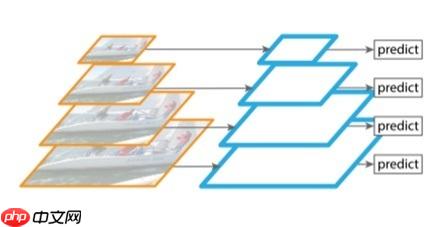
计算机视觉中 cnn backbone 经过多年的发展,沉淀了一些通用的设计模式
最为典型的就是金字塔结构
简单的概括就是:
大致的结构图如下:
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
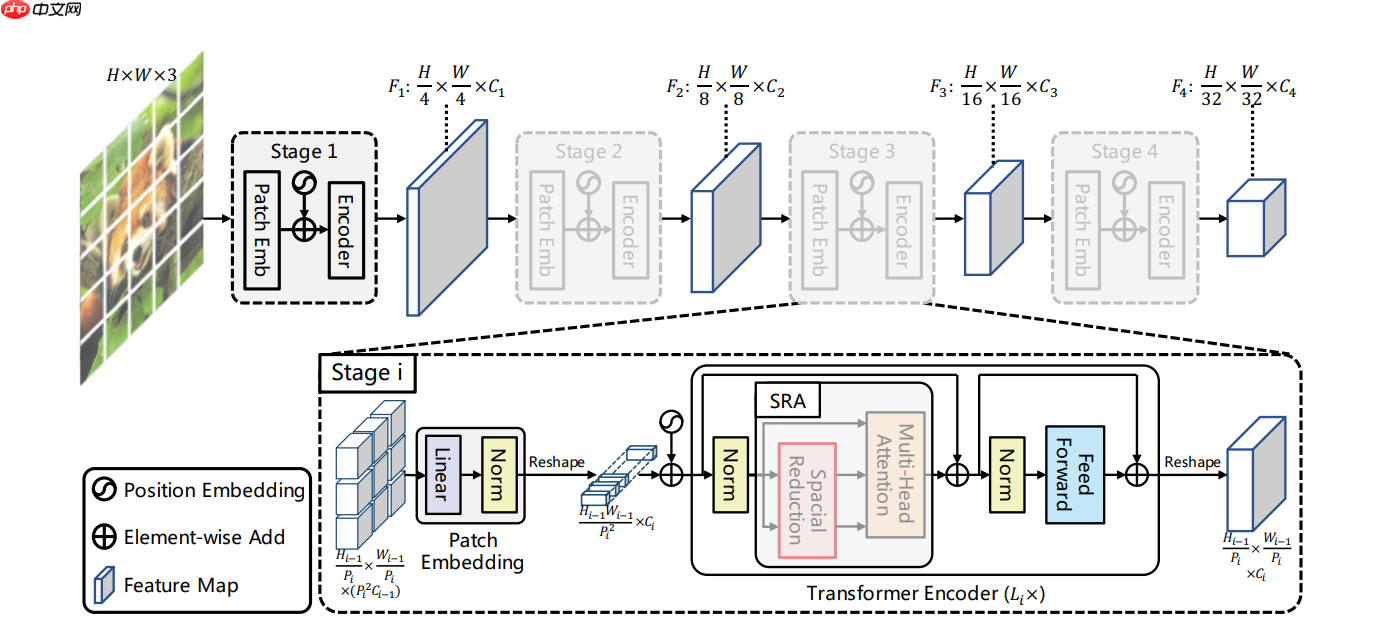
简单概括 PVT 模型的最大改变,就是在每个 Stage 中通过 Patch Embedding 来逐渐降低输入的分辨率
模型结构图如下:

适合品牌专卖店专用,从前台的美工设计就开始强调视觉形象,有助于提升商品的档次,打造网店品牌!后台及程序核心比较简洁,着重在线购物,去掉了繁琐的代码及垃圾程式,在结构上更适合一些中高档的时尚品牌商品展示. 率先引入语言包机制,可在1小时内制作出任何语言版本,程序所有应用文字皆引自LANG目录下的语言包文件,独特的套图更换功能,三级物品分类,购物车帖心设计,在国内率先将购物车与商品显示页面完美结合,完
 0
0

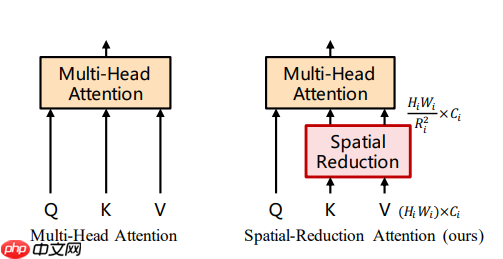
除此之外,为了在保证 feature map 分辨率和全局感受野的同时降低计算量,模型也对 Attention 的方式做了一定的修改
即把 key(K)和 value(V)的长和宽分别缩小到以前的 1/R_i
Attention 的结构图如下:
模型性能精度表如下:
| Model | Model Name | Params (M) | FLOPs (G) | Top-1 (%) | Top-5 (%) |
|---|---|---|---|---|---|
| PVT-Tiny | pvt_ti | 13.2 | 1.9 | 74.96 | 92.47 |
| PVT-Small | pvt_s | 24.5 | 3.8 | 79.87 | 95.05 |
| PVT-Medium | pvt_m | 44.2 | 6.7 | 81.48 | 95.75 |
| PVT-Large | pvt_l | 61.4 | 9.8 | 81.74 | 95.87 |
!pip install ppim==1.0.6
import numpy as npimport paddleimport paddle.nn as nnimport ppim.models.vit as vitfrom ppim.models.vit import trunc_normal_, zeros_, ones_# 修改版 Attentionclass Attention(nn.Layer):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__() assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio if sr_ratio > 1:
self.sr = nn.Conv2D(
dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim) def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape((B, N, self.num_heads, C //
self.num_heads)).transpose((0, 2, 1, 3)) if self.sr_ratio > 1:
x_ = x.transpose((0, 2, 1)).reshape((B, C, H, W))
x_ = self.sr(x_).reshape((B, C, -1)).transpose((0, 2, 1))
x_ = self.norm(x_)
kv = self.kv(x_).reshape((B, -1, 2, self.num_heads, C //
self.num_heads)).transpose((2, 0, 3, 1, 4)) else:
kv = self.kv(x).reshape((B, -1, 2, self.num_heads, C //
self.num_heads)).transpose((2, 0, 3, 1, 4))
k, v = kv[0], kv[1]
attn = (q.matmul(k.transpose((0, 1, 3, 2)))) * self.scale
attn = nn.functional.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((-1, N, C))
x = self.proj(x)
x = self.proj_drop(x) return x# 替换 ViT Block 中的 Attentionclass Block(vit.Block):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, epsilon=1e-6, sr_ratio=1):
super(Block, self).__init__(dim, num_heads, mlp_ratio, qkv_bias, qk_scale, drop,
attn_drop, drop_path, act_layer, norm_layer, epsilon)
