人工智能技术的应用领域日趋广泛,新的智能应用层出不穷。本项目将利用人工智能技术来对蝴蝶图像进行分类,需要能对蝴蝶的类别、属性进行细粒度的识别分类。相关研究工作者能够根据采集到的蝴蝶图片,快速识别图中蝴蝶的种类。期望能够有助于提升蝴蝶识别工作的效率和精度。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

数据集都来源于网络公开数据(和鲸社区)。图片中所涉及的蝴蝶总共有9个属,20个物种,文件genus.txt中描述了9个属名,species.txt描述了20个物种名。
在创建项目时,可以为该项目挂载Butterfly20蝴蝶数据集,即便项目重启,该挂载的数据集也不会被自动清除。具体方法如下:首先采用notebook方式构建项目,项目创建框中的最下方有个数据集选项,选择“+添加数据集”。然后,弹出搜索框,在关键词栏目输入“bufferfly20”,便能够查询到该数据集。最后,选中该数据集,可以自动在项目中挂载该数据集了。
需要注意的是,每次重新打开该项目,data文件夹下除了挂载的数据集,其他文件都将被删除。
被挂载的数据集会自动出现在data目录之下,通常是压缩包的形式。在data/data63004目录,其中有两个压缩文件,分别是Butterfly20.zip和Butterfly20_test.zip。也可以利用下载功能把数据集下载到本地进行训练。
我们看看蝴蝶图像数据长什么样子?
首先,解压缩数据。类以下几个步骤:
第一步,把当前路径转换到data目录,可以使用命令!cd data。在AI studio nootbook中可以使用Linux命令,需要在命令的最前面加上英文的感叹号(!)。用&&可以连接两个命令。用\号可以换行写代码。需要注意的是,每次重新打开该项目,data文件夹下除了挂载的数据集,其他文件都会被清空。因此,如果把数据保存在data目录中,每次重新启动项目时,都需要解压缩一下。如果想省事持久化保存,可以把数据保存在work目录下。
实际上,!加某命令的模式,等价于python中的get_ipython().system('某命令')模式。
第二步,利用unzip命令,把压缩包解压到当前路径。unzip的-q参数代表执行时不显示任何信息。unzip的-o参数代表不必先询问用户,unzip执行后覆盖原有的文件。两个参数合起来,可以写为-qo。
第三步,用rm命令可以把一些文件夹给删掉,比如,__MACOSX文件夹
飞桨领航团图像分类零基础训练营 满分作业

!cd data &&\ unzip -qo data73998/Butterfly20_test.zip &&\ unzip -qo data73998/Butterfly20.zip &&\ rm -r __MACOSX
接着,我们分析一下数据集,发现Butterfly20文件夹中有很多子文件夹,每个子文件夹下又有很多图片,每个子文件夹的名字都是蝴蝶属种的名字。由此,可以推测每个文件夹下是样本,而样本的标签就是子文件夹的名字。
我们绘制data/Butterfly20/001.Atrophaneura_horishanus文件夹下的图片006.jpg。根据百度百科,Atrophaneura horishanus是凤蝶科、曙凤蝶属的一个物种。
我们再绘制data/Butterfly20/002.Atrophaneura_varuna文件夹下的图片006.jpg。根据百度百科,Atrophaneura varuna对应的中文名称是“瓦曙凤蝶”,它是凤蝶科、曙凤蝶属的另一个物种。
虽然乍一看蝴蝶都是相似的,但不同属种的蝴蝶在形状、颜色等细节方面还是存在很大的差别。
import paddleimport matplotlib.pyplot as pltimport PIL.Image as Imageimport numpy as npimport matplotlib.pyplot as plt
import cv2import os
import globimport randomimport timeimport pandas as pdprint(f'Welcome to paddle {paddle.__version__} zoo,\n there are many butterflies here today,\n please enjoy the good time with us!' )/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import MutableMapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Iterable, Mapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Sized
Welcome to paddle 2.0.1 zoo, there are many butterflies here today, please enjoy the good time with us!
but_files = np.array(glob("/data/images/*/*/*")) print number of images in each datasetprint('There are %d total dog images.' % len(but_files))data_path='/home/aistudio/data/Butterfly20/*/*.jpg'test_path='/home/aistudio/data/Butterfly20_test/*.jpg'but_files =glob.glob(data_path)
test_files =glob.glob(test_path)print(f'训练集样品数量为:{len(but_files)}个\n 测试集样品数量为:{len(test_files)}个')训练集样品数量为:1866个 测试集样品数量为:200个
任何时候都要记得欣赏风景,虽然我们要赶着做作业
本关的挑战是蝴蝶分类,即便属于同一属种,不同的蝴蝶图片在角度、明暗、背景、姿态、颜色等方面均存在不小差别。甚至有的图片里面有多只蝴蝶。
index=random.choice(but_files)
index20 =random.sample(but_files,20)
plt.figure(figsize=(12,12),dpi=100)for i in range(20):
img = Image.open(index20[i])
name=index20[i].split('/')[-2]
plt.subplot(4, 5, i + 1)
plt.imshow(img, 'gray')
plt.title(name, fontsize=8)
plt.xticks([]), plt.yticks([])
plt.tight_layout()/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working if isinstance(obj, collections.Iterator): /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return list(data) if isinstance(data, collections.MappingView) else data
<Figure size 1200x1200 with 20 Axes>
#随机显示一个样品的图片index=random.choice(but_files)print(index)
name=index.split('/')[-2]
img = Image.open(index)
img =cv2.imread(index)print(img.shape)
img =img[:,:,::-1]print(f'该样本标签为:{name}')
plt.figure(figsize=(8,10),dpi=50)
plt.axis('off')
plt.imshow(img) #根据数组绘制图像/home/aistudio/data/Butterfly20/015.Pachliopta_aristolochiae/171.jpg (505, 600, 3) 该样本标签为:015.Pachliopta_aristolochiae
<matplotlib.image.AxesImage at 0x7f47a31a9fd0>
<Figure size 400x500 with 1 Axes>
def enlarge(img):
h,w,_=img.shape
ty=(600-h)//2
tx=(600-w)//2
# 定义平移矩阵,需要是numpy的float32类型
# x轴平移200,y轴平移500
M = np.float32([[1, 0, tx], [0, 1, ty]]) # 用仿射变换实现平移
dst = cv2.warpAffine(img, M, (600, 600))
dst = dst[100:501,100:501,:] return dst
index=random.choice(but_files)#index=but_files[1]print(index)
name=index.split('/')[-2]
img = Image.open(index)
img =cv2.imread(index)print(img.shape)
img =img[:,:,::-1]
imgl=enlarge(img)print(imgl.shape)print(f'该样本标签为:{name}')# plt.figure(figsize=(8,10),dpi=50)# plt.axis('off')# plt.imshow(img) plt.figure(figsize=(12,12))#显示各通道信息plt.subplot(121)
plt.imshow(img,'gray')
plt.title('RGB_Image')
plt.subplot(122)
plt.imshow(imgl,'gray')/home/aistudio/data/Butterfly20/016.Papilio_alcmenor/032.jpg (416, 600, 3) (401, 401, 3) 该样本标签为:016.Papilio_alcmenor
<matplotlib.image.AxesImage at 0x7f47a3154090>
<Figure size 864x864 with 2 Axes>
数据准备过程包括以下两个重点步骤:
一是建立样本数据读取路径与样本标签之间的关系。
二是构造读取器与数据预处理。可以写个自定义数据读取器,它继承于PaddlePaddle2.0的dataset类,在__getitem__方法中把自定义的预处理方法加载进去。
