本项目针对中国庞大视障群体出行难问题,利用深度学习技术,以微信小程序为前端,服务器部署训练好的模型。盲人通过手机摄像头实时监测路面,服务器经图像语义分割判断路况,语音引导避障,保障盲道行走安全。项目采用DeepLabv3+算法,自制数据集训练,解决现有产品成本高、使用复杂等问题。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

1. 项目背景
根据世界卫生组织报告显示,全球2.85亿的视力残疾(包括盲和低视力)患者中,约有8000万集中在中国,为全球拥有视力残疾患者最多的国家。其中,约有盲人700多万,占世界盲人总数的18%。失明及视力残疾人群已成为我国经济和社会发展的巨大负担。如何更好更高效地保障盲人的日常生活需求是一个重要的话题。而出行是盲人日常生活中最重要、最基本的需求。本项目针对盲人群体,着手于盲人出行的安全性,针对盲人在盲道上行走的场景设计作品。
据杨渝南团队调查发现,大部分盲人比我们想象的更喜欢外出,36%的盲人每天都会出门,45%的盲人会保持每周2至3次的出行率,仅有少数盲人选择深居简出。但同时他们的出行又很困难,有81%的盲人表示出行的难度较大或很大。因此,盲人有极大的外出需求需要被满足。但在这极大的外出需求下,盲道却未能达到能让盲人安全行走的标准。

在现实生活中,大多数的盲人都是通过普通的盲杖来辅助行走,而盲杖作为一根普通的长杆,探测范围窄,难以发现悬空范围的障碍物,具有较大的盲区。导盲犬虽可以协助盲人行进,却存在训练周期、成本较高的缺点,这也降低了导盲犬的使用性。国内的盲道多数规划不合理,摩托车、共享单车等各种障碍物随意占据着盲道。为了协助盲人安全行进,提高他们的生活质量,行业内也发明了许多高科技产品来助行、导航。然而,这些高科技产品成本过高,使用复杂,受众小,无法投入量产。目前在市场上针对方便盲人生活的智能设备尚未普及,且并未发现一款科技含量高且方便、友好的为盲人服务的电子导航器械。
2. 相关技术
目前现有的导盲技术大部分利用图像识别或传感器等技术,将周围的障碍物检测出来,通过语音或震动的方式,反馈给盲人。市场上目前存在着相似的产品,类似导航头盔、智能手杖或眼镜等,但它们大多都不是基于深度学习的方法。现阶段国内外针对导盲领域的研究方法主要有:RFID 技术、传感器及计算机视觉等技术。

深度学习的概念,源于三十多年来对计算机科学、人工神经网络和人工智能的研究。深度学习是对人脑思维深层次学习的模拟,通过模拟人脑的深层次抽象认知过程,实现计算机对数据的复杂运算和优化。利用深度学习的方法能模拟人眼的功能,判断合适距离的盲道上中障碍物的存在,从而实现引导盲人避开障碍物,在没有障碍物的盲道或没有障碍物的普通路面上行走。
3. 设计方案
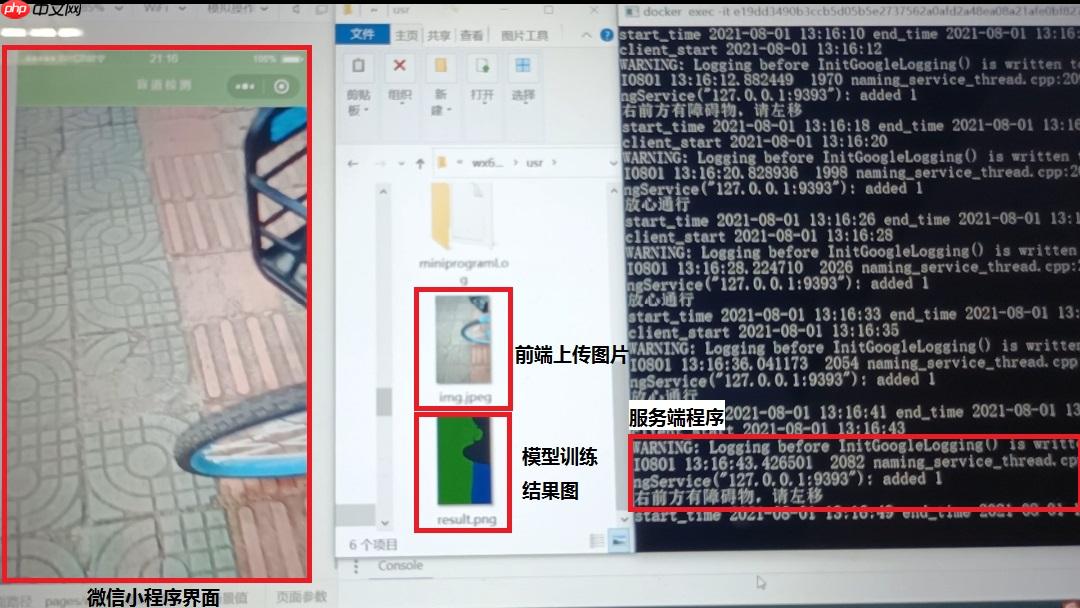
本项目致力于为盲人出行提供更安全的引导服务。该项目将训练好的模型部署在服务器端,前端为微信小程序。盲人出行时将手机摄像头成45度朝下便可实时监测路面盲道状况。在盲道上行走时,小程序通过手机后置摄像头摄像,间隔时间获得一帧图片,将获得照片传给服务器端,在服务器端通过模型获得分割结果图片,再通过方向引导程序,判断安全的行走方向,将判断结果传给小程序前端,语音播报判断结果,引导盲人在盲道上安全行走。当盲道上出现障碍物时,设备会给出警告提醒,语音引导盲人绕过障碍物,谨防出现摔倒等现象。有效便利了盲人群体的出行,给盲人在盲道上行走的安全带来了保障。
本项目为了实现能从图片中识别出没有障碍物的盲道以及普通路面的功能,主要采用了图像语义分割的技术,图像语义分割能对图像中每一个像素点进行分类,确定每个点的类别(如盲道、普通路面或障碍物),进行区域划分,从而能判断出前方路面是否属于盲人可以行走的路面范围。
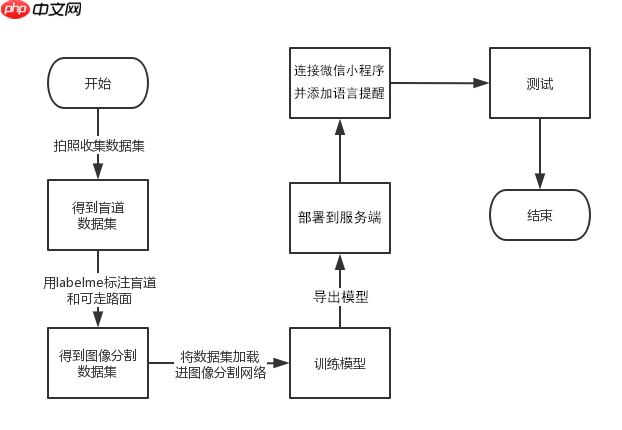
项目开发流程图
3.1 模型训练和部署
项目基于 Paddle2.0和PaddleSeg进行开发,采用DeepLabv3+图像分割网络算法,为减小服务器运行负担,选用轻量级MobileNetV2作为骨干网络,在自制的障碍物数据集上训练并测试。
import osimport ioimport numpy as npimport matplotlib.pyplot as pltfrom PIL import Image as PilImageimport paddlefrom paddle.nn import functional as Fimport warnings
warnings.filterwarnings('ignore')
paddle.__version__
'2.0.2'
3.1.1 收集制作盲道数据集
自行收集盲道数据集,目的能更好地针对盲道情况进行导航。收集不同天气、不同规格的盲道照片,使用labelme对照片中没有障碍物的盲道区域和没有障碍物的普通可走路面进行标注,在进行筛选后,最终使用的图片数量为4300张。使用labelme将标注图片导出,数据集处理完成。




3.1.2 解压缩PaddleSeg和盲道数据集
!unzip -oq /home/aistudio/data/data94991/PaddleSeg-release-2.1.zip -d work/ !unzip -oq /home/aistudio/data/data101207/blindlane.zip -d work/blindlane
数据集概览
根据PaddleSeg要求的数据集格式,处理数据集。
数据集解压后,文件格式如下。
├── label └── image
3.1.3 划分数据集
按照8:1:1的比例划分训练集、验证集和测试集。
数据集处理后,文件格式如下。
