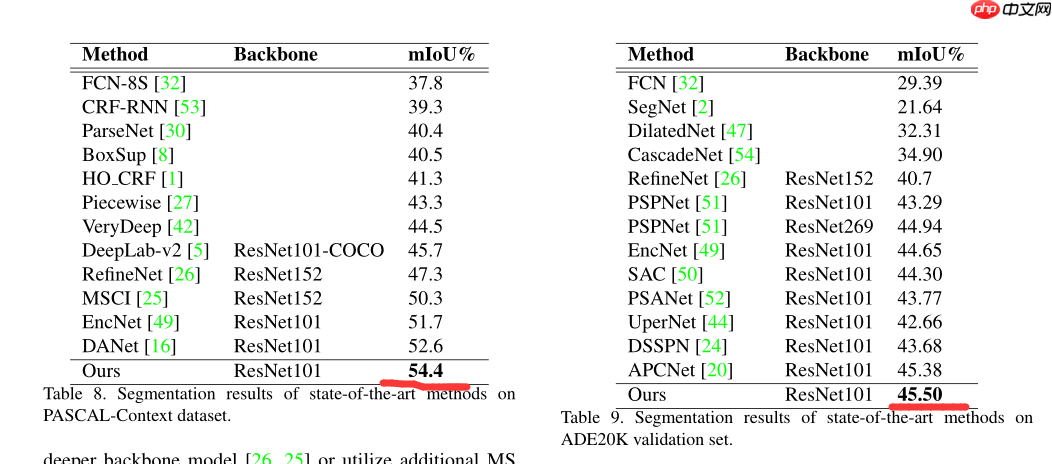
DMNet在PASCAL和ADE20K数据集上都获得了SOTA效果,在PASCAL验证集上的mIOU为54.4%,ADE20K验证集上的mIOU为45.5%。
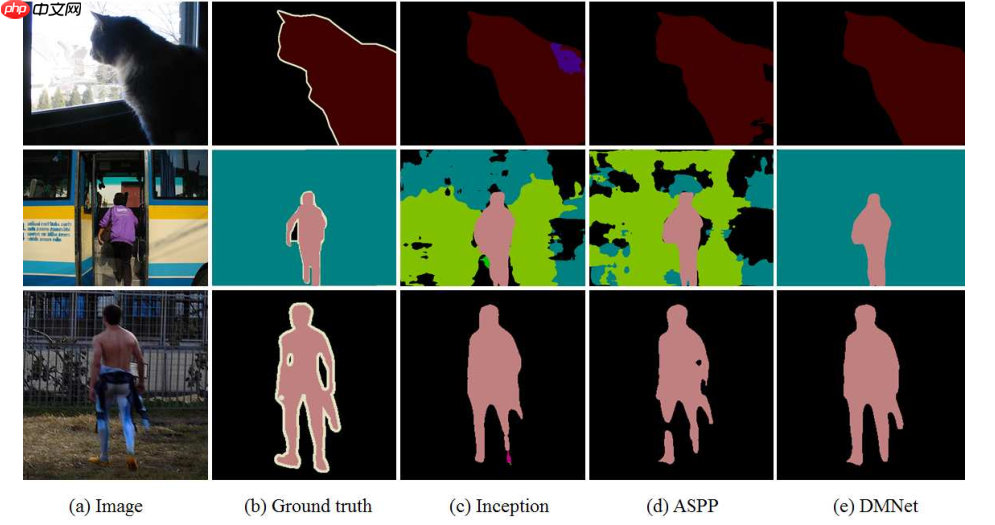
上图为采用了Inception、ASPP和DCM的分割结果对比,从上图可以看出,受益于DCM的滤波器生成策略,DCM能够更好的利用上下文信息来提升语义分割效果。
class DCM(nn.Layer):
"""
Dynamic Convolutional Module used in DMNet.
Args:
filter_size (int): The filter size of generated convolution kernel used in Dynamic Convolutional Module.
fusion (bool): Add one conv to fuse DCM output feature.
in_channels (int): Input channels.
channels (int): Channels after modules, before conv_seg.
"""
def __init__(self, filter_size, fusion, in_channels, channels):
super().__init__()
self.filter_size = filter_size # 滤波器尺寸
self.fusion = fusion # 是否在DCM的输出特征图后面加上一个卷积层
self.channels = channels # 输出通道数
pad = (self.filter_size - 1) // 2 # 计算pad
if (self.filter_size - 1) % 2 == 0:
self.pad = (pad, pad, pad, pad) else:
self.pad = (pad + 1, pad, pad + 1, pad)
self.avg_pool = nn.AdaptiveAvgPool2D(filter_size) # 通过自适应池化产生filter的权重
self.filter_gen_conv = nn.Conv2D(in_channels, channels, 1)
self.input_redu_conv = layers.ConvBNReLU(in_channels, channels, 1) # 1x1的卷积减少特征图通道
self.norm = layers.SyncBatchNorm(channels)
self.act = nn.ReLU() if self.fusion:
self.fusion_conv = layers.ConvBNReLU(channels, channels, 1) def forward(self, x):
generated_filter = self.filter_gen_conv(
self.avg_pool(x)) # 分支二:生成滤波器权重
x = self.input_redu_conv(x) # 分支一:减少特征图通道
b, c, h, w = x.shape
x = x.reshape([1, b * c, h, w])
generated_filter = generated_filter.reshape(
[b * c, 1, self.filter_size, self.filter_size])
x = F.pad(x, self.pad, mode='constant', value=0)
output = F.conv2d(x, weight=generated_filter, groups=b * c) # 深度可分离卷积
output = output.reshape([b, self.channels, h, w])
output = self.norm(output)
output = self.act(output) if self.fusion:
output = self.fusion_conv(output) return output# step 1: 解压数据%cd ~/data/data64550 !tar -xf cityscapes.tar %cd ~/
# step 2: 模型训练%cd ~/DMNet_paddle/ !python train.py --config configs/dmnet/dmnet_cityscapes_1024x512_100k.yml --num_workers 4 --do_eval --use_vdl --log_iter 20 --save_interval 2000
# step 3: 模型验证--此处给出了在Tesla V100 * 4环境下训练出的模型权重%cd ~/DMNet_paddle/ !python val.py --config configs/dmnet/dmnet_cityscapes_1024x512_100k.yml --model_path output/best_model/model.pdparams
本次论文复现赛要求是Cityscapes 验证集mIOU达到79.64%,本次复现的结果为mIOU 79.67%。
环境:
paddlepaddle==2.2.0
Tesla v100 * 4
| Model | Backbone | Resolution | Training Iters | mIoU | mIoU (flip) | mIoU (ms+flip) | Links |
|---|---|---|---|---|---|---|---|
| DMNet | ResNet101_vd | 1024x512 | 80000 | 79.67% | 80.11% | 80.56% | model | log | vdl |
| DMNet | ResNet101_vd | 1024x512 | 80000 | 79.88% | - | - | - |
1、如果复现的精度未达到要求,且差距不大,可以尝试增加训练次数(第一次80k训练精度只有79.35%,后来训练100k达到79.88%达到验收标准,最后PR时再训练80K达到79.67%,miou变化是因为未固定随机数种子);
2、为了tipc方便,最好先验证模型能否正常动转静导出再训练(有些代码在动转静导出时会出错,最好先调试导出功能再训练,节省复现时间);
3、优先使用PaddleSeg框架复现论文,可以节省大量的时间,同时能够再PR时提高效率。
以上就是【第五期论文复现赛-语义分割】DMNet的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 278
278























