






本文介绍SegFormer语义分割网络,其有层次化Transformer编码器和轻量全MLP解码器两大创新。编码器生成多尺度特征,解码器融合特征。还说明基于PaddleSeg工具,用SegFormer对遥感影像地块分割进行训练、推理的过程,包括环境与数据准备、代码修改、网络训练和图片推理等步骤。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

项目说明
SegFormer是2021年发布的语义分割网络,成功地在Transformer中引入层次结构,提取不同尺度信息,在语义分割任务中,其精度与速度均不逊于OCRNet,因此发布后广受欢迎
本项目先对SegFormer原始论文的关键内容进行简单摘录,并使用PaddleSeg代码进行辅助,方便对SegFormer网络结构有详细的理解
然后基于PaddleSeg工具,使用SegFormer对常规赛:遥感影像地块分割的影像进行训练、推理
《SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers》
参考链接:
pdf; url; code
管检测:
transformer;语义分割
关键创新点:
- 提出一种 不需要位置编码的、层次化的 transformer 编码器
- 提出一种 轻量级的、全MLP 的解码器,不需要复杂计算与高计算资源,就可以的到有效的特征表达
层次化的Transformer编码器:
SegFormer主要有2个模块:
- 层次化的transformer编码器/MiT,生成不同尺度特征
- 轻量的全MLP解码器,融合不同层级特征
层次化的特征表示
在SegFormer的编码器MiT中,其仿照CNN结构,通过在不同阶段进行下采样,生成多尺度特征。
MiT输入的图像尺寸为 H*W*3, 经过各个阶段的特征处理得到的特征图尺寸为
2i+1H∗2i+1W∗Ci+1,i∈{1,2,3,4}
代码中,各个阶段的下采样层定义如下:
# patch_embed,通过定义卷积操作的步长/stride,时相下采样self.patch_embed1 = OverlapPatchEmbed( img_size=img_size, patch_size=7, # stage1, 大卷积核7*7
stride=4, # stage1, 4倍下采样
in_chans=in_chans, embed_dim=embed_dims[0])self.patch_embed2 = OverlapPatchEmbed( img_size=img_size // 4, patch_size=3, stride=2, # stage2, 2倍下采样
in_chans=embed_dims[0], embed_dim=embed_dims[1])self.patch_embed3 = OverlapPatchEmbed( img_size=img_size // 8, patch_size=3, stride=2, # stage3, 2倍下采样
in_chans=embed_dims[1], embed_dim=embed_dims[2])self.patch_embed4 = OverlapPatchEmbed( img_size=img_size // 16, patch_size=3, stride=2, # stage4, 2倍下采样
in_chans=embed_dims[2], embed_dim=embed_dims[3])
有重叠的patch合并
SegFormer中的patch合并,仿照ViT中的池化方式,将2*2*Ci 的特征变为1*1*Ci+1,具体实现时,使用卷积下采样并进行通道变换,得到1*1*Ci+1。从而实现下采样、通道维数变化。
这一操作的设计初衷,是为了组合非重叠的图像或特征patch,因此不能保持patch周边的局部连续性。【各个patch是不重叠的,不能跨patch进行信息交互】
为了解决这一问题,本文提出重叠patch合并,并定义如下参数:
patch尺寸K、步长S、填充尺寸P,在网络中设置参了2套参数:K = 7, S = 4, P = 3 ;K = 3, S = 2, P = 1【在stage1中使用大尺寸、大步长生成的patch,可以快速压缩空间信息,实现下采样,便于进行特征计算】
代码中,重叠patch合并层定义如下:
class OverlapPatchEmbed(nn.Layer):
def __init__(self, img_size=224,
patch_size=7, # 卷积核大小
stride=4, # 下采样倍数
in_chans=3, # 输入通道数
embed_dim=768): # 输出通道数
super().__init__() img_size = to_2tuple(img_size) patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.H, self.W = img_size[0] // patch_size[0], img_size[ 1] // patch_size[1]
self.num_patches = self.H * self.W # 定义投影变换所用的卷积
self.proj = nn.Conv2D(
in_chans,
embed_dim, kernel_size=patch_size,
stride=stride,
padding=(patch_size[0] // 2, patch_size[1] // 2)) # 定义layer norm层
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x): x = self.proj(x) # 通过卷积进行特征重投影,实现下采样、通道变换
x_shape = paddle.shape(x)
H, W = x_shape[2], x_shape[3] x = x.flatten(2).transpose([0, 2, 1]) # 将H*W维度压缩成1个维度
x = self.norm(x) # 标准化
return x, H, W
高效的自关注机制
编码器部分的主要计算消耗在于 自关注层/self-attention。
原在始的自关注过程中,Q、K、C的维度均为N*C,N=H*W,自关注原始计算如下:
Attention(Q,K,V)=Softmax(dheadQKT)V
而该公式的计算复杂度为O(N2),计算消耗高,且与图像尺寸相关,因此不适用于高分辨率图像。
本文提出一种改进方式,在计算attention时,参考CNN中的处理,使用下采样率R对K进行处理,改进的计算过程如下:

K=Reshape(RN,C⋅R)(K)
K′=Linear(C⋅R,C)(K)
其中,K是输入的映射特征,K是K维度变换后的特征,K'是降维后的特征。
【通过将K进行reshape将空间维度N的信息转移到通道维度C上,可以得到K;然后通过定义的线性变换层将通道为降到原始维度C上,得到K',实现空间下采样。】
通过上述操作计算复杂度降到O(N2/ R),大大降低了计算复杂度,在SegFormer中中,将各阶段的设置R为[64, 16, 4, 1]