data_list = [] #用个列表保存每个样本的读取路径、标签#由于属种名称本身是字符串,而输入模型的是数字。需要构造一个字典,把某个数字代表该属种名称。键是属种名称,值是整数。label_list=[]with open("/home/aistudio/data/species.txt") as f: for line in f:
a,b = line.strip("\n").split(" ")
label_list.append([b, int(a)-1])
label_dic = dict(label_list)for i in label_dic: print(i)001.Atrophaneura_horishanus 002.Atrophaneura_varuna 003.Byasa_alcinous 004.Byasa_dasarada 005.Byasa_polyeuctes 006.Graphium_agamemnon 007.Graphium_cloanthus 008.Graphium_sarpedon 009.Iphiclides_podalirius 010.Lamproptera_curius 011.Lamproptera_meges 012.Losaria_coon 013.Meandrusa_payeni 014.Meandrusa_sciron 015.Pachliopta_aristolochiae 016.Papilio_alcmenor 017.Papilio_arcturus 018.Papilio_bianor 019.Papilio_dialis 020.Papilio_hermosanus
df = pd.DataFrame(but_files,columns=['filepath']) #生成数据框。df['name'] = df.filepath.apply(lambda x:x.split('/')[-2]) #按要求产生相对路径。只要工作目录下的相对路径 。df['label']=df.name.map(label_dic) #用映射生成标签 df['shape']=df.filepath.apply(lambda x:cv2.imread(x).shape) #数据形状 df['height']=df['shape'].apply(lambda x:x[0])
df['width']=df['shape'].apply(lambda x:x[1])df_dataset=df[['filepath','label']] dataset=np.array(df_dataset).tolist()
dataset[:10]
[['/home/aistudio/data/Butterfly20/009.Iphiclides_podalirius/061.jpg', 8], ['/home/aistudio/data/Butterfly20/009.Iphiclides_podalirius/200.jpg', 8], ['/home/aistudio/data/Butterfly20/009.Iphiclides_podalirius/048.jpg', 8], ['/home/aistudio/data/Butterfly20/009.Iphiclides_podalirius/134.jpg', 8], ['/home/aistudio/data/Butterfly20/009.Iphiclides_podalirius/163.jpg', 8], ['/home/aistudio/data/Butterfly20/009.Iphiclides_podalirius/063.jpg', 8], ['/home/aistudio/data/Butterfly20/009.Iphiclides_podalirius/159.jpg', 8], ['/home/aistudio/data/Butterfly20/009.Iphiclides_podalirius/193.jpg', 8], ['/home/aistudio/data/Butterfly20/009.Iphiclides_podalirius/082.jpg', 8], ['/home/aistudio/data/Butterfly20/009.Iphiclides_podalirius/069.jpg', 8]]
### 数据的最大和最小尺寸df.height.max(),df.width.max(),df.height.min(),df.width.min()
(600, 600, 155, 298)
group=df.name.value_counts() #查看样品分布情况plt.figure(figsize=(8,4),dpi=100) group.plot(kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x7f47a3257550>
<Figure size 800x400 with 1 Axes>
def label_suffle(df,key='label'):
label_max = df[key].value_counts().max() #获取标签数量最大值
label_len = len(np.unique(df[key])) #获取样品标签个数
label_balance =pd.DataFrame() for i in range(label_len): #print(len(df[df[key]==i]))
if len(df[df[key]==i]) == label_max: #比较当前样品编号数量与最大值,如果相等则添加该样本所有数据
label_balance=label_balance.append(df[df[key]==i]) else:
df_i = df[df[key]==i].sample(label_max,replace=True) #否则从该样品自身生产与最大标签数量的样本
label_balance=label_balance.append(df_i)
label_balance.sample(frac=1) #乱序
return label_balancedf=label_suffle(df)
group=df.name.value_counts() #查看样品分布情况plt.figure(figsize=(8,4),dpi=100) group group.plot(kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x7f47a337a610>
<Figure size 800x400 with 1 Axes>
###关键的数据处理: 数据集的生成,抽离验证集后,对训练集的数据标签平滑
df = pd.DataFrame(but_files,columns=['filepath']) #生成数据框。 df['name'] = df.filepath.apply(lambda x:x.split('/')[-2]) #按要求产生相对路径。只要工作目录下的相对路径 。df['label']=df.name.map(label_dic) #用映射生成标签 del df['name']
eval_dataset=df.sample(frac=0.1)
train_dataset= df.drop(index=eval_dataset.index)
train_dataset= label_suffle(train_dataset) # 单独对训练集的数据标签平滑group=train_dataset.label.value_counts() #查看样品分布情况plt.figure(figsize=(8,4),dpi=100)
group.plot(kind='bar')
train_dataset=np.array(train_dataset).tolist()
eval_dataset=np.array(eval_dataset).tolist()# train_dataset['shape']=train_dataset.filepath.apply(lambda x:cv2.imread(x).shape) #数据形状<Figure size 800x400 with 1 Axes>
len(train_dataset)
3320
type(train_dataset),train_dataset[16],len(train_dataset)
(list, ['/home/aistudio/data/Butterfly20/001.Atrophaneura_horishanus/043.jpg', 0], 3320)
train_dataset[1]
['/home/aistudio/data/Butterfly20/001.Atrophaneura_horishanus/074.jpg', 0]
import os
import randomdata_list = [] #用个列表保存每个样本的读取路径、标签#由于属种名称本身是字符串,而输入模型的是数字。需要构造一个字典,把某个数字代表该属种名称。键是属种名称,值是整数。label_list=[]with open("/home/aistudio/data/species.txt") as f: for line in f: a,b = line.strip("\n").split(" ")
label_list.append([b, int(a)-1])
label_dic = dict(label_list)#获取Butterfly20目录下的所有子目录名称,保存进一个列表之中class_list = os.listdir("/home/aistudio/data/Butterfly20")
class_list.remove('.DS_Store') #删掉列表中名为.DS_Store的元素,因为.DS_Store并没有样本。for each in class_list: for f in os.listdir("/home/aistudio/data/Butterfly20/"+each):
data_list.append(["/home/aistudio/data/Butterfly20/"+each+'/'+f,label_dic[each]])#按文件顺序读取,可能造成很多属种图片存在序列相关,用random.shuffle方法把样本顺序彻底打乱。random.shuffle(data_list)#打印前十个,可以看出data_list列表中的每个元素是[样本读取路径, 样本标签]。print(data_list[0:10])#打印样本数量,一共有1866个样本。print("样本数量是:{}".format(len(data_list)))以下,通过opencv 的仿射,将数据填充到600*600的底片中,后续的resize,也不会照成变形。 该数据增强方式为本实践,最有意义的部分之一。
