通过机器翻译,打破语言隔阂,促进沟通交流,始终是NLP领域倍受关注的应用场景之一。当前,很多时候我们会以来各大厂商的在线翻译能力,翻译一些段落(至少笔者是这样)。不过,基于PaddleHub,我们可以实现自由、不首先本地的文本翻译能力,同时,这种实现方式,也为我们提供了针对自有数据集,形成更能精准匹配业务需求翻译能力的可能。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

那么,我们就先来看看,基于PaddleHub,如何在本地将word文档直接翻译为另一种语言,并且还能保留该word文档的标题层级等格式结构。
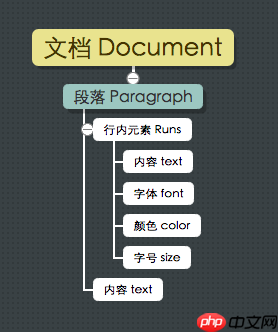
python-docx将整个文章看做是一个Document对象 官方文档 - Document,其基本结构如下:

在python-docx中,run是最基本的单位,每个run对象内的文本样式都是一致的,也就是说,在从docx文件生成文档对象时,python-docx会根据样式的变化来将文本切分为一个个的Run对象。
也可以通过它来处理表格 官方文档 - 表格,基本结构如下:
参考资料:python docx 使用总结
参考官方文档的示例,基于python-docx,我们不需要打开Office软件,也可以用Python写一个完整的word文档,比如:
!pip install python-docx
Looking in indexes: https://mirror.baidu.com/pypi/simple/
Collecting python-docx
Downloading https://mirror.baidu.com/pypi/packages/8b/a0/52729ce4aa026f31b74cc877be1d11e4ddeaa361dc7aebec148171644b33/python-docx-0.8.11.tar.gz (5.6MB)
|████████████████████████████████| 5.6MB 14.9MB/s eta 0:00:01
Collecting lxml>=2.3.2 (from python-docx)
Downloading https://mirror.baidu.com/pypi/packages/cf/4d/6537313bf58fe22b508f08cf3eb86b29b6f9edf68e00454224539421073b/lxml-4.6.3-cp37-cp37m-manylinux1_x86_64.whl (5.5MB)
|████████████████████████████████| 5.5MB 15.6MB/s eta 0:00:01
Building wheels for collected packages: python-docx
Building wheel for python-docx (setup.py) ... done
Created wheel for python-docx: filename=python_docx-0.8.11-cp37-none-any.whl size=184493 sha256=1e95784e743db12bb4c235313b317ef8493520b701e72280d10127fa590a7627
Stored in directory: /home/aistudio/.cache/pip/wheels/dc/ab/e8/a6413f4f5da9cbf373772fa4345e340fc5b7860fd2b7f56ac4
Successfully built python-docx
Installing collected packages: lxml, python-docx
Successfully installed lxml-4.6.3 python-docx-0.8.11from docx import Documentfrom docx.shared import Inches
document = Document()
document.add_heading('Document Title', 0)
p = document.add_paragraph('A plain paragraph having some ')
p.add_run('bold').bold = Truep.add_run(' and some ')
p.add_run('italic.').italic = Truedocument.add_heading('Heading, level 1', level=1)
document.add_paragraph('Intense quote', style='Intense Quote')
document.add_paragraph( 'first item in unordered list', style='List Bullet')
document.add_paragraph( 'first item in ordered list', style='List Number')
document.add_picture('imgs/13523736-c694e2233a8d0bb6.png', width=Inches(1.25))
records = (
(3, '101', 'Spam'),
(7, '422', 'Eggs'),
(4, '631', 'Spam, spam, eggs, and spam')
)
table = document.add_table(rows=1, cols=3)
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'Qty'hdr_cells[1].text = 'Id'hdr_cells[2].text = 'Desc'for qty, id, desc in records:
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = desc
document.add_page_break()
document.save('demo.docx')
在python-docx中,可以对word文档的格式进行解析。本文准备了一个简单的新闻稿word示例,如下所示:
document = Document('新闻稿_带格式.docx')# 查看第1个段落的结构格式print(document.paragraphs[0].style.name)# 查看第1个段落的文本内容print(document.paragraphs[0].text)
Title 网民规模超10亿,国人的数字生活有哪些新生态
# 查看第2个段落的结构格式print(document.paragraphs[1].style.name)# 查看第2个段落的文本内容print(document.paragraphs[1].text)
text_align-justify 截至2021年6月,我国网民规模为10.11亿,互联网普及率达71.6%……8月27日,中国互联网络信息中心(CNNIC)发布第48次《中国互联网络发展状况统计报告》指出,我国超10亿用户接入互联网,形成了全球最为庞大、生机勃勃的数字社会。
# 查看第4个段落的结构格式print(document.paragraphs[3].style.name)# 查看第4个段落的文本内容print(document.paragraphs[3].text)
Heading 1 数字化转型的浪潮已开启
通过下面的方法,将word文档不同段落的结构和内容进行整理。
def get_paragraphs_text(path):
"""
获取所有段落的文本
:param path: word路径
:return: list类型,如:
['Test', 'hello world', ...]
"""
document = Document(path)
all_paragraphs = document.paragraphs
paragraphs_text = [] for paragraph in all_paragraphs: # 拼接一个list,包括段落的结构和内容
paragraphs_text.append([paragraph.style.name,paragraph.text]) return paragraphs_text# 提取文档信息text = get_paragraphs_text('新闻稿_带格式.docx')# 随机查看一个封装后段落的信息text[9]
['text_align-justify', '“短视频、直播正在成为全民新的娱乐方式。”报告指出,截至2021年6月,我国短视频用户规模为8.88亿,占网民整体的87.8%。网络直播用户规模达6.38亿,占网民整体的63.1%。其中,电商直播用户规模为3.84亿,同比增长7524万。']
在PaddleHub中,我们可以便捷地获取PaddlePaddle生态下的预训练模型,完成模型的管理和一键预测。配合使用Fine-tune API,可以基于大规模预训练模型快速完成迁移学习,让预训练模型能更好地服务于特定场景的应用。 PaddleHub目前提供了两种机器翻译的预训练模型,分别是:
import osimport paddlehub as hub
text = get_paragraphs_text('新闻稿_带格式.docx')model = hub.Module(name='transformer_zh-en', beam_size=5)
new_document = Document()for item in text:
src_style = item[0]
src_texts = [item[1]] print('标题层级:', src_style) print(src_texts)
n_best = 1 # 每个输入样本的输出候选句子数量
trg_texts = model.predict(src_texts, n_best=n_best) print(trg_texts) if src_style == 'Title':
new_document.add_heading(trg_texts, 0) elif src_style[:7:] == 'Heading':
new_document.add_heading(trg_texts, level=int(src_style[-1])) else:
new_document.add_paragraph(trg_texts)
new_document.save('translate_news.docx')转换效果:
标题层级: text_align-justify ['身处数字时代的浪潮中,你我的数字生活有哪些新生态?'] ['In the digital age wave, what new ecology do you and I have in digital life?'] 标题层级: Heading 1['数字化转型的浪潮已开启'] ['The tide of digital transformation has started'] 标题层级: text_align-justify ['截至2021年6月,我国网民规模为10.11亿,较2020年12月新增网民2175万,互联网普及率达71.6%。其中,我国手机网民规模为10.07亿,网民中使用手机上网的比例为99.6%。'] ["By June 2021, the number of China's Internet users was 1.011 billion, an increase of 21.75 million since December 2020, and 71.6 percent of the Internet population."]