代码中,改进后的Attention定义如下:
class Attention(nn.Layer):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim**-0.5
self.dim = dim
# 定义q映射
self.q = nn.Linear(dim, dim, bias_attr=qkv_bias)
# 定义kv映射
self.kv = nn.Linear(dim, dim * 2, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
# 定义输入特征的残差映射
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2D(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
def forward(self, x, H, W):
x_shape = paddle.shape(x) B, N = x_shape[0], x_shape[1] C = self.dim
# 输入特征通过映射得到q
q = self.q(x).reshape([B, N, self.num_heads,C // self.num_heads]).transpose([0, 2, 1, 3])
# 输入特征通过映射得到k v
if self.sr_ratio > 1:
x_ = x.transpose([0, 2, 1]).reshape([B, C, H, W])
x_ = self.sr(x_).reshape([B, C, -1]).transpose([0, 2, 1]) # 下采样
x_ = self.norm(x_)
kv = self.kv(x_).reshape([B, -1, 2, self.num_heads,C // self.num_heads]).transpose([2, 0, 3, 1, 4])
else:
kv = self.kv(x).reshape([B, -1, 2, self.num_heads,C // self.num_heads]).transpose([2, 0, 3, 1, 4])
k, v = kv[0], kv[1]
# att计算,q*k/sqrt(d)
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
# att权重与x融合
x = (attn @ v).transpose([0, 2, 1, 3]).reshape([B, N, C])
# 关注后处理
x = self.proj(x)
x = self.proj_drop(x)
return x
Mix-FFN
ViT使用位置编码引入位置信息,但由于在测试时的分辨率发生变化时,会引起精度下降的问题。
本文任务位置信息在语义分割中不是必需的,因此提出Mix-FFN:直接使用3*3卷积对输入特征进行处理,并考虑了用0进行填充导致的局部信息泄漏。计算过程如下:
xout=MLP(GELU(Conv3∗3(MLP(xin))))+xin
其中xin是自关注模块生成的结果,Mix-FNN混合了3*3卷积与MLP,并进一步使用了深度分离卷积减少参数量、提高效率
代码中,Mix-FNN定义如下:
class Mlp(nn.Layer):
def __init__(self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.GELU,
drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop) def forward(self, x, H, W):
x = self.fc1(x) # 线性变换/MLP
x = self.dwconv(x, H, W) # 卷积/Conv3*3
x = self.act(x) # GELU
x = self.drop(x)
x = self.fc2(x) # 线性变换/MLP
x = self.drop(x) return x
Lightweight All-MLP Decoder:
在解码器部分,SegFormer采用了简单的结构,仅由MLP组成,减少了手动设计、计算需求高等问题,主要包括4步:
- 对多尺度特征进行通道维度变换,统一维度:通过MLP进行维度变换
- 对多尺度特征进行空间维度变换,统一尺寸:通过插值上采样进行尺寸变换
- 特征拼接与通道压缩:通过MLP进行通道压缩
- 分类预测:1*1卷积
class SegFormer(nn.Layer):
def __init__(self,
num_classes,
backbone,
embedding_dim, align_corners=False,
pretrained=None):
super(SegFormer, self).__init__()
self.pretrained = pretrained
self.align_corners = align_corners
self.backbone = backbone
self.num_classes = num_classes
c1_in_channels, c2_in_channels, c3_in_channels, c4_in_channels = self.backbone.feat_channels
self.linear_c4 = MLP(input_dim=c4_in_channels, embed_dim=embedding_dim)
self.linear_c3 = MLP(input_dim=c3_in_channels, embed_dim=embedding_dim)
self.linear_c2 = MLP(input_dim=c2_in_channels, embed_dim=embedding_dim)
self.linear_c1 = MLP(input_dim=c1_in_channels, embed_dim=embedding_dim)
self.dropout = nn.Dropout2D(0.1)
self.linear_fuse = layers.ConvBNReLU( in_channels=embedding_dim * 4, out_channels=embedding_dim,
kernel_size=1,
bias_attr=False)
self.linear_pred = nn.Conv2D(
embedding_dim, self.num_classes, kernel_size=1)
def forward(self, x): feats = self.backbone(x)
c1, c2, c3, c4 = feats ############## MLP decoder on C1-C4 ###########
c1_shape = paddle.shape(c1) c2_shape = paddle.shape(c2) c3_shape = paddle.shape(c3) c4_shape = paddle.shape(c4)