def enlarge(img):
h,w,_=img.shape ty=(600-h)//2
tx=(600-w)//2
# 定义平移矩阵,需要是numpy的float32类型
# x轴平移200,y轴平移500
M = np.float32([[1, 0, tx], [0, 1, ty]])
# 用仿射变换实现平移
dst = cv2.warpAffine(img, M, (600, 600))
dst = dst[100:501,100:501,:]
return dstdef random_rotate(img): height,width,_ =img.shape degree=random.choice(range(0,360,10)) size=random.uniform(0.7, 0.95) matRotate = cv2.getRotationMatrix2D((height*0.5, width*0.5),degree, size) # mat rotate 1 center 2 angle 3 缩放系数 return cv2.warpAffine(img, matRotate, (width,height ))
def preprocess(img):
transform = Compose([ Resize(size=(224, 224)), #把数据长宽像素调成224*224
#ColorJitter(0.4, 0.4, 0.4, 0.4), RandomHorizontalFlip(0.5), RandomRotation((-10,10)),
Normalize(mean=[127.5, 127.5, 127.5], std=[127.5, 127.5, 127.5], data_format='HWC'), #标准化
#Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], data_format='HWC'), #标准化 Transpose(), #原始数据形状维度是HWC格式,经过Transpose,转换为CHW格式
])
img = transform(img).astype("float32")
return img#以下代码用于构造读取器与数据预处理#首先需要导入相关的模块import paddle#from paddle.vision.transforms import Compose, ColorJitter, Resize,Transpose, Normalize,RandomRotationfrom paddle.vision.transforms import Compose,CenterCrop, Resize,Normalize,RandomRotation,RandomHorizontalFlip,Transpose,ToTensorimport cv2import numpy as npfrom PIL import Imagefrom paddle.io import Datasetdef enlarge(img):
h,w,_=img.shape
ty=(600-h)//2
tx=(600-w)//2
# 定义平移矩阵,需要是numpy的float32类型
# x轴平移200,y轴平移500
M = np.float32([[1, 0, tx], [0, 1, ty]]) # 用仿射变换实现平移
dst = cv2.warpAffine(img, M, (600, 600))
dst = dst[100:501,100:501,:] return dstdef random_rotate(img):
height,width,_ =img.shape
degree=random.choice(range(0,360,10))
size=random.uniform(0.7, 0.95)
matRotate = cv2.getRotationMatrix2D((height*0.5, width*0.5),degree, size) # mat rotate 1 center 2 angle 3 缩放系数
return cv2.warpAffine(img, matRotate, (width,height ))#自定义的数据预处理函数,输入原始图像,输出处理后的图像,可以借用paddle.vision.transforms的数据处理功能def preprocess(img):
transform = Compose([ #CenterCrop(400),
#Resize(size=(224, 224)), #把数据长宽像素调成224*224
#ColorJitter(0.4, 0.4, 0.4, 0.4),
RandomHorizontalFlip(0.8), #BrightnessTransform(0.4),
RandomRotation((-10,10)),
Resize(size=(224, 224)), #把数据长宽像素调成224*224
Normalize(mean=[0, 0, 0],std=[255, 255, 255], data_format='HWC'),
#Normalize(mean=[127.5, 127.5, 127.5], std=[127.5, 127.5, 127.5], data_format='HWC'), #标准化
#Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225], data_format='HWC'), #标准化
Transpose(), #原始数据形状维度是HWC格式,经过Transpose,转换为CHW格式
])
img = transform(img).astype("float32") return img#自定义数据读取器class Reader(Dataset):
# def __init__(self, data, is_val=False):
# super().__init__()
# #在初始化阶段,把数据集划分训练集和测试集。由于在读取前样本已经被打乱顺序,取20%的样本作为测试集,80%的样本作为训练集。
# self.samples = data[-int(len(data)*0.2):] if is_val else data[:-int(len(data)*0.2)]
def __init__(self, dataset):
super().__init__() #在初始化阶段,把数据集划分训练集和测试集。由于在读取前样本已经被打乱顺序,取20%的样本作为测试集,80%的样本作为训练集。
self.samples = dataset def __getitem__(self, idx):
#处理图像
img_path = self.samples[idx][0] #得到某样本的路径
#img = Image.open(img_path)
img =cv2.imread(img_path) # if img.mode != 'RGB':
# img = img.convert('RGB')
img =img[:,:,::-1]
img=enlarge(img) #img=random_rotate(img)
img = preprocess(img) #数据预处理--这里仅包括简单数据预处理,没有用到数据增强
#处理标签
label = self.samples[idx][1] #得到某样本的标签
label = np.array([label], dtype="int64") #把标签数据类型转成int64
return img, label def __len__(self):
#返回每个Epoch中图片数量
return len(self.samples)#生成训练数据集实例train_dataset = Reader(train_dataset)#生成测试数据集实例eval_dataset = Reader(eval_dataset)#打印一个训练样本#print(train_dataset[1136][0])print(train_dataset[16][0].shape)print(train_dataset[16][1])(3, 224, 224) [0]
len(train_dataset)
3320
len(train_dataset),len(eval_dataset)
(3320, 187)
为了提升探索速度,建议首先选用比较成熟的基础模型,看看基础模型所能够达到的准确度。之后再试试模型融合,准确度是否有提升。最后可以试试自己独创模型。
为简便,这里直接采用50层的残差网络ResNet,并且采用预训练模式。为什么要采用预训练模型呢?因为通常模型参数采用随机初始化,而预训练模型参数初始值是一个比较确定的值。这个参数初始值是经历了大量任务训练而得来的,比如用CIFAR图像识别任务来训练模型,得到的参数。虽然蝴蝶识别任务和CIFAR图像识别任务是不同的,但可能存在某些机器视觉上的共性。用预训练模型可能能够较快地得到比较好的准确度。
在PaddlePaddle2.0中,使用预训练模型只需要设定模型参数pretained=True。
# 请补齐模型实例化代码network = paddle.vision.models.resnet50(num_classes=20, pretrained=True) model = paddle.Model(network) model.summary((1,3, 224, 224))
2021-03-12 22:06:02,097 - INFO - unique_endpoints {''}
2021-03-12 22:06:02,098 - INFO - File /home/aistudio/.cache/paddle/hapi/weights/resnet50.pdparams md5 checking...
2021-03-12 22:06:02,429 - INFO - Found /home/aistudio/.cache/paddle/hapi/weights/resnet50.pdparams-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
Conv2D-1 [[1, 3, 224, 224]] [1, 64, 112, 112] 9,408
BatchNorm2D-1 [[1, 64, 112, 112]] [1, 64, 112, 112] 256
ReLU-1 [[1, 64, 112, 112]] [1, 64, 112, 112] 0
