本项目用Paddle2.0rc解决12类猫的分类问题,旨在掌握其图像分类使用方法。数据集含2160张训练图、240张测试图,先解压并加载库,配置参数后划分训练和验证集,定义数据集类,初始化mobilenet_v1模型,配置优化器等,训练10轮,最后评估、测试并保存模型与结果。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜





!unzip -q data/data63045/cat_12_train.zip -d work/ !unzip -q data/data63045/cat_12_test.zip -d work/ !cp data/data63045/train_list.txt work/
import osimport shutilimport numpy as npimport paddlefrom paddle.io import Datasetfrom paddle.vision.datasets import DatasetFolder, ImageFolderfrom paddle.vision.transforms import Compose, Resize, Transpose
'''
参数配置
'''train_parameters = { "class_dim": 12, #分类数
"target_path":"/home/aistudio/work/",
'train_image_dir': '/home/aistudio/work/trainImages', 'eval_image_dir': '/home/aistudio/work/evalImages', 'test_image_dir': '/home/aistudio/work/cat_12_test', 'train_list_path': '/home/aistudio/work/train_list.txt',
}def create_train_eval():
'''
划分训练集和验证集
'''
train_dir = train_parameters['train_image_dir']
eval_dir = train_parameters['eval_image_dir']
train_list_path = train_parameters['train_list_path']
target_path = train_parameters['target_path'] print('creating training and eval images') if not os.path.exists(train_dir):
os.mkdir(train_dir) if not os.path.exists(eval_dir):
os.mkdir(eval_dir)
with open(train_list_path, 'r') as f:
data = f.readlines() for i in range(len(data)):
img_path = data[i].split('\t')[0]
class_label = data[i].split('\t')[1][:-1] if i % 8 == 0: # 每8张图片取一个做验证数据
eval_target_dir = os.path.join(eval_dir, str(class_label))
eval_img_path = os.path.join(target_path, img_path) if not os.path.exists(eval_target_dir):
os.mkdir(eval_target_dir)
shutil.copy(eval_img_path, eval_target_dir)
else:
train_target_dir = os.path.join(train_dir, str(class_label))
train_img_path = os.path.join(target_path, img_path)
if not os.path.exists(train_target_dir):
os.mkdir(train_target_dir)
shutil.copy(train_img_path, train_target_dir)
print ('划分训练集和验证集完成!')create_train_eval()
creating training and eval images 划分训练集和验证集完成!
class CatDataset(Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, mode='train'):
"""
步骤二:实现构造函数,定义数据读取方式,划分训练和测试数据集
"""
super(CatDataset, self).__init__()
train_image_dir = train_parameters['train_image_dir']
eval_image_dir = train_parameters['eval_image_dir']
test_image_dir = train_parameters['test_image_dir']
transform_train = Compose([Resize(size=(112,112)), Transpose()])
transform_eval = Compose([Resize(size=(112,112)), Transpose()])
train_data_folder = DatasetFolder(train_image_dir, transform=transform_train)
eval_data_folder = DatasetFolder(eval_image_dir, transform=transform_eval)
test_data_folder = ImageFolder(test_image_dir, transform=transform_eval)
self.mode = mode if self.mode == 'train':
self.data = train_data_folder elif self.mode == 'eval':
self.data = eval_data_folder elif self.mode == 'test':
self.data = test_data_folder def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
data = np.array(self.data[index][0]).astype('float32') if self.mode == 'test': return data else:
label = np.array([self.data[index][1]]).astype('int64') return data, label def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.data)train_dataset = CatDataset(mode='train') val_dataset = CatDataset(mode='eval') test_dataset = CatDataset(mode='test')
# 使用内置的模型,这边可以选择多种不同网络,这里选了mobilenet_v1网络model = paddle.vision.models.mobilenet_v1(pretrained=True, num_classes=train_parameters["class_dim"]) model = paddle.Model(model)
100%|██████████| 25072/25072 [00:00<00:00, 28070.41it/s]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1175: UserWarning: Skip loading for fc.weight. fc.weight receives a shape [1024, 1000], but the expected shape is [1024, 12].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1175: UserWarning: Skip loading for fc.bias. fc.bias receives a shape [1000], but the expected shape is [12].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))## 查看模型结构model.summary((-1, 3, 224, 224))
---------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
=================================================================================
Conv2D-160 [[1, 3, 224, 224]] [1, 32, 112, 112] 864
BatchNorm2D-107 [[1, 32, 112, 112]] [1, 32, 112, 112] 128
ReLU-88 [[1, 32, 112, 112]] [1, 32, 112, 112] 0
ConvBNLayer-1 [[1, 3, 224, 224]] [1, 32, 112, 112] 0
Conv2D-161 [[1, 32, 112, 112]] [1, 32, 112, 112] 288
BatchNorm2D-108 [[1, 32, 112, 112]] [1, 32, 112, 112] 128
ReLU-89 [[1, 32, 112, 112]] [1, 32, 112, 112] 0
ConvBNLayer-2 [[1, 32, 112, 112]] [1, 32, 112, 112] 0
Conv2D-162 [[1, 32, 112, 112]] [1, 64, 112, 112] 2,048
BatchNorm2D-109 [[1, 64, 112, 112]] [1, 64, 112, 112] 256
ReLU-90 [[1, 64, 112, 112]] [1, 64, 112, 112] 0
ConvBNLayer-3 [[1, 32, 112, 112]] [1, 64, 112, 112] 0
DepthwiseSeparable-1 [[1, 32, 112, 112]] [1, 64, 112, 112] 0
Conv2D-163 [[1, 64, 112, 112]] [1, 64, 56, 56] 576
BatchNorm2D-110 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
ReLU-91 [[1, 64, 56, 56]] [1, 64, 56, 56] 0
ConvBNLayer-4 [[1, 64, 112, 112]] [1, 64, 56, 56] 0
Conv2D-164 [[1, 64, 56, 56]] [1, 128, 56, 56] 8,192
BatchNorm2D-111 [[1, 128, 56, 56]] [1, 128, 56, 56] 512
ReLU-92 [[1, 128, 56, 56]] [1, 128, 56, 56] 0
ConvBNLayer-5 [[1, 64, 56, 56]] [1, 128, 56, 56] 0
DepthwiseSeparable-2 [[1, 64, 112, 112]] [1, 128, 56, 56] 0
Conv2D-165 [[1, 128, 56, 56]] [1, 128, 56, 56] 1,152
BatchNorm2D-112 [[1, 128, 56, 56]] [1, 128, 56, 56] 512
ReLU-93 [[1, 128, 56, 56]] [1, 128, 56, 56] 0
ConvBNLayer-6 [[1, 128, 56, 56]] [1, 128, 56, 56] 0
Conv2D-166 [[1, 128, 56, 56]] [1, 128, 56, 56] 16,384
BatchNorm2D-113 [[1, 128, 56, 56]] [1, 128, 56, 56] 512
ReLU-94 [[1, 128, 56, 56]] [1, 128, 56, 56] 0
ConvBNLayer-7 [[1, 128, 56, 56]] [1, 128, 56, 56] 0
DepthwiseSeparable-3 [[1, 128, 56, 56]] [1, 128, 56, 56] 0
Conv2D-167 [[1, 128, 56, 56]] [1, 128, 28, 28] 1,152
BatchNorm2D-114 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
ReLU-95 [[1, 128, 28, 28]] [1, 128, 28, 28] 0
ConvBNLayer-8 [[1, 128, 56, 56]] [1, 128, 28, 28] 0
Conv2D-168 [[1, 128, 28, 28]] [1, 256, 28, 28] 32,768
BatchNorm2D-115 [[1, 256, 28, 28]] [1, 256, 28, 28] 1,024