self.attn = Attention(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio) def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x))) return x# 向 ViT PatchEmbed 中添加一个 LN 层class PatchEmbed(vit.PatchEmbed):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super(PatchEmbed, self).__init__(
img_size, patch_size, in_chans, embed_dim)
self.norm = nn.LayerNorm(embed_dim) def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x).flatten(2).transpose((0, 2, 1))
x = self.norm(x)
H, W = H // self.patch_size[0], W // self.patch_size[1] return x, (H, W)# 替换 Block 和 Patch Embedded# 每个 Stage 前加入 Patch Embeddedclass PyramidVisionTransformer(nn.Layer):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
epsilon=1e-6, depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], class_dim=1000):
super().__init__()
self.class_dim = class_dim
self.depths = depths # patch_embed
self.patch_embed1 = PatchEmbed(img_size=img_size, patch_size=patch_size, in_chans=in_chans,
embed_dim=embed_dims[0])
self.patch_embed2 = PatchEmbed(img_size=img_size // 4, patch_size=2, in_chans=embed_dims[0],
embed_dim=embed_dims[1])
self.patch_embed3 = PatchEmbed(img_size=img_size // 8, patch_size=2, in_chans=embed_dims[1],
embed_dim=embed_dims[2])
self.patch_embed4 = PatchEmbed(img_size=img_size // 16, patch_size=2, in_chans=embed_dims[2],
embed_dim=embed_dims[3]) # pos_embed
self.pos_embed1 = self.create_parameter(
shape=(1, self.patch_embed1.num_patches, embed_dims[0]), default_initializer=zeros_)
self.add_parameter("pos_embed1", self.pos_embed1)
self.pos_drop1 = nn.Dropout(p=drop_rate)
self.pos_embed2 = self.create_parameter(
shape=(1, self.patch_embed2.num_patches, embed_dims[1]), default_initializer=zeros_)
self.add_parameter("pos_embed2", self.pos_embed2)
self.pos_drop2 = nn.Dropout(p=drop_rate)
self.pos_embed3 = self.create_parameter(
shape=(1, self.patch_embed3.num_patches, embed_dims[2]), default_initializer=zeros_)
self.add_parameter("pos_embed3", self.pos_embed3)
self.pos_drop3 = nn.Dropout(p=drop_rate)
self.pos_embed4 = self.create_parameter(
shape=(1, self.patch_embed4.num_patches + 1, embed_dims[3]), default_initializer=zeros_)
self.add_parameter("pos_embed4", self.pos_embed4)
self.pos_drop4 = nn.Dropout(p=drop_rate) # transformer encoder
dpr = np.linspace(0, drop_path_rate, sum(depths))
cur = 0
self.block1 = nn.LayerList([Block(
dim=embed_dims[0], num_heads=num_heads[0], mlp_ratio=mlp_ratios[0], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur +
i], norm_layer=norm_layer, epsilon=epsilon,
sr_ratio=sr_ratios[0]) for i in range(depths[0])])
cur += depths[0]
self.block2 = nn.LayerList([Block(