├── label │ ├── train │ │ └── ... │ ├── test│ │ └── ... │ └── eval│ └── ... ├── image │ ├── train │ │ └── ... │ ├── test│ │ └── ... │ └── eval│ └── ... ├── test.txt ├── train.txt └── eval.txt
import codecsimport osimport randomimport shutilfrom PIL import Image
preimages_path = 'work/blindlane/image'prelabel_path = 'work/blindlane/label'trainfile_path = 'work/dataset'images_path = 'work/dataset/image'labels_path = 'work/dataset/label'train_file = codecs.open(os.path.join(trainfile_path, "train.txt"), 'w')
eval_file = codecs.open(os.path.join(trainfile_path, "eval.txt"), 'w')
test_file = codecs.open(os.path.join(trainfile_path, "test.txt"), 'w')
train_ratio = 0.8eval_ratio = 0.9dirlist = ['train','test','eval']def mkdir(path):
if not os.path.exists(os.path.join(path,dirlist[0])):
os.mkdir(os.path.join(path,dirlist[0])) if not os.path.exists(os.path.join(path,dirlist[1])):
os.mkdir(os.path.join(path,dirlist[1])) if not os.path.exists(os.path.join(path,dirlist[2])):
os.mkdir(os.path.join(path,dirlist[2]))
mkdir(images_path)
mkdir(labels_path)
traincon,evalcon,testcon = 0, 0, 0for image_name in os.listdir(preimages_path): for label_name in os.listdir(prelabel_path): if image_name.endswith('png') and (image_name[:-9]==label_name[:-9]):
img = Image.open(os.path.join(preimages_path, image_name))
label = Image.open(os.path.join(prelabel_path, label_name))
ran = random.uniform(0, 1) if ran <= train_ratio:
shutil.copyfile(os.path.join(preimages_path, image_name), os.path.join(os.path.join(images_path,'train'), image_name))
shutil.copyfile(os.path.join(prelabel_path, label_name), os.path.join(os.path.join(labels_path,'train'), label_name))
train_file.write("{0} {1}\n".format(os.path.join(os.path.join('image','train'), image_name), os.path.join(os.path.join('label','train'), label_name)))
traincon+=1
elif ran > train_ratio and ran <= eval_ratio :
shutil.copyfile(os.path.join(preimages_path, image_name), os.path.join(os.path.join(images_path,'eval'), image_name))
shutil.copyfile(os.path.join(prelabel_path, label_name), os.path.join(os.path.join(labels_path,'eval'), label_name))
eval_file.write("{0} {1}\n".format(os.path.join(os.path.join('image','eval'), image_name), os.path.join(os.path.join('label','eval'), label_name)))
evalcon+=1
elif ran >= eval_ratio:
shutil.copyfile(os.path.join(preimages_path, image_name), os.path.join(os.path.join(images_path,'test'), image_name))
shutil.copyfile(os.path.join(prelabel_path, label_name), os.path.join(os.path.join(labels_path,'test'), label_name))