ReLU-96 [[1, 256, 28, 28]] [1, 256, 28, 28] 0
ConvBNLayer-9 [[1, 128, 28, 28]] [1, 256, 28, 28] 0
DepthwiseSeparable-4 [[1, 128, 56, 56]] [1, 256, 28, 28] 0
Conv2D-169 [[1, 256, 28, 28]] [1, 256, 28, 28] 2,304
BatchNorm2D-116 [[1, 256, 28, 28]] [1, 256, 28, 28] 1,024
ReLU-97 [[1, 256, 28, 28]] [1, 256, 28, 28] 0
ConvBNLayer-10 [[1, 256, 28, 28]] [1, 256, 28, 28] 0
Conv2D-170 [[1, 256, 28, 28]] [1, 256, 28, 28] 65,536
BatchNorm2D-117 [[1, 256, 28, 28]] [1, 256, 28, 28] 1,024
ReLU-98 [[1, 256, 28, 28]] [1, 256, 28, 28] 0
ConvBNLayer-11 [[1, 256, 28, 28]] [1, 256, 28, 28] 0
DepthwiseSeparable-5 [[1, 256, 28, 28]] [1, 256, 28, 28] 0
Conv2D-171 [[1, 256, 28, 28]] [1, 256, 14, 14] 2,304
BatchNorm2D-118 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
ReLU-99 [[1, 256, 14, 14]] [1, 256, 14, 14] 0
ConvBNLayer-12 [[1, 256, 28, 28]] [1, 256, 14, 14] 0
Conv2D-172 [[1, 256, 14, 14]] [1, 512, 14, 14] 131,072
BatchNorm2D-119 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,048
ReLU-100 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
ConvBNLayer-13 [[1, 256, 14, 14]] [1, 512, 14, 14] 0
DepthwiseSeparable-6 [[1, 256, 28, 28]] [1, 512, 14, 14] 0
Conv2D-173 [[1, 512, 14, 14]] [1, 512, 14, 14] 4,608
BatchNorm2D-120 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,048
ReLU-101 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
ConvBNLayer-14 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
Conv2D-174 [[1, 512, 14, 14]] [1, 512, 14, 14] 262,144
BatchNorm2D-121 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,048
ReLU-102 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
ConvBNLayer-15 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
DepthwiseSeparable-7 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
Conv2D-175 [[1, 512, 14, 14]] [1, 512, 14, 14] 4,608
BatchNorm2D-122 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,048
ReLU-103 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
ConvBNLayer-16 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
Conv2D-176 [[1, 512, 14, 14]] [1, 512, 14, 14] 262,144
BatchNorm2D-123 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,048
ReLU-104 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
ConvBNLayer-17 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
DepthwiseSeparable-8 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
Conv2D-177 [[1, 512, 14, 14]] [1, 512, 14, 14] 4,608
BatchNorm2D-124 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,048
ReLU-105 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
ConvBNLayer-18 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
Conv2D-178 [[1, 512, 14, 14]] [1, 512, 14, 14] 262,144
BatchNorm2D-125 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,048
ReLU-106 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
ConvBNLayer-19 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
DepthwiseSeparable-9 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
Conv2D-179 [[1, 512, 14, 14]] [1, 512, 14, 14] 4,608