dim=embed_dims[1], num_heads=num_heads[1], mlp_ratio=mlp_ratios[1], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur +
i], norm_layer=norm_layer, epsilon=epsilon,
sr_ratio=sr_ratios[1]) for i in range(depths[1])])
cur += depths[1]
self.block3 = nn.LayerList([Block(
dim=embed_dims[2], num_heads=num_heads[2], mlp_ratio=mlp_ratios[2], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur +
i], norm_layer=norm_layer, epsilon=epsilon,
sr_ratio=sr_ratios[2]) for i in range(depths[2])])
cur += depths[2]
self.block4 = nn.LayerList([Block(
dim=embed_dims[3], num_heads=num_heads[3], mlp_ratio=mlp_ratios[3], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur +
i], norm_layer=norm_layer, epsilon=epsilon,
sr_ratio=sr_ratios[3]) for i in range(depths[3])])
self.norm = norm_layer(embed_dims[3]) # cls_token
self.cls_token = self.create_parameter(
shape=(1, 1, embed_dims[3]), default_initializer=zeros_)
self.add_parameter("cls_token", self.cls_token) # classification head
if class_dim > 0:
self.head = nn.Linear(embed_dims[3], class_dim) # init weights
trunc_normal_(self.pos_embed1)
trunc_normal_(self.pos_embed2)
trunc_normal_(self.pos_embed3)
trunc_normal_(self.pos_embed4)
trunc_normal_(self.cls_token)
self.apply(self._init_weights) def reset_drop_path(self, drop_path_rate):
dpr = np.linspace(0, drop_path_rate, sum(self.depths))
cur = 0
for i in range(self.depths[0]):
self.block1[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[0] for i in range(self.depths[1]):
self.block2[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[1] for i in range(self.depths[2]):
self.block3[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[2] for i in range(self.depths[3]):
self.block4[i].drop_path.drop_prob = dpr[cur + i] def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) def forward_features(self, x):
B = x.shape[0] # stage 1
x, (H, W) = self.patch_embed1(x)
x = x + self.pos_embed1
x = self.pos_drop1(x) for blk in self.block1:
x = blk(x, H, W)
x = x.reshape((B, H, W, -1)).transpose((0, 3, 1, 2)) # stage 2
x, (H, W) = self.patch_embed2(x)
x = x + self.pos_embed2
x = self.pos_drop2(x) for blk in self.block2:
x = blk(x, H, W)
x = x.reshape((B, H, W, -1)).transpose((0, 3, 1, 2)) # stage 3
x, (H, W) = self.patch_embed3(x)
x = x + self.pos_embed3
x = self.pos_drop3(x) for blk in self.block3:
x = blk(x, H, W)
x = x.reshape((B, H, W, -1)).transpose((0, 3, 1, 2)) # stage 4
x, (H, W) = self.patch_embed4(x)
cls_tokens = self.cls_token.expand((B, -1, -1))