MaxPool2D-1 [[1, 64, 112, 112]] [1, 64, 56, 56] 0
Conv2D-3 [[1, 64, 56, 56]] [1, 64, 56, 56] 4,096
BatchNorm2D-3 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
ReLU-2 [[1, 256, 56, 56]] [1, 256, 56, 56] 0
Conv2D-4 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,864
BatchNorm2D-4 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
Conv2D-5 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384
BatchNorm2D-5 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024
Conv2D-2 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384
BatchNorm2D-2 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024
BottleneckBlock-1 [[1, 64, 56, 56]] [1, 256, 56, 56] 0
Conv2D-6 [[1, 256, 56, 56]] [1, 64, 56, 56] 16,384
BatchNorm2D-6 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
ReLU-3 [[1, 256, 56, 56]] [1, 256, 56, 56] 0
Conv2D-7 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,864
BatchNorm2D-7 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
Conv2D-8 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384
BatchNorm2D-8 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024
BottleneckBlock-2 [[1, 256, 56, 56]] [1, 256, 56, 56] 0
Conv2D-9 [[1, 256, 56, 56]] [1, 64, 56, 56] 16,384
BatchNorm2D-9 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
ReLU-4 [[1, 256, 56, 56]] [1, 256, 56, 56] 0
Conv2D-10 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,864
BatchNorm2D-10 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
Conv2D-11 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,384
BatchNorm2D-11 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024
BottleneckBlock-3 [[1, 256, 56, 56]] [1, 256, 56, 56] 0
Conv2D-13 [[1, 256, 56, 56]] [1, 128, 56, 56] 32,768
BatchNorm2D-13 [[1, 128, 56, 56]] [1, 128, 56, 56] 512
ReLU-5 [[1, 512, 28, 28]] [1, 512, 28, 28] 0
Conv2D-14 [[1, 128, 56, 56]] [1, 128, 28, 28] 147,456
BatchNorm2D-14 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
Conv2D-15 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536
BatchNorm2D-15 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048
Conv2D-12 [[1, 256, 56, 56]] [1, 512, 28, 28] 131,072
BatchNorm2D-12 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048
BottleneckBlock-4 [[1, 256, 56, 56]] [1, 512, 28, 28] 0
Conv2D-16 [[1, 512, 28, 28]] [1, 128, 28, 28] 65,536
BatchNorm2D-16 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
ReLU-6 [[1, 512, 28, 28]] [1, 512, 28, 28] 0
Conv2D-17 [[1, 128, 28, 28]] [1, 128, 28, 28] 147,456
BatchNorm2D-17 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
Conv2D-18 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536
BatchNorm2D-18 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048
BottleneckBlock-5 [[1, 512, 28, 28]] [1, 512, 28, 28] 0
Conv2D-19 [[1, 512, 28, 28]] [1, 128, 28, 28] 65,536
BatchNorm2D-19 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
ReLU-7 [[1, 512, 28, 28]] [1, 512, 28, 28] 0
Conv2D-20 [[1, 128, 28, 28]] [1, 128, 28, 28] 147,456
BatchNorm2D-20 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
Conv2D-21 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536
BatchNorm2D-21 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048
BottleneckBlock-6 [[1, 512, 28, 28]] [1, 512, 28, 28] 0
Conv2D-22 [[1, 512, 28, 28]] [1, 128, 28, 28] 65,536
BatchNorm2D-22 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
ReLU-8 [[1, 512, 28, 28]] [1, 512, 28, 28] 0
Conv2D-23 [[1, 128, 28, 28]] [1, 128, 28, 28] 147,456
BatchNorm2D-23 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
Conv2D-24 [[1, 128, 28, 28]] [1, 512, 28, 28] 65,536
BatchNorm2D-24 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048
BottleneckBlock-7 [[1, 512, 28, 28]] [1, 512, 28, 28] 0
Conv2D-26 [[1, 512, 28, 28]] [1, 256, 28, 28] 131,072
BatchNorm2D-26 [[1, 256, 28, 28]] [1, 256, 28, 28] 1,024
ReLU-9 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-27 [[1, 256, 28, 28]] [1, 256, 14, 14] 589,824
BatchNorm2D-27 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
Conv2D-28 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144
BatchNorm2D-28 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
Conv2D-25 [[1, 512, 28, 28]] [1, 1024, 14, 14] 524,288
BatchNorm2D-25 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
BottleneckBlock-8 [[1, 512, 28, 28]] [1, 1024, 14, 14] 0
Conv2D-29 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144
BatchNorm2D-29 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
ReLU-10 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-30 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824
BatchNorm2D-30 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
Conv2D-31 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144