BatchNorm2D-126 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,048
ReLU-107 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
ConvBNLayer-20 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
Conv2D-180 [[1, 512, 14, 14]] [1, 512, 14, 14] 262,144
BatchNorm2D-127 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,048
ReLU-108 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
ConvBNLayer-21 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
DepthwiseSeparable-10 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
Conv2D-181 [[1, 512, 14, 14]] [1, 512, 14, 14] 4,608
BatchNorm2D-128 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,048
ReLU-109 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
ConvBNLayer-22 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
Conv2D-182 [[1, 512, 14, 14]] [1, 512, 14, 14] 262,144
BatchNorm2D-129 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,048
ReLU-110 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
ConvBNLayer-23 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
DepthwiseSeparable-11 [[1, 512, 14, 14]] [1, 512, 14, 14] 0
Conv2D-183 [[1, 512, 14, 14]] [1, 512, 7, 7] 4,608
BatchNorm2D-130 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
ReLU-111 [[1, 512, 7, 7]] [1, 512, 7, 7] 0
ConvBNLayer-24 [[1, 512, 14, 14]] [1, 512, 7, 7] 0
Conv2D-184 [[1, 512, 7, 7]] [1, 1024, 7, 7] 524,288
BatchNorm2D-131 [[1, 1024, 7, 7]] [1, 1024, 7, 7] 4,096
ReLU-112 [[1, 1024, 7, 7]] [1, 1024, 7, 7] 0
ConvBNLayer-25 [[1, 512, 7, 7]] [1, 1024, 7, 7] 0
DepthwiseSeparable-12 [[1, 512, 14, 14]] [1, 1024, 7, 7] 0
Conv2D-185 [[1, 1024, 7, 7]] [1, 1024, 7, 7] 9,216
BatchNorm2D-132 [[1, 1024, 7, 7]] [1, 1024, 7, 7] 4,096
ReLU-113 [[1, 1024, 7, 7]] [1, 1024, 7, 7] 0
ConvBNLayer-26 [[1, 1024, 7, 7]] [1, 1024, 7, 7] 0
Conv2D-186 [[1, 1024, 7, 7]] [1, 1024, 7, 7] 1,048,576
BatchNorm2D-133 [[1, 1024, 7, 7]] [1, 1024, 7, 7] 4,096
ReLU-114 [[1, 1024, 7, 7]] [1, 1024, 7, 7] 0
ConvBNLayer-27 [[1, 1024, 7, 7]] [1, 1024, 7, 7] 0
DepthwiseSeparable-13 [[1, 1024, 7, 7]] [1, 1024, 7, 7] 0
AdaptiveAvgPool2D-3 [[1, 1024, 7, 7]] [1, 1024, 1, 1] 0
Linear-3 [[1, 1024]] [1, 12] 12,300
=================================================================================
Total params: 3,241,164
Trainable params: 3,197,388
Non-trainable params: 43,776
---------------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 174.57
Params size (MB): 12.36
Estimated Total Size (MB): 187.51
---------------------------------------------------------------------------------{'total_params': 3241164, 'trainable_params': 3197388}# 调用飞桨框架的VisualDL模块,保存信息到目录中。callback = paddle.callbacks.VisualDL(log_dir='visualdl_log_dir')
model.prepare(optimizer=paddle.optimizer.Adam(
learning_rate=0.001,
parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())model.fit(train_dataset,
val_dataset,
epochs=10,
batch_size=32,
callbacks=callback,
verbose=1)Epoch 1/10
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:637: UserWarning: When training, we now always track global mean and variance. "When training, we now always track global mean and variance.")