test_file.write("{0} {1}\n".format(os.path.join(os.path.join('image','test'), image_name), os.path.join(os.path.join('label','test'), label_name)))
testcon+=1train_file.close()
eval_file.close()
test_file.close()print(traincon,evalcon,testcon)
3.1.4 训练模型
使用PaddleSeg时的配置信息是采用yml文件描述的,这里使用的是deeplabv3p.yaml文件。 尝试Paddle2.0版本训练转换模型失败,最终选择Paddle1.8环境训练模型。
!python work/PaddleSeg-release-2.1/train.py --cfg deeplabv3p.yaml --use_gpu
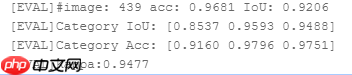
3.1.5 模型评估
## 查看模型训练效果!python work/PaddleSeg-release-2.2/legacy/pdseg/eval.py --use_gpu --cfg deeplabv3p.yaml TEST.TEST_MODEL saved_model/final
## 测试结果可视化 !python work/PaddleSeg-release-2.2/legacy/pdseg/vis.py --use_gpu --cfg deeplabv3p.yaml TEST.TEST_MODEL saved_model/final
评估结果

3.1.6 导出模型
将模型转为适用于PaddleServing的模型
在Paddle2.0环境中运行export_serving_model.py
# 安装转换所需包!pip install paddle-serving-client !pip install paddle-serving-server !pip install paddle_serving_app
# model/saved_model/final为上述训练所保存的模型!python work/PaddleSeg-release-2.1/legacy/pdseg/export_serving_model.py --cfg /home/aistudio/deeplabv3p.yaml TEST.TEST_MODEL model/saved_model/final
3.1.7 部署服务端
# 在终端运行服务端代码!python -m paddle_serving_server.serve --model freeze_model/serving_server --thread 5 --port 9292 --ir_optim
# 运行客户端代码 image_path为需要预测的图片地址 !python work/PaddleSeg-release-2.1/legacy/deploy/paddle-serving/seg_client.py image_path
3.1.8 行走方向判断
首先获得模型生成label图片中障碍物区域的像素值,设置二值化范围生成图片,此时图片像素区分为障碍物区域和可安全行走区域。
同时划分图像中未来行走区域,判断行走区域中是否有代表障碍物区域的像素值,当像素值大于阈值时,说明前方有障碍物。
通过计算障碍物区域质心判断行走方向,以图像中线为基准,质心相对偏左,则提示向右移动。从而实现简易的行走导向功能。
与障碍物判断相似,通过二值化划分可走普通路面和可走盲道,在计算盲道区域质心,即可实现引导走回盲道的功能。但由于设备性能不足,项目目前未加入此功能。

基于PHP+MYSQL开发,除了网上书店必备的商品管理、配送支付管理、订单管理、会员分组、会员管理、查询统计和多项商品促销功能,还具有完整的文章、图文、下载、单页、广告发布等网站内容管理功能。系统具有静态HTML生成、UTF-8多语言支持、可视化模版引擎等技术特点,支持多频道调用不同模版和任意设置频道首页,适合建立各种规模的网上书店。系统具有以下主要功能模块: 网站参数设置 - 对网站的一些参数进
行走方向判断程序详见path.py
3.2 微信小程序前端
3.2.1 搭建微信小程序开发环境
申请微信小程序账号
微信公众号平台:https://mp.weixin.qq.com/
微信小程序账号啊申请流程:https://developers.weixin.qq.com/miniprogram/dev/framework/
微信小程序注册页面:https://mp.weixin.qq.com/wxopen/waregister?action=step1
注意所填邮箱必须满足以下条件:
(1)未注册过微信公众平台;
(2)未注册过微信开发平台;
(3)未用于绑定过个人微信号。
获取自己的AppID和AppSecret。
安装开发者工具
https://developers.weixin.qq.com/miniprogram/dev/devtools/download.html
3.2.2 新建小程序项目
使用自己的AppID新建项目
project.config.json: 配置文件,配置项目名称、AppID等内容。
app.js: 小程序逻辑,系统的方法处理文件
app.json: 小程序的全局配置
3.2.3 获取微信用户信息