BatchNorm2D-31 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
BottleneckBlock-9 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-32 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144
BatchNorm2D-32 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
ReLU-11 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-33 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824
BatchNorm2D-33 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
Conv2D-34 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144
BatchNorm2D-34 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
BottleneckBlock-10 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-35 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144
BatchNorm2D-35 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
ReLU-12 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-36 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824
BatchNorm2D-36 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
Conv2D-37 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144
BatchNorm2D-37 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
BottleneckBlock-11 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-38 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144
BatchNorm2D-38 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
ReLU-13 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-39 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824
BatchNorm2D-39 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
Conv2D-40 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144
BatchNorm2D-40 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
BottleneckBlock-12 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-41 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,144
BatchNorm2D-41 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
ReLU-14 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-42 [[1, 256, 14, 14]] [1, 256, 14, 14] 589,824
BatchNorm2D-42 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
Conv2D-43 [[1, 256, 14, 14]] [1, 1024, 14, 14] 262,144
BatchNorm2D-43 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
BottleneckBlock-13 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-45 [[1, 1024, 14, 14]] [1, 512, 14, 14] 524,288
BatchNorm2D-45 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,048
ReLU-15 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0
Conv2D-46 [[1, 512, 14, 14]] [1, 512, 7, 7] 2,359,296
BatchNorm2D-46 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
Conv2D-47 [[1, 512, 7, 7]] [1, 2048, 7, 7] 1,048,576
BatchNorm2D-47 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192
Conv2D-44 [[1, 1024, 14, 14]] [1, 2048, 7, 7] 2,097,152
BatchNorm2D-44 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192
BottleneckBlock-14 [[1, 1024, 14, 14]] [1, 2048, 7, 7] 0
Conv2D-48 [[1, 2048, 7, 7]] [1, 512, 7, 7] 1,048,576
BatchNorm2D-48 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
ReLU-16 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0
Conv2D-49 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,359,296
BatchNorm2D-49 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
Conv2D-50 [[1, 512, 7, 7]] [1, 2048, 7, 7] 1,048,576
BatchNorm2D-50 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192
BottleneckBlock-15 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0
Conv2D-51 [[1, 2048, 7, 7]] [1, 512, 7, 7] 1,048,576
BatchNorm2D-51 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
ReLU-17 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0
Conv2D-52 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,359,296
BatchNorm2D-52 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
Conv2D-53 [[1, 512, 7, 7]] [1, 2048, 7, 7] 1,048,576
BatchNorm2D-53 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192
BottleneckBlock-16 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0
AdaptiveAvgPool2D-1 [[1, 2048, 7, 7]] [1, 2048, 1, 1] 0
Linear-1 [[1, 2048]] [1, 20] 40,980
===============================================================================
Total params: 23,602,132
Trainable params: 23,495,892
Non-trainable params: 106,240
-------------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 261.48
Params size (MB): 90.03
Estimated Total Size (MB): 352.09
-------------------------------------------------------------------------------/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1303: UserWarning: Skip loading for fc.weight. fc.weight receives a shape [2048, 1000], but the expected shape is [2048, 20].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1303: UserWarning: Skip loading for fc.bias. fc.bias receives a shape [1000], but the expected shape is [20].