# 统一stage4的维度、尺寸
_c4 = self.linear_c4(c4).transpose([0, 2, 1]).reshape([0, 0, c4_shape[2], c4_shape[3]]) _c4 = F.interpolate(
_c4, size=c1_shape[2:],
mode='bilinear',
align_corners=self.align_corners)
# 统一stage3的维度、尺寸
_c3 = self.linear_c3(c3).transpose([0, 2, 1]).reshape([0, 0, c3_shape[2], c3_shape[3]]) _c3 = F.interpolate(
_c3, size=c1_shape[2:],
mode='bilinear',
align_corners=self.align_corners)
# 统一stage2的维度、尺寸
_c2 = self.linear_c2(c2).transpose([0, 2, 1]).reshape([0, 0, c2_shape[2], c2_shape[3]]) _c2 = F.interpolate(
_c2, size=c1_shape[2:],
mode='bilinear',
align_corners=self.align_corners)
# 统一stage1维度、尺寸
_c1 = self.linear_c1(c1).transpose([0, 2, 1]).reshape(
[0, 0, c1_shape[2], c1_shape[3]])
# 特征拼接与通道压缩
_c = self.linear_fuse(paddle.concat([_c4, _c3, _c2, _c1], axis=1))
logit = self.dropout(_c)
#分类预测
logit = self.linear_pred(logit)
return [
F.interpolate(
logit, size=paddle.shape(x)[2:],
mode='bilinear',
align_corners=self.align_corners)
]
Effective Receptive Field Analysis
语义分割任务中,保持大感受野是关键,本文分析了不同阶段的感受野,如下图:
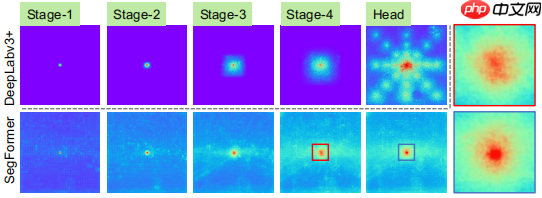
在stage4阶段,DeepLabV3+的感受野小于SegFormer
SegFormer的编码器,在浅层阶段,可以产生类似于卷积一样的局部关注,并输出非局部关注,从而有效捕获stage4的上下文信息
在上采样阶段,Head的感受野除了具有非局部关注外,还有较强的局部关注。
Experiments
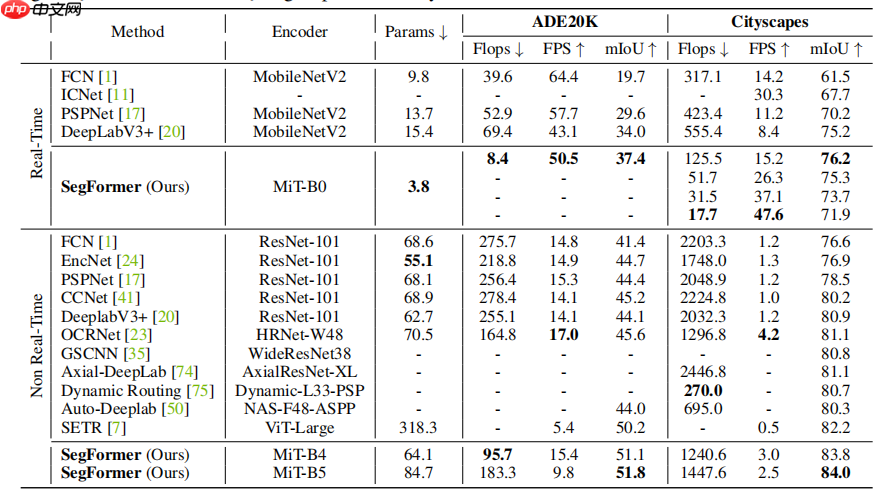
上图是SegFormer在ADE20K、Cityscapes数据集上与不同模型的参数量、精度。
SegFormer B4的Cityscapes miou精度已达到84%,属于SOTA水准,大于OCRNet HRNet48的81.1
【conclusion】
之前的语义分割中常用OCRNet48,虽然精度很高,但由于多尺度、多阶段的特征处理结构,计算速度慢、网络收敛慢。
在使用了SegFormer b3后,发现其与OCRNet48精度相差无几,并且显存占用相对较少、收敛快,在相同时间、显存下,可以加大batchsize与epoch。对于数据量较多,或者对推理速度有限制的应用情境下,SegFormer 是更优选择。
虽然SegFormer在语义冯上的表现已足够优秀,编码器MiT成功借鉴了CNN的层次结构应用在transformer中,但解码器较为简单,仍然存在提高的空间。
在PaddleSeg中使用ConvNeXt进行特征提取实现语义分割
环境准备
# pip升级!pip install --user --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple# 下载仓库,并切换到2.4版本%cd /home/aistudio/ !git clone https://gitee.com/paddlepaddle/PaddleSeg.git #该行仅在初次运行项目时运行即可,后续不需要运行改行命令%cd /home/aistudio/PaddleSeg !git checkout -b release/2.4 origin/release/2.4# 安装依赖!pip install -r requirements.txt
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple Requirement already satisfied: pip in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (22.0.4) /home/aistudio fatal: 目标路径 'PaddleSeg' 已经存在,并且不是一个空目录。 /home/aistudio/PaddleSeg fatal: 一个分支名 'release/2.4' 已经存在。 Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple Requirement already satisfied: pre-commit in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from -r requirements.txt (line 1)) (1.21.0) Requirement already satisfied: yapf==0.26.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from -r requirements.txt (line 2)) (0.26.0) Requirement already satisfied: flake8 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from -r requirements.txt (line 3)) (4.0.1) Requirement already satisfied: pyyaml>=5.