text = get_paragraphs_text('092016_cfpb_CreditReportingDisputeLetter.docx')model = hub.Module(name='transformer_en-de', beam_size=5)
new_document = Document()for item in text:
src_style = item[0]
src_texts = [item[1]] print('标题层级:', src_style) print(src_texts)
n_best = 1 # 每个输入样本的输出候选句子数量
trg_texts = model.predict(src_texts, n_best=n_best) print(trg_texts) if src_style == 'Title':
new_document.add_heading(trg_texts, 0) elif src_style[:7:] == 'Heading':
new_document.add_heading(trg_texts, level=int(src_style[-1])) else:
new_document.add_paragraph(trg_texts)
new_document.save('translate_en2de.docx')def doc_translate(input_file, output_file, modelname):
# 提取docx文档信息
text = get_paragraphs_text(input_file) # 指定模型
model = hub.Module(name=modelname, beam_size=5) # 准备生成转换后的文档
new_document = Document() for item in text:
src_style = item[0]
src_texts = [item[1]] print('标题层级:', src_style) print(src_texts)
n_best = 1 # 每个输入样本的输出候选句子数量
trg_texts = model.predict(src_texts, n_best=n_best) print(trg_texts) # 匹配转换后文档的标题层级
if src_style == 'Title':
new_document.add_heading(trg_texts, 0) elif src_style[:7:] == 'Heading':
new_document.add_heading(trg_texts, level=int(src_style[-1])) else:
new_document.add_paragraph(trg_texts)
new_document.save(output_file)word_folder = './word'files = os.listdir(word_folder)
for fi in files:
input_file = os.path.join(word_folder,fi)
output_file = os.path.join(word_folder,'translate_' + os.path.basename(input_file))
doc_translate(input_file, output_file, 'transformer_zh-en')从上面的转换结果可以看出,当前Paddlehub上的中文转英文预训练模型还是有提升空间的,比如空行会被翻译为No。不过,这个问题python-docx就可以先做部分处理——当然,治本之策还是需要继续finetune模型。

'''
全局内容替换
请确保要替换的内容样式一致
Args:
doc: 文档对象
old_text: 要被替换的文本
new_text: 要替换成的文本
'''def replace_text(doc, old_text, new_text):
# 遍历每个段落
for p in doc.paragraphs: # 如果要搜索的内容在该段落
if old_text in p.text: # 使用 runs 替换内容但不改变样式
# 注意!runs 会根据样式分隔内容,确保被替换内容的样式一致
for run in p.runs: if old_text in run.text:
run.text = run.text.replace(old_text, new_text)# 导入from docx import Document# 从文件创建文档对象document = Document('./word/translate_赛题介绍.docx')# 显示每段的内容replace_text(document, 'No', '')# 保存清洗后的文档document.save('word/translate_clean_赛题介绍.docx')以上就是PaddleHub机器翻译:文档的批量翻译的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 273
273