warnings.warn(("Skip loading for {}. ".format(key) + str(err))){'total_params': 23602132, 'trainable_params': 23495892}<br/>
__all__ = ['CONFIG', 'get']CONFIG = { 'model_save_dir': "./chk_points/", 'num_classes': 20, 'total_images': 1866, 'epochs': 20, 'batch_size': 64, 'image_shape': [3, 224, 224], 'LEARNING_RATE': { 'params': { 'lr': 0.00375
}
}, 'OPTIMIZER': { 'params': { 'momentum': 0.9
}, 'regularizer': { 'function': 'L2', 'factor': 0.000001
}
}, 'LABEL_MAP': [ '001.Atrophaneura_horishanus','002.Atrophaneura_varuna','003.Byasa_alcinous','004.Byasa_dasarada','005.Byasa_polyeuctes','006.Graphium_agamemnon','007.Graphium_cloanthus','008.Graphium_sarpedon','009.Iphiclides_podalirius','010.Lamproptera_curius','011.Lamproptera_meges','012.Losaria_coon','013.Meandrusa_payeni','014.Meandrusa_sciron','015.Pachliopta_aristolochiae','016.Papilio_alcmenor','017.Papilio_arcturus','018.Papilio_bianor','019.Papilio_dialis','020.Papilio_hermosanus'
]
}
def get(full_path): for id, name in enumerate(full_path.split('.')): if id == 0: config = CONFIG
config = config[name]EPOCHS=11BATCH_SIZE=64
<br/>
def create_optim(parameters):
step_each_epoch = len(train_dataset)//64
lr = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=0.00375,
T_max=step_each_epoch * EPOCHS) return paddle.optimizer.Momentum(learning_rate=lr,
parameters=parameters,
weight_decay=paddle.regularizer.L2Decay(0.000001))# 模型训练配置model.prepare(create_optim(network.parameters()), # 优化器
paddle.nn.CrossEntropyLoss(), # 损失函数
paddle.metric.Accuracy(topk=(1, ))) # 评估指标# 训练可视化VisualDL工具的回调函数visualdl = paddle.callbacks.VisualDL(log_dir='visualdl_log')# 启动模型全流程训练model.fit(train_dataset, # 训练数据集
eval_dataset, # 评估数据集
epochs=EPOCHS, # 总的训练轮次
batch_size=BATCH_SIZE, # 批次计算的样本量大小
shuffle=True, # 是否打乱样本集
verbose=1, # 日志展示格式
save_dir='./butterflies/', # 分阶段的训练模型存储路径
callbacks=[visualdl]) # 回调函数使用The loss value printed in the log is the current step, and the metric is the average value of previous step. Epoch 1/11
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:77: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return (isinstance(seq, collections.Sequence) and /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:648: UserWarning: When training, we now always track global mean and variance. "When training, we now always track global mean and variance.")
step 52/52 [==============================] - loss: 0.4693 - acc: 0.6449 - 526ms/step save checkpoint at /home/aistudio/genvex/0 Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 3/3 [==============================] - loss: 0.5537 - acc: 0.8396 - 559ms/step Eval samples: 187 Epoch 2/11 step 52/52 [==============================] - loss: 0.0513 - acc: 0.9678 - 548ms/step save checkpoint at /home/aistudio/genvex/1 Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 3/3 [==============================] - loss: 0.5578 - acc: 0.8396 - 560ms/step Eval samples: 187 Epoch 3/11 step 52/52 [==============================] - loss: 0.0865 - acc: 0.9910 - 572ms/step save checkpoint at /home/aistudio/genvex/2 Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 3/3 [==============================] - loss: 0.4956 - acc: 0.8449 - 570ms/step Eval samples: 187 Epoch 4/11 step 52/52 [==============================] - loss: 0.0245 - acc: 0.9943 - 561ms/step save checkpoint at /home/aistudio/genvex/3 Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 3/3 [==============================] - loss: 0.5737 - acc: 0.8503 - 526ms/step Eval samples: 187 Epoch 5/11 step 52/52 [==============================] - loss: 0.0157 - acc: 0.9973 - 544ms/step save checkpoint at /home/aistudio/genvex/4 Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 3/3 [==============================] - loss: 0.4837 - acc: 0.8556 - 541ms/step Eval samples: 187 Epoch 6/11 step 52/52 [==============================] - loss: 0.0141 - acc: 0.9988 - 539ms/step save checkpoint at /home/aistudio/genvex/5 Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 3/3 [==============================] - loss: 0.5002 - acc: 0.8663 - 574ms/step Eval samples: 187 Epoch 7/11 step 52/52 [==============================] - loss: 