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from -r requirements.txt (line 4)) (5.1.2) Requirement already satisfied: visualdl>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from -r requirements.txt (line 5)) (2.2.3) Requirement already satisfied: opencv-python in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from -r requirements.txt (line 6)) (4.1.1.26) Requirement already satisfied: tqdm in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from -r requirements.txt (line 7)) (4.27.0) Requirement already satisfied: filelock in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from -r requirements.txt (line 8)) (3.0.12) Requirement already satisfied: scipy in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from -r requirements.txt (line 9)) (1.6.3) Requirement already satisfied: prettytable in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from -r requirements.txt (line 10)) (0.7.2) Requirement already satisfied: sklearn in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from -r requirements.txt (line 11)) (0.0) Requirement already satisfied: six in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->-r requirements.txt (line 1)) (1.16.0) Requirement already satisfied: cfgv>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->-r requirements.txt (line 1)) (2.0.1) Requirement already satisfied: nodeenv>=0.11.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->-r requirements.txt (line 1)) (1.3.4) Requirement already satisfied: aspy.yaml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->-r requirements.txt (line 1)) (1.3.0) Requirement already satisfied: virtualenv>=15.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->-r requirements.txt (line 1)) (16.7.9) Requirement already satisfied: toml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->-r requirements.txt (line 1)) (0.10.0) Requirement already satisfied: identify>=1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->-r requirements.txt (line 1)) (1.4.10) Requirement already satisfied: importlib-metadata in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->-r requirements.txt (line 1)) (4.2.0) Requirement already satisfied: pyflakes<2.5.0,>=2.4.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8->-r requirements.txt (line 3)) (2.4.0) Requirement already satisfied: pycodestyle<2.9.0,>=2.8.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8->-r requirements.txt (line 3)) (2.8.0) Requirement already satisfied: mccabe<0.7.0,>=0.6.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8->-r requirements.txt (line 3)) (0.6.1) Requirement already satisfied: flask>=1.1.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.0.0->-r requirements.txt (line 5)) (1.1.1) Requirement already satisfied: numpy in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.0.0->-r requirements.txt (line 5)) (1.19.5) Requirement already satisfied: protobuf>=3.11.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.0.0->-r requirements.txt (line 5)) (3.14.0) Requirement already satisfied: pandas in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.0.0->-r requirements.txt (line 5)) (1.1.5) Requirement already satisfied: requests in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.0.0->-r requirements.txt (line 5)) (2.24.0) Requirement already satisfied: matplotlib in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.0.0->-r requirements.txt (line 5)) (2.2.3) Requirement already satisfied: bce-python-sdk in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.0.0->-r requirements.txt (line 5)) (0.8.53) Requirement already satisfied: shellcheck-py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.0.0->-r requirements.txt (line 5)) (0.7.1.1) Requirement already satisfied: Pillow>=7.