x = paddle.concat((cls_tokens, x), axis=1)
x = x + self.pos_embed4
x = self.pos_drop4(x) for blk in self.block4:
x = blk(x, H, W)
x = self.norm(x) return x[:, 0] def forward(self, x):
x = self.forward_features(x) if self.class_dim > 0:
x = self.head(x) return xdef pvt_ti(**kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=nn.LayerNorm, depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1], **kwargs) return modeldef pvt_s(**kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=nn.LayerNorm, depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], **kwargs) return modeldef pvt_m(**kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=nn.LayerNorm, depths=[3, 4, 18, 3], sr_ratios=[8, 4, 2, 1], **kwargs) return modeldef pvt_l(**kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=nn.LayerNorm, depths=[3, 8, 27, 3], sr_ratios=[8, 4, 2, 1], **kwargs) return model# 实例化模型model = pvt_ti()# 测试模型前向计算out = model(paddle.randn((1, 3, 224, 224)))# 打印输出形状print(out.shape)
[1, 1000]
# 解压数据集!mkdir ~/data/ILSVRC2012 !tar -xf ~/data/data68594/ILSVRC2012_img_val.tar -C ~/data/ILSVRC2012
import osimport cv2import numpy as npimport paddleimport paddle.vision.transforms as Tfrom ppim import pvt_lfrom PIL import Image# 构建数据集# backend cv2class ILSVRC2012(paddle.io.Dataset):
def __init__(self, root, label_list, transform, backend='pil'):
self.transform = transform
self.root = root
self.label_list = label_list
self.backend = backend
self.load_datas() def load_datas(self):
self.imgs = []
self.labels = [] with open(self.label_list, 'r') as f: for line in f:
img, label = line[:-1].split(' ')
self.imgs.append(os.path.join(self.root, img))
self.labels.append(int(label)) def __getitem__(self, idx):
label = self.labels[idx]
image = self.imgs[idx] if self.backend=='cv2':
image = cv2.imread(image) else:
image = Image.open(image).convert('RGB')
image = self.transform(image) return image.astype('float32'), np.array(label).astype('int64') def __len__(self):
return len(self.imgs)# 配置模型model, val_transforms = pvt_l(pretrained=True)
model = paddle.Model(model)
model.prepare(metrics=paddle.metric.Accuracy(topk=(1, 5)))# 配置数据集val_dataset = ILSVRC2012('data/ILSVRC2012', transform=val_transforms, label_list='data/data68594/val_list.txt')# 模型验证model.evaluate(val_dataset, batch_size=128){'acc_top1': 0.8174, 'acc_top5': 0.95874}以上就是PVT:引入金字塔结构的视觉 Transformer的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 629
629

