0.0057 - acc: 0.9988 - 552ms/step save checkpoint at /home/aistudio/genvex/6 Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 3/3 [==============================] - loss: 0.5119 - acc: 0.8663 - 536ms/step Eval samples: 187 Epoch 8/11 step 52/52 [==============================] - loss: 0.0086 - acc: 0.9976 - 602ms/step save checkpoint at /home/aistudio/genvex/7 Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 3/3 [==============================] - loss: 0.4774 - acc: 0.8663 - 570ms/step Eval samples: 187 Epoch 9/11 step 52/52 [==============================] - loss: 0.0119 - acc: 0.9985 - 552ms/step save checkpoint at /home/aistudio/genvex/8 Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 3/3 [==============================] - loss: 0.4764 - acc: 0.8610 - 576ms/step Eval samples: 187 Epoch 10/11 step 52/52 [==============================] - loss: 0.0139 - acc: 0.9982 - 543ms/step save checkpoint at /home/aistudio/genvex/9 Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 3/3 [==============================] - loss: 0.4978 - acc: 0.8449 - 535ms/step Eval samples: 187 Epoch 11/11 step 52/52 [==============================] - loss: 0.0067 - acc: 0.9988 - 558ms/step save checkpoint at /home/aistudio/genvex/10 Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 3/3 [==============================] - loss: 0.5808 - acc: 0.8556 - 545ms/step Eval samples: 187 save checkpoint at /home/aistudio/genvex/final
model.save('butterfly', False) # save for inference/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/hapi/model.py:1738: UserWarning: 'inputs' was not specified when Model initialization, so the input shape to be saved will be the shape derived from the user's actual inputs. The input shape to be saved is [[64, 3, 224, 224]]. For saving correct input shapes, please provide 'inputs' for Model initialization. % self._input_info[0])
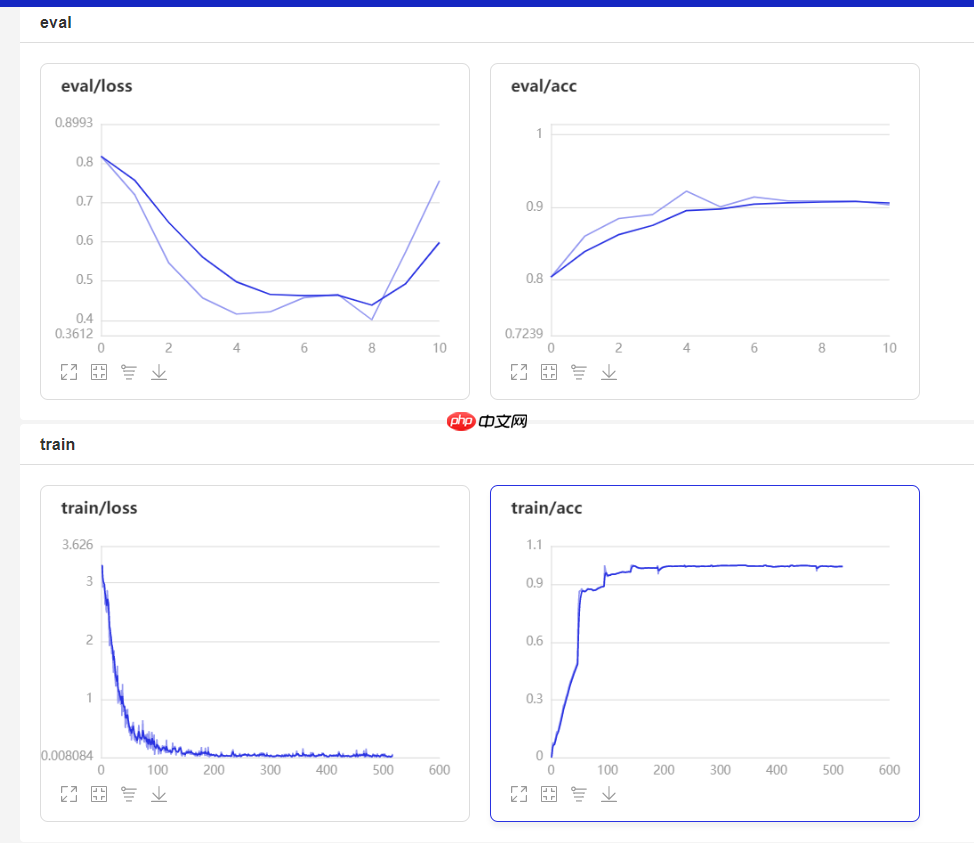
测试集,训练集均达 90%以上

## 构建测试集数据框image_list =glob.glob('/home/aistudio/data/Butterfly20_test/*.jpg')
df_image=pd.DataFrame(image_list)
df_image.rename(columns={0:'file_path'}, inplace = True)
df_image['submit']=df_image.file_path.apply(lambda x:x.split('/')[-1])
df_image.sort_values(by='submit', ascending=True, inplace=True )
df_image.reset_index(drop=True)file_path submit 0 /home/aistudio/data/Butterfly20_test/1.jpg 1.jpg 1 /home/aistudio/data/Butterfly20_test/10.jpg 10.jpg 2 /home/aistudio/data/Butterfly20_test/100.jpg 100.jpg 3 /home/aistudio/data/Butterfly20_test/101.jpg 101.jpg 4 /home/aistudio/data/Butterfly20_test/102.jpg 102.jpg .. ... ... 195 /home/aistudio/data/Butterfly20_test/95.jpg 95.jpg 196 /home/aistudio/data/Butterfly20_test/96.jpg 96.jpg 197 /home/aistudio/data/Butterfly20_test/97.jpg 97.jpg 198 /home/aistudio/data/Butterfly20_test/98.jpg 98.jpg 199 /home/aistudio/data/Butterfly20_test/99.jpg 99.jpg [200 rows x 2 columns]
# 定义数据预处理import paddle.vision.transforms as T
data_transforms = T.Compose([
T.Resize(size=(224, 224)),
T.Transpose(), # HWC -> CHW
T.Normalize(
mean=[0, 0, 0], # 归一化
std=[255, 255, 255],
to_rgb=True)
])<br/>
#paddle.set_device('gpu:0') paddle.set_device('cpu')
model = paddle.jit.load("butterfly")
model.eval() #训练模式def infer(img):
xdata =data_transforms(Image.open(img)).reshape(-1,3,224,224)
out = model(xdata)
label_pre=np.argmax(out.numpy())
return label_pre
infer(df_image.file_path[199])8
labelx=[]for i in df_image.file_path:
x=infer(i)
labelx.append(x)df_image['class_num'] = labelxdel df_image['file_path']
df_image.to_csv('submit2.csv', index=False,header=None)index=random.choice(image_list)
index20 =random.sample(image_list,20)
plt.figure(figsize=(12,12),dpi=100)for i in range(20):
img = cv2.imread(index20[i])
name=f'predict:{infer(index20[i])}'
plt.subplot(4, 5, i + 1)
plt.imshow(img[:,:,::-1], 'gray')
plt.title(name, fontsize=15,color='red')
plt.xticks([]), plt.yticks([])
plt.tight_layout()<Figure size 1200x1200 with 20 Axes>