step 60/60 [==============================] - loss: 2.2463 - acc: 0.6090 - 294ms/step Eval begin... step 9/9 [==============================] - loss: 0.4193 - acc: 0.6704 - 285ms/step Eval samples: 270 Epoch 2/10 step 60/60 [==============================] - loss: 1.6789 - acc: 0.8571 - 292ms/step Eval begin... step 9/9 [==============================] - loss: 1.3652 - acc: 0.7630 - 280ms/step Eval samples: 270 Epoch 3/10 step 60/60 [==============================] - loss: 2.7546 - acc: 0.9069 - 301ms/step Eval begin... step 9/9 [==============================] - loss: 0.5788 - acc: 0.7704 - 277ms/step Eval samples: 270 Epoch 4/10 step 60/60 [==============================] - loss: 2.8266 - acc: 0.9212 - 294ms/step Eval begin... step 9/9 [==============================] - loss: 1.0253 - acc: 0.7630 - 289ms/step Eval samples: 270 Epoch 5/10 step 60/60 [==============================] - loss: 2.9948 - acc: 0.9111 - 298ms/step Eval begin... step 9/9 [==============================] - loss: 1.0942 - acc: 0.6963 - 279ms/step Eval samples: 270 Epoch 6/10 step 60/60 [==============================] - loss: 0.8608 - acc: 0.9101 - 293ms/step Eval begin... step 9/9 [==============================] - loss: 1.5086 - acc: 0.7444 - 282ms/step Eval samples: 270 Epoch 7/10 step 60/60 [==============================] - loss: 2.5132 - acc: 0.9392 - 296ms/step Eval begin... step 9/9 [==============================] - loss: 1.0570 - acc: 0.7593 - 276ms/step Eval samples: 270 Epoch 8/10 step 60/60 [==============================] - loss: 0.8880 - acc: 0.9508 - 298ms/step Eval begin... step 9/9 [==============================] - loss: 1.3956 - acc: 0.7111 - 285ms/step Eval samples: 270 Epoch 9/10 step 60/60 [==============================] - loss: 0.0301 - acc: 0.9370 - 291ms/step Eval begin... step 9/9 [==============================] - loss: 1.6584 - acc: 0.7333 - 280ms/step Eval samples: 270 Epoch 10/10 step 60/60 [==============================] - loss: 8.0418 - acc: 0.9757 - 294ms/step Eval begin... step 9/9 [==============================] - loss: 0.2750 - acc: 0.7630 - 279ms/step Eval samples: 270
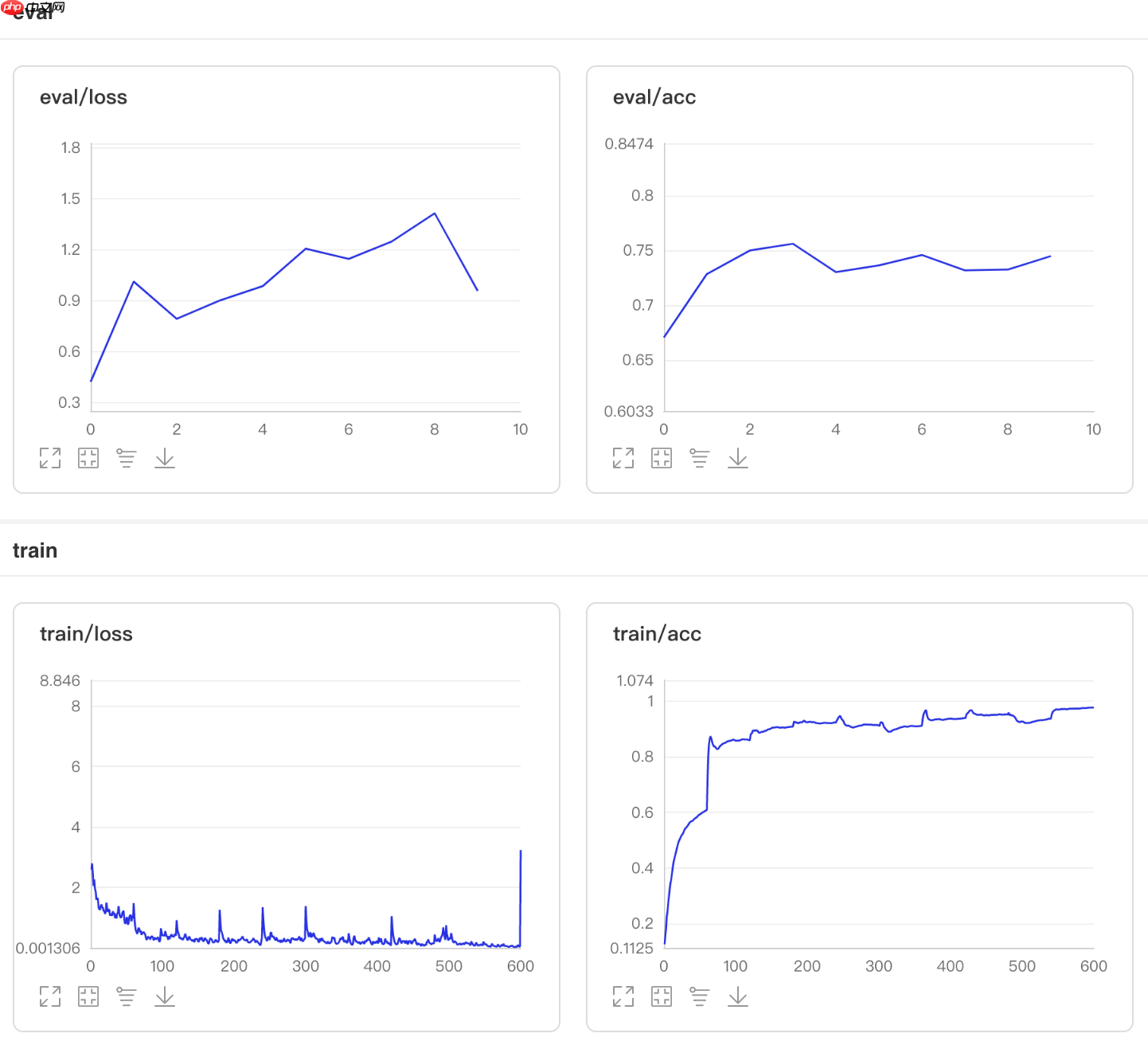
model.evaluate(val_dataset, verbose=1)
Eval begin... step 270/270 [==============================] - loss: 1.6444 - acc: 0.7630 - 16ms/step Eval samples: 270
{'loss': [1.6443943], 'acc': 0.762962962962963}results = model.predict(test_dataset)
Predict begin... step 240/240 [==============================] - 14ms/step Predict samples: 240
labels = []for result in results[0]:
lab = np.argmax(result)
labels.append(lab)test_paths = os.listdir('work/cat_12_test')final_result=[]for i in range(len(labels)):
final_result.append(test_paths[i] + ',' + str(labels[i]) + '\n')with open("work/result.csv","w") as f:
f.writelines(final_result)model.save('work/model') # save for training以上就是基于Paddle2.0的猫12分类的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 465
465