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.0.0->-r requirements.txt (line 5)) (8.2.0) Requirement already satisfied: Flask-Babel>=1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.0.0->-r requirements.txt (line 5)) (1.0.0) Requirement already satisfied: scikit-learn in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from sklearn->-r requirements.txt (line 11)) (0.24.2) Requirement already satisfied: Werkzeug>=0.15 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl>=2.0.0->-r requirements.txt (line 5)) (0.16.0) Requirement already satisfied: itsdangerous>=0.24 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl>=2.0.0->-r requirements.txt (line 5)) (1.1.0) Requirement already satisfied: Jinja2>=2.10.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl>=2.0.0->-r requirements.txt (line 5)) (3.0.0) Requirement already satisfied: click>=5.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl>=2.0.0->-r requirements.txt (line 5)) (7.0) Requirement already satisfied: Babel>=2.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl>=2.0.0->-r requirements.txt (line 5)) (2.9.1) Requirement already satisfied: pytz in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl>=2.0.0->-r requirements.txt (line 5)) (2022.1) Requirement already satisfied: zipp>=0.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from importlib-metadata->pre-commit->-r requirements.txt (line 1)) (3.7.0) Requirement already satisfied: typing-extensions>=3.6.4 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from importlib-metadata->pre-commit->-r requirements.txt (line 1)) (4.1.1) Requirement already satisfied: pycryptodome>=3.8.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bce-python-sdk->visualdl>=2.0.0->-r requirements.txt (line 5)) (3.9.9) Requirement already satisfied: future>=0.6.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bce-python-sdk->visualdl>=2.0.0->-r requirements.txt (line 5)) (0.18.0) Requirement already satisfied: python-dateutil>=2.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->visualdl>=2.0.0->-r requirements.txt (line 5)) (2.8.2) Requirement already satisfied: kiwisolver>=1.0.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->visualdl>=2.0.0->-r requirements.txt (line 5)) (1.1.0) Requirement already satisfied: cycler>=0.10 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->visualdl>=2.0.0->-r requirements.txt (line 5)) (0.10.0) Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->visualdl>=2.0.0->-r requirements.txt (line 5)) (3.0.7) Requirement already satisfied: chardet<4,>=3.0.