1 001.Atrophaneura_horishanus2 002.Atrophaneura_varuna3 003.Byasa_alcinous4 004.Byasa_dasarada5 005.Byasa_polyeuctes6 006.Graphium_agamemnon7 007.Graphium_cloanthus8 008.Graphium_sarpedon9 009.Iphiclides_podalirius10 010.Lamproptera_curius11 011.Lamproptera_meges12 012.Losaria_coon13 013.Meandrusa_payeni14 014.Meandrusa_sciron15 015.Pachliopta_aristolochiae16 016.Papilio_alcmenor17 017.Papilio_arcturus18 018.Papilio_bianor19 019.Papilio_dialis20 020.Papilio_hermosanus
#定义模型class MyNet(paddle.nn.Layer):
def __init__(self):
super(MyNet,self).__init__()
self.layer=paddle.vision.models.resnet50(pretrained=True)
self.fc = paddle.nn.Linear(1000, 20) #网络的前向计算过程
def forward(self,x):
x=self.layer(x)
x=self.fc(x) return x一是定义输入数据形状大小和数据类型。
二是实例化模型。如果要用高阶API,需要用Paddle.Model()对模型进行封装,如model = paddle.Model(model,inputs=input_define,labels=label_define)。
三是定义优化器。这个使用Adam优化器,学习率设置为0.0001,优化器中的学习率(learning_rate)参数很重要。要是训练过程中得到的准确率呈震荡状态,忽大忽小,可以试试进一步把学习率调低。
四是准备模型。这里用到高阶API,model.prepare()。
五是训练模型。这里用到高阶API,model.fit()。参数意义详见下述代码注释。
#定义输入input_define = paddle.static.InputSpec(shape=[-1,3,224,224], dtype="float32", name="img") label_define = paddle.static.InputSpec(shape=[-1,1], dtype="int64", name="label")#实例化网络对象并定义优化器等训练逻辑model = MyNet() model = paddle.Model(model,inputs=input_define,labels=label_define) #用Paddle.Model()对模型进行封装 optimizer = paddle.optimizer.Adam(learning_rate=0.0001, parameters=model.parameters())#上述优化器中的学习率(learning_rate)参数很重要。要是训练过程中得到的准确率呈震荡状态,忽大忽小,可以试试进一步把学习率调低。model.prepare(optimizer=optimizer, #指定优化器 loss=paddle.nn.CrossEntropyLoss(), #指定损失函数 metrics=paddle.metric.Accuracy()) #指定评估方法 model.fit(train_data=train_dataset, #训练数据集 eval_data=eval_dataset, #测试数据集 batch_size=64, #一个批次的样本数量 epochs=10, #迭代轮次 save_dir="/home/aistudio/genvex", #把模型参数、优化器参数保存至自定义的文件夹 save_freq=20, #设定每隔多少个epoch保存模型参数及优化器参数 log_freq=100 #打印日志的频率 )
如果是要参加建模比赛,通常赛事组织方会提供待预测的数据集,我们需要利用自己构建的模型,来对待预测数据集合中的数据标签进行预测。也就是说,我们其实并不知道到其真实标签是什么,只有比赛的组织方知道真实标签,我们的模型预测结果越接近真实结果,那么分数也就越高。
预测流程分为以下几个步骤:
一是构建数据读取器。因为预测数据集没有标签,该读取器写法和训练数据读取器不一样,建议重新写一个类,继承于Dataset基类。
二是实例化模型。如果要用高阶API,需要用Paddle.Model()对模型进行封装,如paddle.Model(MyNet(),inputs=input_define),由于是预测模型,所以仅设定输入数据格式就好了。
三是读取刚刚训练好的参数。这个保存在/home/aistudio/work目录之下,如果指定的是final则是最后一轮训练后的结果。可以指定其他轮次的结果,比如model.load('/home/aistudio/work/30'),这里用到了高阶API,model.load()
四是准备模型。这里用到高阶API,model.prepare()。
五是读取待预测集合中的数据,利用已经训练好的模型进行预测。
六是结果保存。
from paddle.static import InputSpec# 网络结构示例化network = paddle.vision.models.resnet50(num_classes=get('num_classes'))# 模型封装model_2 = paddle.Model(network, inputs=[InputSpec(shape=[-1] + get('image_shape'), dtype='float32', name='image')])# 训练好的模型加载#model_2.load(get('model_save_dir'))model_2.load('/home/aistudio/chk_points/final')# 模型配置model_2.prepare()# 执行预测class InferDataset(Dataset):
def __init__(self, img_path=None):
"""
数据读取Reader(推理)
:param img_path: 推理单张图片
"""
super().__init__() if img_path:
self.img_paths = [img_path] else: raise Exception("请指定需要预测对应图片路径") def __getitem__(self, index):
# 获取图像路径
img_path = self.img_paths[index] # 使用Pillow来读取图像数据并转成Numpy格式
img = Image.open(img_path) if img.mode != 'RGB':
img = img.convert('RGB')
img = preprocess(img) #数据预处理--这里仅包括简单数据预处理,没有用到数据增强
return img def __len__(self):
return len(self.img_paths)#得到待预测数据集中每个图像的读取路径infer_list=[]with open("/home/aistudio/data/testpath.txt") as file_pred: for line in file_pred:
infer_list.append("/home/aistudio/data/"+line.strip())#模型预测结果通常是个数,需要获得其对应的文字标签。这里需要建立一个字典。def get_label_dict2():
label_list2=[] with open("/home/aistudio/data/species.txt") as filess: for line in filess:
a,b = line.strip("\n").split(" ")
label_list2.append([int(a)-1, b])
label_dic2 = dict(label_list2) return label_dic2
label_dict2 = get_label_dict2()#print(label_dict2)results=[]for infer_path in infer_list:
infer_data = InferDataset(infer_path)
result = model_2.predict(test_data=infer_data)[0] #关键代码,实现预测功能
result = paddle.to_tensor(result)
result = np.argmax(result.numpy()) #获得最大值所在的序号
results.append("{}".format(label_dict2[result])) #查找该序号所对应的标签名字# infer_data = InferDataset(infer_list)# result = model_2.predict(infer_data)#把结果保存起来with open("work/result.txt", "w") as f: for r in results:
f.write("{}\n".format(r))
```<br/>
以上就是基于PaddlePaddle2.0的蝴蝶图像识别分类——你的私人蝴蝶博物馆的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 467
467

