通过wx.getSetting()获取用户的当前设置,通过wx.getUserInfo()获取用户信息,通过wx.request()发起 HTTPS 网络请求将获取到的微信用户信息存入到数据库,其中url为开发者服务器接口地址,其中code_to_openidv3可以连接后端代码。
// 获取用户信息
wx.getSetting({
success: res => { if (res.authSetting['scope.userInfo']) {
wx.getUserInfo({
fail:res=>{
console.log("获取用户信息失败",res)
},
success: res => {
// 可以将 res 发送给后台解码出 unionId
this.globalData.userInfo = res.userInfo
// 登录
wx.login({
success: res => { // 发送 res.code 到后台换取 openId, sessionKey, unionId
wx.request({
url: wxUrl + "code_to_openidv3",
data: {
//...
},
success: res => {
wx.setStorageSync('MY_OPENID', res.data.openid)
//跳转主页面
},
fail: function (res) {
console.log('wx.login fail' + res)
}
})
}
})
// 由于 getUserInfo 是网络请求,可能会在 Page.onLoad 之后才返回
// 所以此处加入 callback 以防止这种情况 if (this.userInfoReadyCallback) {
this.userInfoReadyCallback(res)
}
}
})
}
}
})
3.2.4 实现实时获取摄像头图像
页面布局:
功能实现:
使用微信小程序摄像头功能需要先获取用户的授权,通过wx.createCameraContext()创建 camera 上下文 CameraContext 对象,通过CameraContext.takePhoto()能拍摄照片,将照片保存至同一路径下,每次保存替换前一张照片,每5秒保存一张。在保存成功一张图片后通过wx.getFileSystemManager().readFile()读取指定路径下的文本文件。读取内容为“1”,播放向左行的指令音频;读取内容为“2”,播放向右行的指令音频;读取内容为“0”,播放直行的指令音频。
const ctx = wx.createCameraContext() function takepic(){
ctx.takePhoto({ quality: 'high', filePath: wx.env.USER_DATA_PATH + '/img.jpeg', success: (res) => {
self.setData({
src: res.tempImagePath
}) const path = res.tempImagePath;
wx.saveFile({ tempFilePath: path, filePath: wx.env.USER_DATA_PATH + '/img.jpeg', success: (res) => {
wx.getFileSystemManager().readFile({ //读取文件
filePath: wx.env.USER_DATA_PATH + '/message/message.txt', encoding: 'utf-8', success: res => { console.log(res.data) if(res.data == '1')
{ console.log("left!")
audio_left.play(); console.log("play success!")
} else if (res.data == '2'){ console.log("right!")
audio_right.play(); console.log("play success!")
} else if (res.data == '0'){ console.log("go straight!")
audio_straight.play(); console.log("play success!")
}
}, fail: console.error
})
}, fail: (err) => {
},
});
}
}) return function(){
takepic()
}
} var interval = setInterval(takepic(),5000)
音频读取实现
#创建内部 audio 上下文 InnerAudioContext 对象const audio_left = wx.createInnerAudioContext({});const audio_right = wx.createInnerAudioContext({});const audio_straight = wx.createInnerAudioContext({});#音频路径onShow() {
audio_left.src = wx.env.USER_DATA_PATH + '/audio/1left.mp3'
audio_right.src = wx.env.USER_DATA_PATH + '/audio/1right.mp3'
audio_straight.src = wx.env.USER_DATA_PATH + '/audio/1straight.mp3'},#播放audio_left.play();
audio_right.play();
audio_straight.play();
3.3 效果展示