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl>=2.0.0->-r requirements.txt (line 5)) (3.0.4) Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl>=2.0.0->-r requirements.txt (line 5)) (1.25.11) Requirement already satisfied: certifi>=2017.4.17 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl>=2.0.0->-r requirements.txt (line 5)) (2021.10.8) Requirement already satisfied: idna<3,>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl>=2.0.0->-r requirements.txt (line 5)) (2.10) Requirement already satisfied: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn->sklearn->-r requirements.txt (line 11)) (0.14.1) Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn->sklearn->-r requirements.txt (line 11)) (2.1.0) Requirement already satisfied: MarkupSafe>=2.0.0rc2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Jinja2>=2.10.1->flask>=1.1.1->visualdl>=2.0.0->-r requirements.txt (line 5)) (2.0.1) Requirement already satisfied: setuptools in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from kiwisolver>=1.0.1->matplotlib->visualdl>=2.0.0->-r requirements.txt (line 5)) (56.2.0)
数据准备
# 耗时约35秒!unzip -oq /home/aistudio/data/data77571/train_and_label.zip -d /home/aistudio/data/src/ !unzip -oq /home/aistudio/data/data77571/img_test.zip -d /home/aistudio/data/src/
# 生产数据集划分txt# 演示时使用比例0.98:0.02!python /home/aistudio/work/segmentation/data_split.py \ 0.98 0.02 0 \
/home/aistudio/data/src/img_train \
/home/aistudio/data/src/lab_train# # 实践时使用比例0.2:0.2# !python /home/aistudio/work/segmentation/data_split.py \# 0.8 0.2 0 \# /home/aistudio/data/src/img_train \# /home/aistudio/data/src/lab_train
代码准备
# 修改文件!cp /home/aistudio/work/segmentation/segformerb3.yml /home/aistudio/PaddleSeg/segformerb3.yml !cp /home/aistudio/work/segmentation/utils.py /home/aistudio/PaddleSeg/paddleseg/utils/utils.py # 加载tif数据与模型参数!cp /home/aistudio/work/segmentation/predict.py /home/aistudio/PaddleSeg/paddleseg/core/predict.py # 预测类别结果保存!cp /home/aistudio/work/segmentation/transformer_utils.py /home/aistudio/PaddleSeg/paddleseg/models/backbones/transformer_utils.py # 修复数据类型bug
网络训练
# 演示时使用的训练超参数,约5分钟!python /home/aistudio/PaddleSeg/train.py \
--config /home/aistudio/PaddleSeg/segformerb3.yml \
--save_dir /home/aistudio/data/output_seg \
--do_eval \
--use_vdl \
--batch_size 32 \
--iters 100 \
--save_interval 50 \
--log_iters 10 \
--fp16
# # 实践时使用的训练超参数,约20+小时# !python /home/aistudio/PaddleSeg/train.py \# --config /home/aistudio/PaddleSeg/segformerb3.yml \# --save_dir /home/aistudio/data/output_seg \# --do_eval \# --use_vdl \# --batch_size 32 \# --iters 100000 \# --save_interval 2100 \# --log_iters 100 \# --fp16
# 将训练参数转移到best_model/seg下!mkdir /home/aistudio/best_model !mkdir /home/aistudio/best_model/seg !cp /home/aistudio/data/output_seg/best_model/model.pdparams /home/aistudio/best_model/seg/model.pdparams
mkdir: 无法创建目录"/home/aistudio/best_model/seg": 没有那个文件或目录 cp: 无法获取'/home/aistudio/data/output_seg/best_model/model.pdparams' 的文件状态(stat): 没有那个文件或目录
图片推理
# 结果保存在/home/aistudio/data/infer_seg下!python /home/aistudio/PaddleSeg/predict.py \
--config /home/aistudio/PaddleSeg/segformerb3.yml \
--model_path /home/aistudio/best_model/seg/model.pdparams \
--image_path /home/aistudio/data/src/img_testA \
--save_dir /home/aistudio/data/infer_seg
预测结果/训练5分钟






























